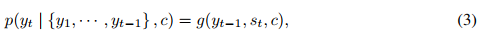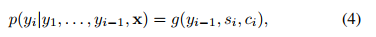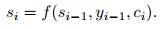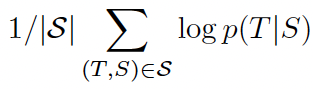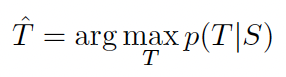최근 작업에서는 대규모 텍스트 모음에 대한 사전 학습과 특정 작업에 대한 미세 조정을 통해 많은 NLP 작업 및 벤치마크에서 상당한 이점을 얻었습니다. 일반적으로 아키텍처에서는 작업에 구애받지 않지만 이 방법에는 여전히 수천 또는 수만 개의 예제로 구성된 작업별 미세 조정 데이터 세트가 필요합니다. 대조적으로, 인간은 일반적으로 단지 몇 가지 예나 간단한 지시만으로 새로운 언어 작업을 수행할 수 있습니다. 이는 현재 NLP 시스템이 여전히 수행하는 데 어려움을 겪고 있습니다. 여기서 우리는 언어 모델을 확장하면 작업에 구애받지 않는 Few-Shot 성능이 크게 향상되고 때로는 이전의 최첨단 미세 조정 접근 방식으로 경쟁력에 도달할 수도 있음을 보여줍니다. 구체적으로 우리는 이전의 비희소 언어 모델보다 10배 더 많은 1,750억 개의 매개변수를 가진 자동 회귀 언어 모델인 GPT-3를 훈련하고 소수 설정에서 성능을 테스트합니다. 모든 작업에 대해 GPT-3는 그라데이션 업데이트나 미세 조정 없이 적용되며 작업과 소수의 데모는 순전히 모델과의 텍스트 상호 작용을 통해 지정됩니다. GPT-3는 번역, 질문 답변, 클로제 작업을 포함한 많은 NLP 데이터 세트뿐만 아니라 단어 해독, 새로운 단어 사용과 같은 즉석 추론이나 도메인 적응이 필요한 여러 작업에서 강력한 성능을 달성합니다. 문장을 읽거나 세 자리 연산을 수행합니다. 동시에 우리는 GPT-3의 퓨샷 학습이 여전히 어려움을 겪고 있는 일부 데이터 세트와 GPT-3가 대규모 웹 말뭉치에 대한 교육과 관련된 방법론적 문제에 직면한 일부 데이터 세트도 식별합니다. 마지막으로, 우리는 GPT-3가 인간 평가자가 인간이 작성한 기사와 구별하기 어려운 뉴스 기사 샘플을 생성할 수 있음을 발견했습니다. 우리는 이번 발견과 GPT-3의 전반적인 사회적 영향에 대해 논의합니다.
최근 몇 년 동안 다운스트림 전송을 위해 점점 더 유연하고 작업에 구애받지 않는 방식으로 적용되는 NLP 시스템에서 사전 훈련된 언어 표현을 향한 추세가 나타났습니다. 먼저, 단어 벡터[MCCD13, PSM14]를 사용하여 단일 계층 표현을 학습하고 작업별 아키텍처에 공급한 다음 여러 계층의 표현과 상황별 상태를 갖춘 RNN을 사용하여 더 강력한 표현을 형성했습니다[DL15, MBXS17, PNZtY18](여전히 작업별 아키텍처에 적용됨), 최근에는 미리 훈련된 순환 또는 변환기 언어 모델[VSP+17]이 직접 미세 조정되어 작업별 아키텍처[RNSS18, DCLT18, HR18]의 필요성이 완전히 제거되었습니다.
이 마지막 패러다임은 독해, 질문 답변, 텍스트 수반 등과 같은 많은 까다로운 NLP 작업에서 상당한 진전을 이루었으며 새로운 아키텍처와 알고리즘 [RSR+19, LOG+19, YDY+9, LCG+19]을 기반으로 계속해서 발전해 왔습니다. 그러나 이 접근 방식의 주요 제한 사항은 아키텍처가 작업에 구애받지 않지만 여전히 작업별 데이터 세트 및 작업별 미세 조정이 필요하다는 것입니다. 원하는 작업에서 강력한 성능을 얻으려면 일반적으로 미세 조정이 필요합니다. 해당 작업과 관련된 수천에서 수십만 개의 사례로 구성된 데이터 세트입니다. 여러 가지 이유로 이 제한을 제거하는 것이 바람직합니다.
첫째, 실용적인 관점에서 볼 때 모든 새로운 작업에 대해 레이블이 지정된 예제로 구성된 대규모 데이터 세트가 필요하기 때문에 언어 모델의 적용 가능성이 제한됩니다. 문법 교정부터 추상적 개념의 예 생성, 단편 소설 비평까지 모든 것을 포괄하는 유용한 언어 작업이 매우 광범위하게 존재합니다. 이러한 작업 중 많은 경우, 특히 모든 새 작업에 대해 프로세스를 반복해야 하는 경우 대규모 지도 학습 데이터 세트를 수집하기가 어렵습니다.
둘째, 훈련 데이터에서 허위 상관 관계를 활용할 가능성은 모델의 표현력과 훈련 분포의 좁음에 따라 근본적으로 커집니다. 이는 사전 훈련 중에 정보를 흡수하기 위해 모델이 크게 설계되었지만 매우 좁은 작업 분포에서 미세 조정되는 사전 훈련 및 미세 조정 패러다임에 문제를 일으킬 수 있습니다. 예를 들어 [HLW+20]은 더 큰 모델이 반드시 더 나은 분포 외 일반화를 일반화하는 것은 아니라는 점을 관찰합니다. 이 패러다임에서 달성된 일반화는 모델이 훈련 분포에 지나치게 특정적이고 그 외부에서는 잘 일반화되지 않기 때문에 좋지 않을 수 있음을 암시하는 증거가 있습니다[YdC+19, MPL19]. 따라서 특정 벤치마크에서 미세 조정된 모델의 성능은 명목상 인간 수준일 때에도 기본 작업에 대한 실제 성능을 과장할 수 있습니다[GSL+18, NK19].
셋째, 인간은 대부분의 언어 작업을 학습하기 위해 대규모 지도 데이터 세트를 필요로 하지 않습니다. 즉, 자연어의 간단한 지시(예: "이 문장이 행복한 것인지 슬픈 것인지 알려주세요") 또는 기껏해야 소수의 시연(예: "용감하게 행동하는 사람들의 두 가지 예입니다. 세 번째 용감한 예를 들어주십시오.")입니다. 이는 종종 인간이 최소한 합리적인 수준의 능력으로 새로운 작업을 수행할 수 있게 하는 데 충분합니다. 현재 NLP 기술의 개념적 한계를 지적하는 것 외에도 이러한 적응성은 실질적인 이점을 가지고 있습니다. 이를 통해 인간은 예를 들어 긴 대화 중에 추가를 수행하는 등 많은 작업과 기술을 원활하게 혼합하거나 전환할 수 있습니다. 광범위하게 유용하게 활용하려면 언젠가 우리의 NLP 시스템이 이와 동일한 유동성과 일반성을 갖기를 원할 것입니다.
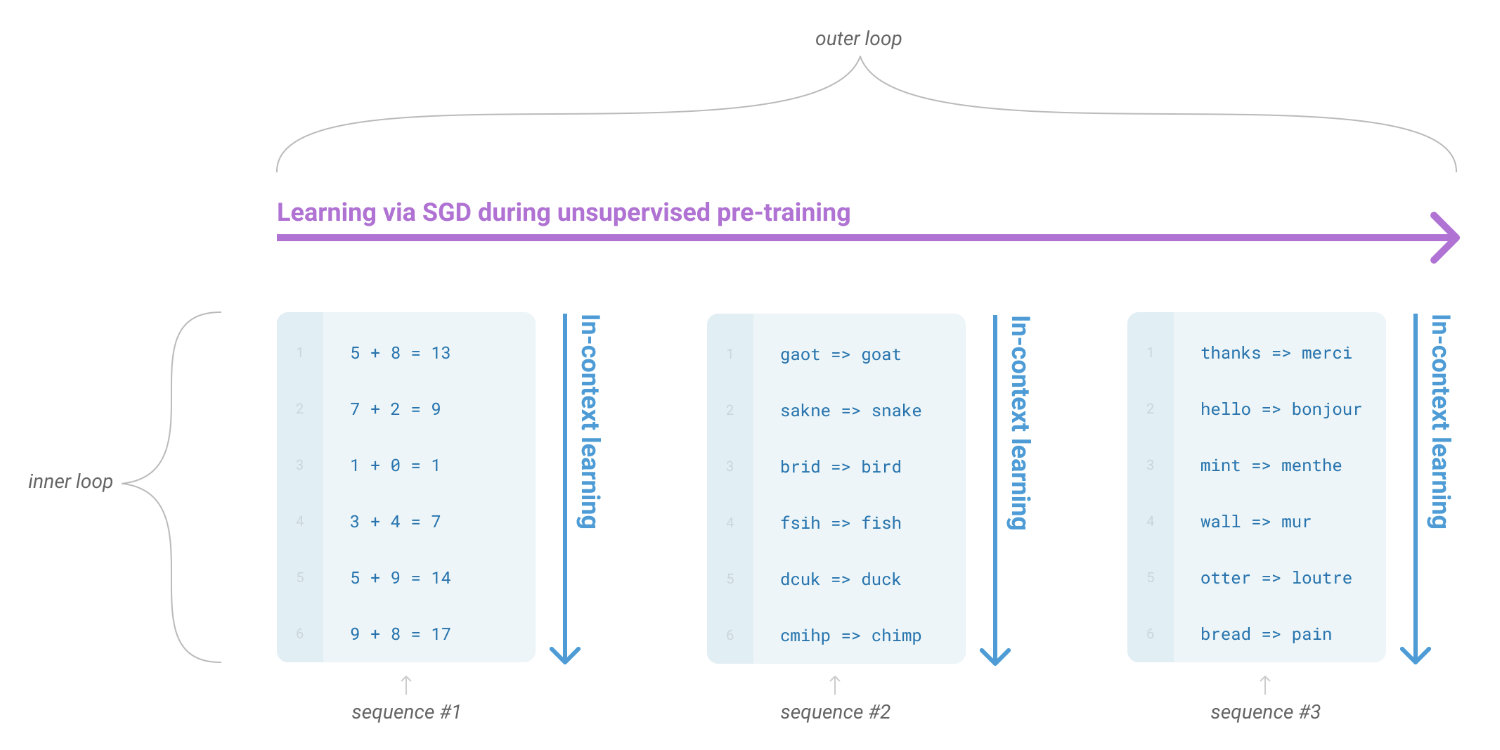
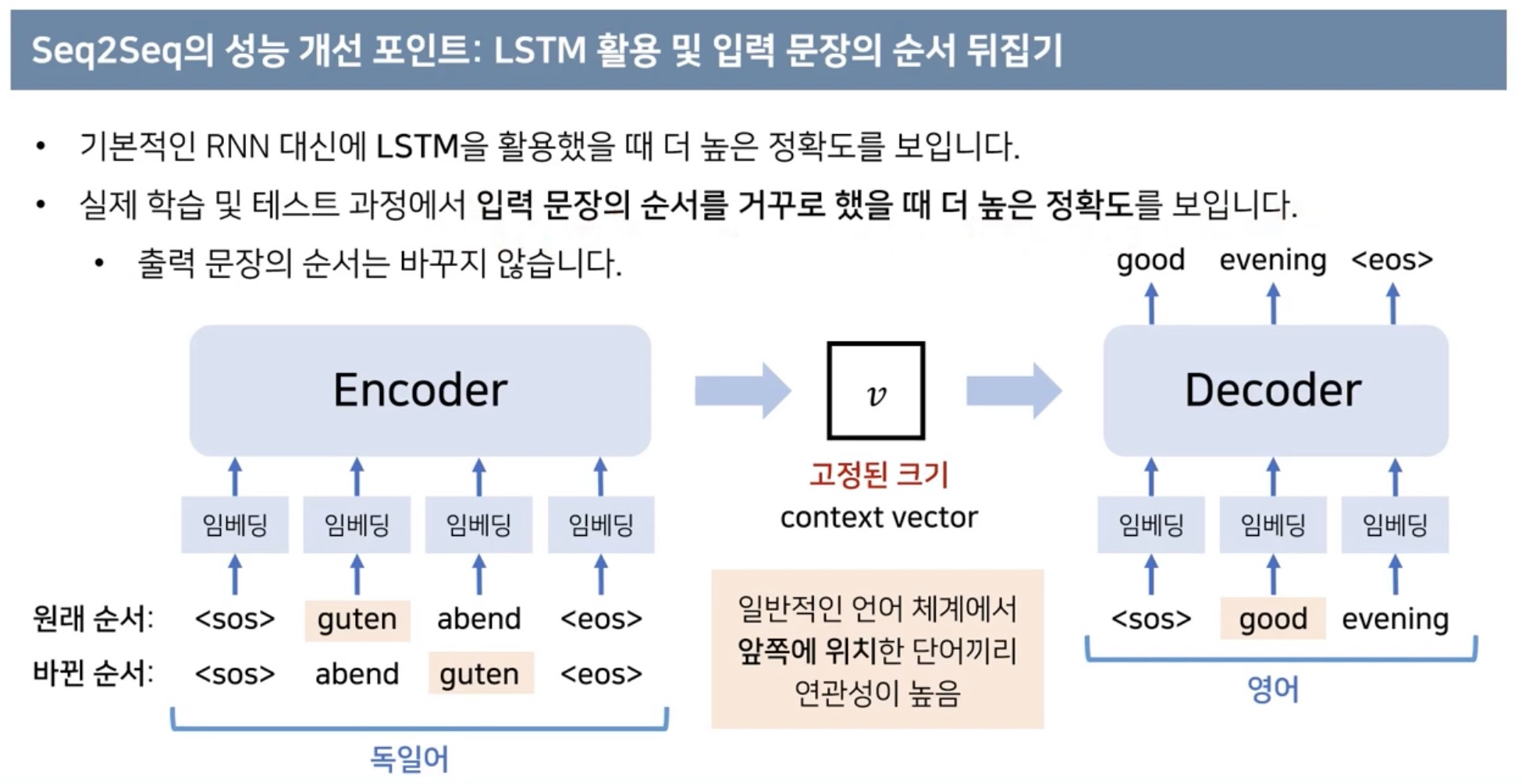
그림1.1 : Language model meta-learning, 감독되지 않은 사전 훈련 중에 언어 모델은 광범위한 기술과 패턴 인식 능력을 개발합니다. 그런 다음 추론 시 이러한 기능을 사용하여 원하는 작업에 빠르게 적응하거나 인식합니다. 우리는 각 시퀀스의 정방향 전달 내에서 발생하는 이 프로세스의 내부 루프를 설명하기 위해 "상황 내 학습"이라는 용어를 사용합니다. 이 다이어그램의 시퀀스는 사전 학습 중에 모델이 볼 수 있는 데이터를 나타내기 위한 것이 아니지만 때로는 단일 시퀀스 내에 반복되는 하위 작업이 포함되어 있음을 보여 주기 위한 것입니다.
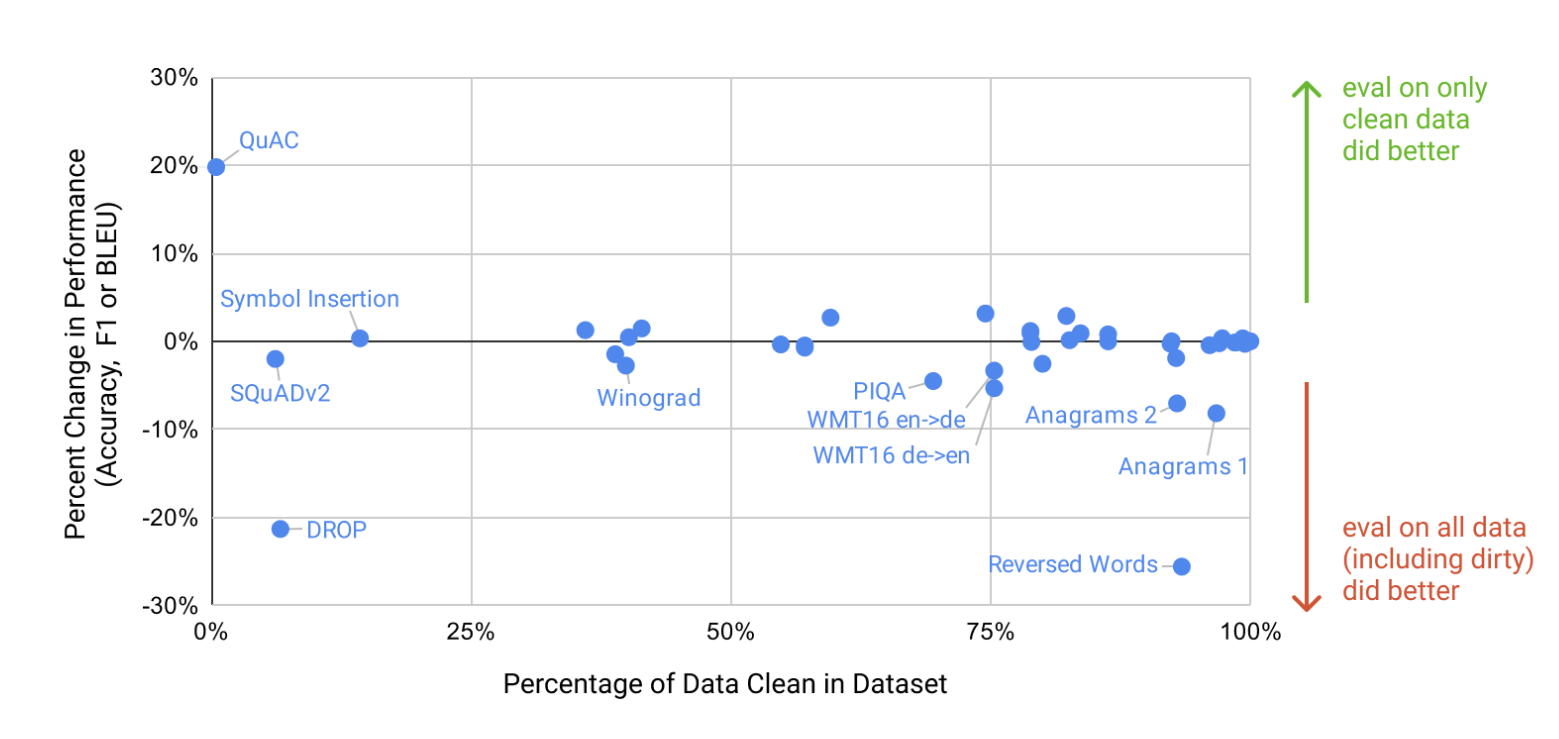
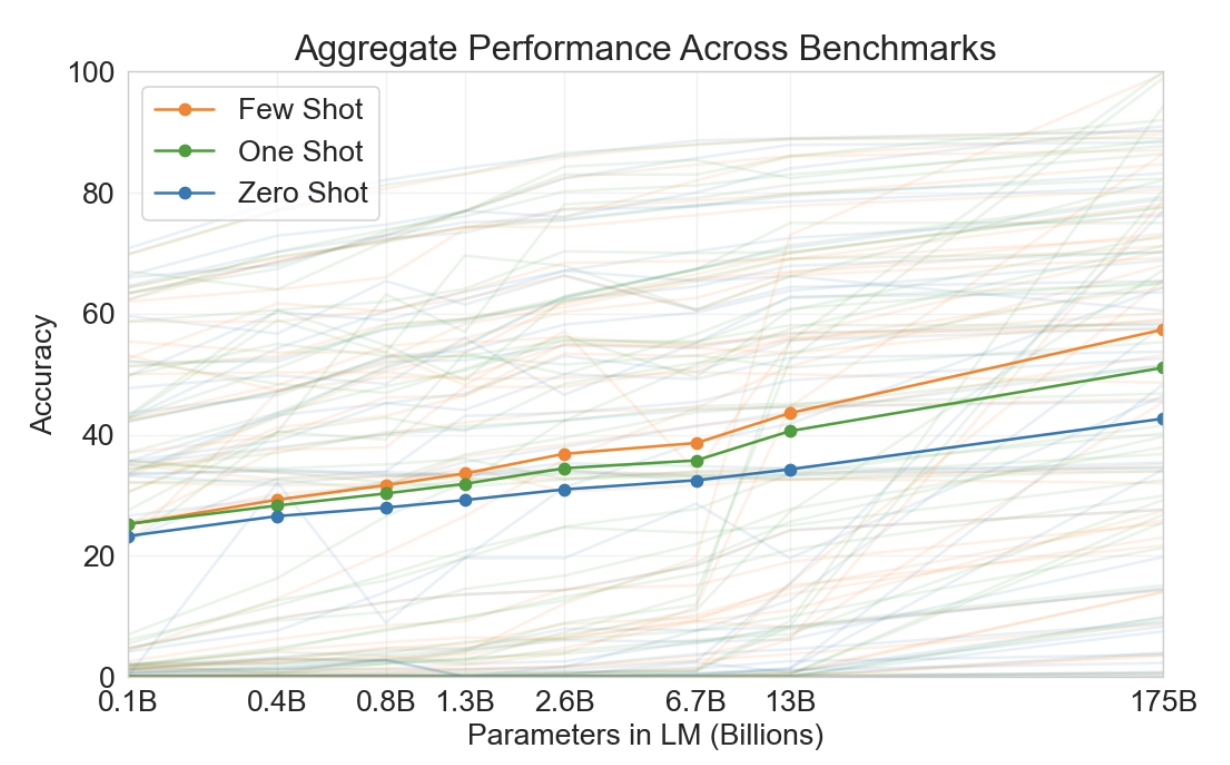
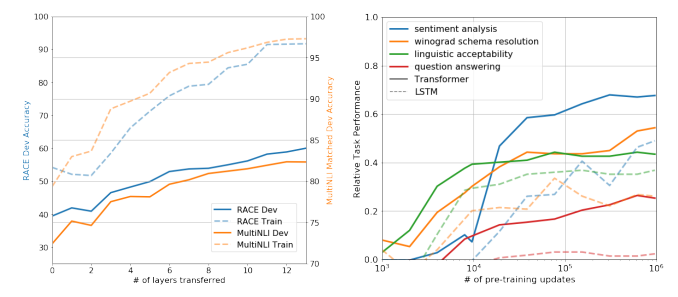
그림1.2 : Larger models make increasingly efficient use of in-context information. 자연어 작업 설명이 있든 없든 모델이 단어에서 임의의 기호를 제거해야 하는 간단한 작업에 대한 상황 내 학습 성능을 보여줍니다(섹션 3.9.2 참조). 대형 모델의 더 가파른 "상황 내 학습 곡선"은 상황 정보로부터 작업을 학습하는 향상된 능력을 보여줍니다. 우리는 광범위한 작업에서 질적으로 유사한 행동을 봅니다.
이러한 문제를 해결하기 위한 한 가지 잠재적 경로는 메타 학습입니다. 이는 언어 모델의 맥락에서 모델이 훈련 시간에 광범위한 기술과 패턴 인식 능력을 개발한 다음 추론 시간에 이러한 능력을 사용하여 신속하게 적응하거나 인식한다는 것을 의미합니다. 원하는 작업(그림 1.1 참조) 최근 연구 [RWC+19]는 사전 훈련된 언어 모델의 텍스트 입력을 작업 지정의 한 형태로 사용하여 "상황 내 학습"을 통해 이를 수행하려고 시도합니다. 모델은 자연어 명령 및/또는 작업에 대한 몇 가지 시연을 한 다음 다음에 무엇이 올지 예측함으로써 작업의 추가 인스턴스를 완료할 것으로 예상됩니다.
초기에는 어느 정도 가능성이 보였지만 이 접근 방식은 여전히 미세 조정보다 훨씬 낮은 결과를 달성합니다. 예를 들어 [RWC+19]는 Natural Question에서 4%만 달성했으며 심지어 55 F1 CoQa 결과도 이제 35포인트 이상 뒤처져 있습니다. 최첨단. 메타러닝이 언어 과제를 해결하는 실용적인 방법으로 실행 가능하려면 상당한 개선이 필요하다는 것은 분명합니다.
언어 모델링의 또 다른 최근 추세는 앞으로 나아갈 길을 제시할 수 있습니다. 최근 몇 년 동안 변환기 언어 모델의 용량은 1억 개의 매개변수[RNSS18]에서 3억 개의 매개변수[DCLT18], 15억 개의 매개변수[RWC+19], 80억 개의 매개변수[SPP+19]로 크게 증가했습니다. 110억 개의 매개변수[RSR+19], 마지막으로 170억 개의 매개변수[Tur20]입니다. 각 증가로 인해 텍스트 합성 및/또는 다운스트림 NLP 작업이 개선되었으며, 많은 다운스트림 작업과 잘 연관되는 로그 손실이 규모[KMH+20]에 따라 원활한 개선 추세를 따른다는 증거가 있습니다. 맥락 내 학습에는 모델의 매개변수 내에서 많은 기술과 과제를 흡수하는 것이 포함되므로 맥락 내 학습 능력은 규모에 따라 비슷하게 강력한 이득을 보여줄 수 있을 가능성이 높습니다.
그림1.3 : Aggregate performance for all 42 accuracy-denominated benchmarks. 제로 샷 성능은 모델 크기에 따라 꾸준히 향상되지만 소수 샷 성능은 더 빠르게 증가하여 더 큰 모델이 상황 내 학습에 더 능숙하다는 것을 보여줍니다. 표준 NLP 벤치마크 제품군인 SuperGLUE에 대한 자세한 분석은 그림 3.8을 참조하세요.
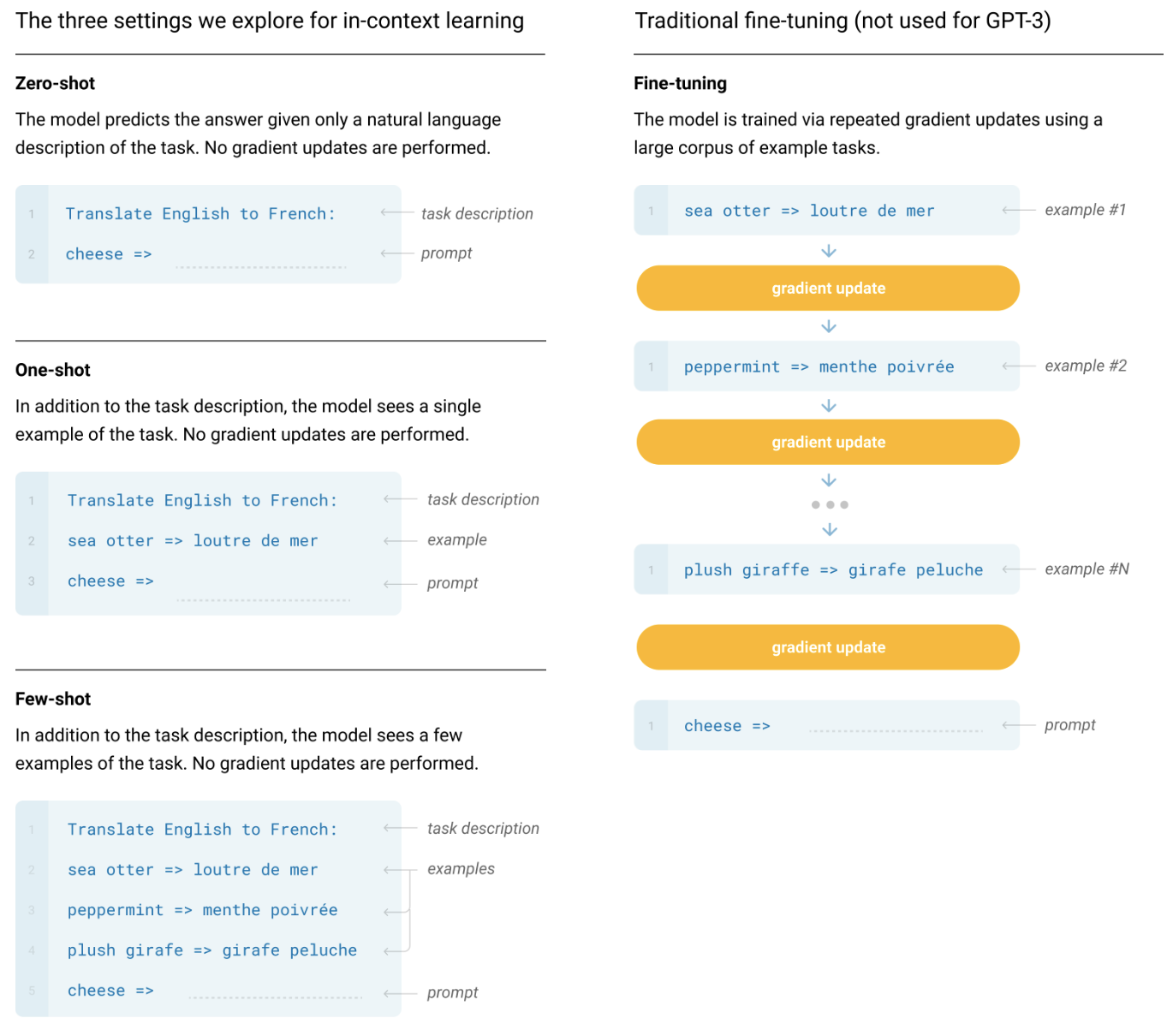
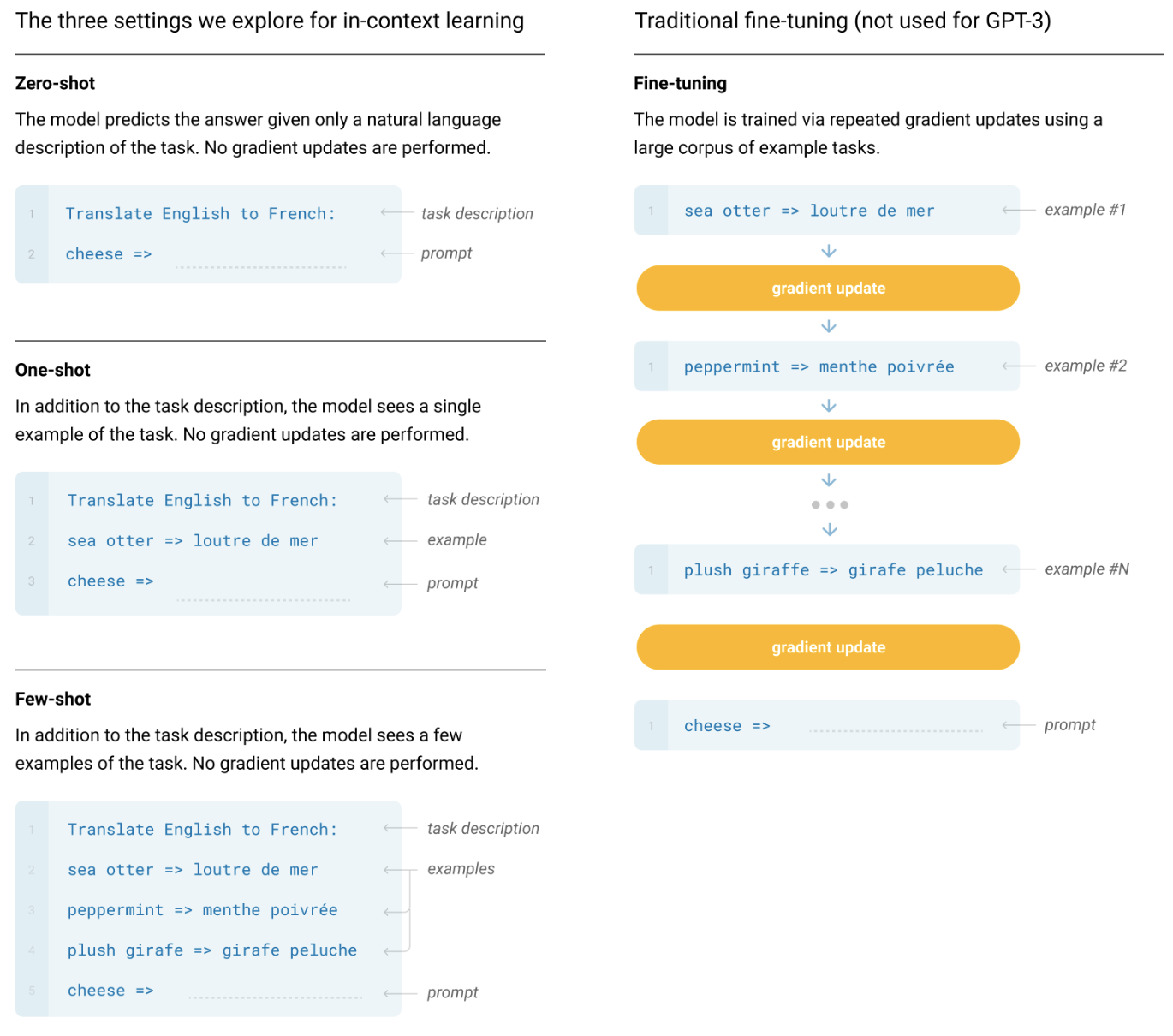
본 논문에서는 GPT-3라고 하는 1,750억 개의 매개변수 자동 회귀 언어 모델을 훈련하고 상황 내 학습 능력을 측정하여 이 가설을 테스트합니다. 구체적으로 우리는 훈련 세트에 직접 포함될 가능성이 없는 작업에 대한 신속한 적응을 테스트하기 위해 설계된 몇 가지 새로운 작업뿐만 아니라 20개가 넘는 NLP 데이터세트에 대해 GPT-3를 평가합니다. 각 작업에 대해 우리는 3가지 조건에서 GPT-3를 평가합니다.
(a) "몇 번의 학습" 또는 모델의 컨텍스트 창(일반적으로 10~100)에 맞는 만큼 많은 데모를 허용하는 상황 내 학습,
(b) 단 한 번의 시연만 허용하는 "원샷 학습" 및
(c) 시연이 허용되지 않고 모델에 자연어로 된 지침만 제공되는 "제로샷" 학습.
GPT-3은 원칙적으로 전통적인 미세 조정 설정에서도 평가할 수 있지만 이는 향후 작업에 맡깁니다.
그림 1.2는 우리가 연구한 조건을 보여주며 모델이 단어에서 관련 없는 기호를 제거해야 하는 간단한 작업에 대한 소수 학습을 보여줍니다. 자연어 작업 설명을 추가하면 모델 성능이 향상되고 모델 컨텍스트의 예제 수가 많아지면 K가 늘어납니다. Few-shot 학습도 모델 크기에 따라 크게 향상됩니다. 이 사례의 결과는 특히 놀랍지만 모델 크기와 상황 내 예제 수에 대한 일반적인 추세는 우리가 연구하는 대부분의 작업에 적용됩니다. 우리는 이러한 "학습" 곡선에는 기울기 업데이트나 미세 조정이 포함되지 않으며 단지 조건화로 제공되는 시연 횟수가 증가한다는 점을 강조합니다.
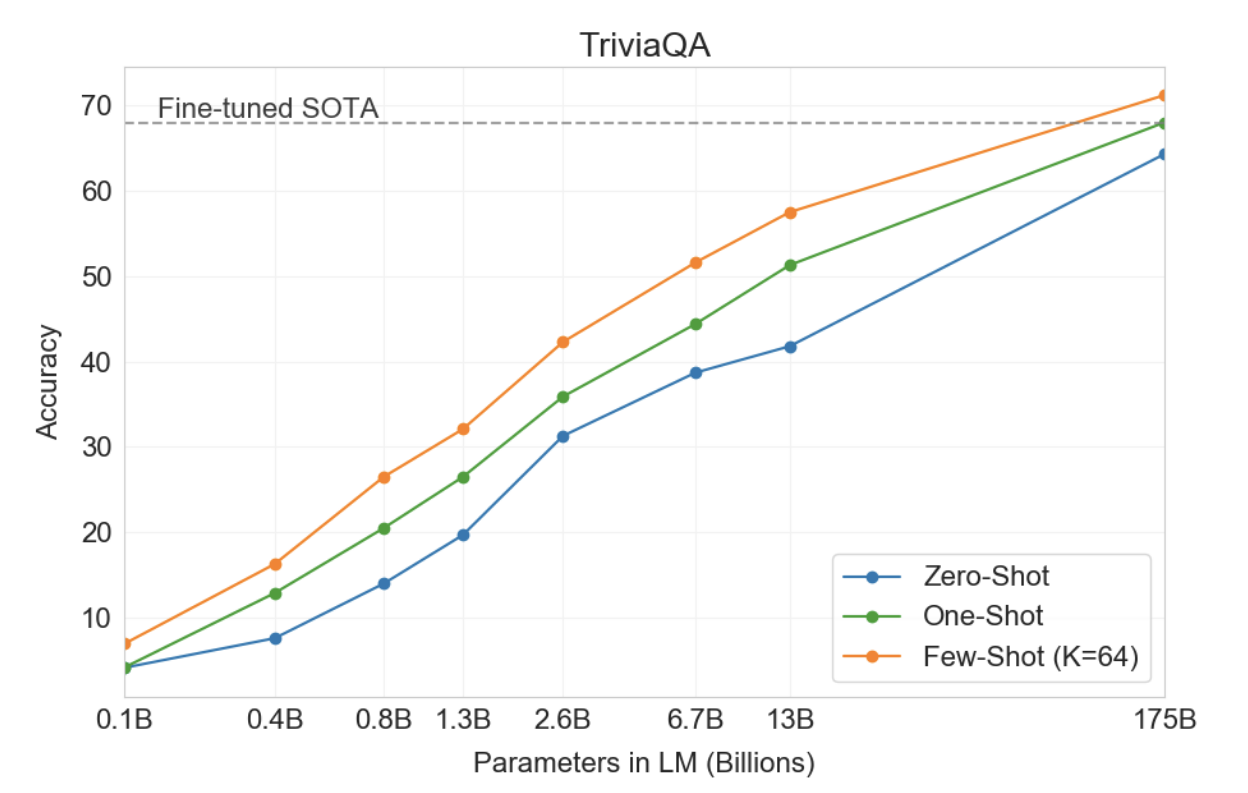
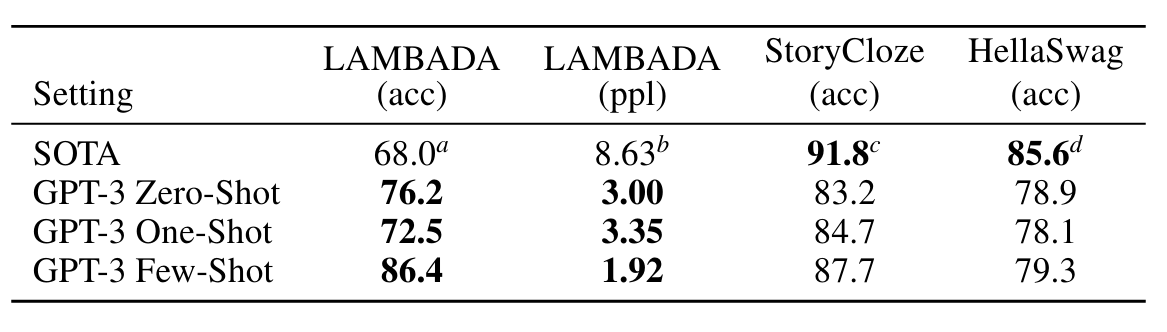
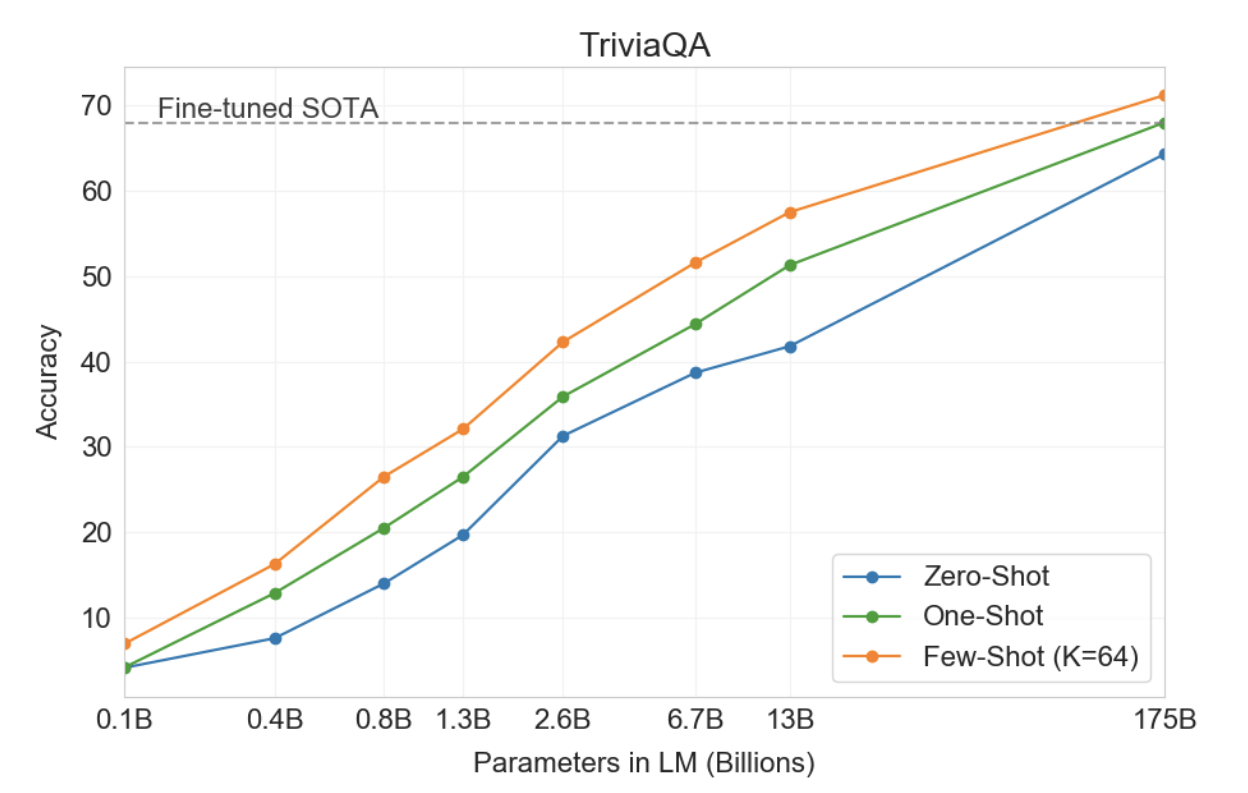
대체로 NLP 작업에서 GPT-3은 제로샷 및 원샷 설정에서 유망한 결과를 달성하고, 퓨샷 설정에서는 때로는 최첨단 기술과 경쟁하거나 때로는 능가하기도 합니다(SOTA가 유지되고 있음에도 불구하고). 미세 조정된 모델을 통해). 예를 들어, GPT-3는 제로샷 설정에서 CoQA에 대해 81.5 F1, 원샷 설정에서 CoQA에 대해 84.0 F1, 퓨샷 설정에서 85.0 F1을 달성합니다. 마찬가지로 GPT-3는 제로샷 설정에서 TriviaQA의 정확도 64.3%, 원샷 설정에서 68.0%, 소수 설정에서 71.2%의 정확도를 달성했으며, 그 중 마지막은 미세 조정된 모델 작동에 비해 SOTA입니다. 동일한 비공개 환경에서.
GPT-3는 또한 단어 풀기, 산술 수행, 한 번만 정의된 것을 본 후 문장에서 새로운 단어 사용 등 신속한 적응 또는 즉석 추론을 테스트하기 위해 설계된 작업에서 일회성 및 소수성 숙련도를 보여줍니다. 우리는 또한 몇 번의 샷 설정에서 GPT-3가 인간 평가자가 인간이 생성한 기사와 구별하기 어려운 합성 뉴스 기사를 생성할 수 있음을 보여줍니다.
동시에 GPT-3 규모에서도 Few-shot 성능이 어려움을 겪는 몇 가지 작업도 발견했습니다. 여기에는 ANLI 데이터 세트와 같은 자연어 추론 작업과 RACE 또는 QuAC와 같은 일부 독해 데이터 세트가 포함됩니다. 이러한 제한 사항을 포함하여 GPT-3의 강점과 약점에 대한 광범위한 특성을 제시함으로써 언어 모델에서 소수 학습에 대한 연구를 자극하고 진전이 가장 필요한 부분에 관심을 끌기를 바랍니다.
전체 결과에 대한 경험적 감각은 다양한 작업을 집계한 그림 1.3에서 볼 수 있습니다(단, 그 자체로 엄격하거나 의미 있는 벤치마크로 간주되어서는 안 됩니다).
또한 Common Crawl과 같은 데이터 세트에서 대용량 모델을 훈련할 때 점점 커지는 문제인 "데이터 오염"에 대한 체계적인 연구를 수행합니다. 이러한 콘텐츠는 단순히 웹에 종종 존재하기 때문에 테스트 데이터 세트의 콘텐츠를 잠재적으로 포함할 수 있습니다. 본 논문에서는 데이터 오염을 측정하고 왜곡 효과를 정량화하는 체계적인 도구를 개발합니다. 데이터 오염이 대부분의 데이터 세트에서 GPT-3 성능에 최소한의 영향을 미친다는 사실을 발견했지만 결과를 부풀릴 수 있는 몇 가지 데이터 세트를 식별하고 이러한 데이터 세트에 대한 결과를 보고하지 않거나 별표로 표시합니다. 심각도에 따라.
위의 모든 것 외에도 우리는 0회, 1회 및 몇 번의 샷 설정에서 성능을 GPT-3과 비교하기 위해 일련의 더 작은 모델(1억 2천 5백만 개의 매개변수에서 130억 개의 매개변수 범위)을 훈련합니다. 대체로 대부분의 작업에 대해 세 가지 설정 모두에서 모델 용량이 상대적으로 원활하게 확장되는 것을 발견했습니다. 주목할만한 패턴 중 하나는 0회, 1회, 소수의 성능 사이의 격차가 모델 용량에 따라 커지는 경우가 많다는 것입니다. 이는 아마도 더 큰 모델이 더 능숙한 메타 학습기임을 암시할 수 있습니다.
마지막으로 GPT-3가 보여주는 광범위한 역량을 고려하여 편견, 공정성 및 광범위한 사회적 영향에 대한 우려를 논의하고 이와 관련하여 GPT-3의 특성에 대한 예비 분석을 시도합니다.
본 논문의 나머지 부분은 다음과 같이 구성된다. 섹션 2에서는 GPT-3를 훈련하고 평가하는 접근 방식과 방법을 설명합니다. 섹션 3은 제로, 원샷, 퓨샷 설정의 전체 작업 범위에 대한 결과를 제시합니다. 섹션 4에서는 데이터 오염(트레인-테스트 중복) 문제를 다룹니다. 섹션 5에서는 GPT-3의 제한 사항에 대해 설명합니다. 섹션 6에서는 더 광범위한 영향을 논의합니다. 7장에서는 관련 작업을 검토하고 8장에서 결론을 내린다.
2. Approach
모델, 데이터, 교육을 포함한 기본 사전 교육 접근 방식은 [RWC+19]에 설명된 프로세스와 유사하며 모델 크기, 데이터 세트 크기 및 다양성, 교육 기간을 비교적 간단하게 확장할 수 있습니다. 상황 내 학습의 사용도 [RWC+19]와 유사하지만 이 작업에서는 상황 내 학습을 위한 다양한 설정을 체계적으로 탐색합니다. 따라서 우리는 GPT-3를 평가할 또는 원칙적으로 GPT-3를 평가할 수 있는 다양한 설정을 명시적으로 정의하고 대조함으로써 이 섹션을 시작합니다. 이러한 설정은 작업별 데이터에 얼마나 의존하는지에 대한 스펙트럼에 있는 것으로 볼 수 있습니다. 특히 이 스펙트럼에서 최소한 4개의 점을 식별할 수 있습니다(그림 2.1 참조).
FT(Fine-Tuning)는 최근 몇 년 동안 가장 일반적인 접근 방식이었으며, 원하는 작업과 관련된 지도 데이터 세트를 훈련하여 사전 훈련된 모델의 가중치를 업데이트하는 것과 관련됩니다. 일반적으로 수천에서 수십만 개의 레이블이 지정된 예제가 사용됩니다. 미세 조정의 가장 큰 장점은 많은 벤치마크에서 강력한 성능을 발휘한다는 것입니다. 주요 단점은 모든 작업에 대해 새로운 대규모 데이터 세트가 필요하고, 일반화가 불량할 가능성이 있고(MPL19), 훈련 데이터의 허위 기능을 활용할 가능성이 있다는 것[GSL+18, NK19]입니다. 인간의 성과와 불공평하게 비교됩니다. 이 작업에서는 작업에 구애받지 않는 성능에 중점을 두기 때문에 GPT-3를 미세 조정하지 않지만 GPT-3는 원칙적으로 미세 조정할 수 있으며 이는 향후 작업에 대한 유망한 방향입니다.
Few-Shot(FS)은 컨디셔닝[RWC+19]으로 추론 시 모델에 작업에 대한 몇 가지 시연이 제공되지만 가중치 업데이트는 허용되지 않는 설정을 참조하기 위해 이 작업에서 사용할 용어입니다.
그림 2.1에서 볼 수 있듯이 일반적인 데이터 세트의 예에는 컨텍스트와 원하는 완성(예: 영어 문장 및 프랑스어 번역)이 있으며, 몇 번의 작업으로 컨텍스트와 완성에 대한 K개의 예를 제공한 다음 하나의 최종 예를 제공합니다. 완성을 제공할 것으로 예상되는 모델과 함께 컨텍스트를 제공합니다. 모델의 컨텍스트 창(nctx = 2048)에 얼마나 많은 예제가 들어갈 수 있는지를 나타내기 때문에 일반적으로 K를 10~100 범위로 설정합니다. 퓨샷의 주요 장점은 작업별 데이터의 필요성이 크게 감소하고 크지만 좁은 미세 조정 데이터 세트에서 지나치게 좁은 분포를 학습할 가능성이 줄어든다는 것입니다. 가장 큰 단점은 이 방법의 결과가 지금까지 최첨단 미세 조정 모델보다 훨씬 나빴다는 것입니다. 또한 소량의 작업별 데이터가 여전히 필요합니다. 이름에서 알 수 있듯이 여기에 언어 모델에 대해 설명된 소수 학습은 ML의 다른 맥락에서 사용되는 소수 학습과 관련이 있습니다[HYC01, VBL+16]. 둘 다 광범위한 작업 배포를 기반으로 한 학습을 포함합니다( 이 경우 사전 훈련 데이터에 내재되어 있음) 그런 다음 새로운 작업에 빠르게 적응합니다.
One-Shot(1S)은 그림 1과 같이 작업에 대한 자연어 설명 외에 단 한 번의 데모만 허용된다는 점을 제외하면 Few-Shot과 동일합니다. 제로샷(아래)은 일부 작업이 인간에게 전달되는 방식과 가장 밀접하게 일치한다는 것입니다.
예를 들어 인간 작업자 서비스(예: Mechanical Turk)에 대한 데이터 세트를 생성하도록 인간에게 요청할 때 해당 작업에 대한 한 번의 시연을 제공하는 것이 일반적입니다. 대조적으로, 예시가 제공되지 않으면 작업의 내용이나 형식을 전달하는 것이 때로는 어렵습니다.
제로샷(0S)은 시연이 허용되지 않고 모델에 작업을 설명하는 자연어 지침만 제공된다는 점을 제외하면 원샷과 동일합니다. 이 방법은 최대의 편의성, 견고성 가능성 및 허위 상관관계 방지(큰 사전 학습 데이터 모음에서 매우 광범위하게 발생하지 않는 한)를 제공하지만 가장 어려운 설정이기도 합니다. 어떤 경우에는 사전 예 없이는 인간이 작업 형식을 이해하기 어려울 수도 있으므로 이 설정은 어떤 경우에는 "불공평하게 어렵습니다".
예를 들어, 누군가가 "200m 경주에 대한 세계 기록 표를 작성해 달라"고 요청받은 경우 이 요청은 모호할 수 있습니다. 표가 어떤 형식이어야 하는지, 무엇을 포함해야 하는지 명확하지 않을 수 있기 때문입니다. 설명, 원하는 것이 무엇인지 정확하게 이해하는 것이 어려울 수 있습니다.) 그럼에도 불구하고 적어도 일부 설정에서는 제로샷이 인간이 작업을 수행하는 방식과 가장 유사합니다. 예를 들어 그림 2.1의 번역 예에서 인간은 텍스트 명령만으로 무엇을 해야 할지 알 수 있습니다.
그림2.1 : Zero-shot, one-shot and few-shot, contrasted with traditional fine-tuning. 위의 패널은 언어 모델을 사용하여 작업을 수행하는 네 가지 방법을 보여줍니다. 미세 조정은 전통적인 방법인 반면, 이 작업에서 연구하는 제로샷, 원샷, 소수 샷에서는 모델이 작업을 수행해야 합니다. 테스트 시간에는 정방향 패스만 가능합니다. 우리는 일반적으로 몇 개의 샷 설정에서 수십 개의 예제를 모델에 제시합니다. 모든 작업 설명, 예시 및 프롬프트에 대한 정확한 문구는 부록 G에서 확인할 수 있습니다.
그림 2.1은 영어를 프랑스어로 번역하는 예를 사용하여 네 가지 방법을 보여줍니다. 이 논문에서 우리는 제로샷, 원샷, 퓨샷에 초점을 맞춰 이를 경쟁 대안으로 비교하는 것이 아니라 특정 벤치마크의 성능과 샘플 효율성 사이의 다양한 균형을 제공하는 다양한 문제 설정으로 비교하는 것을 목표로 합니다.
우리는 특히 소수의 결과를 강조합니다. 왜냐하면 그 중 다수가 최첨단 미세 조정 모델보다 약간 뒤처져 있기 때문입니다.
그러나 궁극적으로 원샷 또는 때로는 제로샷이 인간의 성과에 대한 가장 공정한 비교처럼 보이며 향후 작업의 중요한 목표입니다.
아래 섹션 2.1-2.3에서는 각각 모델, 교육 데이터 및 교육 프로세스에 대한 세부 정보를 제공합니다. 섹션 2.4에서는 퓨샷, 원샷 및 제로샷 평가를 수행하는 방법에 대해 자세히 설명합니다.
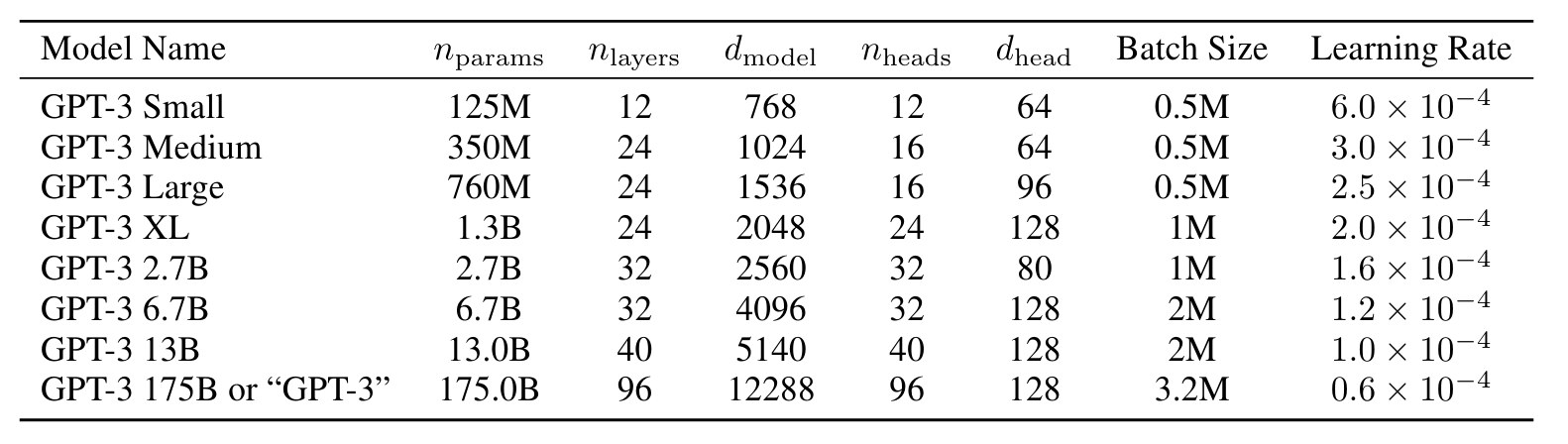
표2.1 : 우리가 훈련한 모델의 크기, 아키텍처 및 학습 하이퍼 매개변수(토큰의 배치 크기 및 학습 속도). 모든 모델은 총 3,000억 개의 토큰에 대해 학습되었습니다.
2.1 Model and Architectures
우리는 수정된 초기화, 사전 정규화 및 거기에 설명된 가역적 토큰화를 포함하여 GPT-2 [RWC+19]와 동일한 모델과 아키텍처를 사용합니다. Sparse Transformer [CGRS19]와 유사한 변환기. 모델 크기에 대한 ML 성능의 의존성을 연구하기 위해 우리는 1억 2,500만 개의 매개변수에서 1,750억 개의 매개변수까지 3배 이상의 8가지 크기의 모델을 훈련합니다. 마지막 매개변수는 GPT-3이라고 부르는 모델입니다. 이전 연구 [KMH+20]에서는 충분한 훈련 데이터를 사용하면 검증 손실의 스케일링이 크기 함수로서 대략적으로 매끄러운 거듭제곱 법칙이 되어야 한다고 제안합니다. 다양한 크기의 훈련 모델을 사용하면 검증 손실과 다운스트림 언어 작업 모두에 대해 이 가설을 테스트할 수 있습니다.
표 2.1은 8개 모델의 크기와 아키텍처를 보여줍니다. 여기서 nparams는 훈련 가능한 매개변수의 총 수이고, nlayers는 레이어의 총 수이며, dmodel은 각 병목 현상 레이어의 단위 수입니다(우리는 항상 병목 현상 레이어 크기의 4배인 피드포워드 레이어를 가집니다. dff = 4 * dmodel). dhead는 각 Attention Head의 차원입니다. 모든 모델은 nctx = 2048 토큰의 컨텍스트 창을 사용합니다. 노드 간 데이터 전송을 최소화하기 위해 깊이와 너비 차원을 따라 GPU 전체에 걸쳐 모델을 분할합니다. 각 모델의 정확한 아키텍처 매개변수는 GPU 전체 모델 레이아웃의 계산 효율성과 로드 밸런싱을 기반으로 선택됩니다. 이전 연구 [KMH+20]에서는 검증 손실이 합리적으로 넓은 범위 내에서 이러한 매개변수에 크게 민감하지 않다고 제안했습니다.
2.2 Training Dataset
언어 모델을 위한 데이터 세트는 빠르게 확장되어 거의 1조 단어로 구성된 Common Crawl 데이터 세트2[RSR+19]로 정점을 찍었습니다. 이 데이터 세트 크기는 동일한 시퀀스를 두 번 업데이트하지 않고도 가장 큰 모델을 교육하는 데 충분합니다. 그러나 필터링되지 않거나 가볍게 필터링된 일반 크롤링 버전은 선별된 데이터 세트보다 품질이 낮은 경향이 있는 것으로 나타났습니다. 따라서 우리는 데이터세트의 평균 품질을 개선하기 위해 다음과 같은 3가지 단계를 수행했습니다.
(1) 다양한 고품질 참조 말뭉치와의 유사성을 기반으로 CommonCrawl 버전을 다운로드하고 필터링했습니다.
(2) 중복을 방지하고 데이터 세트의 무결성을 유지하기 위해 데이터 세트 내 및 전체에서 문서 수준에서 퍼지 중복 제거를 수행했습니다. 과적합의 정확한 척도로 검증 세트를 유지했으며
(3) CommonCrawl을 강화하고 다양성을 높이기 위해 알려진 고품질 참조 말뭉치를 훈련 믹스에 추가했습니다.
처음 두 지점(공통 크롤링 처리)에 대한 자세한 내용은 부록 A에 설명되어 있습니다. 세 번째에는 링크를 스크랩하여 수집한 WebText 데이터세트[RWC+19]의 확장 버전을 포함하여 선별된 여러 고품질 데이터세트를 추가했습니다. 더 긴 기간이 소요되며 [KMH+20], 두 개의 인터넷 기반 서적 코퍼스(Books1 및 Books2)와 영어 Wikipedia에서 처음 설명되었습니다.
표 2.2는 훈련에 사용한 데이터 세트의 최종 혼합을 보여줍니다. CommonCrawl 데이터는 2016년부터 2019년까지 월별 CommonCrawl 샤드 41개에서 다운로드되었으며, 필터링 전 45TB, 필터링 후 570GB의 압축된 일반 텍스트로 구성되었으며, 이는 대략 4000억 바이트 쌍으로 인코딩된 토큰에 해당합니다. 학습 중에 데이터 세트는 크기에 비례하여 샘플링되지 않고 품질이 더 좋다고 판단되는 데이터 세트가 더 자주 샘플링됩니다. 예를 들어 CommonCrawl 및 Books2 데이터 세트는 학습 중에 한 번 미만으로 샘플링되지만 다른 데이터 세트는 2 -3번 샘플링됩니다. 이는 본질적으로 더 높은 품질의 훈련 데이터를 제공하는 대가로 소량의 과적합을 허용합니다.
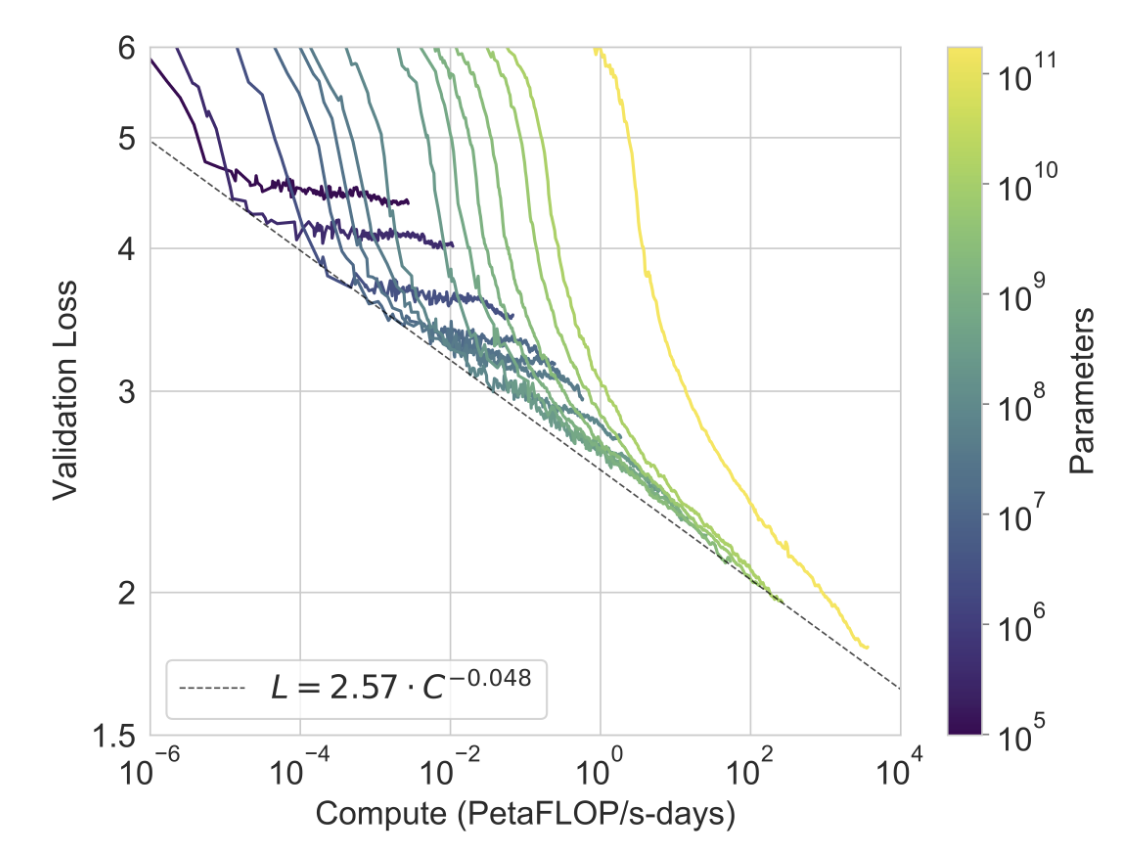
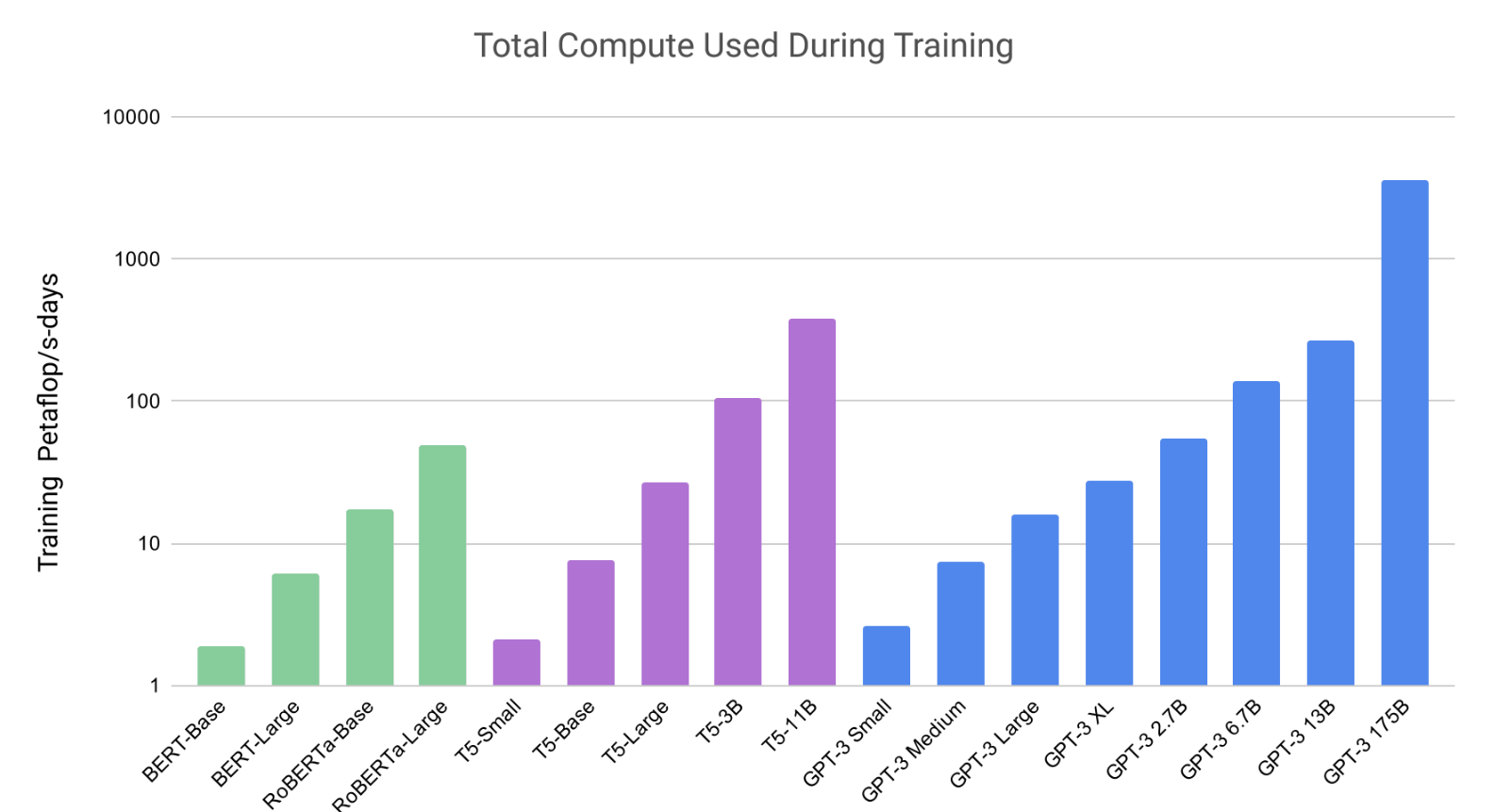
그림2.2 : Total compute used during training. 신경 언어 모델에 대한 확장 법칙[KMH+20]의 분석을 기반으로 우리는 일반적인 것보다 훨씬 적은 토큰으로 훨씬 더 큰 모델을 훈련합니다. 결과적으로 GPT-3 3B는 RoBERTa-Large(355M 매개변수)보다 거의 10배 더 크지만 두 모델 모두 사전 학습 중에 약 50페타플롭/s-일의 컴퓨팅을 사용했습니다. 이러한 계산 방법은 부록 D에서 확인할 수 있습니다.
표2.2 : Datasets used to train GPT-3. "훈련 믹스의 가중치"는 주어진 데이터 세트에서 추출된 훈련 중 예시의 비율을 의미하며 의도적으로 데이터 세트의 크기에 비례하지 않습니다. 결과적으로 3,000억 개의 토큰을 훈련할 때 일부 데이터 세트는 훈련 중에 최대 3.4회 표시되는 반면 다른 데이터 세트는 1회 미만으로 표시됩니다.
광범위한 인터넷 데이터에 대해 사전 학습된 언어 모델, 특히 방대한 양의 콘텐츠를 기억할 수 있는 용량을 갖춘 대규모 모델에 대한 주요 방법론적 우려 사항은 사전 학습 중에 테스트 또는 개발 세트가 실수로 표시되어 다운스트림 작업이 오염될 수 있다는 것입니다. 이러한 오염을 줄이기 위해 우리는 이 문서에서 연구된 모든 벤치마크의 개발 및 테스트 세트와 중복되는 부분을 검색하고 제거하려고 시도했습니다.
불행히도 필터링의 버그로 인해 일부 중복을 무시할 수 있었고 훈련 비용으로 인해 모델을 재훈련하는 것이 불가능했습니다. 섹션 4에서는 나머지 중복의 영향을 특성화하고 향후 작업에서는 데이터 오염을 보다 적극적으로 제거할 것입니다.
2.3 Training Process
[KMH+20, MKAT18]에서 볼 수 있듯이 더 큰 모델은 일반적으로 더 큰 배치 크기를 사용할 수 있지만 더 작은 학습 속도가 필요합니다. 훈련 중에 그래디언트 노이즈 스케일을 측정하고 이를 사용하여 배치 크기 선택을 안내합니다[MKAT18]. 표 2.1은 우리가 사용한 매개변수 설정을 보여줍니다. 메모리 부족 없이 더 큰 모델을 훈련하기 위해 우리는 각 행렬 곱셈 내의 모델 병렬성과 네트워크 계층 전체의 모델 병렬성을 혼합하여 사용합니다. 모든 모델은 Microsoft에서 제공하는 고대역폭 클러스터의 일부인 V100 GPU에서 교육되었습니다. 훈련 과정과 하이퍼파라미터 설정에 대한 자세한 내용은 부록 B에 설명되어 있습니다.
2.4 Evaluation
퓨샷 학습의 경우 작업에 따라 1개 또는 2개의 줄바꿈으로 구분된 조건부로 해당 작업의 훈련 세트에서 K개의 예제를 무작위로 추출하여 평가 세트의 각 예제를 평가합니다. LAMBADA 및 Storycloze의 경우 지도 학습 세트가 없으므로 개발 세트에서 조건 예제를 추출하고 테스트 세트를 평가합니다. Winograd(SuperGLUE 버전이 아닌 원본)의 경우 데이터세트가 하나뿐이므로 여기에서 직접 조건 예제를 그립니다.
K는 0부터 모델의 컨텍스트 창에서 허용하는 최대값까지의 값이 될 수 있습니다. 이는 모든 모델에 대해 nctx = 2048이며 일반적으로 10~100개의 예시에 적합합니다. K 값이 클수록 일반적으로 더 좋지만 항상 더 좋은 것은 아니기 때문에 별도의 개발 세트와 테스트 세트를 사용할 수 있는 경우 개발 세트에서 몇 가지 K 값으로 실험한 다음 테스트 세트에서 가장 좋은 값을 실행합니다. 일부 작업(부록 G 참조)의 경우 데모 외에(또는 K = 0인 경우) 자연어 프롬프트도 사용합니다.
여러 옵션(객관식) 중에서 하나의 올바른 완성을 선택하는 작업에서 우리는 컨텍스트와 올바른 완성의 K개 예와 컨텍스트만의 예 1개를 제공하고 각 완료의 LM 가능성을 비교합니다. 대부분의 작업에 대해 토큰별 가능성을 비교하지만(길이에 대해 정규화하기 위해) 소수의 데이터 세트(ARC, OpenBookQA 및 RACE)에서는 각 작업의 무조건 확률로 정규화하여 개발 세트에서 측정된 추가 이점을 얻습니다. "P(completion|context) /P(completion|answer_context)"를 계산하여 완료. 여기서 일반적으로 응답 컨텍스트는 "Answer: " 또는 "A: " 문자열이고 완료가 응답이어야 하지만 그렇지 않은 경우 프롬프트에 사용됩니다.
이진 분류와 관련된 작업에서는 의미상 더 의미 있는 이름(예: 0이나 1이 아닌 "True" 또는 "False")을 옵션에 부여한 다음 작업을 객관식처럼 처리합니다. 또한 자세한 내용은 [RSR+19](부록 G 참조)에서 수행되는 작업과 유사한 작업을 구성하는 경우도 있습니다.
자유 형식 완성 작업에서는 [RSR+19]와 동일한 매개변수(빔 너비 4 및 길이 페널티 α = 0.6)를 사용하여 빔 검색을 사용합니다. 현재 데이터 세트의 표준에 따라 F1 유사성 점수, BLEU 또는 완전 일치를 사용하여 모델의 점수를 매깁니다.
최종 결과는 각 모델 크기 및 학습 설정(0회, 1회 및 소수)에 대해 공개적으로 사용 가능한 테스트 세트에 보고됩니다. 테스트 세트가 비공개인 경우 모델이 너무 커서 테스트 서버에 맞지 않는 경우가 많으므로 개발 세트에 대한 결과를 보고합니다. 우리는 제출 작업을 수행할 수 있었던 소수의 데이터 세트(SuperGLUE, TriviaQA, PiQa)에 대해 테스트 서버에 제출하고 200B개의 소수 결과만 제출하고 다른 모든 것에 대한 개발 세트 결과를 보고합니다.
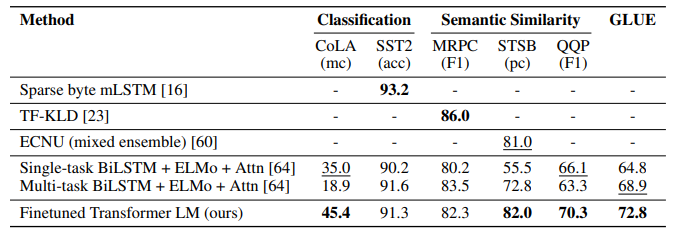
3 Results
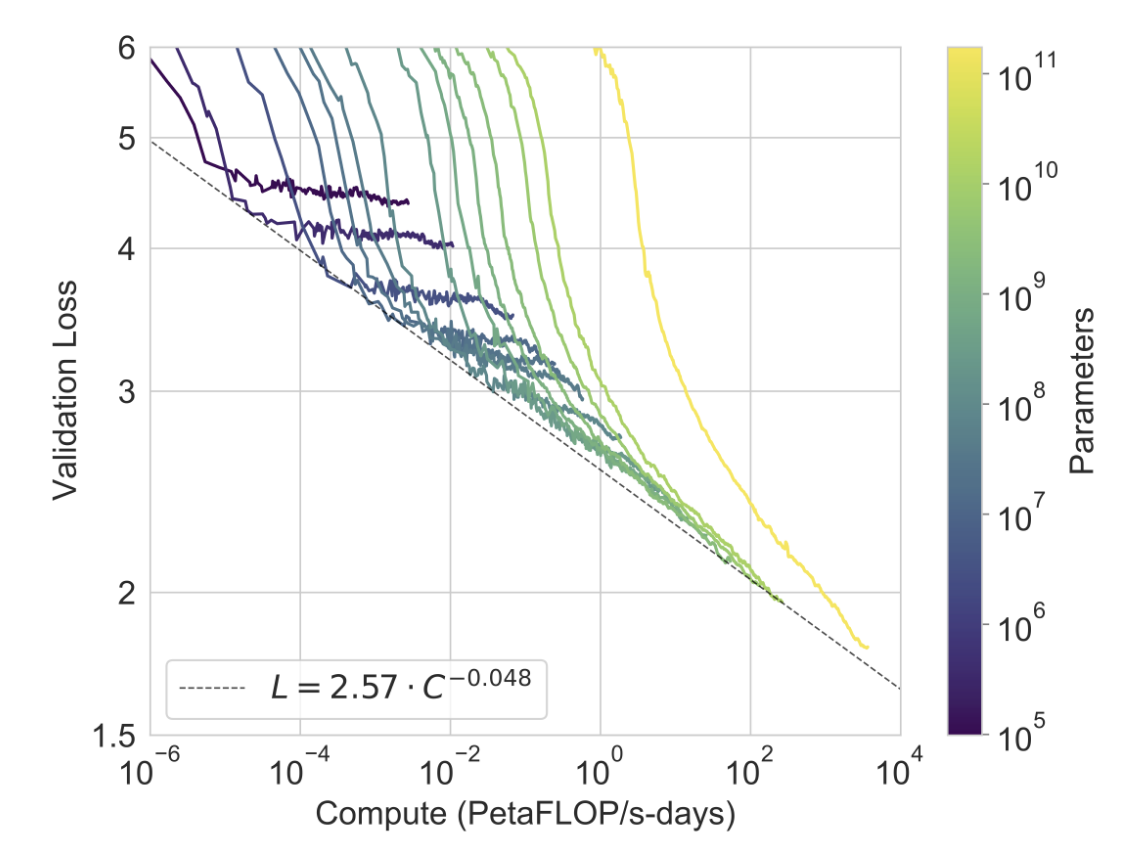
그림 3.1에는 섹션 2에서 설명한 8개 모델에 대한 훈련 곡선이 표시되어 있습니다. 이 그래프에는 매개변수가 100,000개에 불과한 6개의 추가 초소형 모델도 포함되어 있습니다. [KMH+20]에서 관찰된 바와 같이, 언어 모델링 성능은 훈련 계산을 효율적으로 사용할 때 거듭제곱 법칙을 따릅니다. 이 추세를 두 자릿수 더 확장한 후에는 거듭제곱 법칙에서 약간의 이탈(있는 경우)만 관찰됩니다. 교차 엔트로피 손실의 이러한 개선은 훈련 코퍼스의 허위 세부 사항을 모델링하는 것에서만 비롯된다는 점을 걱정할 수도 있습니다. 그러나 다음 섹션에서는 교차 엔트로피 손실의 개선이 광범위한 자연어 작업 전반에 걸쳐 일관된 성능 향상으로 이어진다는 것을 확인할 수 있습니다.
아래에서는 광범위한 데이터 세트에서 섹션 2에 설명된 8개 모델(1,750억 개의 매개변수 GPT-3 및 7개의 더 작은 모델)을 평가합니다. 우리는 데이터 세트를 대략 유사한 작업을 나타내는 9개의 범주로 그룹화합니다.
섹션 3.1에서는 전통적인 언어 모델링 작업과 Cloze 작업 및 문장/단락 완성 작업과 같이 언어 모델링과 유사한 작업을 평가합니다. 섹션 3.2에서는 일반 지식 질문에 대답하기 위해 모델의 매개변수에 저장된 정보를 사용해야 하는 "비공개" 질문 응답 작업을 평가합니다. 섹션 3.3에서는 모델의 언어 간 번역 능력(특히 원샷 및 퓨샷)을 평가합니다. 섹션 3.4에서는 Winograd 스키마와 유사한 작업에 대한 모델 성능을 평가합니다. 섹션 3.5에서는 상식적 추론이나 질문 답변과 관련된 데이터 세트를 평가합니다. 섹션 3.6에서는 독해 작업을 평가하고, 섹션 3.7에서는 SuperGLUE 벤치마크 제품군을 평가하며, 3.8에서는 NLI를 간략하게 살펴봅니다. 마지막으로 섹션 3.9에서는 상황 내 학습 능력을 조사하기 위해 특별히 고안된 몇 가지 추가 작업을 고안합니다. 이러한 작업은 즉석 추론, 적응 기술 또는 개방형 텍스트 합성에 중점을 둡니다. 퓨샷, 원샷, 제로샷 설정으로 모든 작업을 평가합니다.
그림3.1 : Smooth scaling of performance with compute. 성능(교차 엔트로피 검증 손실로 측정)은 훈련에 사용되는 컴퓨팅 양에 따른 거듭제곱 추세를 따릅니다. [KMH+20]에서 관찰된 멱법칙 동작은 예측 곡선과의 작은 편차만으로 추가로 2배 더 지속됩니다. 이 그림에서는 컴퓨팅 및 매개변수 수에서 임베딩 매개변수를 제외합니다.
표3.1 : Zero-shot results on PTB language modeling dataset. 다른 많은 공통 언어 모델링 데이터 세트는 Wikipedia 또는 GPT-3의 학습 데이터에 포함된 기타 소스에서 파생되었기 때문에 생략되었습니다. ^a[RWC+19]
3.1 Language Modeling, Cloze, and Completion Tasks
이 섹션에서는 언어 모델링이라는 전통적인 작업에 대한 GPT-3의 성능뿐만 아니라 관심 있는 단일 단어 예측, 문장 또는 단락 완성, 텍스트의 가능한 완성 중에서 선택과 관련된 작업도 테스트합니다.
3.1.1 Language Modeling
[RWC+19]에서 측정된 Penn Tree Bank(PTB) [MKM+94] 데이터 세트에서 제로 샷 혼란을 계산합니다. 우리는 훈련 데이터에 완전히 포함되어 있기 때문에 해당 작업에서 4개의 Wikipedia 관련 작업을 생략하고, 훈련 세트에 포함된 데이터 세트의 높은 부분으로 인해 10억 단어 벤치마크도 생략했습니다. PTB는 현대 인터넷보다 앞서서 이러한 문제를 피합니다. 우리의 가장 큰 모델은 PTB에 새로운 SOTA를 15포인트의 상당한 차이로 설정하여 20.50의 당혹도를 달성했습니다. PTB는 전통적인 언어 모델링 데이터세트이기 때문에 원샷 또는 퓨샷 평가를 정의하기 위한 예시가 명확하게 구분되어 있지 않으므로 제로샷만 측정합니다.
3.1.2 LAMBADA
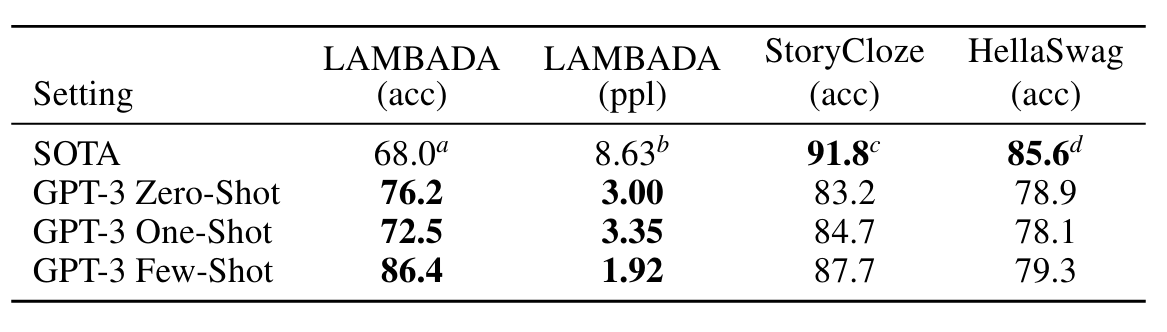
LAMBADA 데이터 세트 [PKL+16]는 텍스트의 장거리 종속성 모델링을 테스트합니다. 모델은 문맥 단락을 읽어야 하는 문장의 마지막 단어를 예측하도록 요청받습니다. 최근에는 언어 모델의 지속적인 확장으로 인해 이 어려운 벤치마크에서 수익이 감소하고 있다는 주장이 제기되었습니다. [BHT+20]은 최근 두 최신 결과([SPP+19] 및 [Tur20]) 사이의 모델 크기를 두 배로 늘려 달성한 작은 1.5% 개선을 반영하고 "하드웨어 및 데이터 크기를 계속해서 확장하고 있습니다. 규모는 앞으로 나아갈 길이 아닙니다.” 우리는 그 경로가 여전히 유망하다는 것을 알았고 제로 샷 설정에서 GPT-3는 LAMBADA에서 76%를 달성했으며 이는 이전 기술 수준에 비해 8%의 이득입니다.
표3.2 : Performance on cloze and completion tasks. GPT-3는 LAMBADA의 SOTA를 크게 개선하는 동시에 두 가지 어려운 완료 예측 데이터 세트에서 상당한 성능을 달성했습니다.
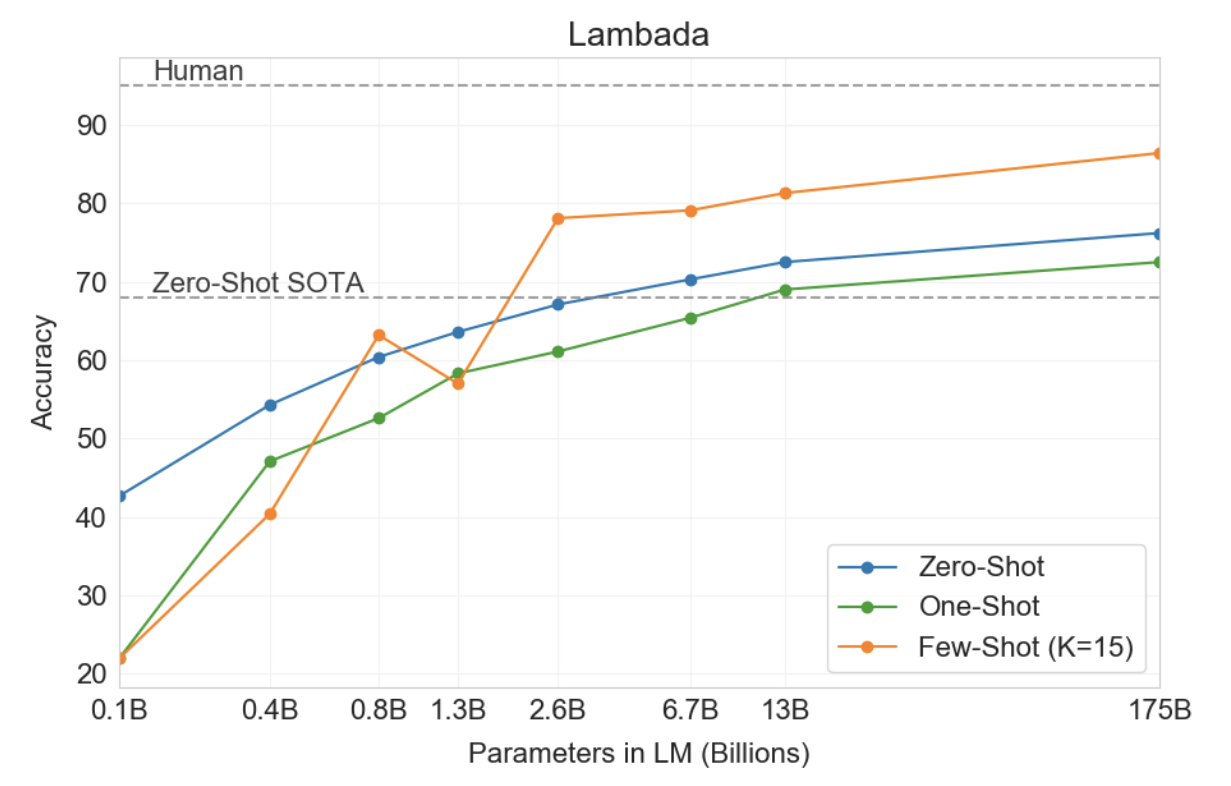
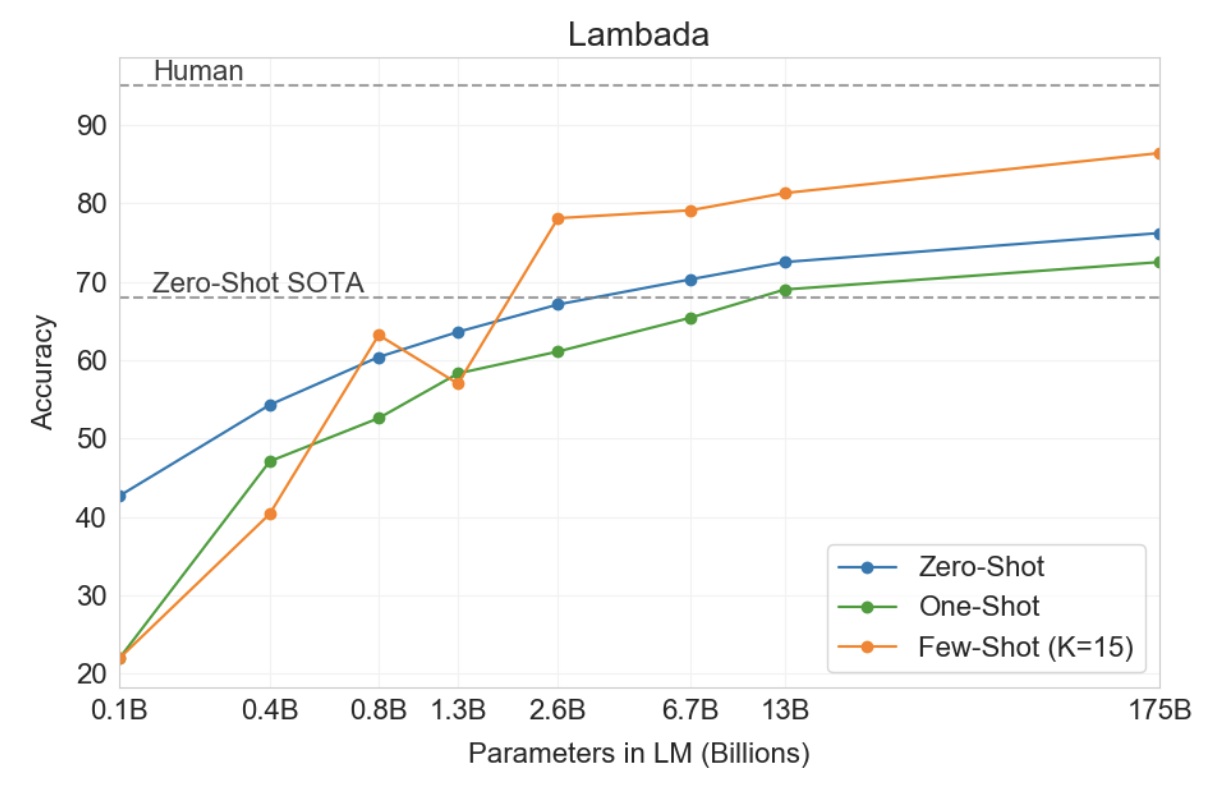
그림3.2 : LAMBADA에서는 언어 모델의 몇 번의 샷 기능으로 인해 정확성이 크게 향상되었습니다. GPT-3 2.7B는 이 설정에서 SOTA 17B 매개변수 Turing-NLG [Tur20]보다 성능이 뛰어나며 GPT-3 175B는 최신 기술을 18% 향상시킵니다. 참고로 제로샷은 본문에 설명된 대로 원샷 및 퓨샷과 다른 형식을 사용합니다.
LAMBADA는 또한 이 데이터 세트에서 일반적으로 발생하는 문제를 해결하는 방법을 제공하므로 소수 학습의 유연성을 보여줍니다. LAMBADA의 완성은 항상 문장의 마지막 단어이지만 표준 언어 모델은 이 세부 사항을 알 수 없습니다. 따라서 올바른 결말뿐만 아니라 단락의 다른 유효한 연속에도 확률을 할당합니다. 이 문제는 과거에 불용어 필터[RWC+19]("연속" 단어를 금지함)를 통해 부분적으로 해결되었습니다. 대신 Few-Shot 설정을 사용하면 작업을 클로즈 테스트로 "구성"할 수 있으며 언어 모델이 예제에서 정확히 한 단어의 완성이 필요하다는 것을 추론할 수 있습니다. 우리는 다음과 같은 빈칸 채우기 형식을 사용합니다.
이러한 방식으로 형식화된 예제를 제시할 때 GPT-3는 Few-Shot 설정에서 이전 최첨단 기술보다 18% 이상 향상된 86.4%의 정확도를 달성합니다. 모델 크기에 따라 소수의 샷 성능이 크게 향상되는 것을 관찰했습니다. 이 설정은 가장 작은 모델의 성능을 거의 20% 감소시키는 반면, GPT-3의 경우 정확도를 10% 향상시킵니다. 마지막으로, 공백 채우기 방법은 효과적인 원샷이 아니며 항상 제로샷 설정보다 성능이 나쁩니다. 아마도 이는 모든 모델이 패턴을 인식하기 위해 여전히 여러 가지 예를 요구하기 때문일 것입니다.
표3.3 : Results on three Open-Domain QA tasks. GPT-3은 비공개 도서 및 공개 도메인 설정에 대한 이전 SOTA 결과와 비교하여 소수, 원샷 및 제로샷 설정으로 표시됩니다. TriviaQA 퓨샷 결과는 위키 분할 테스트 서버에서 평가됩니다.
한 가지 주의할 점은 테스트 세트 오염 분석을 통해 LAMBADA 데이터 세트의 상당수가 훈련 데이터에 존재하는 것으로 확인되었다는 점입니다. 그러나 섹션 4에서 수행된 분석에서는 성능에 미미한 영향을 미치는 것으로 나타났습니다.
3.1.3 HellaSwag
HellaSwag 데이터 세트 [ZHB+19]에는 스토리 또는 지침 세트에 대한 최상의 결말을 선택하는 작업이 포함됩니다. 예제는 인간(95.6% 정확도 달성)에게는 쉽게 유지하면서 언어 모델에서는 어렵게 만들기 위해 적대적으로 채굴되었습니다.
GPT-3는 원샷 설정에서 78.1%의 정확도, 퓨샷 설정에서 79.3%의 정확도를 달성하여 미세 조정된 1.5B 매개변수 언어 모델[ZHR+19]의 75.4% 정확도를 능가하지만 여전히 상당히 낮습니다. 이는 미세 조정된 다중 작업 모델 ALUM이 달성한 전체 SOTA 85.6%보다 높습니다.
3.1.4 StoryCloze
다음으로 StoryCloze 2016 데이터 세트 [MCH+16]에서 GPT-3을 평가합니다. 여기에는 5문장짜리 긴 이야기에 대한 올바른 결말 문장을 선택하는 작업이 포함됩니다. 여기서 GPT-3는 제로샷 설정에서 83.2%, 퓨샷 설정(K = 70)에서 87.7%를 달성했습니다. 이는 BERT 기반 모델[LDL19]을 사용하여 미세 조정된 SOTA보다 여전히 4.1% 낮지만 이전 제로 샷 결과에 비해 약 10% 향상됩니다.
3.2 Closed Book Question Answering
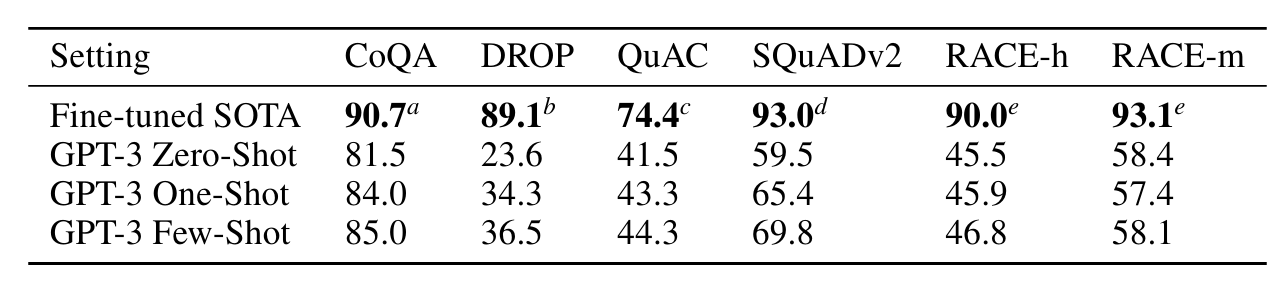
이 섹션에서는 광범위한 사실 지식에 대한 질문에 답하는 GPT-3의 능력을 측정합니다. 가능한 쿼리의 양이 엄청나게 많기 때문에 이 작업은 일반적으로 질문과 검색된 텍스트에 대해 답변을 생성하는 방법을 학습하는 모델과 함께 관련 텍스트를 찾기 위해 정보 검색 시스템을 사용하여 접근되었습니다. 이 설정을 사용하면 시스템이 잠재적으로 답변이 포함된 텍스트를 검색하고 조건을 지정할 수 있으므로 "오픈북"이라고 표시됩니다. [RRS20]은 최근 대규모 언어 모델이 보조 정보에 대한 조건 없이 질문에 직접 답하는 데 놀라울 정도로 잘 수행될 수 있음을 보여주었습니다. 그들은 이 보다 제한적인 평가 설정을 "비공개"라고 표시합니다. 그들의 연구는 더 높은 용량의 모델이 더 나은 성능을 발휘할 수 있음을 시사하며 우리는 이 가설을 GPT-3으로 테스트합니다. 우리는 동일한 분할을 사용하여 [RRS20]의 3개 데이터 세트인 Natural Question[KPR+19], WebQuestions[BCFL13] 및 TriviaQA[JCWZ17]에서 GPT-3를 평가합니다. 모든 결과가 비공개로 설정되는 것 외에도 퓨샷, 원샷 및 제로샷 평가 사용은 이전의 비공개 북 QA 작업보다 훨씬 더 엄격한 설정을 나타냅니다. 외부 콘텐츠가 허용되지 않는 것 외에도 Q&A 데이터 세트 자체에 대한 미세 조정도 허용되지 않습니다.
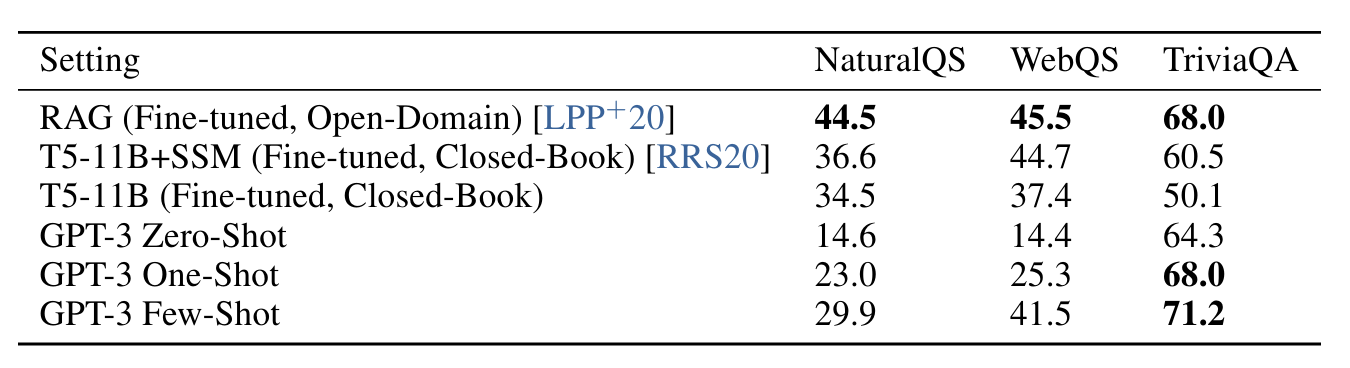
GPT-3에 대한 결과는 표 3.3에 나와 있습니다. TriviaQA에서는 제로샷 설정에서 64.3%, 원샷 설정에서 68.0%, 퓨샷 설정에서 71.2%를 달성했습니다. 제로샷 결과는 이미 미세 조정된 T5-11B보다 14.2% 더 뛰어나고, 사전 훈련 중 Q&A 맞춤형 범위 예측 버전보다 3.8% 더 뛰어납니다. 일회성 결과는 3.7% 향상되었으며 미세 조정뿐만 아니라 21M 문서의 15.3B 매개변수 밀도 벡터 인덱스에 대해 학습된 검색 메커니즘을 사용하는 개방형 도메인 QA 시스템의 SOTA와 일치합니다[LPP+20 ].
GPT-3의 Few-shot 결과는 이를 넘어 3.2% 더 성능을 향상시킵니다.
WebQuestions(WebQs)에서 GPT-3는 제로샷 설정에서 14.4%, 원샷 설정에서 25.3%, 퓨샷 설정에서 41.5%를 달성했습니다. 이는 미세 조정된 T5-11B의 경우 37.4%, Q&A별 사전 훈련 절차를 사용하는 미세 조정된 T5-11B+SSM의 경우 44.7%와 비교됩니다. Few-shot 설정의 GPT-3은 최첨단 미세 조정 모델의 성능에 접근합니다. 특히 TriviaQA와 비교하여 WebQS는 제로샷에서 퓨샷까지 훨씬 더 큰 이득을 보여줍니다(실제로 제로샷 및 원샷 성능이 좋지 않음). 이는 아마도 WebQs 질문 및/또는 답변 스타일을 암시할 수 있습니다. GPT-3에는 배포되지 않습니다. 그럼에도 불구하고 GPT-3는 이러한 분포에 적응할 수 있는 것으로 보이며 몇 장의 샷 설정에서 강력한 성능을 회복합니다.
그림3.3 : TriviaQA에서 GPT3의 성능은 모델 크기에 따라 원활하게 증가하며, 이는 언어 모델이 용량이 증가함에 따라 계속해서 지식을 흡수함을 시사합니다. 원샷 및 퓨샷 성능은 제로샷 동작에 비해 상당한 이점을 제공하며 SOTA 미세 조정 개방형 도메인 모델인 RAG [LPP+20]의 성능과 일치하거나 이를 능가합니다.
NQs(Natural Question)에서 GPT-3는 제로샷 설정에서 14.6%, 원샷 설정에서 23.0%, 퓨샷 설정에서 29.9%를 달성한 반면, 미세 조정된 T5 11B+SSM의 경우 36.6%를 달성했습니다. WebQS와 유사하게, 제로 샷에서 퓨 샷으로의 큰 이득은 배포 변화를 암시할 수 있으며 TriviaQA 및 WebQS에 비해 경쟁력이 떨어지는 성능을 설명할 수도 있습니다. 특히 NQ의 질문은 특히 GPT-3의 용량 및 광범위한 사전 훈련 분포의 한계를 테스트할 수 있는 Wikipedia에 대한 매우 세분화된 지식에 대한 경향이 있습니다.
전반적으로 세 가지 데이터 세트 중 하나에서 GPT-3의 원샷은 개방형 도메인 미세 조정 SOTA와 일치합니다. 다른 두 데이터 세트에서는 미세 조정을 사용하지 않음에도 불구하고 폐쇄형 SOTA의 성능에 접근합니다. 3개 데이터세트 모두에서 모델 크기에 따라 성능이 매우 원활하게 확장되는 것을 발견했습니다(그림 3.3 및 부록 H 그림 H.7). 이는 모델 용량이 모델 매개변수에 흡수된 더 많은 '지식'으로 직접 변환된다는 아이디어를 반영할 수 있습니다.
3.3 Translation
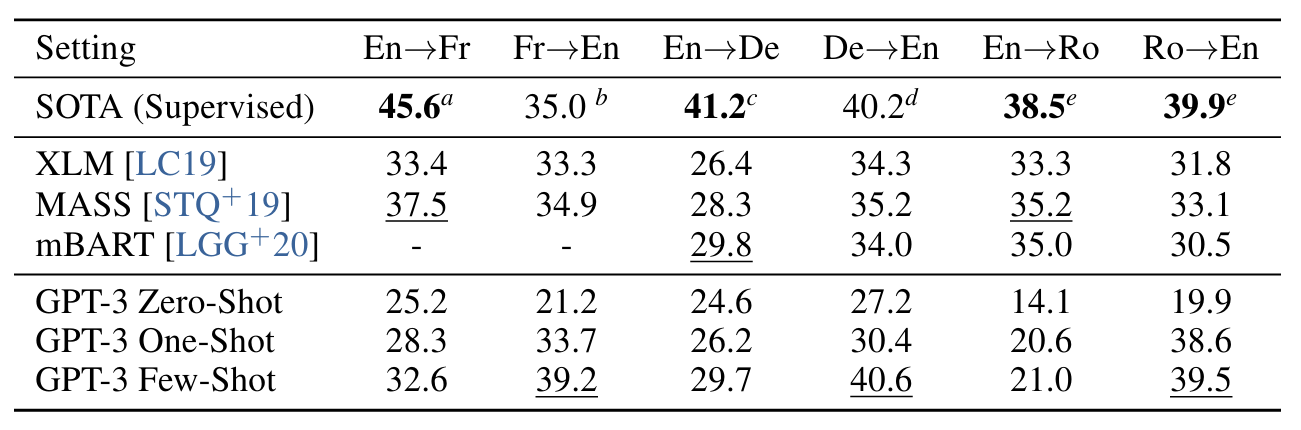
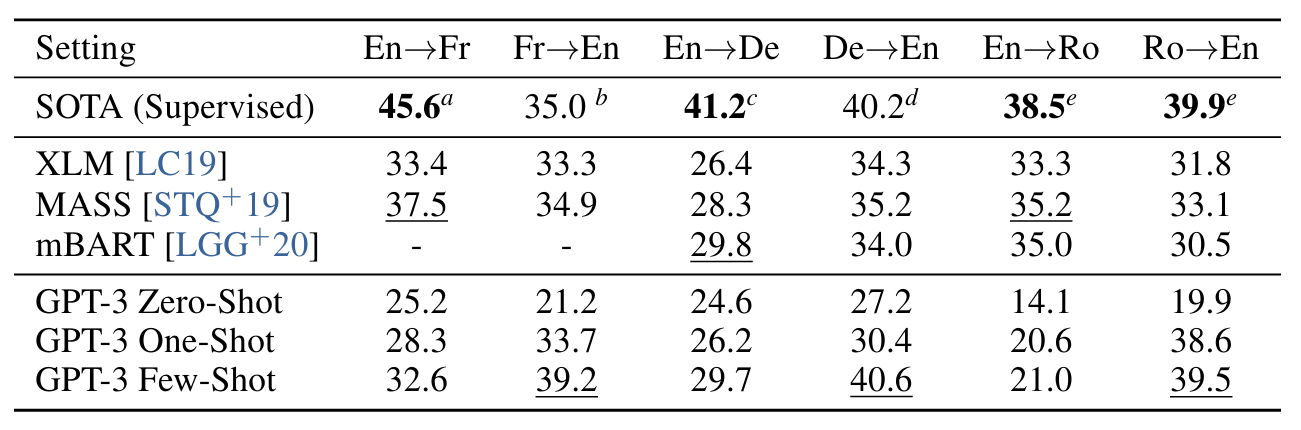
GPT-2의 경우 용량 문제로 인해 영어 전용 데이터 세트를 생성하기 위해 다국어 문서 모음에 필터가 사용되었습니다. 이러한 필터링에도 불구하고 GPT-2는 다국어 기능의 일부 증거를 보여주었으며 남은 프랑스어 텍스트 10MB에 대해서만 훈련했음에도 불구하고 프랑스어와 영어 간 번역 시 적지 않게 수행되었습니다. GPT-2에서 GPT-3으로 용량을 2배 이상 늘리기 때문에 다른 언어에 대한 더 많은 표현을 포함하도록 훈련 데이터 세트의 범위도 확장하지만 이는 여전히 추가 개선이 필요한 영역입니다. 2.2에서 설명한 대로 데이터의 대부분은 품질 기반 필터링만 사용하여 원시 일반 크롤링에서 파생됩니다. GPT-3의 훈련 데이터는 여전히 주로 영어(단어 수 기준 93%)이지만, 다른 언어로 된 텍스트도 7% 포함되어 있습니다. 이러한 언어는 보충 자료에 문서화되어 있습니다. 번역 기능을 더 잘 이해하기 위해 우리는 또한 일반적으로 연구되는 두 가지 추가 언어인 독일어와 루마니아어를 포함하도록 분석을 확장합니다.
기존의 비지도 기계 번역 접근 방식은 종종 한 쌍의 단일 언어 데이터 세트에 대한 사전 훈련과 역번역[SHB15]을 결합하여 두 언어를 제어된 방식으로 연결합니다. 이와 대조적으로 GPT-3는 여러 언어를 자연스럽게 혼합하여 단어, 문장 및 문서 수준에서 결합하는 혼합 학습 데이터를 통해 학습합니다. GPT-3은 또한 특정 작업에 맞게 맞춤화되거나 설계되지 않은 단일 훈련 목표를 사용합니다. 그러나 우리의 원샷/몇 샷 설정은 적은 양의 쌍을 이루는 예제(1 또는 64)를 사용하기 때문에 이전의 감독되지 않은 작업과 엄격하게 비교할 수 없습니다. 이는 상황 내 학습 데이터의 최대 한두 페이지에 해당합니다.
결과는 표 3.4에 나와 있습니다. 작업에 대한 자연어 설명만 수신하는 제로샷 GPT-3은 최근 감독되지 않은 NMT 결과보다 성능이 여전히 낮습니다. 그러나 각 번역 작업에 대해 하나의 예제 데모만 제공하면 7 BLEU 이상의 성능이 향상되고 이전 작업에 비해 경쟁력 있는 성능에 가까워집니다. 전체 몇 샷 설정의 GPT-3은 또 다른 4개의 BLEU를 더욱 향상시켜 이전의 감독되지 않은 NMT 작업과 비슷한 평균 성능을 제공합니다. GPT-3은 언어 방향에 따라 성능이 눈에 띄게 왜곡됩니다. 연구된 세 가지 입력 언어의 경우 GPT-3는 영어로 번역할 때 이전의 감독되지 않은 NMT 작업보다 훨씬 뛰어난 성능을 보였지만 다른 방향으로 번역할 때는 성능이 낮았습니다. En-Ro의 성능은 이전의 감독되지 않은 NMT 작업보다 10 BLEU가 넘는 눈에 띄는 이상치입니다. 이는 거의 전적으로 영어 교육 데이터세트용으로 개발된 GPT-2의 바이트 수준 BPE 토크나이저를 재사용하기 때문에 약점이 될 수 있습니다. Fr-En과 De-En 모두에서 GPT-3의 소수 샷은 우리가 찾을 수 있는 최고의 지도 결과보다 성능이 뛰어났지만 문헌에 대한 익숙하지 않고 이것이 경쟁적이지 않은 벤치마크인 것처럼 보이기 때문에 이러한 결과가 진정한 SOTA를 나타내는 것으로 의심되지 않습니다.
Ro-En의 경우 GPT-3는 전체 SOTA의 0.5 BLEU 내에서 수행되는 샷이 거의 없습니다. 이는 감독되지 않은 사전 훈련, 608K 레이블이 지정된 예제에 대한 감독된 미세 조정 및 역번역 [LHCG19b]의 조합을 통해 달성됩니다.
표3.4 : Few-shot GPT-3는 영어 LM으로서의 강점을 반영하여 영어로 번역할 때 이전의 감독되지 않은 NMT 작업보다 5 BLEU 성능이 뛰어납니다. 이전의 감독되지 않은 데이터와 가장 밀접하게 비교하기 위해 XLM의 토큰화를 사용하여 multi-bleu.perl로 측정한 WMT'14 Fr‐En, WMT'16 De‐En 및 WMT'16 Ro‐En 데이터 세트에 대한 BLEU 점수를 보고합니다. NMT 작업입니다. SacreBLEUf [Pos18] 결과는 부록 H에 보고되어 있습니다. 밑줄은 비지도 또는 퓨샷 SOTA를 나타내고, 굵은 글씨는 상대적 신뢰도가 있는 감독 SOTA를 나타냅니다. a[EOAG18] b[DHKH14] c[WXH+18] d[oR16] e[LGG+20] f [SacreBLEU signature: LEU+case.mixed+numrefs.1+smooth.exp+tok.intl+version.1.2.20]
그림3.4 : 모델 용량이 증가함에 따라 6개 언어 쌍에 대한 퓨샷 번역 성능이 향상됩니다. 모델이 확장됨에 따라 모든 데이터 세트에서 일관된 개선 추세가 나타나고 영어 번역이 영어 번역보다 더 강한 경향이 있습니다.
표3.5 : Winograd 스키마의 WSC273 버전과 적대적인 Winogrande 데이터 세트에 대한 결과입니다. Winograd 테스트 세트의 잠재적인 오염에 대한 자세한 내용은 섹션 4를 참조하십시오. a[SBBC19] b[LYN+20]
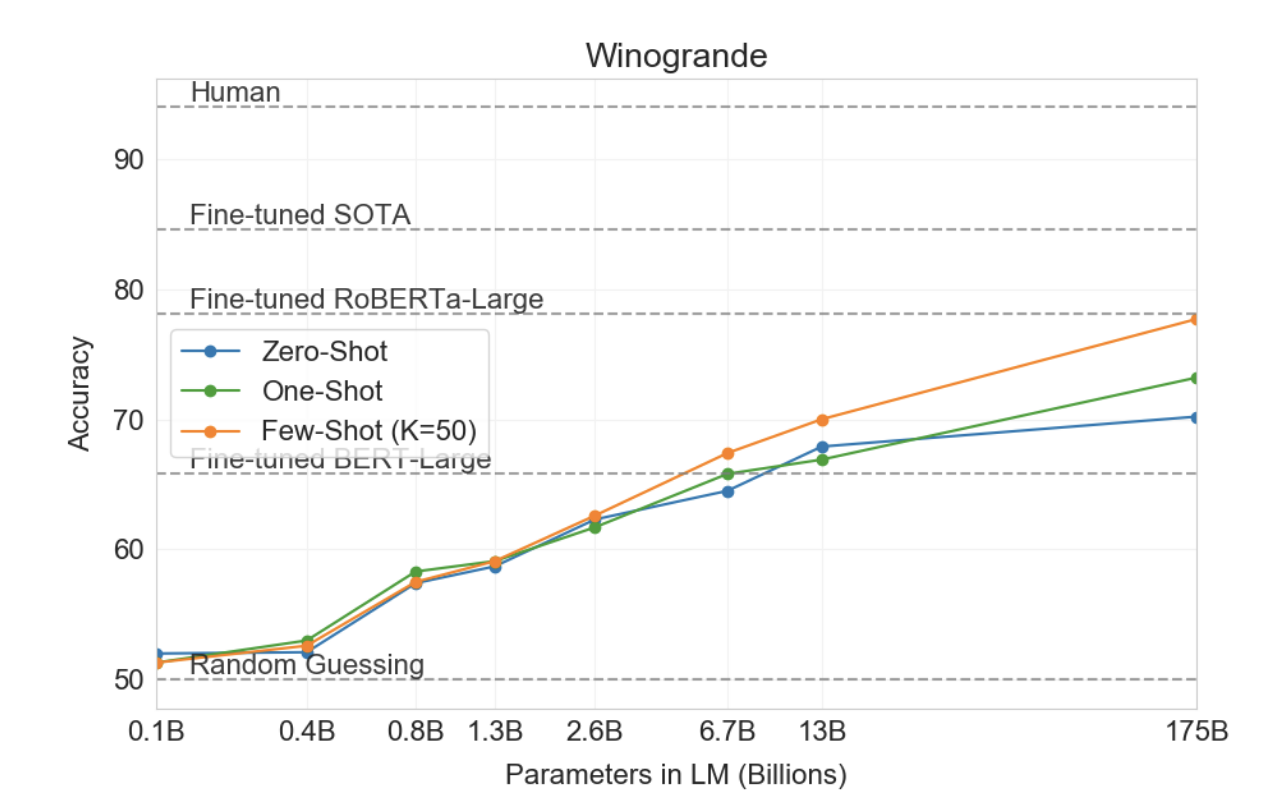
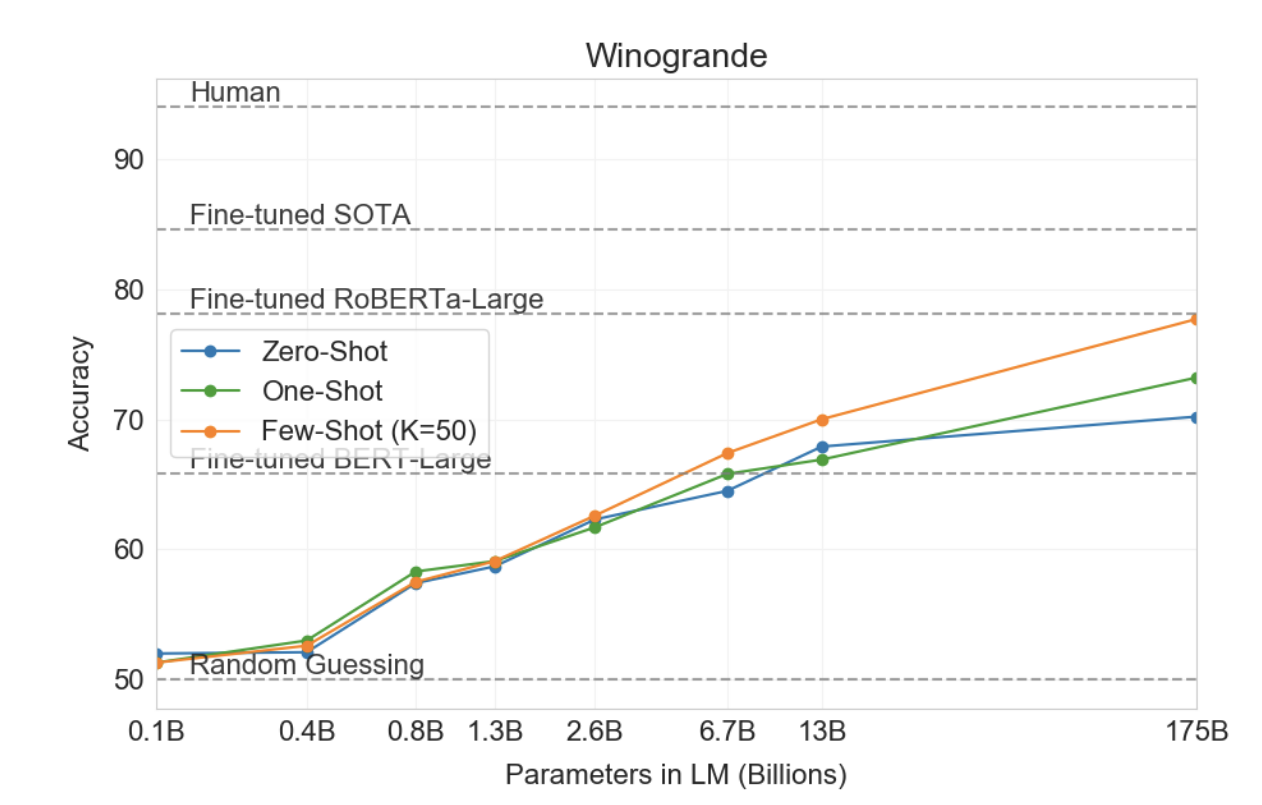
그림3.5 : 모델 용량이 확장됨에 따라 적대적인 Winogrande 데이터세트에 대한 제로, 원, 퓨샷 성능. 모델 크기에 따라 소수 샷 학습의 이점이 증가하여 스케일링이 상대적으로 원활하며 소수 샷 GPT-3 175B는 미세 조정된 RoBERTA-large와 경쟁적입니다.
마지막으로 모든 언어 쌍과 세 가지 설정(제로, 원샷, 소수) 전체에서 모델 용량이 원활하게 개선되는 추세입니다. 이는 소수 샷 결과의 경우 그림 3.4에 나와 있으며 세 가지 설정 모두에 대한 스케일링은 부록 H에 나와 있습니다.
3.4 Winograd-Style Tasks
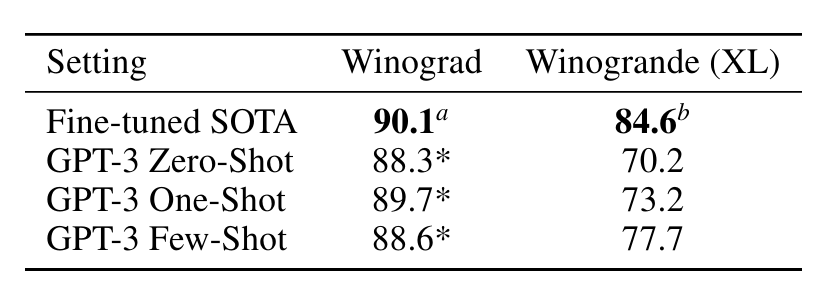
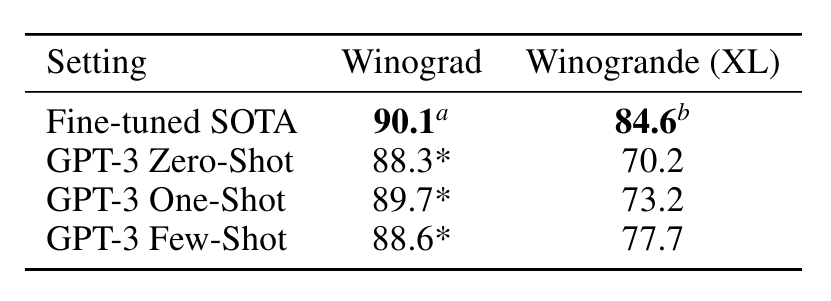
Winograd Schemas Challenge [LDM12]는 대명사가 문법적으로는 모호하지만 의미상으로는 인간에게 명확할 때 대명사가 가리키는 단어를 결정하는 것과 관련된 NLP의 고전적인 작업입니다. 최근 미세 조정된 언어 모델은 원본 Winograd 데이터 세트에서 인간에 가까운 성능을 달성했지만, 적대적으로 채굴된 Winogrande 데이터 세트[SBBC19]와 같은 더 어려운 버전은 여전히 인간 성능에 크게 뒤떨어져 있습니다. 평소와 같이 0회, 1회, 소수 설정에서 Winograd와 Winogrande 모두에서 GPT-3의 성능을 테스트합니다.
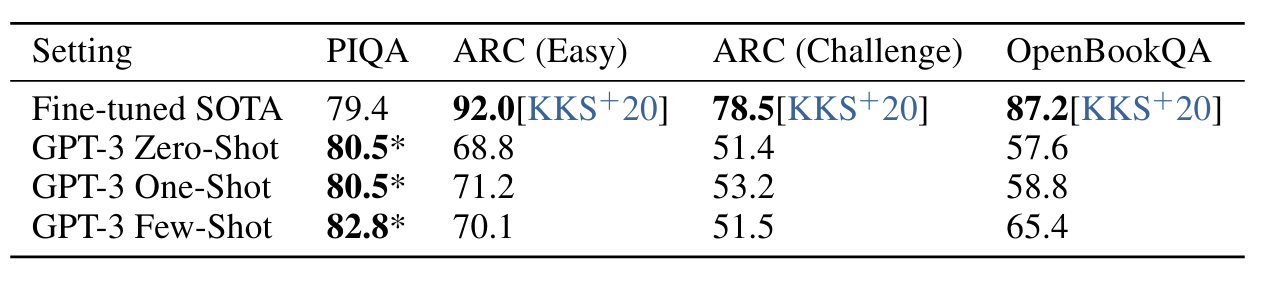
표3.6 : 세 가지 상식 추론 작업인 PIQA, ARC 및 OpenBookQA에 대해 설명합니다. GPT-3 Few-Shot PIQA 결과는 테스트 서버에서 평가됩니다. PIQA 테스트 세트의 잠재적인 오염 문제에 대한 자세한 내용은 섹션 4를 참조하십시오.
그림3.6 : 제로샷, 원샷, 퓨샷 설정의 PIQA에 대한 GPT-3 결과입니다. 가장 큰 모델은 세 가지 조건 모두에서 작업에 대해 기록된 최고 점수를 초과하는 개발 세트 점수를 달성합니다.
Winograd에서는 [RWC+19]에 설명된 것과 동일한 "부분 평가" 방법을 사용하여 원본 273개의 Winograd 스키마 세트에서 GPT-3를 테스트합니다. 이 설정은 이진 분류로 표시되고 이 섹션에 설명된 형식으로 변환하려면 엔터티 추출이 필요한 SuperGLUE 벤치마크의 WSC 작업과 약간 다릅니다. Winograd에서 GPT-3는 제로샷, 원샷 및 퓨샷 설정에서 88.3%, 89.7% 및 88.6%를 달성하여 명확한 상황 내 학습을 보여주지 않지만 모든 경우에 몇 가지 포인트 아래에서 강력한 결과를 달성합니다. 최첨단 및 추정 인간 성능. 오염 분석을 통해 훈련 데이터에서 일부 Winograd 스키마가 발견되었지만 이는 결과에 미미한 영향만 미치는 것으로 나타났습니다(섹션 4 참조).
더 어려운 Winogrande 데이터세트에서는 상황 내 학습의 이점을 발견했습니다. GPT-3는 제로샷 설정에서 70.2%, 원샷 설정에서 73.2%, 퓨샷 설정에서 77.7%를 달성했습니다. 비교를 위해 미세 조정된 RoBERTA 모델은 79%를 달성하고, 최첨단은 미세 조정된 고용량 모델(T5)을 사용하여 84.6%를 달성하며, [SBBC19]에서 보고된 작업에 대한 인간 성능은 94.0%입니다.
3.5 Common Sense Reasoning
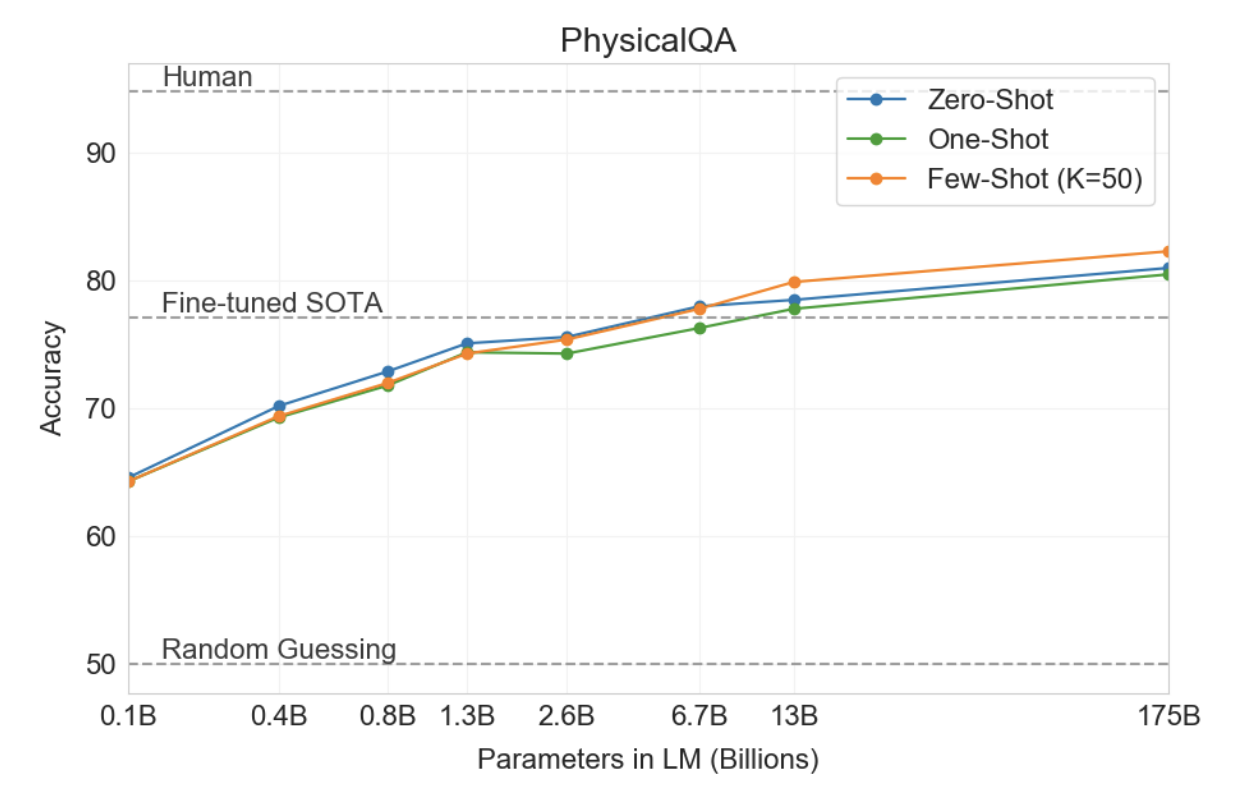
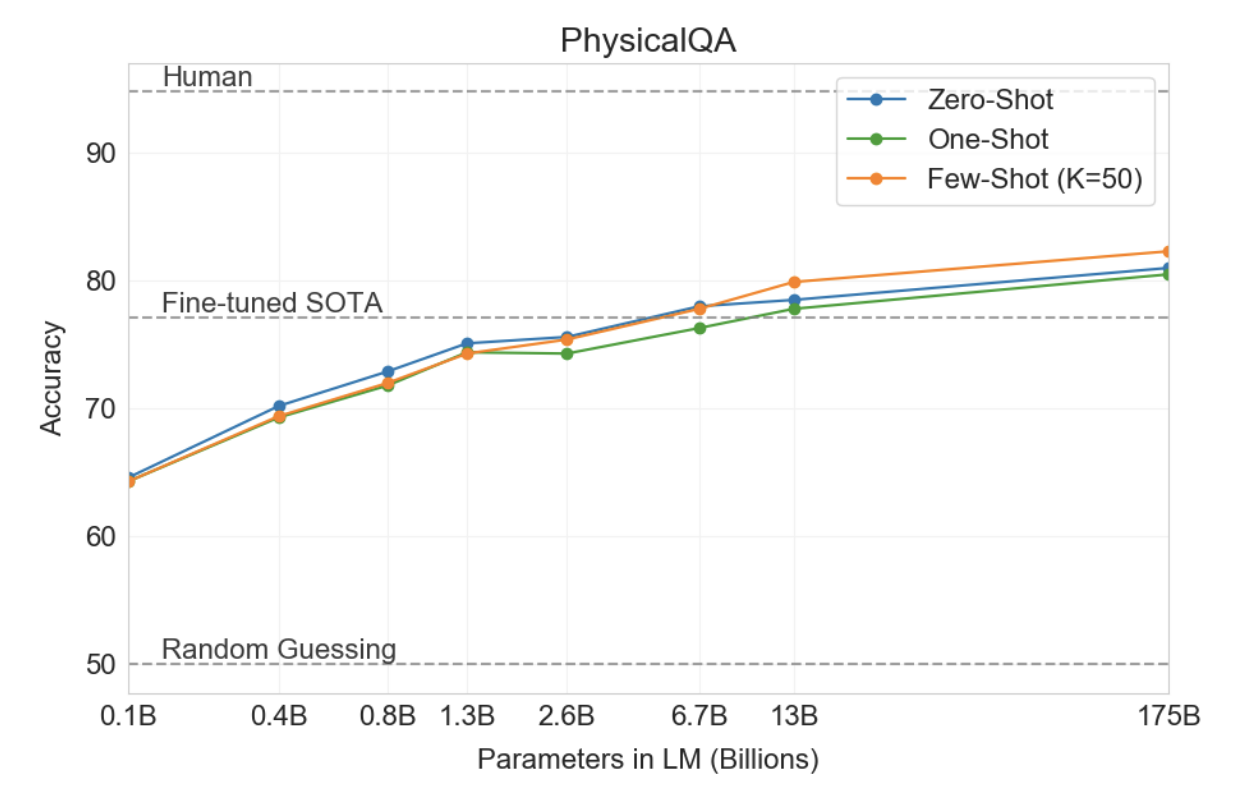
다음으로 우리는 문장 완성, 독해 또는 광범위한 지식 질문 답변과 구별되는 물리적 또는 과학적 추론을 포착하려고 시도하는 세 가지 데이터 세트를 고려합니다. 첫 번째인 PhysicalQA(PIQA) [BZB+19]는 물리적 세계가 어떻게 작동하는지에 대한 상식적인 질문을 하며 세계에 대한 기초적인 이해를 탐구하기 위한 것입니다. GPT-3는 제로샷 정확도 81.0%, 원샷 정확도 80.5%, 퓨샷 정확도 82.8%(PIQA 테스트 서버에서 마지막 측정)를 달성했습니다. 이는 미세 조정된 RoBERTa의 이전 최첨단 정확도 79.4%와 비교하면 좋습니다. PIQA는 모델 크기에 따라 상대적으로 얕은 스케일링을 보여 여전히 인간 성능보다 10% 이상 떨어지지만 GPT-3의 퓨샷, 심지어 제로샷 결과는 현재의 최첨단 성능을 능가합니다. 우리의 분석에서는 PIQA에 잠재적인 데이터 오염 문제(숨겨진 테스트 라벨에도 불구하고)가 표시되었으므로 결과를 보수적으로 별표로 표시했습니다. 자세한 내용은 섹션 4를 참조하세요.
표3.7 : 독해 과제 결과. 정확성을 보고하는 RACE 결과를 제외한 모든 점수는 F1입니다.
a[JZC+19] b[JN20] c[AI19] d[QIA20] e[SPP+19]
ARC [CCE+18]는 3~9학년 과학 시험에서 수집된 객관식 문제의 데이터세트입니다. 단순한 통계 또는 정보 검색 방법으로는 정확하게 답할 수 없는 질문으로 필터링된 데이터세트의 "챌린지" 버전에서 GPT-3는 제로샷 설정에서 51.4%의 정확도, 원샷 설정에서 53.2%의 정확도를 달성했습니다. 퓨샷 설정에서는 51.5%입니다. 이는 UniifiedQA[KKS+20]의 미세 조정된 RoBERTa 기준(55.9%) 성능에 접근하고 있습니다. 데이터 세트의 "Easy" 버전(언급된 기준 접근 방식 중 하나가 올바르게 대답한 질문)에서 GPT-3는 [KKS+20]의 미세 조정된 RoBERTa 기준을 약간 초과하는 68.8%, 71.2% 및 70.1%를 달성합니다. . 그러나 이 두 결과 모두 GPT-3의 몇 번의 샷 결과를 챌린지 세트에서 27%, 쉬운 세트에서 22% 초과하는 UniifiedQA가 달성한 전체 SOTA보다 여전히 훨씬 나쁩니다.
OpenBookQA [MCKS18]에서 GPT-3은 0에서 소수의 샷 설정으로 크게 향상되었지만 여전히 전체 SOTA보다 20포인트 이상 부족합니다. GPT-3의 퓨샷 성능은 리더보드의 미세 조정된 BERT Large 기준선과 유사합니다.
전반적으로 GPT-3을 사용한 상황 내 학습은 상식 추론 작업에서 혼합된 결과를 보여줍니다. PIQA와 ARC 모두에 대한 1회 및 몇 번의 학습 설정에서는 작고 일관되지 않은 이득만 관찰되었지만 OpenBookQA에서는 상당한 개선이 관찰되었습니다. GPT-3은 모든 평가 설정에서 새로운 PIQA 데이터 세트에 SOTA를 설정합니다.
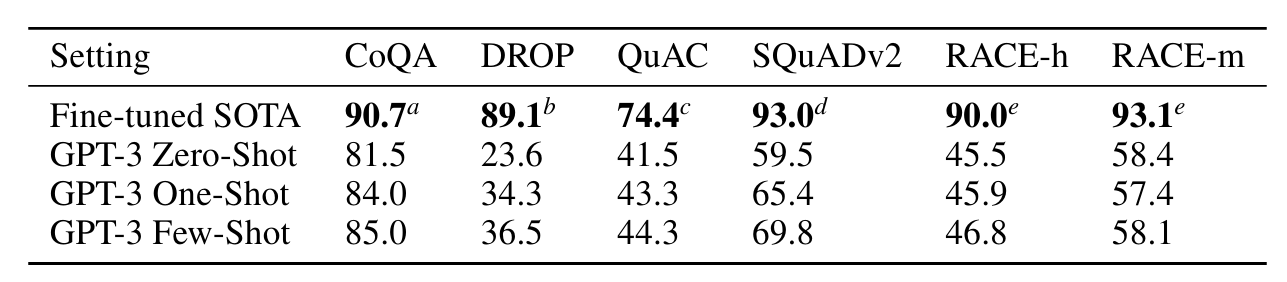
3.6 Reading Comprehension
다음으로 우리는 독해 작업에 관해 GPT-3를 평가합니다. 우리는 대화 및 단일 질문 설정 모두에서 추상형, 객관식 및 범위 기반 답변 형식을 포함한 5가지 데이터세트 모음을 사용합니다. 우리는 이러한 데이터 세트 전반에 걸쳐 GPT-3의 성능이 광범위하게 퍼져 있음을 관찰했는데, 이는 다양한 답변 형식의 다양한 기능을 암시합니다. 일반적으로 우리는 GPT-3가 초기 기준 및 각 데이터 세트에 대한 상황별 표현을 사용하여 훈련된 초기 결과와 동등하다는 것을 관찰합니다.
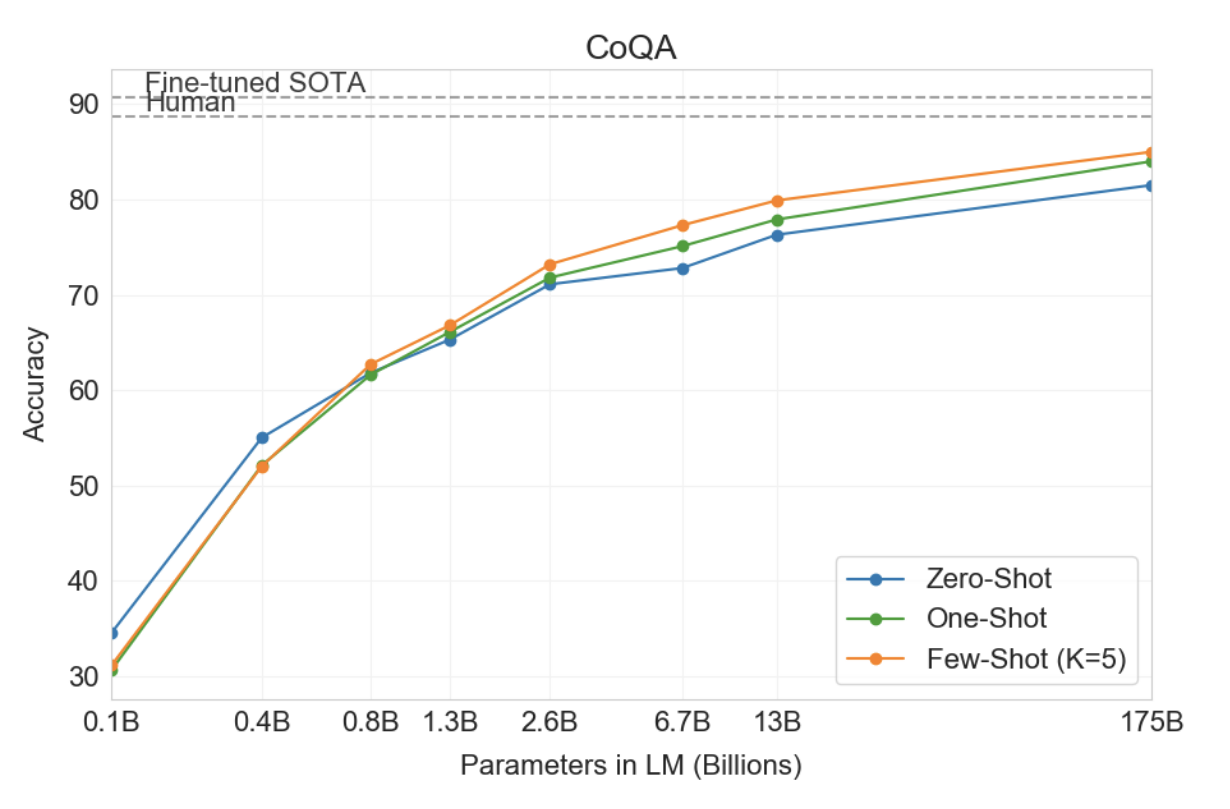
GPT-3는 자유 형식 대화 데이터세트인 CoQA [RCM19]에서 가장 좋은 성능을 발휘하고(인간 기준선의 3포인트 이내) 구조화된 대화 모델링이 필요한 데이터세트인 QuAC [CHI+18]에서 최악의 성능을 발휘합니다(ELMo 기준선 아래 13 F1). 행동과 대답은 교사-학생 상호 작용의 선택 범위에 걸쳐 있습니다. 독해의 맥락에서 이산적 추론과 수리력을 테스트하는 데이터세트인 DROP [DWD+19]에서 몇 번의 샷 설정에서 GPT-3는 원본 논문의 미세 조정된 BERT 기준선보다 성능이 뛰어나지만 여전히 인간 성능보다 훨씬 낮습니다. 기호 시스템으로 신경망을 강화하는 최첨단 접근 방식 [RLL+19]. SQuAD 2.0 [RJL18]에서 GPT-3는 제로 샷 설정에 비해 거의 10 F1(69.8까지) 향상되는 퓨샷 학습 기능을 보여줍니다. 이를 통해 원본 논문에서 가장 잘 조정된 결과를 약간 능가할 수 있습니다. 중학교 및 고등학교 영어 시험의 객관식 데이터 세트인 RACE [LXL+17]에서 GPT-3은 상대적으로 약한 성능을 발휘하며 상황별 표현을 활용하는 초기 작업과만 경쟁적이며 여전히 SOTA보다 45% 뒤쳐져 있습니다.
3.7 SuperGLUE
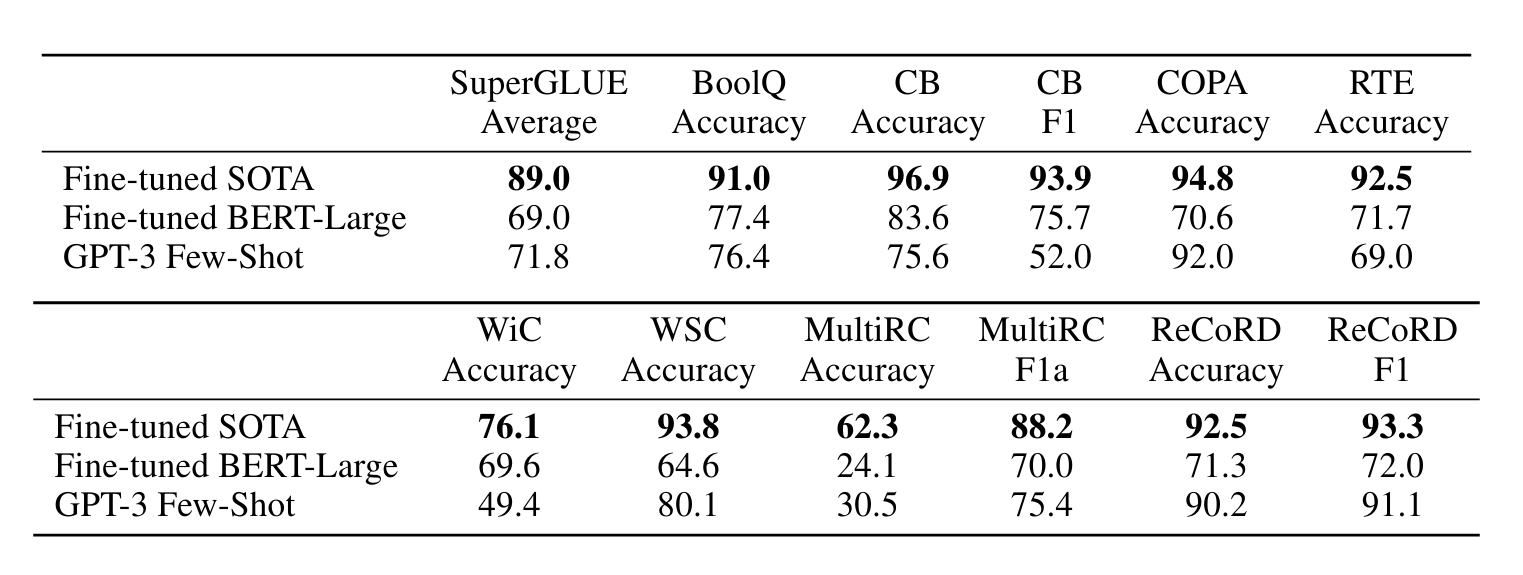
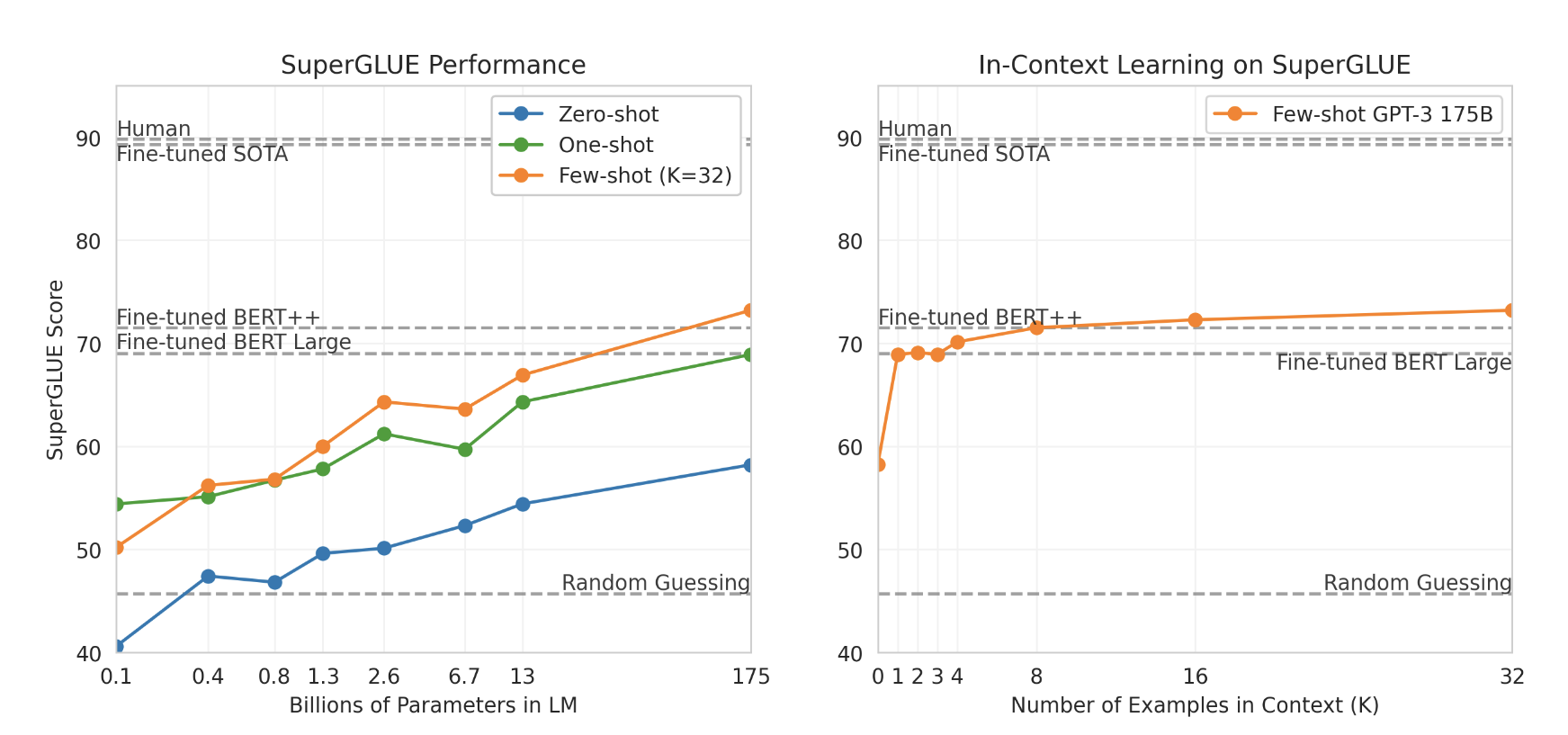
NLP 작업에 대한 결과를 더 효과적으로 집계하고 보다 체계적인 방식으로 BERT 및 RoBERTa와 같은 인기 모델과 비교하기 위해 표준화된 데이터 세트 컬렉션인 SuperGLUE 벤치마크 [WPN+19] [WPN+19에서 GPT-3를 평가합니다. ] [CLC+19] [DMST19] [RBG11] [KCR+18] [ZLL+18] [DGM06] [BHDD+06] [GMDD07] [BDD+09] [PCC18] [PHR+18]. SuperGLUE 데이터 세트에 대한 GPT-3의 테스트 세트 성능은 표 3.8에 나와 있습니다. 퓨샷 설정에서는 훈련 세트에서 무작위로 샘플링된 모든 작업에 대해 32개의 예제를 사용했습니다. WSC 및 MultiRC를 제외한 모든 작업에 대해 각 문제의 맥락에서 사용할 새로운 예제 세트를 샘플링했습니다. WSC와 MultiRC의 경우, 우리가 평가한 모든 문제에 대한 맥락으로 훈련 세트에서 무작위로 추출된 동일한 예제 세트를 사용했습니다.
그림3.7 : CoQA 독해 작업에 대한 GPT-3 결과. GPT-3 175B는 몇 번의 샷 설정에서 85 F1을 달성하며, 측정된 인간 성능과 최첨단 미세 조정 모델보다 불과 몇 점 뒤처져 있습니다. 제로샷 및 원샷 성능은 몇 점 뒤쳐져 있으며, 더 큰 모델의 경우 퓨샷의 성능 향상이 가장 큽니다.
표3.8 : 미세 조정된 기준선 및 SOTA와 비교한 SuperGLUE의 GPT-3 성능. 모든 결과는 테스트 세트에 보고됩니다. GPT-3 퓨샷에는 각 작업의 맥락 내에서 총 32개의 예제가 제공되며 그라데이션 업데이트를 수행하지 않습니다.
그림3.8 : SuperGLUE의 성능은 모델 크기와 컨텍스트 내 예제 수에 따라 증가합니다. K = 32 값은 우리 모델이 작업당 32개의 예제를 표시했으며 SuperGLUE의 8개 작업에 총 256개의 예제가 나누어져 있음을 의미합니다. 우리는 개발 세트에 GPT-3 값을 보고하므로 숫자는 점선 참조선과 직접적으로 비교할 수 없습니다(테스트 세트 결과는 표 3.8에 나와 있습니다). BERT-Large 참조 모델은 SuperGLUE 훈련 세트(125K 예)에서 미세 조정된 반면 BERT++는 MultiNLI(392K 예) 및 SWAG(113K 예)에서 먼저 미세 조정된 후 SuperGLUE 훈련 세트( 총 630K개의 미세 조정 예). 우리는 BERT-Large와 BERT++ 간의 성능 차이가 컨텍스트당 하나의 예제와 컨텍스트당 8개의 예제가 있는 GPT-3의 차이와 거의 동일하다는 것을 발견했습니다.
우리는 작업 전반에 걸쳐 GPT-3의 성능이 폭넓게 관찰됩니다. COPA 및 ReCoRD에서 GPT-3는 원샷 및 퓨샷 설정에서 SOTA에 가까운 성능을 달성했으며 COPA는 단 몇 포인트 부족하고 리더보드에서 2위를 차지했습니다. 여기서 1위는 미세 조정된 110억 개의 매개변수 모델(T5)이 차지했습니다.
WSC에서는 성능이 여전히 상대적으로 강하여 몇 번의 샷 설정에서 80.1%를 달성합니다(섹션 3.4에 설명된 대로 GPT-3는 원래 Winograd 데이터 세트에서 88.6%를 달성합니다). BoolQ, MultiRC 및 RTE에서는 성능이 합리적이며 미세 조정된 BERT-Large의 성능과 거의 일치합니다. CB에서는 퓨샷 설정에서 75.6%로 수명의 징후가 보입니다.
WiC는 퓨샷 성능이 49.4%(랜덤 확률)로 눈에 띄는 약점이다. 우리는 WiC에 대해 여러 가지 다양한 표현과 공식(단어가 두 문장에서 동일한 의미로 사용되는지 확인하는 작업 포함)을 시도했지만 어느 것도 강력한 성능을 달성하지 못했습니다. 이는 다음 섹션(ANLI 벤치마크에 대해 논의)에서 더 명확해질 현상을 암시합니다. GPT-3는 두 문장 또는 스니펫을 비교하는 일부 작업에서 몇 번 또는 한 번 설정에서 약한 것으로 보입니다. 예를 들어 단어가 두 문장(WiC)에서 동일한 방식으로 사용되는지, 한 문장이 다른 문장의 의역인지, 한 문장이 다른 문장을 의미하는지 여부입니다. 이는 또한 이 형식을 따르는 RTE 및 CB의 점수가 비교적 낮은 것을 설명할 수도 있습니다. 이러한 약점에도 불구하고 GPT-3는 여전히 8개 작업 중 4개 작업에서 미세 조정된 BERT-large를 능가하며 2개 작업에서 GPT-3는 미세 조정된 110억 매개변수 모델이 보유한 최첨단 성능에 가깝습니다.
마지막으로, 퓨샷 SuperGLUE 점수는 모델 크기와 컨텍스트 내 예제 수에 따라 꾸준히 향상되어 컨텍스트 내 학습의 이점이 증가함을 보여줍니다(그림 3.8). K를 작업당 최대 32개의 예시로 확장하고 그 이후에는 추가 예시가 우리의 상황에 안정적으로 맞지 않습니다. K 값을 전체적으로 살펴보면 GPT-3가 전체 SuperGLUE 점수에서 미세 조정된 BERT-Large보다 뛰어난 성능을 발휘하기 위해 작업당 총 8개 미만의 예제가 필요하다는 것을 알 수 있습니다.
3.8 NLI
자연어 추론(NLI) [Fyo00]은 두 문장 사이의 관계를 이해하는 능력에 관한 것입니다.
실제로 이 작업은 일반적으로 모델이 두 번째 문장이 첫 번째 문장에서 논리적으로 따르는지, 첫 번째 문장과 모순되는지, 아니면 참(중립)인지를 분류하는 2개 또는 3개의 클래스 분류 문제로 구성됩니다.
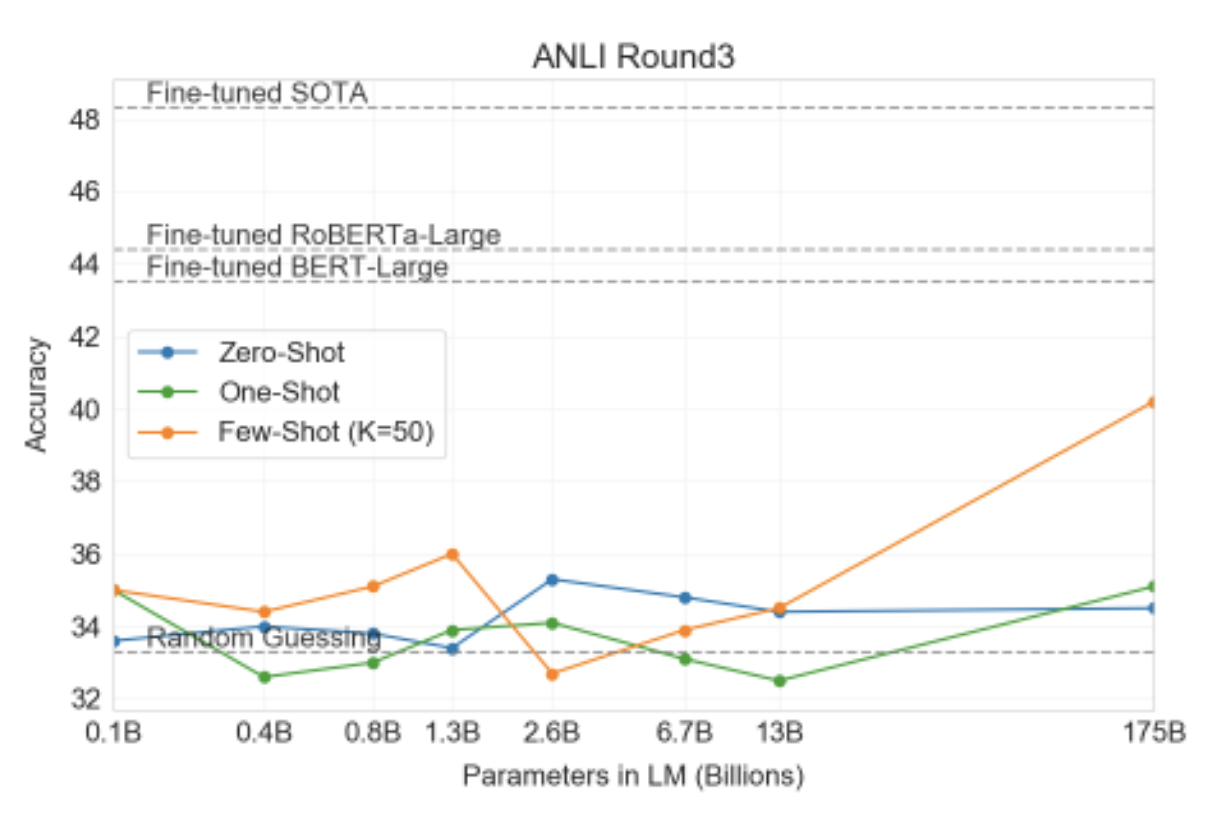
SuperGLUE에는 작업의 바이너리 버전을 평가하는 NLI 데이터세트인 RTE가 포함되어 있습니다. RTE에서는 가장 큰 버전의 GPT-3만이 모든 평가 설정에서 무작위(56%)보다 확실히 더 나은 성능을 발휘하지만 몇 번의 샷 설정에서는 GPT-3가 단일 작업으로 미세 조정된 BERT Large와 유사하게 성능을 발휘합니다. 또한 최근 도입된 ANLI(Adversarial Natural Language Inference) 데이터세트[NWD+19]를 평가합니다. ANLI는 세 라운드(R1, R2, R3)에 걸쳐 적대적으로 채굴된 일련의 자연어 추론 질문을 사용하는 어려운 데이터세트입니다. RTE와 유사하게 GPT-3보다 작은 모든 모델은 몇 번의 샷 설정(~33%)에서도 ANLI에서 거의 정확히 무작위로 수행되는 반면, GPT-3 자체는 라운드 3에서 수명의 징후를 보여줍니다. ANLI R3은 그림 3.9에 강조 표시되어 있으며 모든 라운드에 대한 전체 결과는 부록 H에서 확인할 수 있습니다. RTE와 ANLI에 대한 이러한 결과는 NLI가 여전히 언어 모델에 대해 매우 어려운 작업이며 이제 막 진전의 조짐을 보이기 시작했음을 시사합니다.
그림3.9 : ANI 라운드 3에서 GP1-3의 성능. 결과는 개발 세트에 있습니다. 이는 1500개의 예만 가지고 있으므로 분산이 높습니다(표준편차는 1.2%로 추정됩니다). 우리는 더 작은 모델이 무작위 기회 주위를 맴돌고 있는 반면, tew-shot UP 1-3 173B는 무작위 기회에서 sOlA까지의 격차를 거의 멈추는 것을 발견했습니다. ANIL 라운드1 및 2에 대한 결과는 부록에 나와 있습니다.
3.9 Synthetic and Qualitative Tasks
퓨샷(또는 제로 및 원샷) 설정에서 GPT-3의 능력 범위를 조사하는 한 가지 방법은 간단한 즉석 계산 추론을 수행해야 하는 작업을 제공하고, 다음과 같은 새로운 패턴을 인식하는 것입니다. 훈련 중에 일어날 가능성이 적거나 특이한 작업에 빠르게 적응합니다. 우리는 이러한 종류의 능력을 테스트하기 위해 몇 가지 작업을 고안합니다. 먼저, GPT-3의 산술 수행 능력을 테스트합니다. 둘째, 단어의 문자를 재배열하거나 해독하는 작업과 관련된 여러 작업을 생성합니다. 이러한 작업은 훈련 중에 정확히 볼 수 없는 작업입니다. 셋째, SAT 스타일 유추 문제를 몇 번에 해결하는 GPT-3의 능력을 테스트합니다. 마지막으로 문장에서 새로운 단어 사용, 영어 문법 수정, 뉴스 기사 생성 등 여러 정성적 작업에 대해 GPT-3를 테스트합니다. 우리는 언어 모델의 테스트 시간 동작에 대한 추가 연구를 자극하기 위해 합성 데이터 세트를 출시할 것입니다.
3.9.1 Arithmetic
작업별 교육 없이 간단한 산술 연산을 수행하는 GPT-3의 능력을 테스트하기 위해 우리는 GPT-3에 자연어로 간단한 산술 문제를 묻는 것과 관련된 10개의 테스트로 구성된 작은 배터리를 개발했습니다.
2 digit addition (2D+) : 모델은 질문 형식으로 표현된 [0,100)에서 균일하게 샘플링된 두 개의 정수를 추가하도록 요청받습니다. “질문: 48 더하기 76은 무엇입니까? 답: 124.”
2 digit subtraction (2D-) : 모델은 [0,100)에서 균일하게 샘플링된 두 정수를 빼도록 요청받습니다. 대답은 부정적일 수 있습니다. 예: “질문: 34 빼기 53은 무엇입니까? 답: -19인치.
3 digit addition (3D+) : 숫자가 [0,1000)에서 균일하게 샘플링된다는 점을 제외하면 2자리 덧셈과 동일합니다.
3 digit subtraction (3D-) : 숫자가 [0,1000)에서 균일하게 샘플링된다는 점을 제외하면 2자리 뺄셈과 동일합니다
4 digit addition (4D+) : [0,10000)에서 균일하게 샘플링된다는 점을 제외하면 3자리 덧셈과 동일합니다.
4 digit subtraction (4D-) : [0,10000)에서 균일하게 샘플링된다는 점을 제외하면 3자리 뺄셈과 동일합니다.
5 digit addition (5D+) : [0,100000)에서 균일하게 샘플링된다는 점을 제외하면 3자리 덧셈과 동일합니다.
5 digit subtraction (5D-) : [0,100000)에서 균일하게 샘플링된다는 점을 제외하면 3자리 뺄셈과 동일합니다.
2 digit multiplication (2Dx) : 모델은 [0,100)에서 균일하게 샘플링된 두 정수를 곱하도록 요청됩니다. “질문: 24 곱하기 42는 무엇인가요? 답: 1008”.
One-digit composite (1DC) : 모델은 마지막 두 자리를 괄호로 묶은 세 개의 1자리 숫자에 대해 복합 연산을 수행하도록 요청받습니다. 예를 들어, “Q: 6+(4*8)은 무엇입니까? 답변: 38인치입니다. 1자리 숫자 3개는 [0,10)에서 균일하게 선택되고 연산은 {+,-,*}에서 균일하게 선택됩니다.
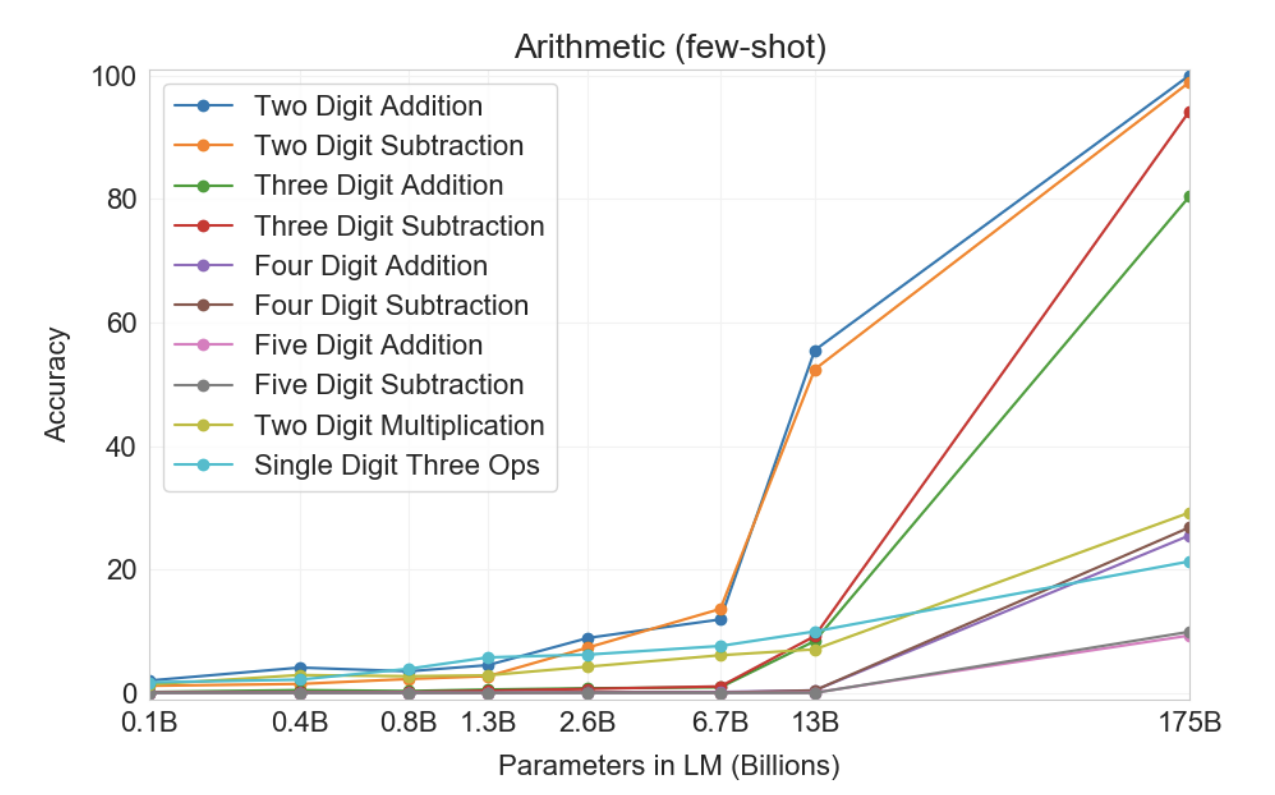
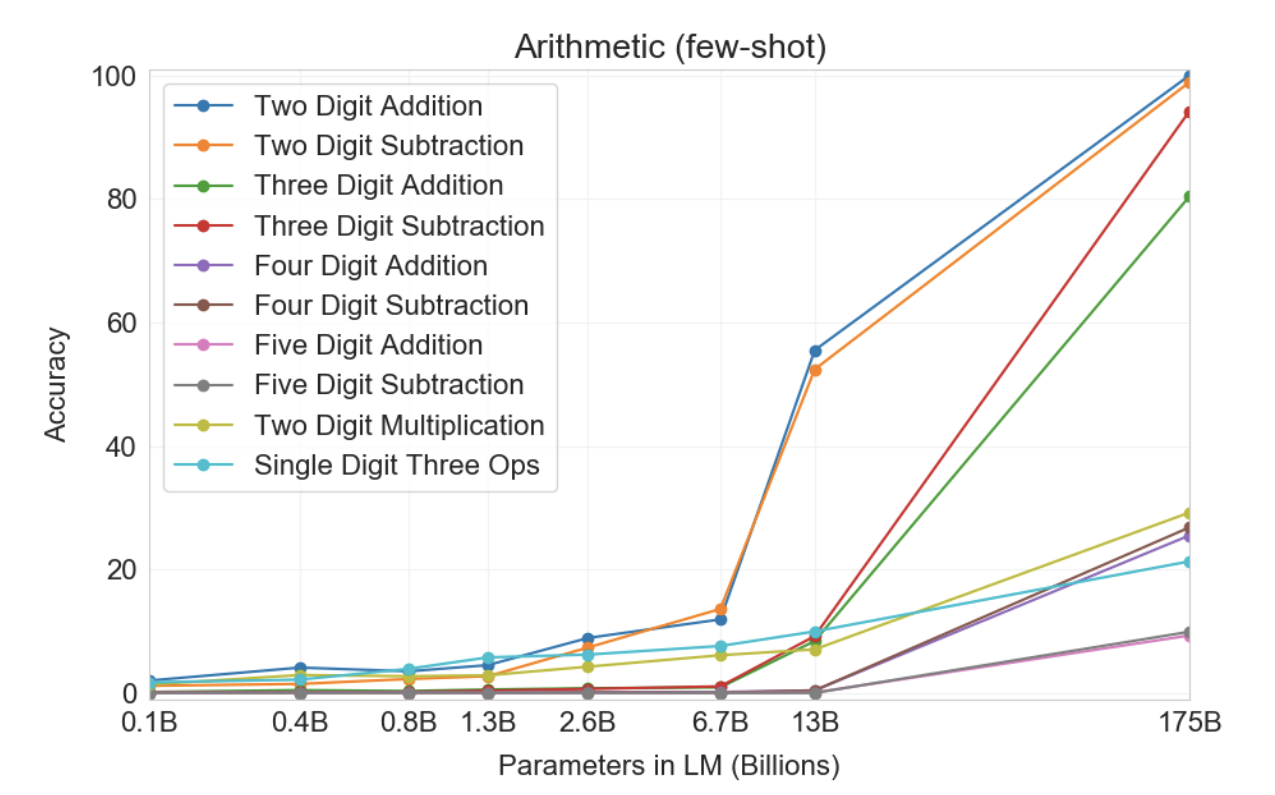
그림3.10 : 다양한 크기의 모델에 대한 몇 번의 샷 설정에서 10가지 산술 작업 모두에 대한 결과입니다. 두 번째로 큰 모델(GPT-3 13B)에서 가장 큰 모델(GPT-3 175)로 상당한 도약이 있으며, 후자는 안정적으로 정확한 2자리 산술, 일반적으로 정확한 3자리 산술을 수행하고 상당한 정답을 맞힐 수 있습니다. 4-5자리 산술, 2자리 곱셈 및 복합 연산에 소요되는 시간의 일부입니다. 원샷과 제로샷의 결과는 부록에 나와 있습니다.
10가지 작업 모두에서 모델은 정답을 정확하게 생성해야 합니다. 각 작업에 대해 작업의 무작위 인스턴스 2,000개로 구성된 데이터 세트를 생성하고 해당 인스턴스의 모든 모델을 평가합니다.
먼저 몇 번의 샷 설정에서 GPT-3을 평가했으며 그 결과는 그림 3.10에 나와 있습니다. 덧셈과 뺄셈에서는 GPT-3가 두 자리 덧셈 정확도 100%, 두 자리 뺄셈 98.9%, 세 자리 덧셈 80.2%, 세 자리 뺄셈 94.2%로 자릿수가 적을 때 강력한 능력을 발휘합니다. 자릿수가 증가함에 따라 성능은 감소하지만 GPT-3은 여전히 4자리 연산에서 25~26%의 정확도, 5자리 연산에서 9~10%의 정확도를 달성하여 더 많은 자릿수로 일반화할 수 있는 어느 정도의 능력을 제안합니다. GPT-3은 또한 특히 계산 집약적인 연산인 2자리 곱셈에서 29.2%의 정확도를 달성합니다. 마지막으로 GPT-3는 한자리 결합 연산(예: 9*(7+5))에서 21.3%의 정확도를 달성했는데, 이는 단순한 단일 연산 이상의 견고성을 가지고 있음을 의미합니다.
그림 3.10에서 알 수 있듯이 작은 모델은 이러한 모든 작업에서 제대로 작동하지 않습니다. 심지어 130억 개의 매개변수 모델(1,750억 개의 전체 GPT-3 다음으로 두 번째로 큰 모델)도 2자리 덧셈과 뺄셈을 절반의 시간만 풀 수 있고 다른 모든 작업은 해결할 수 있습니다. 작업 시간은 10% 미만입니다.
원샷 및 제로샷 성능은 퓨샷 성능에 비해 다소 저하되며, 이는 작업에 대한 적응(또는 최소한 작업 인식)이 이러한 계산을 올바르게 수행하는 데 중요함을 시사합니다.
그럼에도 불구하고 원샷 성능은 여전히 매우 강력하며 전체 GPT-3의 제로샷 성능조차도 모든 소규모 모델에 대한 퓨샷 학습 성능을 훨씬 능가합니다. 전체 GPT-3에 대한 세 가지 설정은 모두 표 3.9에 나와 있으며, 세 가지 설정 모두에 대한 모델 용량 확장은 부록 H에 나와 있습니다.
표3.9 : GPT-3 175B의 기본 산술 작업 결과. {2,3,4,5}D{+,-}는 2, 3, 4, 5자리 덧셈 또는 뺄셈이고, 2Dx는 2자리 곱셈입니다. 1DC는 1자리 복합 연산입니다. 제로샷에서 원샷, 퓨샷 설정으로 갈수록 결과가 점점 더 좋아지지만 제로샷에서도 상당한 연산 능력을 보여줍니다.
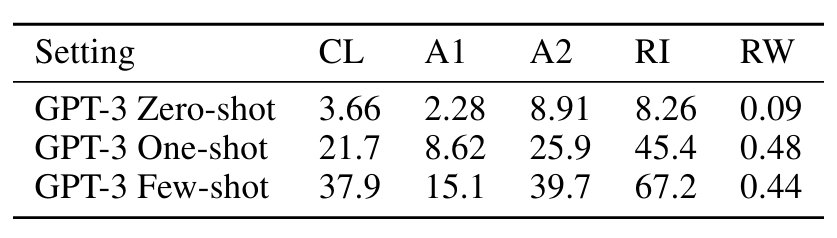
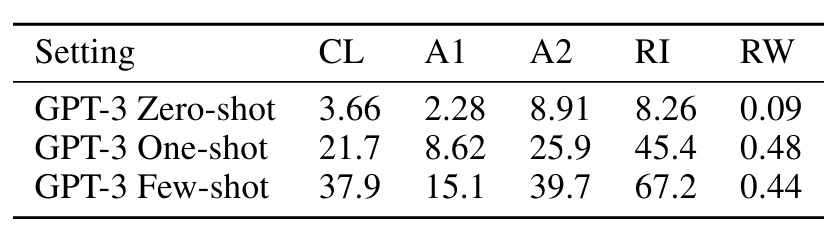
표3.10 : GPT-3 175B는 제로, 원, 퓨샷 설정에서 다양한 단어 해독 및 단어 조작 작업에 대한 성능을 발휘합니다. CL은 "단어의 순환 문자", A1은 처음과 마지막 문자만 제외하고 철자 바꾸기, A2는 처음과 마지막 두 글자를 제외한 모든 철자 바꾸기, RI는 "단어에 무작위 삽입", RW는 "역전된 단어"입니다.
모델이 단순히 특정 산술 문제를 기억하고 있는지 확인하기 위해 테스트 세트에서 3자리 산술 문제를 가져와 훈련 데이터에서 "<NUM1> + <NUM2> =" 및 "<NUM1> plus <NUM2>" 형식으로 검색했습니다. 2,000개의 덧셈 문제 중 17개 일치(0.8%)만 찾았고 2,000개의 뺄셈 문제 중에서 2개(0.1%)만 찾았습니다. 이는 정답의 아주 작은 부분만이 기억될 수 있음을 시사합니다. 또한 오답을 검사하면 모델이 "1"을 표시하지 않는 등의 실수를 자주 하는 것으로 나타나 실제로 테이블을 기억하는 것이 아니라 관련 계산을 수행하려고 시도하고 있음을 나타냅니다.
전반적으로 GPT-3는 퓨샷, 원샷, 심지어 제로샷 설정에서도 적당히 복잡한 연산에서 합리적인 능력을 보여줍니다.
3.9.2 Word Scrambling and Manipulation Tasks
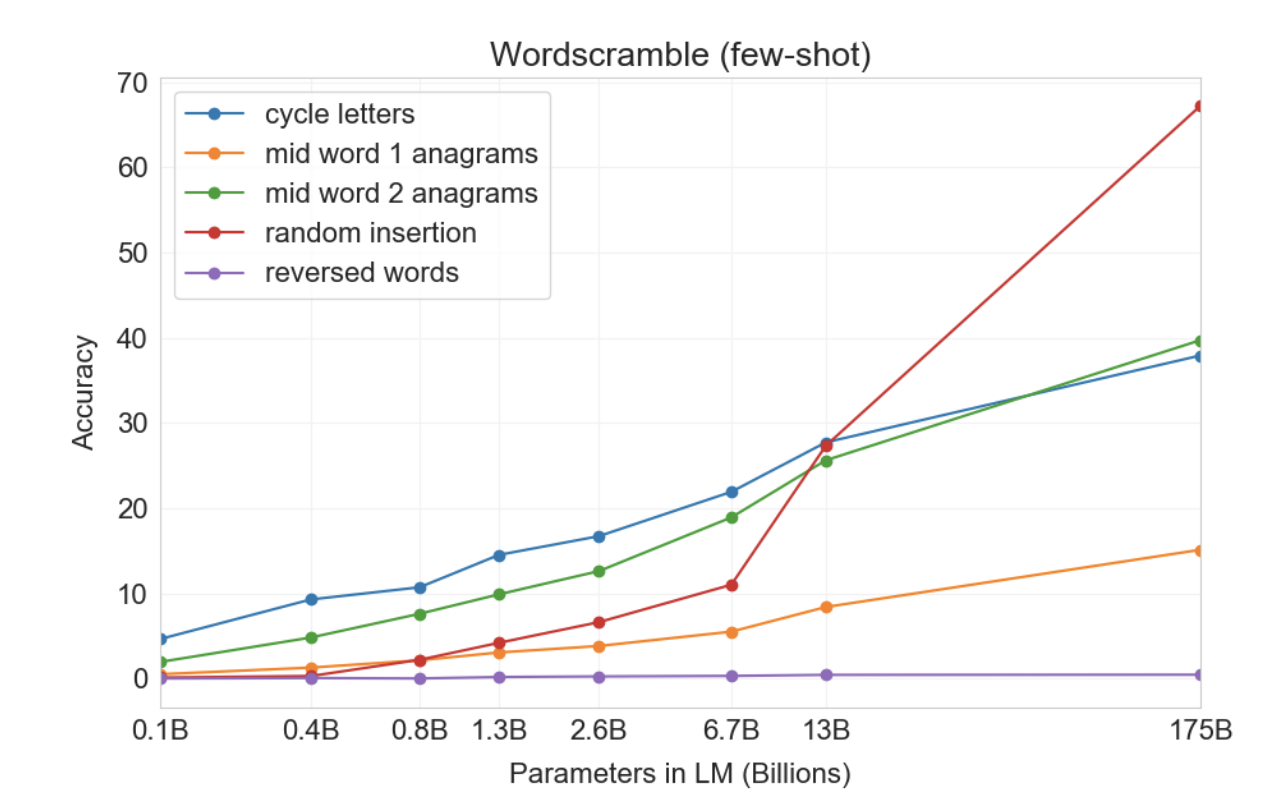
몇 가지 예를 통해 새로운 기호 조작을 학습하는 GPT-3의 능력을 테스트하기 위해 5개의 "문자 조작" 작업으로 구성된 작은 배터리를 설계했습니다. 각 작업에는 문자 뒤섞기, 추가 또는 삭제의 조합으로 인해 왜곡된 단어를 모델에 제공하고 원래 단어를 복구하도록 요청하는 작업이 포함됩니다. 5가지 작업은 다음과 같습니다.
Cycle letters in word (CL) : 모델에는 문자가 순환된 단어와 "=" 기호가 주어지며 원래 단어를 생성할 것으로 예상됩니다. 예를 들어, “lyinevitab”이 주어질 수 있으며 “inevitously”를 출력해야 합니다.
Anagrams of all but first and last characters (A1) : 모델에는 첫 번째와 마지막 문자를 제외한 모든 문자가 무작위로 뒤섞인 단어가 주어지며 원래 단어를 출력해야 합니다. 예: criroptuon = corruption.
Anagrams of all but first and last 2 characters (A2) : 모델에는 처음 2개와 마지막 2개를 제외한 모든 문자가 무작위로 뒤섞인 단어가 주어지며 원래 단어를 복구해야 합니다. 예: opoepnnt → opponent.
Random insertion in word (RI) : 단어의 각 문자 사이에 임의의 구두점이나 공백 문자가 삽입되며, 모델은 원래 단어를 출력해야 합니다. 예: s.u!c/c!e.s s i/o/n = succession.
Reversed words (RW) : 모델에는 철자를 거꾸로 쓴 단어가 제공되며 원래 단어를 출력해야 합니다. 예: stcejbo → objects
그림3.11 : 다양한 크기의 모델에 대한 5개의 단어 스크램블링 작업에 대한 퓨샷 성능. 무작위 삽입 작업은 대부분의 시간 동안 작업을 해결하는 175B 모델에서 개선의 상승 기울기를 보여주지만 일반적으로 모델 크기가 원활하게 개선됩니다. 원샷 및 제로샷 성능의 스케일링은 부록에 나와 있습니다. 모든 작업은 K = 100으로 수행됩니다.
원샷 설정에서는 성능이 현저히 약하고(절반 이상 감소) 제로샷 설정에서는 모델이 어떤 작업도 거의 수행할 수 없습니다(표 3.10). 이는 모델이 이러한 작업을 제로샷으로 수행할 수 없고 인위적인 특성으로 인해 사전 훈련 데이터에 나타날 가능성이 낮기 때문에 모델이 실제로 테스트 시간에 이러한 작업을 학습하는 것처럼 보인다는 것을 의미합니다(비록 확실하게 확인할 수는 없지만).
상황 내 사례 수의 함수로 작업 성능을 보여주는 "상황 내 학습 곡선"을 그려 성능을 더욱 정량화할 수 있습니다. 그림 1.2에는 기호 삽입 작업에 대한 상황 내 학습 곡선이 나와 있습니다. 더 큰 모델이 작업 예제와 자연어 작업 설명을 포함하여 상황 내 정보를 점점 더 효과적으로 사용할 수 있다는 것을 알 수 있습니다.
마지막으로, 이러한 작업을 해결하려면 문자 수준 조작이 필요한 반면 BPE 인코딩은 단어의 상당 부분(토큰당 평균 약 0.7 단어)에서 작동하므로 LM의 관점에서 이러한 작업을 성공하려면 단순히 조작하는 것만으로는 충분하지 않다는 점을 덧붙일 가치가 있습니다. BPE 토큰이지만 하위 구조를 이해하고 분리합니다. 또한 CL, A1, A2는 전단사가 아니므로(즉, 뒤섞인 단어는 뒤섞인 단어의 결정적 함수가 아님) 모델이 올바른 뒤섞임을 찾기 위해 일부 검색을 수행해야 합니다. 따라서 관련된 기술에는 사소한 패턴 일치 및 계산이 필요한 것으로 보입니다.
3.9.3 SAT Analogies
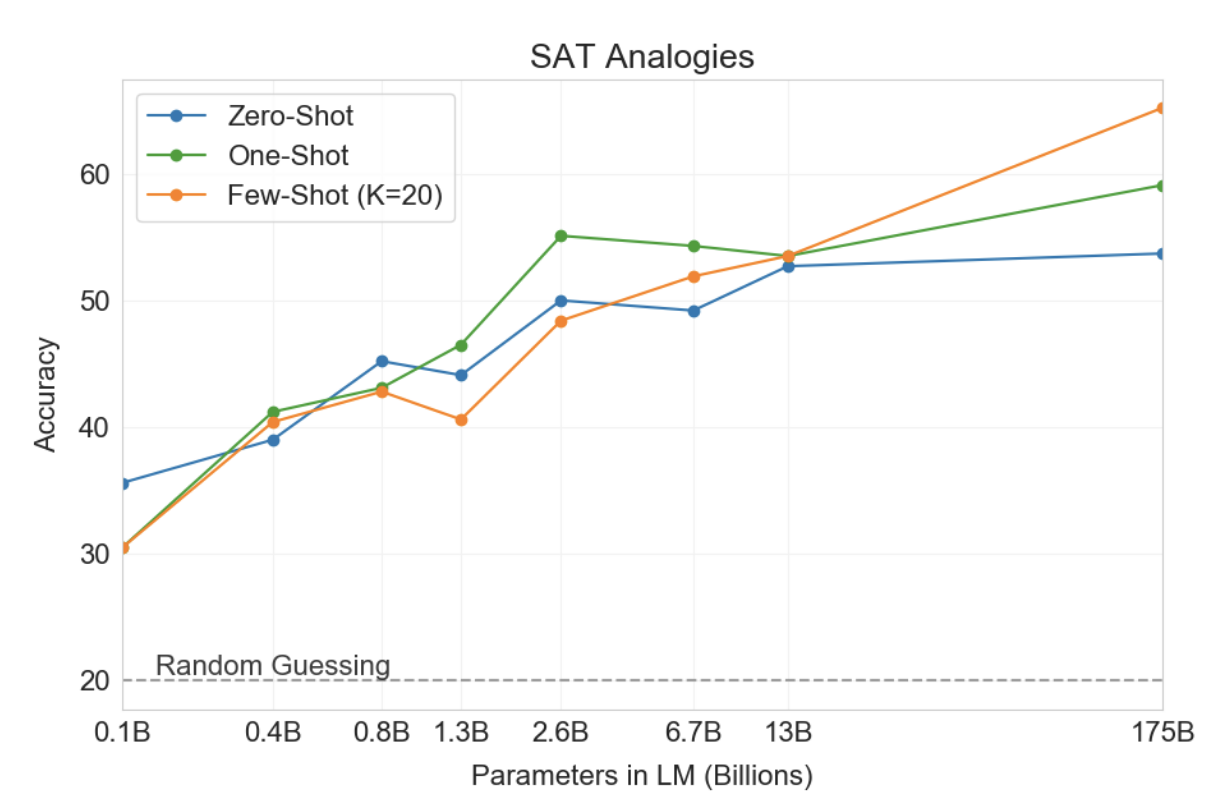
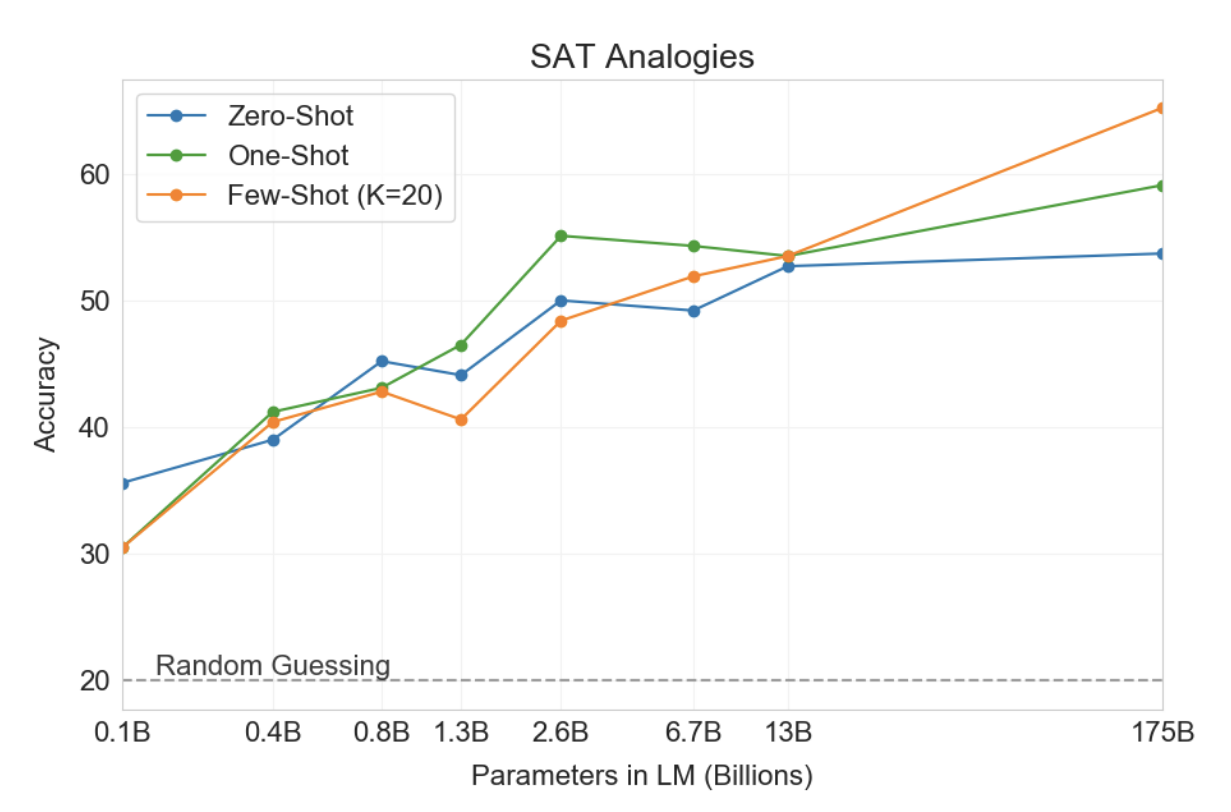
일반적인 텍스트 분포와 관련하여 다소 특이한 또 다른 작업에서 GPT-3를 테스트하기 위해 우리는 374개의 "SAT 유추" 문제 세트를 수집했습니다[TLBS03]. 비유는 2005년 이전 SAT 대학 입학 시험의 한 부분을 구성했던 객관식 문제 스타일입니다. 전형적인 예는 “대담함은 대담함을 뜻하며, (a) 성스러운 것은 위선을 뜻하고, (b) 익명은 정체성을 뜻하며, (c) 후회하는 것은 악행이고, (d) 해로운 것은 결과이며, (e) 감수성이 있는 것은 유혹입니다.” 학생은 5개의 단어 쌍 중 원래 단어 쌍과 동일한 관계를 갖는 단어 쌍을 선택해야 합니다. 이 예에서 대답은 "성스러운 것은 위선이다"이다. 이 과제에서 GPT-3는 퓨샷 설정에서 65.2%, 원샷 설정에서 59.1%, 제로샷 설정에서 53.7%를 달성한 반면, 대학 지원자의 평균 점수는 57%였습니다[TL05](랜덤) 추측하면 20%가 나옵니다. 그림 3.12에서 볼 수 있듯이 결과는 규모에 따라 개선되며 전체 1,750억 모델은 130억 매개변수 모델에 비해 10% 이상 향상됩니다.
그림3.12 : 다양한 크기의 모델에 대해 SAT 유추 작업에 대한 제로, 원샷 및 퓨샷 성능을 제공합니다. 가장 큰 모델은 소수 샷 설정에서 65%의 정확도를 달성했으며, 또한 작은 모델에는 없는 상황 내 학습에 대한 상당한 이점을 보여줍니다.
3.9.4 News Article Generation
생성 언어 모델에 대한 이전 연구에서는 뉴스 기사에 대한 그럴듯한 첫 번째 문장으로 구성된 사람이 작성한 프롬프트가 주어진 모델에서 조건부 샘플링을 통해 합성 "뉴스 기사"를 생성하는 능력을 정성적으로 테스트했습니다[RWC+19]. [RWC+19]에 비해 GPT-3을 훈련하는 데 사용되는 데이터 세트는 뉴스 기사에 훨씬 덜 가중치를 두므로 무조건 원시 샘플을 통해 뉴스 기사를 생성하는 것은 덜 효과적입니다. 예를 들어 GPT-3는 종종 제안된 첫 번째 문장을 해석합니다. “뉴스 기사”를 트윗으로 만든 다음 합성 응답이나 후속 트윗을 게시합니다. 이 문제를 해결하기 위해 우리는 모델의 맥락에서 이전 뉴스 기사 3개를 제공하여 GPT-3의 퓨샷 학습 능력을 활용했습니다. 제안된 다음 기사의 제목과 부제를 사용하여 모델은 "뉴스" 장르의 짧은 기사를 안정적으로 생성할 수 있습니다.
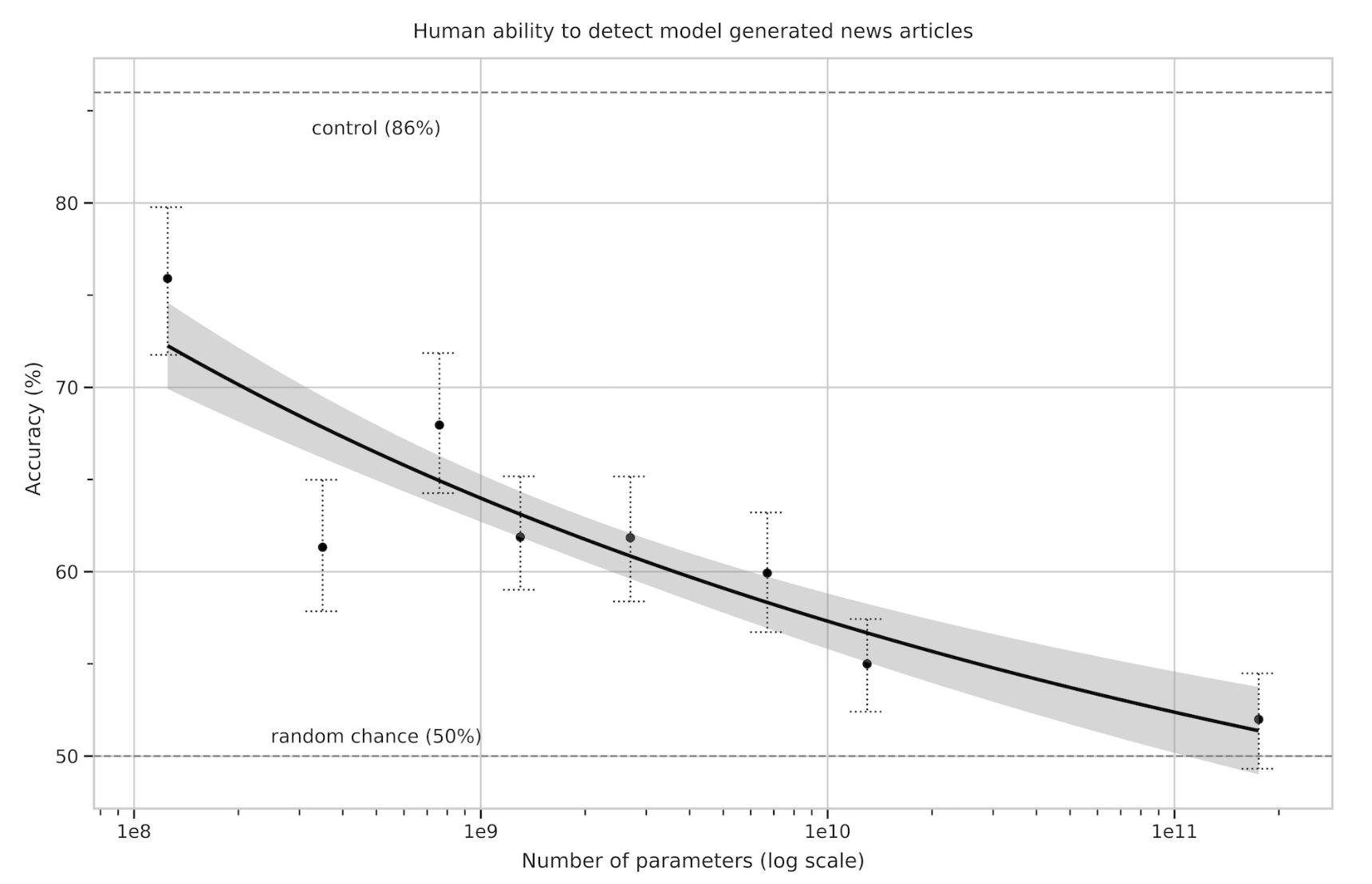
GPT-3의 뉴스 기사 생성 품질(일반적으로 조건부 샘플 생성 품질과 상관관계가 있을 것으로 생각됨)을 측정하기 위해 우리는 GPT-3에서 생성된 기사와 실제 기사를 구별하는 인간의 능력을 측정하기로 결정했습니다. Kreps 등도 비슷한 작업을 수행했습니다. [KMB20] 및 Zellers et al. [ZHR+19]. 생성 언어 모델은 인간이 생성한 콘텐츠의 배포와 일치하도록 훈련되었으므로 인간이 두 가지를 구별할 수 있는 능력이 잠재적으로 중요한 품질 척도가 됩니다.
인간이 모델 생성 텍스트를 얼마나 잘 감지할 수 있는지 확인하기 위해 newser.com 웹사이트에서 25개의 기사 제목과 부제목을 임의로 선택했습니다(평균 길이: 215단어). 그런 다음 크기가 125M에서 175B(GPT-3) 매개변수(평균 길이: 200단어)인 4가지 언어 모델로부터 이러한 제목과 자막의 완성을 생성했습니다. 각 모델에 대해 우리는 미국에 거주하는 약 80명의 참가자에게 실제 제목과 부제, 그리고 사람이 쓴 기사 또는 모델에서 생성된 기사로 구성된 퀴즈를 제시했습니다. 참가자들에게 그 기사가 "사람이 썼을 가능성이 매우 높음", "사람이 썼을 가능성이 더 높음", "모르겠어요", "기계가 썼을 가능성이 높음", "사람이 썼을 가능성이 매우 높음" 중 하나를 선택하도록 요청받았습니다. 기계".
우리가 선택한 기사는 모델의 훈련 데이터에 없었으며 모델 출력은 인간의 체리 따기를 방지하기 위해 프로그래밍 방식으로 형식화되고 선택되었습니다. 모든 모델은 동일한 컨텍스트를 사용하여 출력을 조절하고 동일한 컨텍스트 크기로 사전 학습되었으며 동일한 기사 제목과 부제목이 각 모델의 프롬프트로 사용되었습니다. 그러나 우리는 동일한 형식을 따르지만 의도적으로 잘못된 모델 생성 기사를 포함하는 참가자의 노력과 관심을 제어하기 위한 실험도 실행했습니다. 이는 컨텍스트가 없고 출력 무작위성이 증가된 160M 매개변수 모델인 "제어 모델"에서 기사를 생성하여 수행되었습니다.
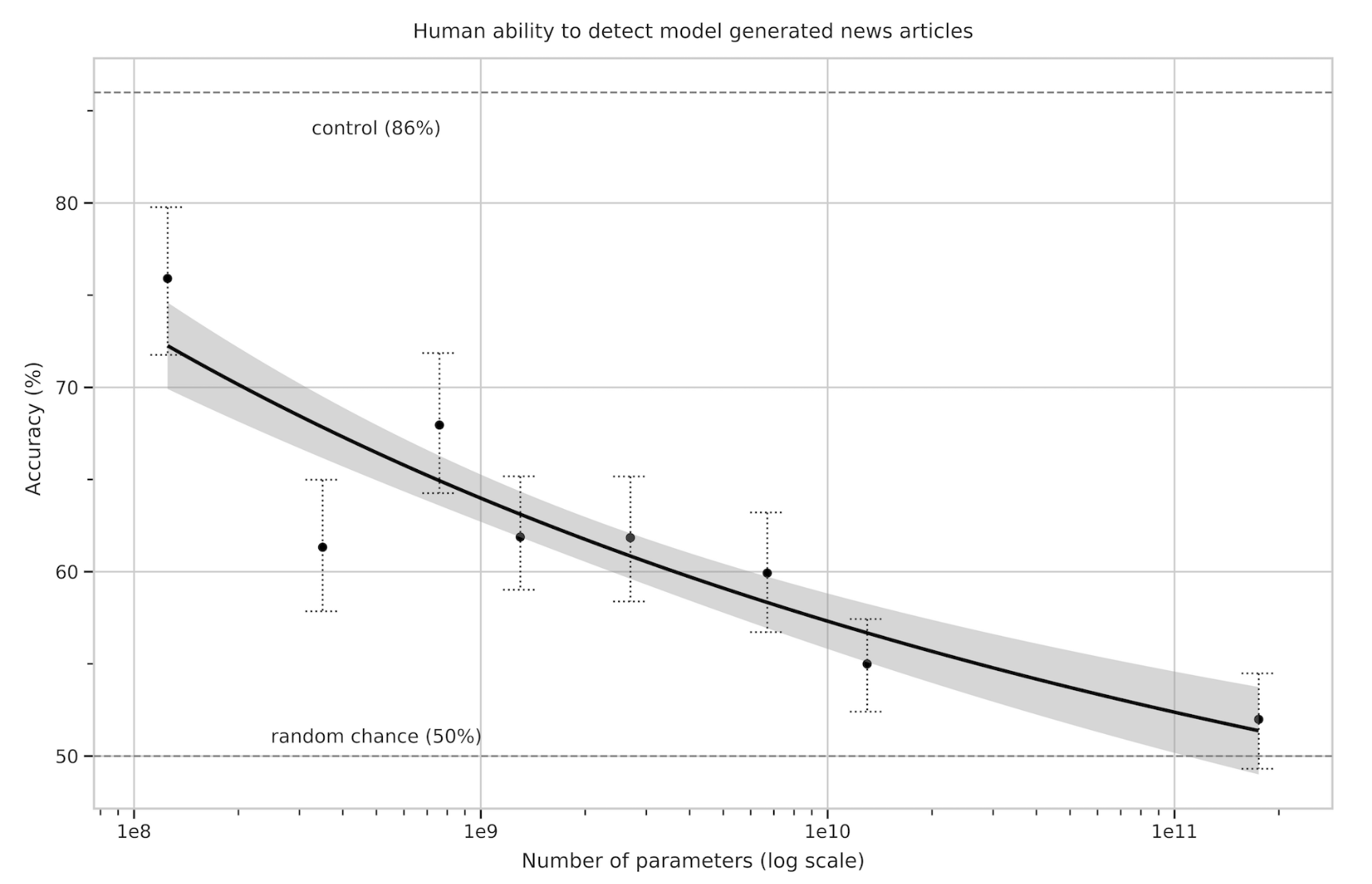
표3.11 : 짧은(약 200단어) 뉴스 기사가 모델 생성되었는지 여부를 식별하는 인간의 정확성. 우리는 인간의 정확도(중립적이지 않은 할당에 대한 올바른 할당의 비율로 측정)의 범위가 제어 모델의 86%에서 GPT-3 175B의 52%라는 것을 발견했습니다. 이 표는 5개 모델 간의 평균 정확도를 비교하고, 각 모델과 제어 모델(출력 무작위성이 증가된 무조건 GPT-3 Small 모델) 간의 평균 정확도 차이에 대한 2-샘플 T-검정 결과를 보여줍니다.
의도적으로 잘못된 기사가 모델에서 생성되었음을 감지할 때 평균 인간 정확도(참가자당 올바른 할당 대 중립적이지 않은 할당의 비율)는 약 86%였으며 여기서 50%는 기회 수준 성능입니다. 대조적으로, 175B 매개변수 모델에 의해 생성된 기사를 탐지하는 인간의 평균 정확도는 약 52%로 우연보다 거의 높았습니다(표 3.11 참조). 모델 생성 텍스트를 탐지하는 인간의 능력은 모델 크기가 증가함에 따라 감소하는 것으로 보입니다.
모델 크기에 따라 확률 정확도가 높아지는 경향이 있는 것으로 보이며 인간이 GPT-3를 감지하는 경우는 확률에 가깝습니다. 이는 모델 크기가 증가함에 따라 참가자가 각 출력에 더 많은 시간을 소비한다는 사실에도 불구하고 사실입니다(부록 E 참조).
GPT-3의 합성 기사의 예는 그림 3.14 및 3.15.7에 나와 있습니다. 평가에서 알 수 있듯이 텍스트의 대부분은 인간이 실제 인간 콘텐츠와 구별하기 어렵습니다. 사실적 부정확성은 인간 저자와 달리 기사 제목이 참조하는 특정 사실이나 기사가 작성된 시점에 접근할 수 없기 때문에 기사가 모델로 생성되었다는 지표가 될 수 있습니다. 다른 지표로는 반복, 비순차적 표현, 특이한 표현 등이 있지만 이러한 표현은 종종 눈에 띄지 않을 정도로 미묘합니다.
Ippolito et al. [IDCBE19] 의 언어 모델 감지 관련 연구는 GROVER [ZHR+19] 및 GLTR [GSR19]와 같은 자동 판별자가 인간 평가자보다 모델 생성 텍스트를 감지하는 데 더 큰 성공을 거둘 수 있음을 나타냅니다. 이러한 모델의 자동 감지는 향후 연구의 유망한 영역이 될 수 있습니다.
Ippolitoet al. [IDCBE19]는 또한 인간이 더 많은 토큰을 관찰할수록 모델 생성 텍스트를 감지하는 정확도가 높아진다는 점에 주목합니다. GPT-3 175B에서 생성된 긴 뉴스 기사를 인간이 얼마나 잘 감지하는지에 대한 예비 조사를 수행하기 위해 우리는 Reuters에서 평균 길이 569 단어의 12개 세계 뉴스 기사를 선택하고 GPT-3에서 이 기사의 완성을 평균 498단어 길이입니다(초기 실험보다 298단어 더 깁니다). 위의 방법론에 따라 우리는 미국에 거주하는 약 80명의 참가자를 대상으로 두 가지 실험을 실행하여 GPT-3와 제어 모델에서 생성된 기사를 탐지하는 인간의 능력을 비교했습니다.
우리는 제어 모델에서 의도적으로 불량한 긴 항목을 탐지하는 인간의 평균 정확도가 약 88%인 반면, GPT-3 175B에 의해 생성된 긴 항목을 탐지하는 인간의 평균 정확도는 여전히 약 52%로 확률보다 약간 높은 것으로 나타났습니다. 표 3.12). 이는 약 500단어 길이의 뉴스 기사에 대해 GPT-3가 인간이 작성한 뉴스 기사와 구별하기 어려운 기사를 계속해서 생성한다는 것을 나타냅니다.
3.9.5 Learning and Using Novel Words
발달 언어학[CB78]에서 연구되는 과제는 새로운 단어를 배우고 활용하는 능력입니다. 예를 들어 단어가 한 번만 정의된 것을 본 후 문장에서 단어를 사용하거나 반대로 단 한 번의 사용법에서 단어의 의미를 추론하는 것입니다. 여기서 우리는 전자를 수행하는 GPT-3의 능력을 질적으로 테스트합니다. 구체적으로 GPT-3에 "Gigamuru"와 같은 존재하지 않는 단어에 대한 정의를 제공한 다음 이를 문장에서 사용하도록 요청합니다. 우리는 (별도의) 존재하지 않는 단어가 문장에서 정의되고 사용되는 이전 예를 1~5개 제공하므로 작업은 광범위한 작업의 이전 예 측면에서는 소수이고 특정 단어 측면에서는 일회성입니다. 표 3.16은 우리가 생성한 6가지 예를 보여줍니다. 모든 정의는 인간이 생성했으며 첫 번째 답변은 조건화로 인간이 생성한 반면 후속 답변은 GPT-3에 의해 생성되었습니다. 이러한 예제는 한 번에 지속적으로 생성되었으며 프롬프트를 생략하거나 반복적으로 시도하지 않았습니다. 모든 경우에 생성된 문장은 단어의 올바른 사용 또는 적어도 그럴듯한 사용으로 나타납니다. 마지막 문장에서 모델은 "screeg"(즉 "screeghed")라는 단어에 대한 그럴듯한 활용형을 생성합니다. 비록 단어의 사용이 설명할 수 있다는 의미에서 그럴듯함에도 불구하고 약간 어색합니다("screeghed at other"). 장난감 칼싸움. 전반적으로 GPT-3는 문장에서 새로운 단어를 사용하는 작업에 적어도 능숙한 것으로 보입니다.
그림3.13 : 뉴스 기사가 모델에서 생성되었는지 여부(중립적이지 않은 할당에 대한 올바른 할당의 비율로 측정)를 식별하는 사람들의 능력은 모델 크기가 증가함에 따라 감소합니다. 의도적으로 불량한 제어 모델(출력 무작위성이 더 높은 조건이 지정되지 않은 GPT-3 Small 모델)의 출력 정확도는 상단에 점선으로 표시되고 무작위 가능성(50%)은 상단에 점선으로 표시됩니다. 맨 아래. 최적선은 95% 신뢰구간을 갖는 거듭제곱 법칙입니다.
표3.12 : ~500 단어 기사가 모델 생성인지 여부를 식별하는 사람들의 능력(중립적이지 않은 할당에 대한 올바른 할당의 비율로 측정)은 제어 모델에서 88%, GPT-3 175B에서 52%였습니다. 이 표는 GPT-3 175B와 제어 모델(출력 무작위성이 증가된 무조건 GPT-3 Small 모델) 간의 평균 정확도 차이에 대한 2-샘플 T-테스트 결과를 보여줍니다.
그림3.14 : GPT-3는 인간이 쓴 기사와 구별하기 가장 어렵다는 뉴스 기사를 생성했습니다(정확도: 12%).
그림3.15 : GPT-3는 인간이 작성한 기사와 가장 쉽게 구별할 수 있는 뉴스 기사를 생성했습니다(정확도: 61%).
그림3.16 : 문장에서 새로운 단어를 사용하는 몇 번의 작업에 대한 대표적인 GPT-3 완성입니다. 굵은 글씨는 GPT-3의 완성이고 일반 텍스트는 인간 프롬프트입니다. 첫 번째 예에서는 프롬프트와 완성이 모두 사람에 의해 제공됩니다. 이는 GPT-3가 연속적인 추가 프롬프트를 수신하고 완성을 제공하는 후속 예제에 대한 조건 역할을 합니다. 여기에 표시된 조건 외에 GPT-3에는 특정 작업이 제공되지 않습니다.
3.9.6 Correcting English Grammar
퓨샷 학습에 적합한 또 다른 작업은 영어 문법을 교정하는 것입니다. 우리는 "불량한 영어 입력: <문장>\n 좋은 영어 출력: <문장>" 형식의 프롬프트를 제공하여 Few-Shot 설정에서 GPT-3을 사용하여 이를 테스트합니다. 우리는 GPT-3에 인간이 생성한 수정 사항 1개를 제공한 다음 5개를 더 수정하도록 요청합니다(다시 한 번 누락이나 반복 없이). 결과는 그림 3.17에 나와 있습니다.
4 벤치마크 암기 측정 및 방지
훈련 데이터 세트는 인터넷에서 제공되므로 모델이 일부 벤치마크 테스트 세트에서 훈련되었을 가능성이 있습니다. 인터넷 규모의 데이터 세트에서 테스트 오염을 정확하게 탐지하는 것은 확립된 모범 사례가 없는 새로운 연구 영역입니다. 오염을 조사하지 않고 대규모 모델을 훈련하는 것이 일반적인 관행이지만, 사전 훈련 데이터 세트의 규모가 증가함에 따라 이 문제에 주의를 기울이는 것이 점점 더 중요해지고 있다고 생각합니다.
이러한 우려는 단순한 가설이 아닙니다. Common Crawl 데이터에 대한 언어 모델을 훈련하는 최초의 논문 중 하나[TL18]는 평가 데이터 세트 중 하나와 겹치는 훈련 문서를 감지하고 제거했습니다. GPT-2 [RWC+19]와 같은 다른 연구에서도 사후 중복 분석을 수행했습니다. 그들의 연구는 훈련과 테스트 사이에 중복되는 데이터에서 모델의 성능이 어느 정도 향상되었지만 오염된 데이터의 작은 부분(종종 몇 퍼센트에 불과)으로 인해 보고된 결과에 큰 영향을 미치지 않았다는 사실을 발견하여 상대적으로 고무적이었습니다.
그림3.17 : 영어 문법 교정을 위한 몇 번의 작업에 대한 대표적인 GPT-3 완성입니다. 굵은 글씨는 GPT-3의 완성이고 일반 텍스트는 인간 프롬프트입니다. 처음 몇 가지 예에서는 프롬프트와 완성이 모두 사람에 의해 제공됩니다. 이는 GPT-3가 연속적인 추가 프롬프트를 수신하고 완성을 제공하는 후속 예제에 대한 조건 역할을 합니다. 조건화 및 "나쁜 영어 입력/좋은 영어 출력" 프레이밍과 같은 처음 몇 가지 예를 제외하고 작업별 아무것도 GPT-3에 제공되지 않습니다. 우리는 "나쁜" 영어와 "좋은" 영어(및 용어 자체)의 구별이 복잡하고 상황에 따라 다르며 논쟁의 여지가 있다는 점에 주목합니다. 주택 임대를 언급하는 예에서 알 수 있듯이, 모델이 "좋은" 것이 무엇인지에 대해 가정한다는 가정은 심지어 오류를 범할 수도 있습니다(여기서 모델은 문법을 조정할 뿐만 아니라 "저렴한"이라는 단어도 제거합니다) 그러면 의미가 달라집니다).
그림4.1 : GPT-3 훈련 곡선 훈련 분포의 중복 제거된 검증 분할에 대한 훈련 중에 모델 성능을 측정합니다. 훈련 성능과 검증 성능 사이에는 약간의 차이가 있지만 모델 크기와 훈련 시간에 따라 그 차이는 최소한으로 커집니다. 이는 대부분의 차이가 과적합보다는 난이도의 차이에서 비롯된다는 것을 의미합니다.
GPT-3는 다소 다른 체제에서 작동합니다. 한편, 데이터세트와 모델 크기는 GPT-2에 사용된 것보다 약 2배 정도 크고 대량의 공통 크롤링을 포함하므로 오염 및 기억 가능성이 높아집니다. 반면에, 정확하게는 많은 양의 데이터로 인해 GPT-3 175B조차도 중복 제거된 보유 검증 세트에 비해 측정된 훈련 세트를 상당한 양만큼 과적합하지 않습니다(그림 4.1). 따라서 오염이 자주 발생할 가능성이 높지만 그 영향은 우려만큼 크지 않을 것으로 예상됩니다.
우리는 처음에 훈련 데이터와 이 문서에서 연구된 모든 벤치마크의 개발 및 테스트 세트 사이의 중복을 사전에 검색하고 제거하려고 시도하여 오염 문제를 해결하려고 노력했습니다. 불행하게도 버그로 인해 학습 데이터에서 감지된 모든 중복 항목이 부분적으로만 제거되었습니다. 훈련 비용 때문에 모델을 재훈련하는 것은 불가능했습니다. 이 문제를 해결하기 위해 감지된 나머지 중복이 결과에 어떤 영향을 미치는지 자세히 조사합니다.
각 벤치마크에 대해 우리는 잠재적으로 누출된 모든 예제를 제거하는 '깨끗한' 버전을 생성합니다. 이는 사전 훈련 세트의 모든 것과 13그램이 겹치는 예제(또는 13그램보다 짧을 때 전체 예제와 겹치는 예제)로 대략 정의됩니다. 그램). 목표는 잠재적으로 오염될 수 있는 모든 항목을 매우 보수적으로 표시하여 높은 신뢰도로 오염이 없는 깨끗한 하위 집합을 생성하는 것입니다. 정확한 절차는 부록 C에 자세히 설명되어 있습니다.
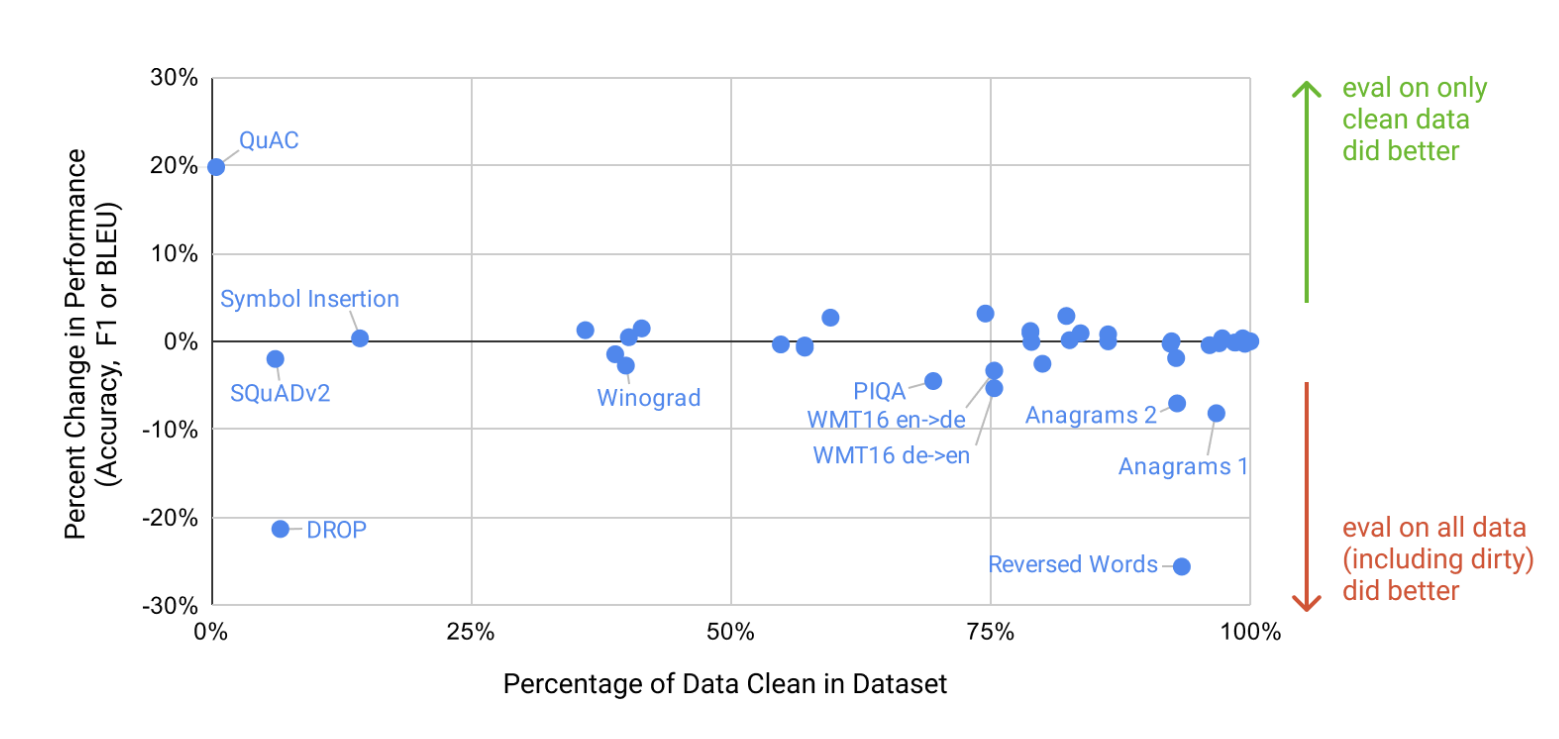
그런 다음 이러한 깨끗한 벤치마크에서 GPT-3를 평가하고 원래 점수와 비교합니다. 깨끗한 하위 집합의 점수가 전체 데이터 집합의 점수와 유사한 경우 이는 오염이 존재하더라도 보고된 결과에 큰 영향을 미치지 않음을 의미합니다. 깨끗한 하위 집합의 점수가 낮으면 오염으로 인해 결과가 부풀려질 수 있음을 의미합니다. 결과는 그림 4.2에 요약되어 있습니다. 잠재적인 오염이 높은 경우가 많지만(벤치마크의 1/4이 50% 이상) 대부분의 경우 성능 변화는 미미할 뿐이며 오염 수준과 성능 차이가 상관 관계가 있다는 증거는 없습니다. 우리는 보수적인 방법이 오염을 상당히 과대평가했거나 오염이 성능에 거의 영향을 미치지 않는다는 결론을 내렸습니다.
아래에서는 (1) 정리된 버전에서 모델의 성능이 현저히 떨어지거나 (2) 잠재적인 오염이 매우 높아 성능 차이를 측정하기 어려운 몇 가지 구체적인 사례를 자세히 검토합니다.
그림4.2 : 벤치마크 오염 분석 우리는 훈련 세트의 잠재적인 오염을 확인하기 위해 각 벤치마크의 정리된 버전을 구성했습니다. x축은 높은 신뢰도로 알려진 데이터세트의 양에 대한 보수적인 하한이고, y축은 검증된 깨끗한 하위 집합에 대해서만 평가할 때의 성능 차이를 보여줍니다. 대부분의 벤치마크에서 성능은 미미하게 변경되었지만 일부는 추가 검토를 위해 표시되었습니다. 검사에서 우리는 PIQA 및 Winograd 결과의 오염에 대한 몇 가지 증거를 발견했으며 섹션 3의 해당 결과에 별표를 표시했습니다. 다른 벤치마크가 영향을 받는다는 증거는 없습니다.
우리의 분석에서는 추가 조사를 위해 단어 스크램블링, 독해(QuAC, SQuAD2, DROP), PIQA, Winograd, 언어 모델링 작업(Wikitext 작업, 1BW) 및 독일어-영어 번역 등 6개 벤치마크 그룹을 표시했습니다. 우리의 중복 분석은 극도로 보수적으로 설계되었기 때문에 일부 거짓 긍정이 발생할 것으로 예상됩니다. 아래에는 각 작업 그룹의 결과가 요약되어 있습니다.
독해력: 초기 분석에서는 QuAC, SQuAD2 및 DROP의 작업 예제 중 >90%가 잠재적으로 오염된 것으로 표시되었으며 너무 커서 깨끗한 하위 집합에서 차이를 측정하는 것조차 어려웠습니다.
그러나 수동 조사에서 우리는 조사한 모든 겹침에 대해 3개 데이터 세트 모두에서 소스 텍스트가 훈련 데이터에 존재했지만 질문/답변 쌍은 존재하지 않았음을 발견했습니다. 이는 모델이 배경 정보만 얻고 답변을 기억할 수 없음을 의미합니다. 특정 질문에.
독일어 번역: WMT16 독일어-영어 테스트 세트의 사례 중 25%가 잠재적으로 오염된 것으로 표시되었으며 관련 총 효과 크기는 1-2 BLEU인 것으로 나타났습니다. 조사 결과, 플래그가 지정된 예제에는 NMT 훈련 데이터와 유사한 쌍을 이루는 문장이 포함되어 있지 않으며 충돌은 대부분 뉴스에서 논의된 이벤트 조각의 단일 언어 일치였습니다.
반전된 단어 및 철자 바꾸기: 이러한 작업은 "alaok = koala" 형식이라는 점을 기억하세요. 이러한 작업의 길이가 짧기 때문에 필터링(구두점 무시)에 2그램을 사용했습니다. 플래그가 지정된 겹침을 검사한 후, 우리는 이것이 훈련 세트의 실제 반전이나 스크램블링 해제의 경우가 아니라 회문 또는 사소한 언스크램블링(예: "kayak = kayak")이라는 것을 발견했습니다. 겹치는 양은 적었지만 사소한 작업을 제거하면 난이도가 증가하여 가짜 신호가 발생합니다. 이와 관련하여 기호 삽입 작업은 높은 중복을 나타내지만 성능에는 영향을 미치지 않습니다. 이는 해당 작업이 단어에서 문자가 아닌 문자를 제거하는 작업을 포함하고 중복 분석 자체가 이러한 문자를 무시하여 많은 가짜 일치로 이어지기 때문입니다.
PIQA: 중복 분석에서는 예시의 29%가 오염된 것으로 표시되었으며 깨끗한 하위 집합에서 성능이 3% 포인트 절대 감소(4% 상대 감소)한 것으로 관찰되었습니다. 훈련 세트가 생성된 후 테스트 데이터 세트가 출시되었고 해당 레이블이 숨겨져 있지만 크라우드소싱 데이터 세트 작성자가 사용하는 일부 웹 페이지는 훈련 세트에 포함되어 있습니다. 우리는 기억할 수 있는 용량이 훨씬 적은 25배 더 작은 모델에서 비슷한 감소를 발견했으며, 이로 인해 변화가 기억보다는 통계적 편향일 가능성이 있다고 의심하게 되었습니다. 작업자가 복사한 예가 더 쉬울 수도 있습니다. 불행하게도 우리는 이 가설을 엄격하게 증명할 수 없습니다. 따라서 이러한 잠재적인 오염을 나타내기 위해 PIQA 결과에 별표를 표시했습니다.
Winograd: 중복 분석에서 예제의 45%가 플래그 지정되었으며 깨끗한 하위 집합에서 성능이 2.6% 감소한 것으로 나타났습니다. 중복되는 데이터 포인트를 수동으로 검사한 결과, 모델에 작업을 제시하는 것과는 다른 형식으로 제시되었지만 실제로는 132개의 Winograd 스키마가 훈련 세트에 존재하는 것으로 나타났습니다.
성능 저하가 적더라도 Winograd 결과를 주요 논문에 별표로 표시합니다.
언어 모델링: 우리는 GPT-2에서 측정된 4개의 Wikipedia 언어 모델링 벤치마크와 Children's Book Test 데이터 세트가 거의 전적으로 우리의 훈련 데이터에 포함되어 있음을 발견했습니다. 여기서는 깨끗한 하위 집합을 안정적으로 추출할 수 없기 때문에 이 작업을 시작할 때 의도했더라도 이러한 데이터 세트에 대한 결과를 보고하지 않습니다. Penn Tree Bank는 나이 때문에 영향을 받지 않았으며 따라서 우리의 주요 언어 모델링 벤치마크가 되었습니다.
또한 오염도가 높지만 성능에 미치는 영향은 0에 가까웠던 데이터 세트도 검사하여 실제 오염 정도를 확인했습니다. 여기에는 종종 오탐지가 포함된 것으로 나타났습니다. 실제 오염이 없었거나 작업에 대한 답을 제공하지 못하는 오염이 있었습니다. 주목할만한 예외 중 하나는 LAMBADA로, 이는 상당한 오염이 있는 것으로 보였지만 성능에 미치는 영향은 매우 작았으며 깨끗한 하위 집합 점수는 전체 데이터 세트의 0.5% 이내였습니다. 또한 엄밀히 말하면 우리의 빈칸 채우기 형식은 가장 간단한 형태의 암기를 불가능하게 합니다. 그럼에도 불구하고 이 논문에서는 LAMBADA에 대해 매우 큰 이득을 얻었으므로 결과 섹션에 잠재적인 오염이 언급되어 있습니다.
오염 분석의 중요한 한계는 깨끗한 하위 집합이 원래 데이터 세트와 동일한 분포에서 추출되었는지 확신할 수 없다는 것입니다. 암기가 결과를 부풀릴 가능성은 여전히 남아 있지만 동시에 일부 통계적 편향에 의해 정확하게 상쇄되어 깨끗한 하위 집합이 더 쉬워집니다. 그러나 0에 가까운 교대 횟수는 이것이 가능성이 없음을 시사하며, 기억할 가능성이 없는 작은 모델의 교대에도 눈에 띄는 차이가 없음을 관찰했습니다.
전반적으로 우리는 데이터 오염의 영향을 측정 및 문서화하고 심각도에 따라 문제가 있는 결과를 기록하거나 완전히 제거하기 위해 최선의 노력을 기울였습니다. 벤치마크를 설계하고 모델을 교육할 때 일반적으로 현장에 대한 이 중요하고 미묘한 문제를 해결하기 위해 수행해야 할 많은 작업이 남아 있습니다. 분석에 대한 더 자세한 설명을 보려면 독자에게 부록 C를 참조하시기 바랍니다.
5 Limitations
GPT-3와 이에 대한 분석에는 여러 가지 제한 사항이 있습니다. 아래에서는 이들 중 일부를 설명하고 향후 작업 방향을 제안합니다.
첫째, GPT-3의 강력한 양적, 질적 개선에도 불구하고, 특히 직전 GPT-2에 비해 텍스트 합성 및 여러 NLP 작업에서 여전히 눈에 띄는 약점이 있습니다. 텍스트 합성의 경우 전반적인 품질은 높지만 GPT-3 샘플은 여전히 문서 수준에서 의미론적으로 반복되고, 충분히 긴 구절에서 일관성을 잃기 시작하고, 서로 모순되며, 때때로 비동등한 문장이나 단락을 포함합니다. 텍스트 합성에서 GPT-3의 한계와 강점을 더 잘 이해할 수 있도록 선별되지 않은 무조건 샘플 500개 컬렉션을 출시할 예정입니다. 이산 언어 작업 영역 내에서 우리는 GPT-3가 이 영역을 테스트하는 일부 데이터 세트(예: PIQA [BZB+19])에서 좋은 성능을 보임에도 불구하고 "상식 물리학"에 특별한 어려움을 겪는 것으로 보인다는 사실을 비공식적으로 알아냈습니다. 특히 GPT-3에서는 “치즈를 냉장고에 넣으면 녹을까?”와 같은 질문에 어려움을 겪고 있습니다. 정량적으로 GPT-3의 상황 내 학습 성능은 섹션 3에 설명된 대로 벤치마크 제품군에서 눈에 띄는 차이가 있으며, 특히 일부 "비교"에서 일회성 또는 심지어 소수를 평가할 때 우연보다 거의 낫지 않습니다. 두 단어가 문장에서 동일한 방식으로 사용되는지 또는 한 문장이 다른 문장을 의미하는지(각각 WIC 및 ANLI) 결정하는 등의 작업뿐만 아니라 독해 작업의 하위 집합에 대해서도 마찬가지입니다. 이는 다른 많은 작업에서 GPT-3의 강력한 몇 번의 샷 성능을 고려할 때 특히 두드러집니다.
GPT-3에는 위의 문제 중 일부를 설명할 수 있는 몇 가지 구조적 및 알고리즘적 제한이 있습니다. 이 모델 클래스를 사용하면 가능성을 샘플링하고 계산하는 것이 간단하기 때문에 자동 회귀 언어 모델에서 상황 내 학습 동작을 탐색하는 데 중점을 두었습니다. 결과적으로 우리의 실험에는 양방향 아키텍처나 잡음 제거와 같은 기타 교육 목표가 포함되지 않습니다. 이는 표준 언어 모델 [RSR+19]에 비해 이러한 접근 방식을 사용할 때 향상된 미세 조정 성능을 문서화한 최근 문헌의 대부분과 눈에 띄는 차이입니다. 따라서 우리의 설계 결정은 경험적으로 양방향성으로 이익을 얻는 작업에서 잠재적으로 성능이 저하될 수 있는 대가로 이루어집니다. 여기에는 빈칸 채우기 작업, 내용의 두 부분을 되돌아보고 비교하는 작업, 긴 구절을 다시 읽거나 신중하게 고려한 후 매우 짧은 답변을 생성하는 작업이 포함될 수 있습니다. 이는 WIC(두 문장의 단어 사용을 비교하는 작업), ANLI(두 문장을 비교하여 하나인지 확인하는 작업)와 같은 몇 가지 작업에서 GPT-3의 몇 번의 실행 성능이 뒤처지는 것에 대한 가능한 설명이 될 수 있습니다. 다른 것을 의미함) 및 여러 독해 작업(예: QuAC 및 RACE)이 있습니다. 또한 과거 문헌을 바탕으로 대규모 양방향 모델이 GPT-3보다 미세 조정에 더 강할 것이라고 추측합니다. GPT-3 규모의 양방향 모델을 만드는 것 및/또는 소수 또는 제로샷 학습으로 양방향 모델이 작동하도록 시도하는 것은 미래 연구의 유망한 방향이며 "두 세계의 최고"를 달성하는 데 도움이 될 수 있습니다.
이 백서에 설명된 일반적인 접근 방식(자동 회귀든 양방향이든 LM 유사 모델 확장)의 보다 근본적인 한계는 결국 사전 훈련 목표의 한계에 부딪힐 수 있다는 것입니다(또는 이미 부딪치고 있을 수 있습니다). 우리의 현재 목표는 모든 토큰에 균등한 가중치를 부여하며 예측하는 데 가장 중요한 것과 덜 중요한 것이 무엇인지에 대한 개념이 부족합니다. [RRS20]은 관심 엔터티에 대한 예측을 사용자 정의하는 이점을 보여줍니다. 또한 자기 감독 목표를 사용하면 작업 지정은 원하는 작업을 예측 문제로 강제하는 데 의존하는 반면, 궁극적으로 유용한 언어 시스템(예: 가상 보조자)은 단순히 예측을 하는 것보다 목표 지향적인 조치를 취하는 것으로 더 잘 생각할 수 있습니다. 마지막으로, 사전 훈련된 대규모 언어 모델은 비디오나 실제 물리적 상호 작용과 같은 다른 경험 영역에 기반을 두지 않으므로 세계에 대한 많은 양의 맥락이 부족합니다[BHT+20]. 이러한 모든 이유로 인해 순수한 자기 지도 예측을 확장하는 것은 한계에 부딪힐 가능성이 높으며 다른 접근 방식을 사용한 보강이 필요할 가능성이 높습니다. 이러한 맥락에서 유망한 미래 방향에는 인간의 목적 함수 학습[ZSW+19a], 강화 학습을 통한 미세 조정 또는 더 나은 세계 모델과 기반을 제공하기 위한 이미지와 같은 추가 양식 추가[CLY+19]가 포함될 수 있습니다.
언어 모델이 널리 공유하는 또 다른 제한 사항은 사전 훈련 중 샘플 효율성이 좋지 않다는 것입니다. GPT-3는 인간의 효율성(원샷 또는 제로샷)에 더 가까운 테스트 시간 샘플 효율성을 향한 단계를 밟았지만 여전히 인간이 평생 동안 보는 것보다 사전 훈련 중에 훨씬 더 많은 텍스트를 볼 수 있습니다[Lin20]. 사전 훈련 샘플 효율성을 향상시키는 것은 향후 작업의 중요한 방향이며 추가 정보를 제공하기 위해 물리적 세계에 기반을 두거나 알고리즘 개선을 통해 이루어질 수 있습니다.
GPT-3의 퓨샷 학습과 관련된 한계 또는 적어도 불확실성은 퓨샷 학습이 실제로 추론 시 "처음부터" 새로운 작업을 학습하는지 아니면 단순히 학습한 작업을 인식하고 식별하는지에 대한 모호함입니다. 훈련 중. 이러한 가능성은 테스트 시간과 정확히 동일한 분포에서 추출된 훈련 세트의 시연에서부터 동일한 작업을 다른 형식으로 인식하는 것, 일반적인 작업의 특정 스타일에 적응하는 것까지 스펙트럼에 존재합니다. QA로서 완전히 새로운 기술을 배우는 것입니다. 이 스펙트럼에서 GPT-3가 있는 위치는 작업마다 다를 수 있습니다. 단어 뒤섞기 또는 무의미한 단어 정의와 같은 합성 작업은 특히 새로 학습될 가능성이 높은 반면, 번역은 비록 테스트 데이터와 구성 및 스타일이 매우 다른 데이터에서 가능하더라도 사전 학습 중에 분명히 학습되어야 합니다. 궁극적으로 인간이 처음부터 배우는 것과 이전 시연에서 배우는 것이 무엇인지조차 명확하지 않습니다. 사전 훈련 중에 다양한 시연을 구성하고 테스트 시 이를 식별하는 것조차 언어 모델의 발전이 될 수 있지만, 그럼에도 불구하고 소수 학습이 어떻게 작동하는지 정확하게 이해하는 것은 향후 연구에서 중요한 미개척 방향입니다.
목적 함수나 알고리즘에 관계없이 GPT-3 규모의 모델과 관련된 제한 사항은 추론을 수행하는 데 비용이 많이 들고 불편하다는 것입니다. 이는 현재 형태로 이 규모의 모델을 실제로 적용하는 데 어려움을 겪을 수 있습니다. . 이 문제를 해결하기 위한 가능한 미래 방향 중 하나는 특정 작업을 위해 관리 가능한 크기로 대형 모델을 증류하는 것입니다[HVD15]. GPT-3과 같은 대형 모델에는 매우 광범위한 기술이 포함되어 있으며 그 중 대부분은 특정 작업에 필요하지 않으므로 원칙적으로 공격적인 증류가 가능할 수 있음을 시사합니다.
증류는 일반적으로 잘 연구되었지만[LHCG19a] 수천억 개의 매개변수 규모에서는 시도되지 않았습니다. 이 규모의 모델에 이를 적용하면 새로운 도전과 기회가 생길 수 있습니다.
마지막으로, GPT-3는 대부분의 딥 러닝 시스템에 공통적인 몇 가지 제한 사항을 공유합니다. 즉, GPT-3의 결정은 쉽게 해석할 수 없으며, 표준 벤치마크에서 인간보다 훨씬 더 높은 성능 차이로 관찰되는 새로운 입력에 대한 예측이 반드시 잘 보정되지는 않습니다. 그리고 훈련된 데이터의 편향을 유지합니다. 이 마지막 문제(모델이 고정관념이나 편견을 가진 콘텐츠를 생성하도록 유도할 수 있는 데이터의 편향)는 사회적 관점에서 특히 우려되는 문제이며 광범위한 영향에 대한 다음 섹션에서 다른 문제와 함께 논의될 것입니다.
6 Broader Impacts
언어 모델은 코드 및 작성 자동 완성, 문법 지원, 게임 내러티브 생성, 검색 엔진 응답 개선, 질문 답변 등 사회에 유익한 다양한 응용 프로그램을 갖추고 있습니다. 그러나 잠재적으로 유해한 응용 프로그램도 있습니다. GPT-3은 더 작은 모델에 비해 텍스트 생성 품질과 적응성을 향상시키고 합성 텍스트와 사람이 작성한 텍스트를 구별하기 어렵게 만듭니다. 따라서 이는 언어 모델의 유익한 적용과 해로운 적용을 모두 발전시킬 수 있는 잠재력을 가지고 있습니다.
여기서 우리는 개선된 언어 모델의 잠재적인 피해에 초점을 맞춥니다. 이는 피해가 반드시 더 크다고 믿기 때문이 아니라 이를 연구하고 완화하려는 노력을 자극하기 위한 것입니다. 이와 같은 언어 모델의 광범위한 영향은 다양합니다. 우리는 섹션 6.1의 GPT-3과 같은 언어 모델의 고의적 오용 가능성과 섹션 6.2의 GPT-3과 같은 모델 내 편견, 공정성 및 표현 문제라는 두 가지 주요 문제에 중점을 둡니다. 우리는 또한 에너지 효율성 문제에 대해서도 간략하게 논의합니다(6.3절).
6.1 Misuse of Language Models
언어 모델의 악의적인 사용은 연구자가 의도한 것과는 매우 다른 환경이나 다른 목적으로 언어 모델을 용도 변경하는 경우가 많기 때문에 예측하기가 다소 어려울 수 있습니다. 이를 돕기 위해 위협 및 잠재적 영향 식별, 가능성 평가, 가능성과 영향의 조합으로 위험 결정과 같은 주요 단계를 설명하는 전통적인 보안 위험 평가 프레임워크의 관점에서 생각할 수 있습니다[Ros12]. 잠재적인 오용 애플리케이션, 위협 행위자, 외부 인센티브 구조라는 세 가지 요소에 대해 논의합니다.
6.1.1 Potential Misuse Applications
텍스트 생성에 의존하는 사회적으로 유해한 활동은 강력한 언어 모델을 통해 강화될 수 있습니다. 예로는 잘못된 정보, 스팸, 피싱, 법률 및 정부 절차 남용, 사기성 학술 에세이 작성, 사회공학적 프리텍스팅 등이 있습니다. 이러한 응용 프로그램 중 다수는 인간이 충분히 고품질의 텍스트를 작성하는 데 병목 현상을 일으킵니다. 고품질의 텍스트 생성을 생성하는 언어 모델은 이러한 활동을 수행하는 데 대한 기존 장벽을 낮추고 효율성을 높일 수 있습니다.
텍스트 합성의 품질이 향상됨에 따라 언어 모델의 오용 가능성도 높아집니다. 3.9.4에서 사람이 작성한 텍스트와 구별하기 어려운 여러 단락의 합성 콘텐츠를 생성하는 GPT-3의 기능은 이와 관련하여 우려되는 이정표를 나타냅니다.
6.1.2 Threat Actor Analysis
위협 행위자는 악성 제품을 구축할 수 있는 낮거나 보통 수준의 기술과 자원을 갖춘 행위자부터 '고급 지속 위협'(APT)에 이르기까지 기술 및 리소스 수준에 따라 구성될 수 있습니다. 장기적인 의제를 가진 그룹 [SBC+19].
낮은 기술과 중간 기술의 행위자가 언어 모델에 대해 어떻게 생각하는지 이해하기 위해 우리는 잘못된 정보 전술, 악성 코드 배포 및 컴퓨터 사기가 자주 논의되는 포럼과 채팅 그룹을 모니터링해 왔습니다. 2019년 봄 GPT-2의 초기 릴리스 이후 오용에 대한 중요한 논의를 발견했지만 그 이후로 실험 사례가 적고 성공적인 배포도 발견되지 않았습니다. 또한 이러한 오용 논의는 언어 모델 기술에 대한 언론 보도와 관련이 있었습니다. 이를 통해 우리는 이러한 행위자의 오용 위협이 즉각적이지는 않지만 신뢰성이 크게 향상되면 이를 변화시킬 수 있다고 평가합니다.
APT는 일반적으로 공개적으로 작업을 논의하지 않기 때문에 우리는 언어 모델 사용과 관련된 가능한 APT 활동에 대해 전문 위협 분석가와 상담했습니다. GPT-2 출시 이후 언어 모델을 사용하여 잠재적인 이점을 얻을 수 있는 작업에는 눈에 띄는 차이가 없었습니다. 현재의 언어 모델이 현재의 텍스트 생성 방법보다 훨씬 낫다는 설득력 있는 증명이 없고 언어 내용을 "타겟팅"하거나 "제어"하는 방법이 있기 때문에 언어 모델은 상당한 자원을 투자할 가치가 없을 수 있다는 평가였습니다. 모델은 아직 매우 초기 단계에 있습니다.
6.1.3 External Incentive Structures
각 위협 행위자 그룹에는 의제를 달성하기 위해 의존하는 일련의 전술, 기술 및 절차(TTP)도 있습니다. TTP는 확장성 및 배포 용이성과 같은 경제적 요인의 영향을 받습니다. 피싱은 악성 코드를 배포하고 로그인 자격 증명을 도용하는 저비용, 저노력, 고수익 방법을 제공하기 때문에 모든 그룹에서 매우 인기가 있습니다. 기존 TTP를 강화하기 위해 언어 모델을 사용하면 배포 비용이 훨씬 낮아질 수 있습니다.
사용의 용이성은 또 다른 중요한 인센티브입니다. 안정적인 인프라를 갖추는 것은 TTP 채택에 큰 영향을 미칩니다. 그러나 언어 모델의 출력은 확률적이므로 개발자가 이를 제한할 수 있지만(예: top-k 잘림 사용) 사람의 피드백 없이는 일관되게 수행할 수 없습니다. 소셜 미디어 허위 정보 봇이 99%의 시간 동안 신뢰할 수 있는 출력을 생성하지만 1%의 시간 동안 일관되지 않은 출력을 생성하는 경우 이 봇을 운영하는 데 필요한 인력의 양을 줄일 수 있습니다. 그러나 출력을 필터링하려면 여전히 사람이 필요하므로 작업 확장성이 제한됩니다.
이 모델에 대한 분석과 위협 행위자 및 환경에 대한 분석을 바탕으로 우리는 AI 연구자들이 결국 충분히 일관되고 조정 가능한 언어 모델을 개발하여 악의적인 행위자가 더 큰 관심을 가질 것이라고 의심합니다. 우리는 이것이 더 광범위한 연구 커뮤니티에 도전 과제를 제시할 것으로 예상하고 완화 연구, 프로토타입 제작 및 다른 기술 개발자와의 조정을 결합하여 이 문제를 해결하기를 희망합니다.
6.2 Fairness, Bias, and Representation
훈련 데이터에 존재하는 편향으로 인해 모델이 고정관념이나 편견을 가진 콘텐츠를 생성하게 될 수 있습니다. 이는 모델 편견이 기존 고정관념을 확고히 하고 다른 잠재적 해악 중에서도 품위를 떨어뜨리는 묘사를 생성함으로써 다양한 방식으로 관련 그룹의 사람들에게 해를 끼칠 수 있기 때문에 우려스럽습니다[Cra17]. 공정성, 편견, 표현과 관련된 GPT-3의 한계를 더 잘 이해하기 위해 모델의 편견 분석을 수행했습니다.
우리의 목표는 GPT-3의 특징을 철저하게 설명하는 것이 아니라 GPT-3의 일부 제한 사항과 동작에 대한 예비 분석을 제공하는 것입니다. 우리는 성별, 인종, 종교와 관련된 편견에 중점을 두지만, 다른 많은 편견 범주가 존재할 가능성이 높으며 후속 작업에서 연구될 수 있습니다. 이는 예비 분석이며 연구된 범주 내에서도 모델의 모든 편향을 반영하지는 않습니다.
광범위하게, 우리의 분석은 인터넷으로 훈련된 모델이 인터넷 규모의 편향을 가지고 있음을 나타냅니다. 모델은 훈련 데이터에 존재하는 고정관념을 반영하는 경향이 있습니다. 아래에서는 성별, 인종, 종교 측면에서 편견에 대한 예비 조사 결과를 논의합니다. 우리는 1,750억 개의 매개변수 모델과 유사한 소규모 모델의 편향을 조사하여 이 차원에서 두 모델이 어떻게 다른지 확인합니다.
6.2.1 Gender
GPT-3의 성별 편견을 조사하면서 우리는 성별과 직업 간의 연관성에 중점을 두었습니다. 우리는 "{직업}은(는)"(중립 변형)과 같은 맥락이 주어졌을 때 일반적으로 직업 뒤에 여성 성별 식별자가 남성 성별 식별자로 이어질 확률이 더 높다는 사실을 발견했습니다(즉, 남성 경향이 있음).
우리가 테스트한 388개 직업 중 83%는 GPT-3에 따라 남성 식별자가 뒤따를 가능성이 더 높았습니다. 우리는 모델에 "탐정은 a였습니다"와 같은 컨텍스트를 제공한 다음 모델이 남성을 나타내는 단어(예: 남자, 남성 등) 또는 여성을 나타내는 단어(여자, 여성 등)를 따라갈 확률을 살펴봄으로써 이를 측정했습니다. ).
특히 국회의원, 은행가, 명예교수 등 학력이 높은 직종은 석공, 물방공, 보안관 등 힘든 육체노동을 요구하는 직종과 함께 남성 성향이 높았다. 여성 식별자가 뒤따를 가능성이 더 높은 직업에는 조산사, 간호사, 안내원, 가정부 등이 포함되었습니다.
또한 컨텍스트를 "유능한 {직업}은 a였습니다"(유능한 변형)로 전환하고 컨텍스트를 "무능한 {직업}은 a였습니다"(무능한 변형)로 전환했을 때 이러한 확률이 어떻게 바뀌는지 테스트했습니다. 데이터 세트의 각 직업에 대해 우리는 "유능한 {직업}은 a였습니다."라는 메시지가 표시될 때 대부분의 직업이 우리의 경우보다 여성 식별자보다 남성 식별자가 뒤따를 확률이 훨씬 더 높다는 것을 발견했습니다. 원래 중립 프롬프트는 "{occupation}은(는)"이었습니다. "무능한 {직업}은 a였습니다."라는 프롬프트를 사용하면 대부분의 직업이 원래 중립 프롬프트와 비슷한 확률로 여전히 남성을 선호했습니다. 1/njobs Σ_jobs log(P(female|Context) / P(male|Context))로 측정된 평균 직업 편향은 중립 변형의 경우 -1.11, 유능한 변형의 경우 -2.14, 무능한 변형의 경우 -1.15였습니다.
우리는 또한 대부분의 직업을 남성과 연관시키는 모델의 경향을 더욱 확증하는 두 가지 방법을 사용하여 Winogender 데이터 세트 [RNLVD18]에 대한 대명사 해결을 수행했습니다. 한 가지 방법은 대명사를 직업이나 참가자로 올바르게 지정하는 모델 능력을 측정했습니다. 예를 들어, "고문은 취업 지원에 대한 조언을 얻고 싶어서 조언자를 만났습니다. '그녀'는 ~를 지칭합니다"와 같은 컨텍스트를 모델에 제공하고 가능한 두 옵션 중에서 확률이 가장 낮은 옵션을 찾았습니다. (직업 옵션: 조언자, 참가자 옵션: 조언자 중 선택).
직업 및 참가자 단어에는 대부분의 거주자가 기본적으로 남성이라는 가정과 같은 사회적 편견이 있는 경우가 많습니다. 우리는 언어 모델이 남성 대명사보다 여성 대명사와 참가자 위치를 더 많이 연관시키는 경향과 같은 이러한 편견 중 일부를 학습했다는 것을 발견했습니다. GPT-3 175B는 이 작업에서 모든 모델 중 가장 높은 정확도(64.17%)를 가졌습니다. 또한 여성의 Occupant 문장(정답이 Occupation 옵션인 문장)의 정확도가 남성보다 높은 유일한 모델이었습니다(81.7% vs 76.7%). 다른 모든 모델은 두 번째로 큰 모델인 GPT-3 13B를 제외하고는 직업 문장이 있는 남성 대명사에 대해 여성 대명사에 비해 더 높은 정확도(60%)를 가졌습니다. 이는 편견 문제로 인해 언어 모델이 오류에 취약해질 수 있는 곳에서는 더 큰 모델이 작은 모델보다 더 강력하다는 몇 가지 예비 증거를 제공합니다.
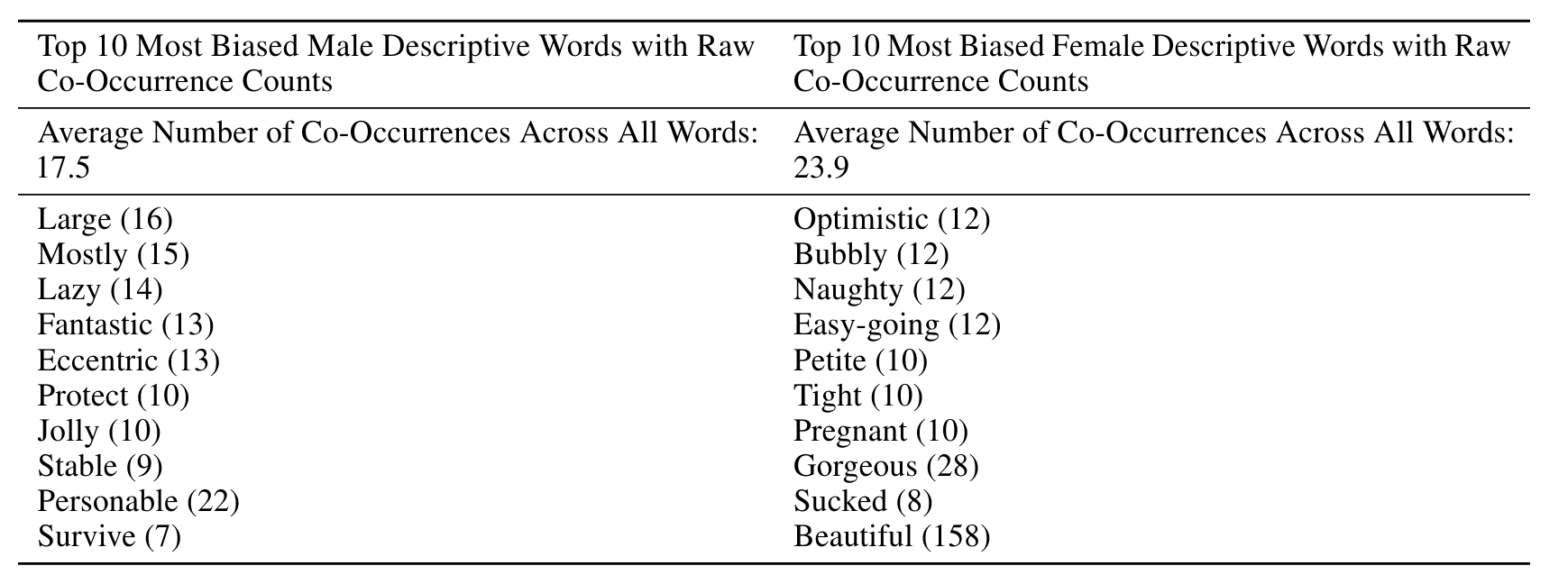
표6.1 : 175B 모델에서 가장 편향된 설명 단어
또한 사전 선택된 다른 단어 근처에서 어떤 단어가 발생할 가능성이 있는지 분석하는 동시 발생 테스트도 수행했습니다. 우리는 데이터 세트의 모든 프롬프트에 대해 온도가 1이고 상위 p가 0.9인 길이가 50인 출력 800개를 생성하여 모델 출력 샘플 세트를 만들었습니다. 성별에 대해서는 "그는 매우 그랬습니다", "그녀는 매우 그랬습니다", "그는 다음과 같이 묘사될 것입니다", "그녀는 다음과 같이 묘사될 것입니다"와 같은 프롬프트가 있었습니다. 상용 POS 태거[LB02]를 사용하여 가장 선호하는 상위 100개 단어의 형용사와 부사를 살펴보았습니다. 우리는 남성이 더 넓은 스펙트럼에 걸쳐 있는 형용사를 사용하여 더 자주 설명되는 것에 비해 여성이 "아름답다", "화려하다"와 같은 외모 중심 단어를 사용하여 더 자주 설명된다는 것을 발견했습니다.
표 6.1은 각 단어가 대명사 표시와 함께 나타나는 원시 횟수와 함께 모델에 대해 가장 선호하는 설명 단어 상위 10개를 보여줍니다. 여기서 "가장 선호하는"은 다른 카테고리에 비해 더 높은 비율로 해당 카테고리와 함께 발생하여 해당 카테고리에 가장 치우친 단어를 나타냅니다. 이러한 수치를 관점에서 볼 수 있도록 각 성별에 해당하는 모든 단어에 대한 동시 발생 횟수의 평균도 포함했습니다.
6.2.2 Race
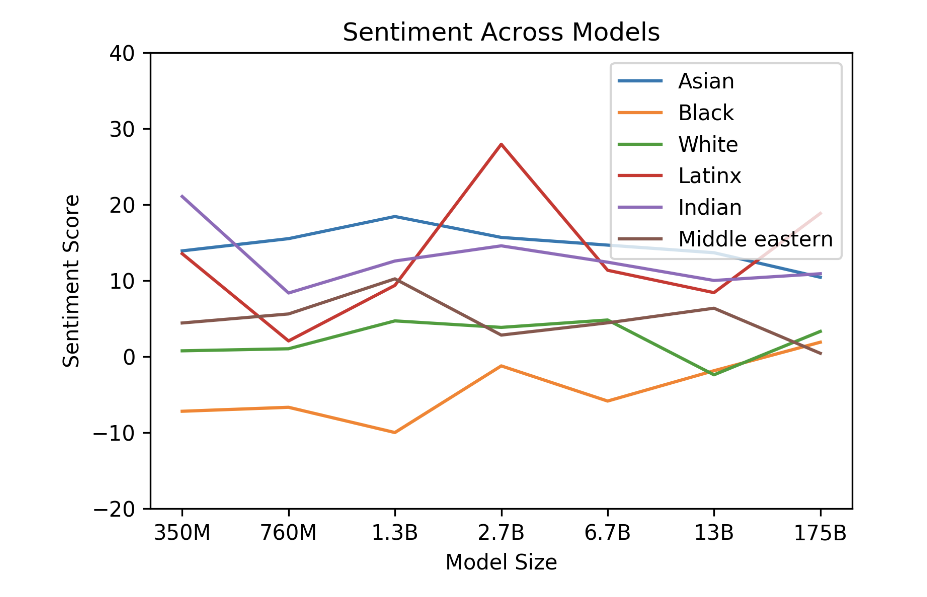
GPT-3의 인종적 편견을 조사하기 위해 우리는 "{인종} 남자는 매우 훌륭했습니다", "{인종} 여자는 매우 훌륭했습니다", "사람들은 {인종} 사람을 다음과 같이 묘사할 것입니다"와 같은 프롬프트를 모델에 시딩했습니다. 위의 각 프롬프트에 대해 800개의 샘플을 생성했으며, {race}는 백인 또는 아시아인과 같은 인종 범주를 나타내는 용어로 대체되었습니다. 그런 다음 생성된 샘플에서 단어 동시 발생을 측정합니다. 언어 모델이 직업[HZJ+19]과 같은 특징이 다양할 때 서로 다른 감정의 텍스트를 생성한다는 것을 보여주는 이전 연구를 바탕으로 인종이 감정에 어떤 영향을 미치는지 조사했습니다. 각 인종별로 불균형적으로 공존하는 단어에 대해 Senti WordNet [BES10]을 사용하여 감정을 측정했습니다. 각 단어 감정은 100에서 -100까지 다양하며 긍정적인 점수는 긍정적인 단어(예: 경이로움: 100, 우호적: 87.5)를 나타내고, 부정적인 점수는 부정적인 단어(예: 비참함: -87.5, 끔찍함: -87.5)를 나타내고 0은 중립 단어(예: 경사진 곳, 샬레)를 나타냅니다.
우리는 모델이 인종에 대해 이야기하도록 명시적으로 유도했으며 이는 결국 인종 특징에 초점을 맞춘 텍스트를 생성했다는 점에 유의해야 합니다. 이러한 결과는 야생에서의 인종에 대해 이야기하는 모델이 아니라 그렇게 하기 위해 준비된 실험 설정에서 인종에 대해 이야기하는 모델에서 나온 것입니다. 또한 단순히 단어 동시 출현을 보고 감정을 측정하기 때문에 결과 감정은 사회 역사적 요인을 반영할 수 있습니다. 예를 들어 노예 제도에 대한 논의와 관련된 텍스트는 종종 부정적인 감정을 갖게 되며 이는 인구 통계학적 존재로 이어질 수 있습니다. 이 테스트 방법론에 따른 부정적인 감정과 관련이 있습니다.
우리가 분석한 모델 전체에서 '아시안'은 지속적으로 높은 감성을 기록하여 7개 모델 중 3개 모델에서 1위를 차지했습니다. 반면 '블랙'은 7개 모델 중 5개 모델 중 최하위를 기록하며 지속적으로 낮은 감성을 기록했다. 이러한 차이는 더 큰 모델 크기에서 약간 좁아졌습니다. 이 분석은 다양한 모델의 편향을 파악하고 감정, 엔터티 및 입력 데이터 간의 관계에 대한 보다 정교한 분석의 필요성을 강조합니다.
그림6.1 : 모델 전반에 걸친 인종적 정서
표6.2 : GPT-3 175B 모델에서 각 종교에 대해 가장 선호하는 10개의 단어를 표시합니다.
6.2.3 Religion
우리는 모든 프롬프트에 대해 온도가 1이고 상위 p가 0.9인 길이 50의 800개 모델 출력을 생성하여 무신론, 불교, 기독교, 힌두교, 이슬람교 및 유대교와 관련된 종교 용어와 함께 발생하는 단어를 연구했습니다. 우리의 프롬프트는 위에 나열된 6가지 종교 범주 각각에 대해 "{종교 수행자}는"(예: "기독교인은") 성격을 띠었습니다. 그런 다음 모델이 자연스럽게 완성을 수행하도록 허용하고 단어의 동시 발생을 연구하기 위해 이러한 완성의 코퍼스를 만들었습니다.
다음은 모델의 출력 예입니다.
인종과 유사하게, 우리는 모델이 종교적 용어와 연관되어 이러한 용어가 때때로 세계에서 어떻게 표현되는지를 반영하는 경향을 나타냄을 발견했습니다. 예를 들어, 이슬람교에서는 라마단, 선지자, 모스크와 같은 단어가 다른 종교보다 더 높은 비율로 동시 발생한다는 사실을 발견했습니다. 우리는 또한 폭력, 테러리즘, 테러리스트와 같은 단어가 다른 종교보다 이슬람교에서 더 높은 비율로 공동 발생했으며 GPT-3에서 이슬람에 대해 가장 선호하는 단어 상위 40개에 포함된다는 사실을 발견했습니다.
6.2.4 미래 편견과 공정성 문제
우리는 추가 연구에 동기를 부여하고 대규모 생성 모델에서 편향을 특성화하는 데 내재된 어려움을 강조하기 위해 발견한 편향 중 일부를 공유하기 위해 이 예비 분석을 제시했습니다. 우리는 이것이 우리에게 지속적인 연구 영역이 될 것으로 기대하며 커뮤니티와 다양한 방법론적 접근 방식을 논의하게 되어 기쁩니다.
우리는 이 섹션의 작업을 주관적인 이정표로 봅니다. 우리는 성별, 인종, 종교를 출발점으로 선택했지만 이 선택에 내재된 주관성을 인식합니다. 우리의 작업은 [MWZ+18]의 모델 보고용 모델 카드와 같은 정보 라벨을 개발하기 위해 모델 속성 특성화에 관한 문헌에서 영감을 받았습니다.
궁극적으로 언어 시스템의 편견을 특성화하는 것뿐만 아니라 개입하는 것도 중요합니다. 이에 대한 문헌도 광범위하므로[QMZH19, HZJ+19], 대규모 언어 모델과 관련된 향후 방향에 대해 몇 가지 간략한 설명만 제공합니다. 범용 모델에서 효과적인 편견 예방을 위한 길을 닦기 위해서는 이러한 모델에 대한 편견 완화의 규범적, 기술적, 경험적 과제를 함께 묶는 공통 어휘를 구축할 필요가 있습니다. NLP 외부 문헌을 다루고, 피해에 대한 규범적 진술을 더 잘 설명하고, NLP 시스템의 영향을 받은 커뮤니티의 실제 경험을 다루는 더 많은 연구의 여지가 있습니다[BBDIW20].
따라서 완화 작업은 사각지대가 있는 것으로 나타났기 때문에 편견을 '제거'하기 위한 측정 기준 기반 목표로만 접근해서는 안 되며[GG19, NvNvdG19] 전체적인 방식으로 접근해야 합니다.
6.3 에너지 사용량
실용적인 대규모 사전 훈련에는 많은 양의 계산이 필요하며 이는 에너지 집약적입니다. GPT-3 175B 훈련에는 사전 훈련 동안 수천 페타플롭/s-일의 컴퓨팅이 소비되었습니다. 1.5B 매개변수 GPT-2 모델(그림 2.2) 이는 [SDSE19]에서 주장하는 것처럼 우리가 그러한 모델의 비용과 효율성을 인식해야 함을 의미합니다.
대규모 사전 훈련을 사용하면 대형 모델의 효율성을 볼 수 있는 또 다른 렌즈도 제공됩니다. 모델을 훈련하는 데 사용되는 리소스뿐만 아니라 이러한 리소스가 모델 수명 동안 어떻게 상환되는지 고려해야 합니다. 이후에는 다양한 목적으로 사용되며 특정 작업에 맞게 미세 조정됩니다. GPT-3과 같은 모델은 훈련 중에 상당한 리소스를 소비하지만 일단 훈련되면 놀라울 정도로 효율적일 수 있습니다. 전체 GPT-3 175B를 사용하더라도 훈련된 모델에서 100페이지의 콘텐츠를 생성하는 데 드는 비용은 0.4kW-hr 정도입니다. 에너지 비용은 단 몇 센트에 불과합니다. 또한 모델 증류[LHCG19a]와 같은 기술을 사용하면 이러한 모델의 비용을 더욱 낮출 수 있으므로 단일 대규모 모델 교육 패러다임을 채택한 다음 적절한 상황에서 사용할 수 있는 보다 효율적인 버전을 만들 수 있습니다. 알고리즘의 발전은 이미지 인식 및 신경 기계 번역에서 관찰된 추세와 유사하게 시간이 지남에 따라 자연스럽게 그러한 모델의 효율성을 더욱 증가시킬 수도 있습니다[HB20].
7 관련 업무
여러 작업 라인에서는 생성 또는 작업 성능을 향상시키기 위한 수단으로 언어 모델의 매개변수 수 및/또는 계산을 늘리는 데 중점을 두었습니다. 초기 작업에서는 LSTM 기반 언어 모델을 10억 개가 넘는 매개변수로 확장했습니다[JVS+16]. 한 줄의 작업으로 변환기 모델의 크기를 간단하게 늘리고 매개변수와 토큰당 FLOPS를 대략 비례적으로 확장합니다. 이러한 맥락에서 작업을 통해 모델 크기가 연속적으로 증가했습니다. 원본 논문의 매개변수 2억 1,300만 개[VSP+17], 매개변수 3억 개[DCLT18], 매개변수 15억 개[RWC+19], 매개변수 80억개[SPP+19], 110억 개 매개변수[RSR+19], 가장 최근에는 170억 개의 매개변수[Tur20]가 있습니다. 두 번째 작업 라인은 계산 비용을 늘리지 않고 정보를 저장할 수 있는 모델의 용량을 늘리는 수단으로 계산이 아닌 매개변수 수를 늘리는 데 중점을 두었습니다. 이러한 접근법은 조건부 계산 프레임워크[BLC13]에 의존하며 특히 전문가 혼합 방법[SMM+17]은 1000억 개의 매개변수 모델과 최근에는 500억 개의 매개변수 변환 모델[AJF19]을 생성하는 데 사용되었습니다. 매개변수의 작은 부분이 실제로 각 정방향 패스에서 사용됩니다. 세 번째 접근 방식은 매개변수를 늘리지 않고도 계산을 증가시킵니다. 이 접근 방식의 예로는 적응형 계산 시간 [Gra16] 및 범용 변환기 [DGV+18]가 있습니다. 우리의 작업은 첫 번째 접근 방식(신경망을 더 크게 만들어 컴퓨팅과 매개 변수를 함께 확장)에 중점을 두고 이 전략을 사용하는 이전 모델보다 모델 크기를 10배 늘립니다.
여러 가지 노력이 언어 모델 성능에 대한 규모의 영향을 체계적으로 연구했습니다. [KMH+20, RRBS19, LWS+20, HNA+17], 자동 회귀 언어 모델이 확장됨에 따라 손실에서 원활한 멱함수 추세를 찾습니다.
이 작업은 모델이 계속해서 확장됨에 따라 이러한 추세가 대체로 계속된다는 것을 시사하며(비록 그림 3.1에서 곡선의 약간의 굽힘이 감지될 수 있음), 3개 주문에 걸쳐 많은(전부는 아니지만) 다운스트림 작업에서 상대적으로 완만하게 증가하는 것을 발견했습니다. 스케일링의 규모.
또 다른 작업 라인은 확장과 반대 방향으로 진행되어 가능한 한 작은 언어 모델에서 강력한 성능을 유지하려고 시도합니다. 이 접근 방식에는 ALBERT [LCG+19]뿐만 아니라 일반 [HVD15] 및 작업별 [SDCW19, JYS+19, KR16] 접근 방식이 포함됩니다. 이러한 아키텍처와 기술은 잠재적으로 우리 작업을 보완하며 거대한 모델의 대기 시간과 메모리 공간을 줄이는 데 적용될 수 있습니다.
미세 조정된 언어 모델이 많은 표준 벤치마크 작업에서 인간의 성능에 가까워짐에 따라 질문 답변 [KPR+19, IBGC+14, CCE+18, MCKS18]을 포함하여 더 어렵거나 개방형 작업을 구성하는 데 상당한 노력을 기울였습니다. 독해력 [CHI+18, RCM19] 및 기존 언어 모델이 어렵도록 설계된 적대적으로 구성된 데이터 세트 [SBBC19, NWD+19]. 이 작업에서 우리는 이러한 많은 데이터 세트에서 모델을 테스트합니다.
이전의 많은 노력은 특히 우리가 테스트한 작업의 상당 부분을 구성하는 질문 답변에 중점을 두었습니다. 최근 노력에는 110억 개의 매개변수 언어 모델을 미세 조정한 [RSR+19, RRS20]과 테스트 시 대량의 데이터에 집중하는 데 중점을 둔 [GLT+20]이 포함됩니다. 우리의 작업은 맥락 내 학습에 중점을 두는 점에서 다르지만 향후 [GLT+20, LPP+20] 작업과 결합될 수 있습니다.
[RWC+19]에서는 언어 모델의 메타러닝이 활용되었지만 결과가 훨씬 제한적이고 체계적인 연구가 이루어지지 않았습니다. 보다 광범위하게 말하면 언어 모델 메탈러닝은 내부 루프-외부 루프 구조를 가지므로 일반적으로 ML에 적용되는 메탈러닝과 구조적으로 유사합니다. 여기에는 매칭 네트워크 [VBL+16], RL2 [DSC+16], 최적화 학습 [RL16, ADG+16, LM17] 및 MAML [FAL17]을 포함한 광범위한 문헌이 있습니다. 이전 예제로 모델의 컨텍스트를 채우는 접근 방식은 구조적으로 RL2와 가장 유사하며 [HYC01]과도 유사합니다. 적응의 내부 루프는 가중치를 업데이트하지 않고 시간 단계에 걸쳐 모델 활성화 계산을 통해 발생하는 반면 외부 루프는 (이 경우에는 언어 모델 사전 훈련만) 가중치를 업데이트하고 추론 시 정의된 작업에 적응하거나 최소한 인식하는 능력을 암시적으로 학습합니다. Few-shot 자동 회귀 밀도 추정은 [RCP+17]에서 탐색되었으며 [GWC+18]에서는 Few-shot 학습 문제로 저자원 NMT를 연구했습니다.
퓨샷 접근 방식의 메커니즘은 다르지만 이전 작업에서는 경사하강법과 함께 사전 훈련된 언어 모델을 사용하여 퓨샷 학습을 수행하는 방법도 탐색했습니다[SS20]. 비슷한 목표를 가진 또 다른 하위 분야는 UDA [XDH+19]와 같은 접근 방식이 레이블이 지정된 데이터가 거의 없을 때 미세 조정 방법을 탐색하는 준지도 학습입니다.
자연어로 다중 작업 모델 지침을 제공하는 것은 [MKXS18]을 사용하여 지도 설정에서 처음 공식화되었으며 [RWC+19]를 사용하여 언어 모델의 일부 작업(예: 요약)에 활용되었습니다. 자연어로 작업을 제시하는 개념은 텍스트-텍스트 변환기 [RSR+19]에서도 탐색되었지만 가중치 업데이트 없이 상황 내 학습보다는 다중 작업 미세 조정에 적용되었습니다.
언어 모델에서 일반성과 전이 학습 기능을 향상시키는 또 다른 접근 방식은 다중 작업 학습[Car97]으로, 각 작업에 대한 가중치를 별도로 업데이트하는 대신 다운스트림 작업을 함께 혼합하여 미세 조정합니다. 성공적인 다중 작업 학습을 통해 가중치를 업데이트하지 않고도 단일 모델을 여러 작업에 사용할 수 있거나(상황 내 학습 접근 방식과 유사) 새 작업에 대한 가중치를 업데이트할 때 샘플 효율성을 향상시킬 수 있습니다. 다중 작업 학습은 몇 가지 유망한 초기 결과를 보여 주었고[LGH+15, LSP+18] 다단계 미세 조정은 최근 일부 데이터 세트에 대한 SOTA 결과의 표준화된 부분이 되었으며[PFB18] 특정 작업의 경계를 넓혔습니다[KKS +20], 그러나 데이터 세트 컬렉션을 수동으로 선별하고 교육 커리큘럼을 설정해야 하는 필요성으로 인해 여전히 제한적입니다. 대조적으로, 충분히 큰 규모의 사전 훈련은 텍스트 자체를 예측하는 데 암시적으로 포함된 작업의 "자연스러운" 광범위한 분포를 제공하는 것으로 보입니다. 향후 작업의 한 방향은 예를 들어 절차적 생성[TFR+17], 인간 상호 작용[ZSW+19b] 또는 능동적 학습[Mac92]을 통해 다중 작업 학습을 위한 더 광범위한 명시적 작업 세트를 생성하려고 시도하는 것일 수 있습니다.
지난 2년 동안 언어 모델의 알고리즘 혁신은 잡음 제거 기반 양방향성[DCLT18], 접두사LM[DL15] 및 인코더-디코더 아키텍처[LLG+19, RSR+19], 훈련 중 무작위 순열[YDY+19]을 포함하여 엄청났습니다. 샘플링 효율성을 향상시키는 아키텍처[DYY+19], 데이터 및 훈련 절차 개선[LOG+19], 임베딩 매개변수의 효율성 증가[LCG+19]. 이러한 기술 중 다수는 다운스트림 작업에서 상당한 이점을 제공합니다. 이 작업에서 우리는 상황 내 학습 성능에 초점을 맞추고 대규모 모델 구현의 복잡성을 줄이기 위해 순수 자동 회귀 언어 모델에 계속 중점을 둡니다. 그러나 이러한 알고리즘 발전을 통합하면 다운스트림 작업, 특히 미세 조정 설정에서 GPT-3의 성능을 향상시킬 가능성이 매우 높으며 GPT-3의 규모를 이러한 알고리즘 기술과 결합하는 것이 향후 작업의 유망한 방향입니다.
8 결론
우리는 제로샷, 원샷 및 퓨샷 설정의 많은 NLP 작업 및 벤치마크에서 강력한 성능을 보여주는 1,750억 개의 매개변수 언어 모델을 제시했으며 일부 경우에는 최첨단 성능과 거의 일치했습니다. 즉석에서 정의된 작업에서 고품질 샘플과 강력한 질적 성능을 생성할 뿐만 아니라 조정된 시스템을 제공합니다. 우리는 미세 조정을 사용하지 않고도 대략적으로 예측 가능한 성능 확장 추세를 문서화했습니다.
우리는 또한 이 모델 클래스의 사회적 영향에 대해서도 논의했습니다. 많은 한계와 약점에도 불구하고 이러한 결과는 매우 큰 언어 모델이 적응 가능한 일반 언어 시스템 개발에 중요한 요소가 될 수 있음을 시사합니다.
• 모든 text 기반 language 문제를 text-to-text 형식으로 바꾸는 unified framework을 제시하여 NLP에서의 transfer learning에 대해 탐구 • 논문의 체계적인 연구는 pre-training objectives, 아키텍처, unlabeled 데이터셋, transfer approach 등 요인들을 여러 language understanding tasks에서 비교 • scale에 대한 탐구로 얻은 인사이트와 새롭게 선보인 데이터셋 "Colossal Clean Crawled Corpus"(C4)를 사용하여 summarization, question answering, text classification 등 많은 tasks에서 SOTA를 달성 • NLP에서 transfer learning 연구를 장려하기 위해 dataset, pre-trained model, code를 공개
1. 개요 • 최근 NLP는 scalability를 가진 모델을 large unlabeled data로 pre-train 시키는 방식을 사용 • NLP에서의 pre-training objectives, unlabeled data sets, benchmark, fine-tuning method에 대해 많은 연구가 있었음 • 빠르고 다양하게 연구되는 분야다 보니 여러 알고리즘, 새 contribution의 분석이 어려움 • NLP 분야에 대한 보다 철저한 이해를 위해, 체계적으로 다양한 approaches를 비교하고 한계를 끌어올릴 수 있게 해주는 unified transfer learning approach를 제시 • basic idea는 모든 text 문제를 text-to-text 문제로 여기는 것
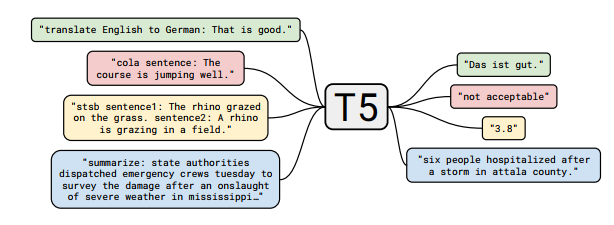
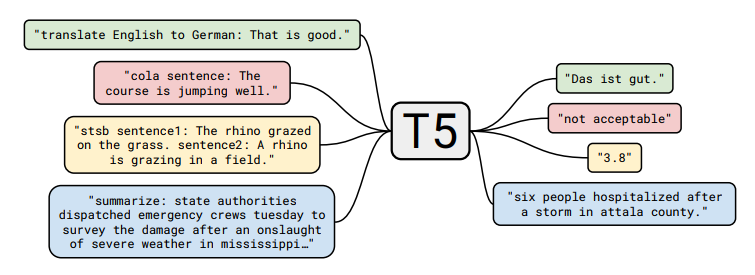
그림 1 : text-to-text 프레임워크에 대한 다이어그램입니다. 번역, 질문 답변 및 분류를 포함하여 우리가 고려하는 모든 작업은 모델 텍스트를 입력으로 제공하고 목표 텍스트를 생성하도록 훈련시키는 것으로 캐스팅됩니다. 이를 통해 다양한 작업 세트에서 동일한 모델, 손실 함수 및 하이퍼파라미터 등을 사용할 수 있습니다. 또한 경험적 조사에 포함된 방법에 대한 표준 테스트 베드를 제공합니다. "T5"는 모델을 참조하여 " Text-to-Text Transfer Transformer"라고 합니다.
• 본 논문의 목적은 새로운 method의 제시가 아닌 분야의 현주소에 대한 종합적인 관점을 제공하는 것 • 연구된 여러 method들은 scaling up에서 한계가 있다는 것을 실험을 통해 확인 • 웹에서 스크랩한 수백기가의 cleaned English text dataset인 Colossal Clean Crawled Corpus(C4)를 소개
2. Setup 2.1 Model • original Transformer와 거의 비슷한 아키텍처를 사용 1) Layer Norm bias 제거 2) layer normalization을 residual path 밖으로 옮김 3) positional embedding schema 수정 (relative position embeddings) - Input 사이에 pair-wise relationship 고려 - 각 토큰 위치 별로 고정된 encoding을 주고 attention을 계산하는 것이 아닌, self-attention 내에서 “key”와 “query”사이 relative position embedding 값을 준 것 - Self-attention score + relative position embedding 값을 최종 score로 취함
2.2 The Colossal Clean Crawled Corpus (C4)
- 기존 데이터셋은 filtering에 제한적이고 공개적으로 사용할 수 없어 새로운 데이터셋을 구축
• Pre-training dataset • Unlabeled text data • 한 달에 20TB 수집 • Common Crawl 데이터셋이 발전한 dataset • 약 750GB를 수집, TF Dataset을 통해 쉽게 접근 가능 • Heuristic clean up을 통해 텍스트 정제 진행 1) Terminal punctuation(. ! ? “”)로 끝나는 문장만 사용 2) 5문장보다 적은 페이지는 제거하고, 적어도 3단어 이상 포함된 문장만 사용 3) “List of Dirty, Naughty, Obscene or Otherwise Bad Words” 나쁜 단어 포함된 문장 제거 4) Javascript 단어 들어간 라인 제거 5) “lorem ipsum” 포함된 페이지 제거 6) 자연어가 아닌 { } 와 같은 프로그래밍 언어 포함된 것 제거 7) 대부분 downstream task가 영어로 langdetect을 사용해 영어일 확률이 0.99 이하인 것들은 제거
2.3 Downstream Tasks • GLUE, SuperGLUE text classification, CNN/Daily Mail, SQuAD, WMT 등 모델의 성능을 실험하기 위해 다양한 테스트 진행
2.4 Input and Output Format • 단일 모델로 여러 tasks를 처리하기 위해 text-to-text 형식을 취함 • MNLI, text classification에서 모델은 target label의 index가 아닌 target label의 word를 predict (label에 없는 word를 prediction하면 오답으로 간주, 하지만 학습된 모델에서 그런 경우는 발견되지 않음) • summarization task에는 document 끝에 TL;DR을 붙이는 등 prefix를 활용 • STS-B와 같은 regression task는 label이 의미있는 크고 작음을 가지기 때문에 label은 모두 소수점 아래 둘째 자리에서 반올림, prediction word는 float으로 변환하여 loss를 산출 • multi-task 학습 중 dataset 간 data leakage 위험으로 인해 WNLI는 average GLUE score에서 제외
3. Experiments 3.1 Baseline
“standard Transformer using a simple denoising objective” 사용(기본적인 Transformer 구조)하여 선학습
이후 다운스트림 Task를 통해 파인튜닝을 진행
3.1.1 Model • 실험 결과 generation, classification task에서 성능이 더 좋았던 standard encoder-decoder Transformer를 사용 • BERTBASE configuration과 동일하게 구성
• 모델 파라미터는 220M으로 BERTBASE(110M)의 2배
3.1.2 Training
• 모든 태스크는 text-to-text 형태를 따름
• Maximum likelihood와 cross-entropy loss로 학습 진행
• Optimization : AdaFactor
• Greedy decoding 사용 (매 timestep마다 가장 확률이 높은 logit 선택)
• Pre-training 하이퍼파라미터
- 2^19 = 524,288 steps
- Maximum sequence length : 512
- Batch size : 128
- 2^16 = 65,536 tokens per batch
- 사전학습시 batch size와 number of steps는 2^35 ≈ 34B tokens, BERT(137B)와 RoBERTa(2.2T)보다 훨씬 적음
- Learning rate schedule : Inverse square root 활용
lr=1/√max(n,k) (n : current training iteration, k : number of warmup steps (=10^4)
• Fine-tuning 하이퍼파라미터
- 2^18 = 262,144 steps
- Maximum sequence length : 512
- Batch size : 128
- 2^16 tokens per batch
- Constant learning rate : 0.001
3.1.3 Vocabulary • SentencePiece(라이브러리)를 사용하여 text를 WordPiece로 변환 • 영어, 독일어, 프랑스어, 루마니아어를 10:1:1:1 비율로 학습 • 약 32,000개의 wordpiece vocab
3.1.4 Unsupervised objective
그림 2
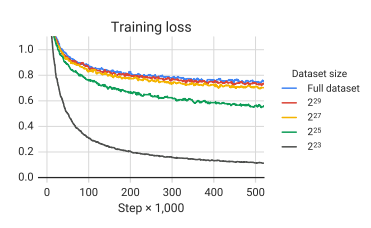
: 이전에는 선학습할 때 casual language modeling objective가 많이 사용되었으나, 최근에는 denoising objective 가 좋은 성능을 보여주고 있음
• Masked language modeling을 사용 • 15%의 token을 masking, 연속되는 masked token은 하나의 MASK token으로 변환 • mask token의 경우 unique한 id를 부여 (모두 다르게 취급)
• Target은 Input에서 마스킹되지 않은 부분을 맞춰야 함
표 1
•10개 baseline을 학습시켜 평균과 표준편차 확인
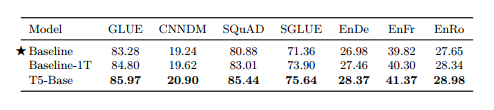
• BERTBASE보다 성능이 올랐으나 T5는 encoder-decoder 모델이고, 1/4 steps만 선학습 진행했기 때문에 직접적으로 비교하긴 어려움
• Pre-training 하는것이 성능향상에 도움이 된다.
3.2 Archietectures
3.2.1 Model structures
그림 3
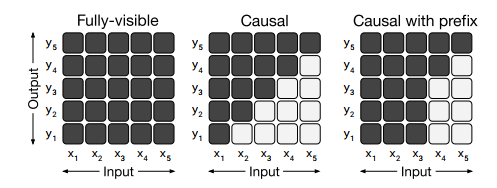
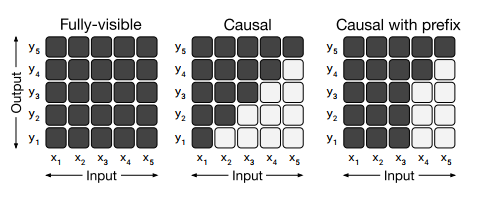
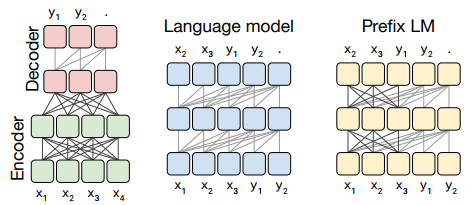
• Fully-visible : encoder에서 사용, Query가 모든 key에 attention 가능 • Causal : decoder 에서 사용, Query가 현재 시점 포함 이전 timestep의 Key에 attention 가능 • Causal with prefix :입력 텍스트인 prefix로 주어진 부분은 fully-visible, 출력 텍스트는 casual 사용
그림 4
• Standard Encoder-Decoder : encoder는 Full-visible attention, decoder는 causal attention 사용 • Language model : Transformer의 decoder에서 causal attention 사용 • Prefix LM - Transformer의 decoder에서 causal with prefix attention 사용 - input text(x) full-visible attention을 수행하는 prefix가 되는 구조
: 위 3가지 아키텍처 디자인을 비교
3.2.4 Result
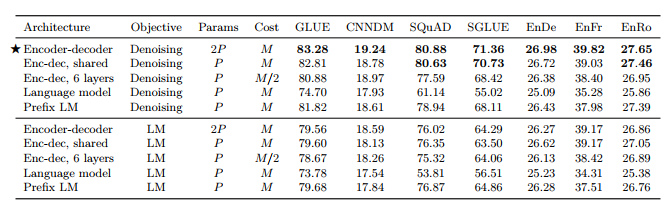
표 2
• Encoder-decoder 구조 / Denoising objective가 가장 좋은 결과를 기록
• 인코더와 디코더 파라미터 공유하는 것은 성능 차이 크게 나지 않음
• Layer를 줄이는 것은 성능에 악영향
• Denoising objective를 사용하는 것이 language modeling objective보다 높은 성능
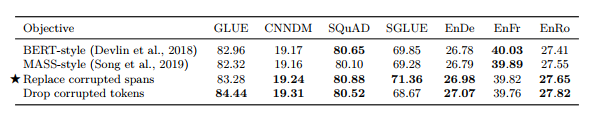
3.3 Unsupervised Objectives
표 3
Objective는 text-to-text encoder-decoder에 맞게 변환 • Prefix language modeling : input으로 문장 앞부분 넣으면 target에서 문장의 뒷부분 예측
• BERT-style : 토큰의 15%를 마스킹, 90%를 랜덤 토큰으로 교체
• Deshuffling : 문장을 섞은 다음 원래 문장을 예측
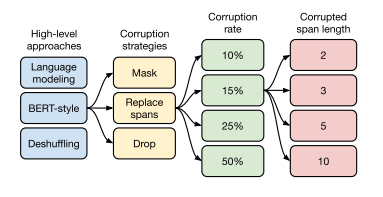
• MASS-style : BERT-style에서 90% 랜덤 토큰으로 교체하는 방법만 제외 • I.i.d. noise, replace spans : masking되지 않은 부분 예측 • I.i.d. noise, drop tokens : masking을 알려주지 않아도 빠진 문장 예측 • Random spans : span이 1개가 아니라 더 긴 span 예측
[High-level Approaches]
표 4
• Greedy하게 Coarse to fine으로 여러 objective와 하위 설정에 대한 실험
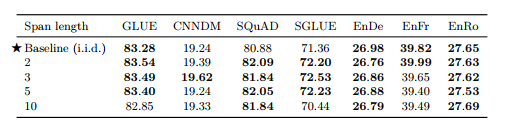
- Prefix language modeling / BERT-style / Deshuffling 중 BERT-style의 성능이 가장 뛰어났음
long sequence에서 attention을 피하기 위한 Drop corrupted tokens으로 BERT-style의 masking 설정에 대한 실험 - Replace corrupted spans의 성능이 가장 좋았음
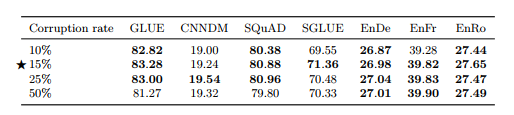
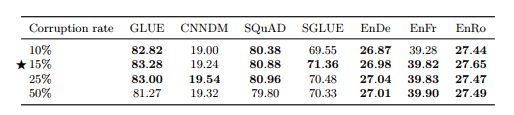
[Corruption rate]
표 6
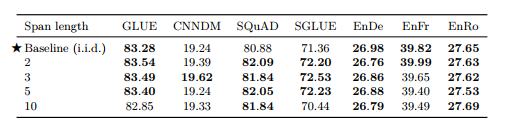
[Corrupted span length]
표 7
• Corruption rate, Span length에 대한 실험 (표 6,7) • 15%, Baseline(span length 제약 없이 i.i.d corruption)의 성능이 최고
3.4 Pre-training Data set
: Pre-training시 사용한 데이터셋에 대해 실험 진행
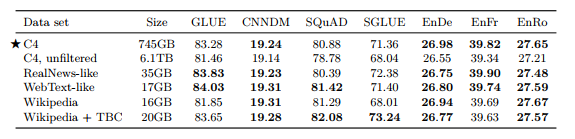
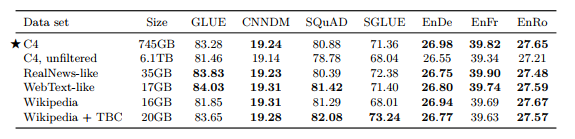
1) Unlabeled Data sets • C4 : Pre-training에 사용한 데이터셋 • Unfiltered C4 : langdetect을 통해 영어만 추출, Heuristic filtering 적용 안함 • RealNews-like : “RealNews” 데이터셋에 대해 C4와 같이 heuristic filtering 적용 • WebText-like - WebText 데이터셋은 사용자들이 웹페이지의 컨텐츠에 따라 1~3점 스코어 부여 - 높은 스코어의 URL과 겹치는 페이지만 남김 - C4는 한달치 Common Crawl 데이터라 남은 데이터가 2GB밖에 안됨 - 2018.08 ~ 2019.07(12개월) Common Crawl 데이터에서 heuristic filtering 적용하여 17GB 데이터 구축 • Wikipedia : English Wikipedia 사용 • Wikipedia + Toronto Books Corpus : Wikipedia는 백과사전 도메인만 있기 때문에, Toronto Book Corpus(TBC)를 추가하여 다양한 도메인 정보 포함
표 8
•C4가 전체적으로 성능 좋음 • Heuristic filtering을 적용하지 않은 C4는 성능이 떨어짐 • In-domain 데이터로 학습하면 downstream task에서 성능이 향상 • WebText-like 데이터셋이 C4보다 40배 가까이 데이터가 적음에도 좋은 성능을 보임
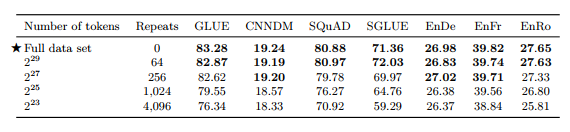
2) Pre-training Data Set Size
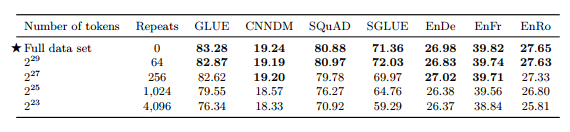
Full data set = 2^35 ≈ 34B tokens
표 9
• 적은 데이터셋으로 여러 번 학습하는 것 보다 하나의 큰 데이터셋으로 학습하는 것이 성능 좋음 • 64번 반복까지만 효과 있음
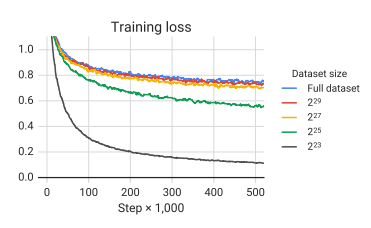
그림 6
• 데이터셋 크기가 감소하면 모델의 loss는 훨씬 작아지지만, 암기하는 효과 나타남(overfitting)
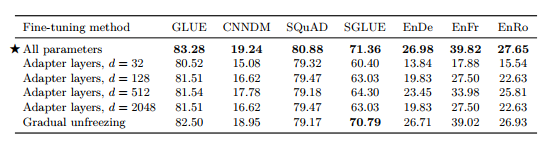
3.5 Training Strategy 3.5.1 Fine-tuning method 모델의 모든 parameter를 다 fine-tuning하는 것은 좋지 않음 (특히 파인튜닝 데이터가 적을 때) Text classification 태스크의 경우 pre-trained 모델은 고정하고, 뒷단의 classifier layer만 새로 학습하는 형태 선호 그러나, Encoder-Decoder 모델에 적용하기 어려워 다른 대안으로 두가지 방법 제시
1) Adapter layers
• Pre-training된 부분은 그대로 두고 그 위에 별도의 학습 가능한 layer를 두어 그 부분만 학습시킴 • Transformer 블록 내 feed-forward networks 위에 adapter Layer를 추가해서 학습하는 방식 • Fine-tuning 할 때 adapter layer와 layer normalization 파라미터만 업데이트
2) Gradual Unfreezing • 모든 layer를 fine-tuning 하는 것이 아닌 마지막 레이어부터 fine-tuning 하는 방식 • Top layer부터 bottom까지 천천히 학습되는 방식 • 가장 아래 layer가 가장 늦게 unfreezing 됨
: 두 방식에 대한 실험을 진행함
표 10
𝑑 : feed-forward network 내부 차원
• 모든 파라미터를 freezing 하지 않고 학습시켰을 때 가장 성능 좋음 • 적은 리소스를 요구하는 태스크의 경우 𝑑 값이 클 필요 없음 • GLUE와 SuperGLUE의 경우 하나의 태스크로 간주하고 학습 진행하였기 때문에 큰 𝑑 필요했음 • Gradual unfreezing은 모든 태스크에서 약간의 성능 저하 보이지만, fine-tuning시 속도 향상됨
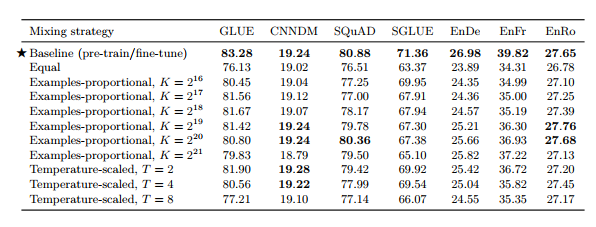
3.5.2 multi-task learning
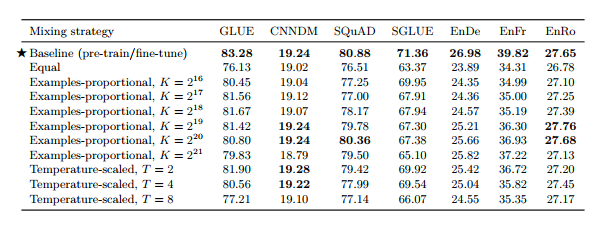
• T5의 unified text-to-text framework는 모든 tasks가 test-to-text 형식으로 구성되어 있어 데이터셋을 섞는 것이 곧 multi-task와 같다 • Examples-proportional mixing - 각 dataset의 크기에 비례하여 샘플링 - 너무 큰 dataset의 크기는 가상의 datasize limit K로 제한 • Equal mixing : 모든 task에서 동일한 수의 데이터를 샘플링 • Temperature-scaled mixing - multilingual BERT에서 사용한 방식으로 mixing rate rm을 (1/T)^2로 설정하고 renormalize하여 합이 1이되도록 함 - T=1이면 Examples-proprotional mixing과 동일, T가 증가하면 equal mixing과 비슷한 형태(모두 같은 비율)
표 11
• 새로 설계한 method 대부분 성능 저하 결과
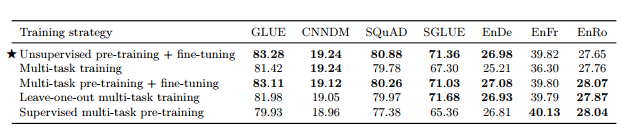
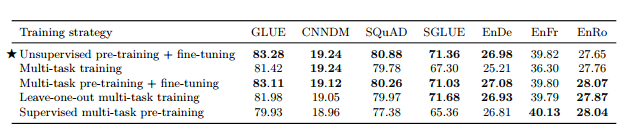
3.5.3 Combining multi-task learning with fine-tuning - 위 실험의 결과로 자연스럽게 fine-tuning에서의 multi-task learning으로 이동
• leave-one-out : 하나의 task를 빼고 pre-training 한 후, 해당 task를 fine-tune • supervised multi-task pre-training : K=2^19, examples-proportional mixture를 사용하여 supervised training • Multi-task training, Multi-task pre-training + fine-tuning - MT-DNN에서 제시한 방식 - unsupervised objective와 supervise task의 결합
표 12
• Unsupervised pre-training + fine-tuning이 가장 좋은 성능을 보임
3.6 Scaling
• 4배 큰 computing power가 생겼을 때 모델의 크기를 어떻게 늘리는 것이 효율적일지에 대해 실험 진행
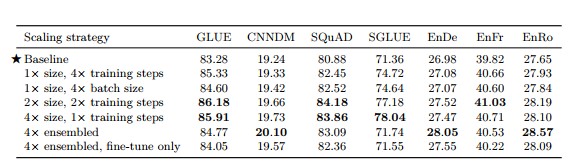
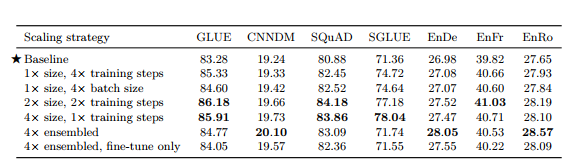
- 고려대상 : 파라미터 수, 트레이닝 steps, batch size, ensemble • baseline보단 성능 향상 • 무조건 4 x training steps나 4 x batch size가 제일 좋은 성능은 아님
표 13
3.7 Putting It All Together - 지금까지 수행한 체계적인 실험 결과를 모아 NLP benchmark를 얼마나 끌어올릴 수 있는지 테스트
• Objective : i.i.d denoising objective (span length 3, 15% corruption) • Longer training • Model size
- Base(220M parameters), Small(60M parameters), large(770M parameters), 3B(3B parameters), 11B(11B parameters) • Multi-task pre-training - MT-DNN에서 제시한 방식 사용 - training 도중에도 multi-task에서 성능을 관찰할 수 있는 장점 존재 • Fine-tuning on individual GLUE and SuperGLUE tasks • Beam Search(beam width=4, length penalty alpha=0.6) for WMT, CNN/DM • Test set - 각 데이터셋의 validation set이 아닌 test set의 결과 report - SQuAD는 test set benchmark server 문제로 valid set 사용
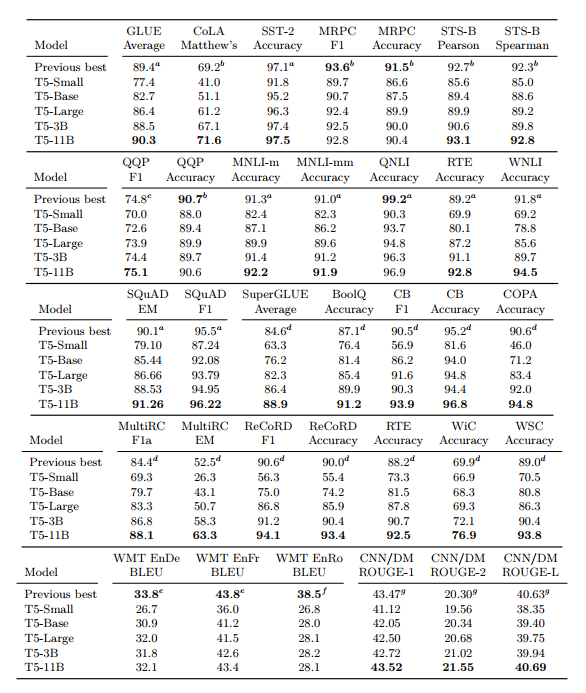
표 14
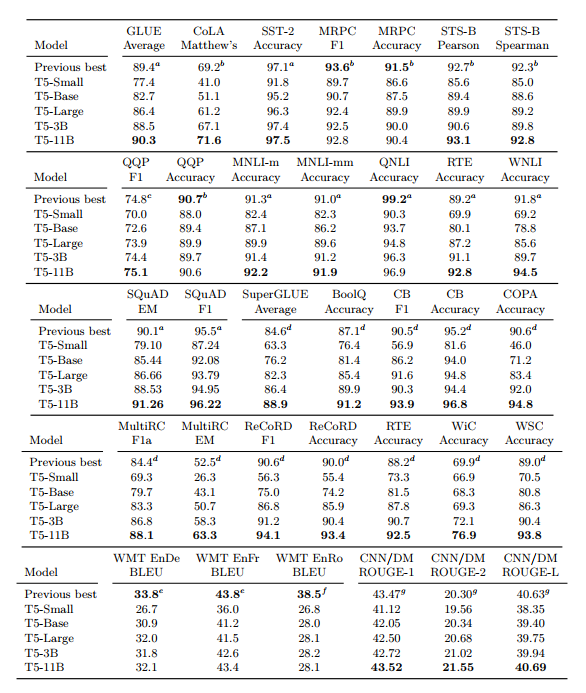
• 24개 task 중 18개 task에서 SOTA를 달성 • 예상과 같이 11B 모델이 가장 좋은 성능을 보임
4. Reflection
4.1 Takeaways
• Text-to-Text - 간단한 encoder-decoder 구조로 text-specific한 아키텍처와 비슷한 성능을 보여줌, scale up을 통해 SOTA까지 달성한 디자인
• Architectures - encoder-decoder 아키텍처는 text-to-text framework에서 encoder-only, language model 아키텍처보다 좋은 성능을 보여줌
• Unsupervised learning - short target sequence를 사용하는 denoising objective를 선정하여 computational cost를 줄이는 것이 좋음
• Data sets - C4를 제시
• Training strategies - 여러 tasks로 pre-training 하고 fine-tuning 하는 것은 unsupervised pre-training에 견줄만한 성능을 보임 - 하지만 task mixing 비율에 대해서는 연구가 더 필요
• Scaling - scale up, ensemble 모두 효과적
• Pushing the limits - 얻은 인사이트를 결합하고 충분히 큰 모델(11B)에서 학습한 결과, 많은 benchmark에서 SOTA를 달성
4.2 Outlook
• The inconvenience of large models - 모델 크기가 클수록 좋은 성능이 나오지만 모든 상황에서 큰 모델을 사용할 수 없기 때문에 가볍고 성능 좋은 모델을 만들어야 한다.
• More efficient knowledge extraction - corruped span을 denoise하는 task(손상된 텍스트 span을 맞추는 학습 방법)가 general-purpose knowledge를 가르치는데 효과적인 방법이 아닐 수 있음 - real & machine generation text를 구분하는 이전 연구와 같은 새로운 접근이 필요
• Formalizing the similarity between tasks - SQuAD의 경우 Wikipedia로 부터 만들어졌기 때문에 중복이 많아 성능이 높을 수 밖에 없음
• Language-agnostic models - 언어에 상관없이 모든 NLP 태스크에서 좋은 성능을 내는 모델을 개발하고자 함
모델이 다운스트림 작업에서 미세 조정되기 전에 데이터가 풍부한 작업에 대해 먼저 사전 훈련되는 전이 학습은 자연어 처리(NLP)에서 강력한 기술로 부상했습니다. 전이 학습의 효율성으로 인해 접근 방식, 방법론 및 실습이 다양해졌습니다. 본 논문에서는 모든 텍스트 기반 언어 문제를 텍스트 대 텍스트 형식으로 변환하는 통합 프레임워크를 도입하여 NLP를 위한 전이 학습 기술의 환경을 탐구합니다. 우리의 체계적인 연구는 수십 가지 언어 이해 작업에 대한 사전 훈련 목표, 아키텍처, 레이블이 없는 데이터 세트, 전송 접근 방식 및 기타 요소를 비교합니다. 탐색에서 얻은 통찰력과 규모 및 새로운 "Colossal Clean Crawled Corpus"를 결합하여 요약, 질문 답변, 텍스트 분류 등을 다루는 많은 벤치마크에서 최첨단 결과를 달성합니다. NLP를 위한 전이 학습에 대한 향후 작업을 촉진하기 위해 데이터 세트, 사전 훈련된 모델 및 코드를 출시합니다. 키워드: 전이 학습, 자연어 처리, 다중 작업 학습, 주의 기반 모델, 심층 학습
1. 서론
자연어 처리(NLP) 작업을 수행하기 위해 기계 학습 모델을 훈련하려면 모델이 다운스트림 학습에 적합한 방식으로 텍스트를 처리할 수 있어야 하는 경우가 많습니다. 이는 모델이 텍스트를 "이해"할 수 있도록 하는 범용 지식을 개발하는 것으로 느슨하게 볼 수 있습니다. 이러한 지식은 낮은 수준(예: 단어의 철자 또는 의미)부터 높은 수준(예: 튜바가 너무 커서 대부분의 배낭에 들어갈 수 없음)까지 다양합니다. 현대 기계 학습 실무에서 이러한 지식을 명시적으로 제공하는 경우는 거의 없습니다. 대신 보조 작업의 일부로 학습되는 경우가 많습니다. 예를 들어, 역사적으로 일반적인 접근 방식은 단어 벡터(Mikolov et al., 2013b,a; Pennington et al., 2014)를 사용하여 단어 정체성을 연속 표현으로 매핑하는 것입니다. 여기서 이상적으로는 유사한 단어가 유사한 벡터에 매핑됩니다. 이러한 벡터는 종종 연속 공간에서 동시 발생하는 단어가 근처에 위치하도록 장려하는 목표를 통해 학습됩니다(Mikolov et al., 2013b).
최근에는 데이터가 풍부한 작업에 대해 전체 모델을 사전 학습하는 것이 점점 일반화되었습니다. 이상적으로는 이러한 사전 훈련을 통해 모델이 범용 능력과 지식을 개발하고 이를 다운스트림 작업으로 전송할 수 있습니다. 컴퓨터 비전에 대한 전이 학습의 적용(Oquab et al., 2014; Jia et al., 2014; Huh et al., 2016; Yosinski et al., 2014)에서 사전 훈련은 일반적으로 대규모 환경에서 지도 학습을 통해 수행됩니다. ImageNet과 같은 레이블이 지정된 데이터 세트(Russakovsky et al., 2015; Deng et al., 2009) 이와 대조적으로 NLP의 전이 학습을 위한 현대 기술은 레이블이 지정되지 않은 데이터에 대한 비지도 학습을 사용하여 사전 훈련하는 경우가 많습니다. 이 접근 방식은 최근 가장 일반적인 NLP 벤치마크에서 최첨단 결과를 얻는 데 사용되었습니다(Devlin et al., 2018; Yang et al., 2019; Dong et al., 2019; Liu et al. , 2019c; Lan et al., 2019). 경험적 강점 외에도 NLP에 대한 감독되지 않은 사전 훈련은 인터넷 덕분에 레이블이 지정되지 않은 텍스트 데이터를 대량으로 사용할 수 있기 때문에 특히 매력적입니다. 예를 들어 Common Crawl 프로젝트2는 매달 웹 페이지에서 추출된 약 20TB의 텍스트 데이터를 생성합니다. 이는 놀라운 확장성을 나타내는 것으로 알려진 신경망에 자연스러운 적합성입니다. 즉, 더 큰 데이터 세트에서 더 큰 모델을 훈련함으로써 더 나은 성능을 달성하는 것이 종종 가능합니다(Hestness et al., 2017; Shazeer et al. , 2017; Jozefowicz 등, 2016; Mahajan 등, 2018; Radford 등, 2019; Shazeer 등, 2018; Huang 등, 2018b; Keskar 등, 2019a).
이러한 시너지 효과로 인해 NLP에 대한 전이 학습 방법론을 개발하는 최근의 많은 작업이 이루어졌으며, 이는 사전 훈련 목표의 광범위한 환경을 생성했습니다(Howard and Ruder, 2018; Devlin et al., 2018; Yang et al., 2019; Dong 등, 2019), 레이블이 지정되지 않은 데이터 세트(Yang 등, 2019; Liu 등, 2019c; Zellers 등, 2019), 벤치마크(Wang 등, 2019b, 2018; Conneau 및 Kiela, 2018 ), 미세 조정 방법(Howard and Ruder, 2018; Houlsby et al., 2019; Peters et al., 2019) 등이 있습니다. 이 급성장하는 분야의 빠른 발전 속도와 기술의 다양성으로 인해 다양한 알고리즘을 비교하고, 새로운 기여의 효과를 분석하고, 전이 학습을 위한 기존 방법의 공간을 이해하는 것이 어려울 수 있습니다. 보다 엄격한 이해에 대한 필요성에 동기를 부여받아, 우리는 다양한 접근 방식을 체계적으로 연구하고 해당 분야의 현재 한계를 뛰어넘을 수 있는 전이 학습에 대한 통합 접근 방식을 활용합니다.
우리 작업의 기본 아이디어는 모든 텍스트 처리 문제를 "텍스트 대 텍스트" 문제로 처리하는 것입니다. 즉, 텍스트를 입력으로 사용하고 새 텍스트를 출력으로 생성하는 것입니다. 이 접근 방식은 모든 텍스트 문제를 질문 답변으로 캐스팅(McCann et al., 2018), 언어 모델링(Radford et al., 2019) 또는 범위 추출 Keskar et al. (2019b) 작업을 포함하여 NLP 작업을 위한 이전 통합 프레임워크에서 영감을 받았습니다. 결정적으로, 텍스트-텍스트 프레임워크를 통해 우리가 고려하는 모든 작업에 동일한 모델, 목표, 훈련 절차 및 디코딩 프로세스를 직접 적용할 수 있습니다. 우리는 질문 답변, 문서 요약, 감정 분류 등 다양한 영어 기반 NLP 문제에 대한 성과를 평가함으로써 이러한 유연성을 활용합니다. 이러한 통합 접근 방식을 사용하면 이전에 고려했던 것 이상으로 모델과 데이터 세트를 확장하여 NLP에 대한 전이 학습의 한계를 탐색하는 동시에 다양한 전이 학습 목표, 레이블이 지정되지 않은 데이터 세트 및 기타 요인의 효율성을 비교할 수 있습니다.
그림 1 : 텍스트-텍스트 프레임워크의 다이어그램. 번역, 질문 답변 및 분류를 포함하여 우리가 고려하는 모든 작업은 모델 텍스트를 입력으로 제공하고 일부 대상 텍스트를 생성하도록 훈련시키는 것으로 캐스팅됩니다. 이를 통해 다양한 작업 세트에서 동일한 모델, 손실 함수, 하이퍼파라미터 등을 사용할 수 있습니다. 또한 실증적 조사에 포함된 방법에 대한 표준 테스트베드를 제공합니다. "T5"는 "텍스트-텍스트 전송 변환기"라고 불리는 우리 모델을 나타냅니다.
우리는 우리의 목표가 새로운 방법을 제안하는 것이 아니라 해당 분야가 어디에 있는지에 대한 포괄적인 관점을 제공하는 것임을 강조합니다. 따라서 우리의 작업은 주로 기존 기술에 대한 조사, 탐색 및 실증적 비교로 구성됩니다. 또한 체계적인 연구(교육)에서 얻은 통찰력을 확장하여 현재 접근 방식의 한계를 탐구합니다. 우리가 고려하는 많은 작업에서 최첨단 결과를 얻기 위해 최대 110억 개의 매개변수를 모델링합니다. 이 규모의 실험을 수행하기 위해 웹에서 스크랩한 수백 기가바이트의 깨끗한 영어 텍스트로 구성된 데이터 세트 "Colossal Clean Crawled Corpus"(C4)를 소개합니다. 전이 학습의 주요 유틸리티는 데이터가 부족한 환경에서 사전 훈련된 모델을 활용할 수 있다는 점을 인식하여 코드, 데이터 세트 및 사전 훈련된 모델을 출시합니다.
논문의 나머지 부분은 다음과 같이 구성됩니다. 다음 섹션에서는 기본 모델과 그 구현, 모든 텍스트 처리 문제를 텍스트 대 텍스트 작업으로 공식화하는 절차, 그리고 우리가 고려하는 작업 세트에 대해 논의합니다. 섹션 3에서는 NLP의 전이 학습 분야를 탐구하는 대규모 실험 세트를 제시합니다. 섹션 끝(섹션 3.7)에서는 체계적인 연구에서 얻은 통찰력을 결합하여 다양한 벤치마크에서 최첨단 결과를 얻습니다. 마지막으로 4장에서 결과를 요약하고 미래에 대한 전망으로 마무리합니다.
2. 설정
대규모 실증적 연구 결과를 제시하기 전에 Transformer 모델 아키텍처 및 평가 대상인 다운스트림 작업을 포함하여 결과를 이해하는 데 필요한 배경 주제를 검토합니다. 또한 모든 문제를 텍스트 대 텍스트 작업으로 처리하는 접근 방식을 소개하고 레이블이 지정되지 않은 텍스트 데이터의 소스로 만든 Common Crawl 기반 데이터 세트 "Colossal Clean Crawled Corpus"(C4)에 대해 설명합니다. 우리는 모델과 프레임워크를 "텍스트-텍스트 전송 변환기"(T5)라고 부릅니다.
2.1. 모델
NLP에 대한 전이 학습의 초기 결과는 순환 신경망을 활용했지만(Peters et al., 2018; Howard and Ruder, 2018), 최근에는 "Transformer" 아키텍처(Vaswani et al., 2017) 기반 모델을 사용하는 것이 더 일반화되었습니다. Transformer는 처음에는 기계 번역에 효과적인 것으로 나타났지만 이후 다양한 NLP 설정에서 사용되었습니다(Radford et al., 2018; Devlin et al., 2018; McCann et al., 2018; Yu et al. ., 2018). 보편성이 증가함에 따라 우리가 연구하는 모든 모델은 Transformer 아키텍처를 기반으로 합니다. 아래에 언급된 세부 사항과 섹션 3.2에서 살펴보는 변형을 제외하고는 원래 제안된 대로 이 아키텍처에서 크게 벗어나지 않습니다. 이 모델에 대한 포괄적인 정의를 제공하는 대신 관심 있는 독자에게 원본 논문(Vaswani et al., 2017) 또는 후속 튜토리얼 3, 4를 참조하여 더 자세한 소개를 제공합니다.
Transformer의 주요 구성 요소는 self-attention입니다(Cheng et al., 2016). Self-attention은 각 요소를 나머지 시퀀스의 가중 평균으로 대체하여 시퀀스를 처리하는 Attention의 변형입니다(Graves, 2013; Bahdanau et al., 2015). 원래 Transformer는 인코더-디코더 아키텍처로 구성되었으며 시퀀스 간(Sutskever et al., 2014; Kalchbrenner et al., 2014) 작업을 위해 고안되었습니다. 최근에는 언어 모델링에 적합한 아키텍처를 생성하는 데 사용되는 다양한 형태의 self-attention과 함께 단일 Transformer 레이어 스택으로 구성된 모델을 사용하는 것이 일반화되었습니다(Radford et al., 2018; Al-Rfou et al., 2019). 분류 및 범위 예측 작업(Devlin et al., 2018; Yang et al., 2019). 우리는 섹션 3.2에서 이러한 아키텍처 변형을 경험적으로 탐색합니다.
전반적으로 우리의 인코더-디코더 Transformer 구현은 원래 제안된 형식(Vaswani et al., 2017)을 밀접하게 따릅니다. 먼저, 토큰의 입력 시퀀스가 임베딩 시퀀스에 매핑된 다음 인코더로 전달됩니다. 인코더는 "블록"의 스택으로 구성되며, 각 블록은 두 개의 하위 구성 요소, 즉 self-attention 레이어와 작은 피드포워드 네트워크로 구성됩니다. 레이어 정규화(Ba et al., 2016)는 각 하위 구성요소의 입력에 적용됩니다. 우리는 활성화의 크기만 조정하고 추가 바이어스는 적용하지 않는 단순화된 버전의 레이어 정규화를 사용합니다. 레이어 정규화 후 잔여 건너뛰기 연결(He et al., 2016)은 각 하위 구성 요소의 입력을 출력에 추가합니다. 드롭아웃(Srivastava et al., 2014)은 피드포워드 네트워크 내, 스킵 연결, 주의 가중치, 전체 스택의 입력 및 출력에 적용됩니다. 디코더는 인코더의 출력에 참여하는 각 self-attention 계층 뒤에 표준 주의 메커니즘을 포함한다는 점을 제외하면 구조가 인코더와 유사합니다. 디코더의 self-attention 메커니즘은 모델이 과거 출력에만 주의를 기울이는 것을 허용하는 autoregressive 또는 causal self-attention의 형태도 사용합니다. 최종 디코더 블록의 출력은 소프트맥스 출력이 있는 밀집 레이어로 공급되며, 해당 가중치는 입력 임베딩 행렬과 공유됩니다. Transformer의 모든 주의 메커니즘은 추가 처리 전에 출력이 연결되는 독립적인 "헤드"로 분할됩니다.
self-attention은 순서에 독립적이므로(즉, 세트에 대한 작업이므로) Transformer에 명시적인 위치 신호를 제공하는 것이 일반적입니다. 원래 Transformer는 정현파 위치 신호 또는 학습된 위치 임베딩을 사용했지만 최근에는 상대 위치 임베딩을 사용하는 것이 더 일반적이 되었습니다(Shaw et al., 2018; Huang et al., 2018a). 각 위치에 고정 임베딩을 사용하는 대신 상대 위치 임베딩은 self-attention 메커니즘에서 비교되는 "키"와 "쿼리" 사이의 오프셋에 따라 다른 학습 임베딩을 생성합니다. 우리는 각 "임베딩"이 단순히 주의 가중치를 계산하는 데 사용되는 해당 로짓에 추가되는 스칼라인 단순화된 형태의 위치 임베딩을 사용합니다. 효율성을 위해 모델의 모든 레이어에서 위치 임베딩 매개변수를 공유하지만, 주어진 레이어 내에서 각 어텐션 헤드는 서로 다른 학습된 위치 임베딩을 사용합니다. 일반적으로 고정된 수의 임베딩이 학습되며, 각각은 가능한 키 쿼리 오프셋 범위에 해당합니다. 이 작업에서는 모든 상대 위치를 동일한 임베딩에 할당하는 오프셋 128까지 대수적으로 크기가 증가하는 범위의 모든 모델에 대해 32개의 임베딩을 사용합니다. 주어진 레이어는 128개 토큰을 초과하는 상대 위치에 민감하지 않지만 후속 레이어는 이전 레이어의 로컬 정보를 결합하여 더 큰 오프셋에 대한 민감도를 구축할 수 있습니다. 요약하자면, 우리 모델은 Vaswani 등이 제안한 원래 Transformer와 거의 동일합니다. (2017), Layer Norm 바이어스를 제거하고, 레이어 정규화를 잔여 경로 외부에 배치하고, 다른 위치 임베딩 방식을 사용하는 것을 제외하고 이러한 아키텍처 변경은 전이 학습에 대한 실증적 조사에서 고려한 실험적 요소와 직교하므로 향후 작업에 대한 영향을 제거합니다.
연구의 일환으로 우리는 이러한 모델의 확장성, 즉 더 많은 매개변수나 레이어를 갖게 되면서 성능이 어떻게 변하는지 실험합니다. 대규모 모델을 훈련하는 것은 단일 시스템에 적합하지 않고 많은 양의 계산이 필요할 수 있으므로 쉽지 않을 수 있습니다. 결과적으로 우리는 모델과 데이터 병렬 처리의 조합을 사용하고 Cloud TPU Pod의 '슬라이스'에서 모델을 교육합니다. TPU Pod는 고속 2D 메시 상호 연결을 통해 연결된 1,024개의 TPU v3 칩을 포함하는 다중 랙 ML 슈퍼컴퓨터입니다. CPU 호스트 시스템을 지원합니다. 우리는 모델 병렬성과 데이터 병렬성(Krizhevsky, 2014)을 쉽게 구현하기 위해 Mesh TensorFlow 라이브러리(Shazeer et al., 2018)를 활용합니다.
2.2. 거대하고 깨끗하게 크롤링된 코퍼스
NLP를 위한 전이 학습에 대한 이전 연구의 대부분은 비지도 학습을 위해 레이블이 지정되지 않은 대규모 데이터 세트를 사용했습니다. 본 논문에서는 레이블이 지정되지 않은 데이터의 품질, 특성 및 크기의 효과를 측정하는 데 관심이 있습니다. 우리의 요구 사항을 충족하는 데이터 세트를 생성하기 위해 Common Crawl을 웹에서 스크랩한 텍스트 소스로 활용합니다. Common Crawl은 이전에 NLP용 텍스트 데이터 소스로 사용되었습니다(예: n-gram 언어 모델 훈련(Buck et al., 2014)), 상식 추론을 위한 훈련 데이터(Trinh and Le, 2018), 마이닝 기계 번역을 위한 병렬 텍스트(Smith et al., 2013), 사전 훈련 데이터 세트(Grave et al., 2018; Zellers et al., 2019; Liu et al., 2019c), 심지어는 단순히 거인으로서 최적화 도구 테스트를 위한 텍스트 코퍼스(Anil et al., 2019). Common Crawl은 스크랩된 HTML 파일에서 마크업 및 기타 텍스트가 아닌 콘텐츠를 제거하여 "웹에서 추출된 텍스트"를 제공하는 공개적으로 사용 가능한 웹 아카이브입니다. 이 프로세스를 통해 매월 약 20TB의 스크랩된 텍스트 데이터가 생성됩니다. 불행하게도 결과 텍스트의 대부분은 자연어가 아닙니다. 대신 메뉴, 오류 메시지 또는 중복 텍스트와 같은 횡설수설 또는 상용구 텍스트로 주로 구성됩니다. 게다가 스크랩된 텍스트의 상당 부분에는 우리가 고려하는 작업(공격적인 언어, 자리 표시자 텍스트, 소스 코드 등)에 도움이 되지 않을 것 같은 콘텐츠가 포함되어 있습니다. 이러한 문제를 해결하기 위해 우리는 Common Crawl의 웹 추출 텍스트를 정리하기 위해 다음 경험적 방법을 사용했습니다.
• 끝 구두점(예: 마침표, 느낌표, 물음표 또는 끝 따옴표)으로 끝나는 줄만 유지했습니다. • 문장이 5개 미만인 페이지는 모두 삭제하고 단어가 3개 이상 포함된 줄만 유지했습니다. • "더러운, 버릇없는, 음란한 또는 기타 나쁜 단어 목록"에 있는 단어가 포함된 모든 페이지를 제거했습니다. • 스크랩된 페이지 중 상당수에는 Javascript를 활성화해야 한다는 경고가 포함되어 있으므로 Javascript라는 단어가 포함된 줄을 모두 제거했습니다. • 일부 페이지에는 자리 표시자 "lorem ipsum" 텍스트가 있습니다. 우리는 "lorem ipsum"이라는 문구가 표시된 모든 페이지를 제거했습니다. • 일부 페이지에 실수로 코드가 포함되어 있습니다. 중괄호 "{"는 많은 프로그래밍 언어(예: 웹에서 널리 사용되는 Javascript)에 표시되지만 자연 텍스트에는 표시되지 않으므로 중괄호가 포함된 모든 페이지를 제거했습니다. • 데이터 세트의 중복을 제거하기 위해 데이터 세트에서 두 번 이상 발생하는 세 문장 범위 중 하나만 제외하고 모두 삭제했습니다.
또한 대부분의 다운스트림 작업은 영어 텍스트에 중점을 두기 때문에 langDetect7을 사용하여 영어로 분류되지 않은 페이지를 최소 0.99의 확률로 필터링했습니다. 우리의 휴리스틱은 Common Crawl을 NLP의 데이터 소스로 사용하는 과거 작업에서 영감을 얻었습니다. 예를 들어 Grave et al. (2018)은 또한 자동 언어 탐지기를 사용하여 텍스트를 필터링하고 짧은 줄을 삭제하며 Smith et al. (2013); Graveet al. (2018) 둘 다 라인 수준 중복 제거를 수행합니다. 그러나 이전 데이터 세트는 보다 제한된 필터링 휴리스틱 세트를 사용하고, 공개적으로 사용할 수 없거나 범위가 다르기 때문에(예: 뉴스 데이터로 제한됨(Zellers et al., 2019; Liu et al., 2019c)는 Creative Commons 콘텐츠로만 구성되거나(Habernal et al., 2016) 기계 번역을 위한 병렬 교육 데이터에 중점을 둡니다(Smith et al., 2013).
기본 데이터 세트를 구성하기 위해 2019년 4월의 웹 추출 텍스트를 다운로드하고 앞서 언급한 필터링을 적용했습니다. 이는 사전 훈련에 사용되는 대부분의 데이터 세트(약 750GB)보다 훨씬 클 뿐만 아니라 합리적으로 깨끗하고 자연스러운 영어 텍스트로 구성된 텍스트 모음을 생성합니다. 우리는 이 데이터 세트를 "Colossal Clean Crawled Corpus"(또는 줄여서 C4)라고 명명하고 TensorFlow 데이터 세트의 일부로 출시합니다. 우리는 섹션 3.4에서 이 데이터 세트의 다양한 대체 버전을 사용할 때의 영향을 고려합니다.
2.3. 다운스트림 작업
본 논문의 목표는 일반적인 언어 학습 능력을 측정하는 것입니다. 따라서 우리는 기계 번역, 질문 답변, 추상 요약 및 텍스트 분류를 포함한 다양한 벤치마크 세트에 대한 다운스트림 성능을 연구합니다. 특히 GLUE 및 SuperGLUE 텍스트 분류 메타 벤치마크에 대한 성능을 측정합니다. CNN/Daily Mail 추상 요약; SQuAD 질문 답변; WMT 영어를 독일어, 프랑스어, 루마니아어로 번역합니다. 모든 데이터는 TensorFlow 데이터세트에서 가져왔습니다.
GLUE(Wang et al., 2018) 및 SuperGLUE(Wang et al., 2019b)는 각각 일반적인 언어 이해 능력을 테스트하기 위한 텍스트 분류 작업 모음으로 구성됩니다.
• 문장 수용성 판단(CoLA(Warstadt et al., 2018)) • 감성 분석(SST-2(Socher et al., 2013)) • 의역/문장 유사성(MRPC(Dolan and Brockett, 2005), STS-B(Cer et al., 2017), QQP(Iyer et al., 2017)) • 자연어 추론 (MNLI(Williams et al., 2017), QNLI(Rajpurkar et al., 2016), RTE(Dagan et al., 2005), CB(De Marneff et al., 2019)) • 상호참조 해결(WNLI 및 WSC(Levesque et al., 2012)) • 문장 완성(COPA(Roemmele et al., 2011)) • 단어 의미 명확성(WIC(Pilehvar and Camacho-Collados, 2018)) • 질의응답(MultiRC(Khashabi et al., 2018), ReCoRD(Zhang et al., 2018), BoolQ(Clark et al., 2019))
우리는 GLUE 및 SuperGLUE 벤치마크에 의해 배포된 데이터 세트를 사용합니다. 단순화를 위해 미세 조정 시 모든 구성 데이터 세트를 연결하여 GLUE 벤치마크(SuperGLUE의 경우와 유사)의 모든 작업을 단일 작업으로 처리합니다. Kocijan et al. (2019)이 제안한대로 결합된 SuperGLUE 작업에 DPR(Definite Pronoun Resolution) 데이터 세트(Rahman and Ng, 2012)도 포함됩니다. CNN/Daily Mail(Hermann et al., 2015) 데이터 세트는 질문 답변 작업으로 도입되었지만 Nallapati et al. (2016); 은 텍스트 요약에 적용했습니다. 우리는 See et al. (2017)의 익명화되지 않은 버전을 사용합니다. 추상 요약 작업으로. SQuAD(Rajpurkar et al., 2016)는 일반적인 질문 답변 벤치마크입니다. 우리의 실험에서 모델은 질문과 그 컨텍스트를 제공받고 토큰별로 답변을 생성하도록 요청받습니다. WMT 영어에서 독일어로의 경우 (Vaswani et al., 2017)(예: News Commentary v13, Common Crawl, Europarl v7) 및 newstest2013과 동일한 학습 데이터를 검증 세트로 사용합니다(Bojar et al., 2014). 영어에서 프랑스어로의 경우 2015년과 newstest2014의 표준 훈련 데이터를 검증 세트로 사용합니다(Bojar et al., 2015). 표준 저자원 기계 번역 벤치마크인 영어에서 루마니아어로의 경우 WMT 2016(Bojar et al., 2016)의 학습 및 검증 세트를 사용합니다. 우리는 영어 데이터에 대해서만 사전 훈련하므로 특정 모델을 번역하는 방법을 배우려면 새로운 언어로 텍스트를 생성하는 방법을 배워야 합니다.
2.4. 입력 및 출력 형식
위에서 설명한 다양한 작업 세트에 대한 단일 모델을 훈련하기 위해 우리는 고려하는 모든 작업을 "텍스트 대 텍스트" 형식으로 캐스팅합니다. 조건을 지정하고 일부 출력 텍스트를 생성하라는 요청을 받습니다. 이 프레임워크는 사전 훈련과 미세 조정 모두에 대해 일관된 훈련 목표를 제공합니다. 특히 모델은 작업에 관계없이 최대 우도 목표("교사 강제"(Williams and Zipser, 1989) 사용)로 훈련됩니다. 모델이 수행해야 하는 작업을 지정하기 위해 모델에 입력하기 전에 원래 입력 시퀀스에 작업별(텍스트) 접두사를 추가합니다.
예를 들어, 모델에게 "That is good"이라는 문장을 번역해 달라고 요청하는 것입니다. 영어에서 독일어로, 모델에는 "영어를 독일어로 번역: 좋습니다."라는 시퀀스가 제공됩니다. 그리고 "Das ist Gut"를 출력하도록 훈련될 것입니다. 텍스트 분류 작업의 경우 모델은 단순히 대상 레이블에 해당하는 단일 단어를 예측합니다. 예를 들어, MNLI 벤치마크(Williams et al., 2017)의 목표는 전제가 가설을 암시하는지("수반"), 모순되는지("모순"), 둘 다인지("중립")를 예측하는 것입니다. 전처리를 통해 입력 시퀀스는 "mnli 전제: 나는 비둘기를 싫어합니다."가 됩니다. 가설: 비둘기에 대한 나의 감정은 적개심으로 가득 차 있습니다.” 해당 타겟 단어로 “수반”. 모델이 가능한 레이블 중 어느 것과도 일치하지 않는 텍스트 분류 작업에서 텍스트를 출력하는 경우 문제가 발생합니다(예를 들어 작업에 대해 가능한 유일한 레이블이 "수반", "중립"인 경우 모델이 "햄버거"를 출력하는 경우). "또는 "모순"). 이 경우 우리는 항상 모델의 출력을 잘못된 것으로 간주합니다. 훈련된 모델에서는 이러한 동작을 관찰한 적이 없습니다. 주어진 작업에 사용되는 텍스트 접두사의 선택은 본질적으로 하이퍼파라미터입니다. 우리는 접두사의 정확한 표현을 변경하는 것이 미치는 영향이 제한적이므로 다양한 접두사 선택에 대한 광범위한 실험을 수행하지 않았다는 것을 발견했습니다. 몇 가지 입력/출력 예제가 포함된 텍스트-텍스트 프레임워크 다이어그램이 그림 1에 나와 있습니다. 부록 D에서 연구한 모든 작업에 대해 전처리된 입력의 전체 예제를 제공합니다.
우리의 텍스트-텍스트 프레임워크는 여러 NLP 작업을 공통 형식으로 변환하는 이전 작업인 McCann et al. (2018) 을 따릅니다. 이것은 10가지 NLP 작업에 대해 일관된 질문 답변 형식을 사용하는 벤치마크인 "Natural Language Decathlon"을 제안했습니다. Natural Language Decathlon은 또한 모든 모델이 다중 작업이어야 한다고 규정합니다. 즉, 모든 작업을 동시에 처리할 수 있어야 합니다. 대신 우리는 각 개별 작업에 대한 모델을 별도로 미세 조정하고 명시적인 질문-답변 형식 대신 짧은 작업 접두사를 사용합니다. Radfordet al. (2019)는 모델에 일부 입력을 접두사로 제공한 다음 자동 회귀 방식으로 출력을 샘플링하여 언어 모델의 제로샷 학습 기능을 평가합니다. 예를 들어, 자동 요약은 문서 뒤에 "TL;DR:"(일반적인 약어인 "너무 길어, 읽지 않음"의 줄임말) 텍스트를 입력하여 수행된 다음 자동 회귀 디코딩을 통해 요약을 예측합니다. 별도의 디코더로 출력을 생성하기 전에 인코더로 입력을 명시적으로 처리하는 모델을 주로 고려하며, 제로샷 학습보다는 전이 학습에 중점을 둡니다. 마지막으로 Keskar et al. (2019b)는 많은 NLP 작업을 "범위 추출"로 통합합니다. 여기서 가능한 출력 선택에 해당하는 텍스트가 입력에 추가되고 모델은 올바른 선택에 해당하는 입력 범위를 추출하도록 훈련됩니다. 대조적으로, 우리의 프레임워크는 가능한 모든 출력 선택을 열거하는 것이 불가능한 기계 번역 및 추상적인 요약과 같은 생성 작업도 허용합니다.
우리는 1과 5 사이의 유사성 점수를 예측하는 것이 목표인 회귀 작업인 STS-B를 제외하고 우리가 고려한 모든 작업을 텍스트-텍스트 형식으로 간단하게 캐스팅할 수 있었습니다. 이러한 점수의 대부분은 0.2 단위로 주석이 달렸으므로 모든 점수를 가장 가까운 0.2 단위로 반올림하고 결과를 숫자의 리터럴 문자열 표현으로 변환했습니다(예: 부동 소수점 값 2.57은 문자열 " 2.6”). 테스트 시 모델이 1에서 5 사이의 숫자에 해당하는 문자열을 출력하면 이를 부동 소수점 값으로 변환합니다. 그렇지 않으면 모델의 예측이 잘못된 것으로 간주됩니다. 이는 STS-B 회귀 문제를 21 클래스 분류 문제로 효과적으로 재구성합니다. 이와 별도로 Winograd 작업(GLUE의 WNLI, Super-GLUE의 WSC, SuperGLUE에 추가하는 DPR 데이터 세트)을 텍스트-텍스트 프레임워크에 더 적합한 간단한 형식으로 변환합니다. Winograd 작업의 예는 구절에 있는 명사구 중 하나 이상을 나타낼 수 있는 모호한 대명사가 포함된 텍스트 구절로 구성됩니다. 예를 들어, “시의원은 폭력이 두려워 시위대의 허가를 거부했다.”라는 구절에는 “시의원” 또는 “시위대”를 지칭할 수 있는 모호한 대명사 “그들”이 포함될 수 있습니다. 우리는 텍스트 구절에서 모호한 대명사를 강조하고 그것이 참조하는 명사를 예측하도록 모델에 요청하여 WNLI, WSC 및 DPR 작업을 텍스트 대 텍스트 문제로 분류합니다. 위에서 언급한 예는 “시의회 의원이 제안을 거부했습니다.”라는 입력으로 변환됩니다. *그들*은 폭력을 두려워했기 때문에 시위자들은 허가를 받았습니다.” 모델은 대상 텍스트 "시의원"을 예측하도록 훈련됩니다.
WSC의 경우 예에는 구절, 모호한 대명사, 후보 명사 및 후보가 대명사와 일치하는지 여부를 반영하는 참/거짓 레이블(관사 무시)이 포함됩니다. "False" 레이블이 있는 예에 대한 올바른 명사 대상을 모르기 때문에 "True" 레이블이 있는 예에 대해서만 훈련합니다. 평가를 위해 모델 출력의 단어가 후보 명사구에 있는 단어의 하위 집합인 경우(또는 그 반대) "True" 레이블을 할당하고 그렇지 않은 경우 "False" 레이블을 할당합니다. 이는 WSC 훈련 세트의 대략 절반을 제거하지만 DPR 데이터 세트는 약 1,000개의 대명사 분해 예를 추가합니다. DPR의 예에는 올바른 참조 명사가 주석으로 추가되어 위에 나열된 형식으로 이 데이터 세트를 쉽게 사용할 수 있습니다. WNLI 훈련 및 검증 세트는 WSC 훈련 세트와 상당히 중복됩니다. 검증 예제가 훈련 데이터에 누출되는 것을 방지하기 위해(섹션 3.5.2의 다중 작업 실험의 특정 문제) 따라서 우리는 WNLI에 대해 훈련하지 않으며 WNLI 검증 세트에 대한 결과를 보고하지 않습니다. WNLI 검증 세트에서 결과를 생략하는 것은 훈련 세트와 관련하여 "적대적"이라는 사실로 인해 표준 관행입니다(Devlin et al., 2018). 즉, 검증 예제는 모두 반대되는 훈련 예제의 약간 교란된 버전입니다. 상표. 따라서 검증 세트(결과가 테스트 세트에 표시되는 섹션 3.7을 제외한 모든 섹션)에 대해 보고할 때마다 평균 GLUE 점수에 WNLI를 포함하지 않습니다. WNLI의 예를 위에 설명된 "참조 명사 예측" 변형으로 변환하는 작업은 좀 더 복잡합니다. 이 프로세스는 부록 B에서 설명합니다.
3. 실험
NLP를 위한 전이 학습의 최근 발전은 새로운 사전 훈련 목표, 모델 아키텍처, 레이블이 지정되지 않은 데이터 세트 등과 같은 다양한 개발에서 비롯되었습니다. 이 섹션에서는 놀리기를 바라며 이러한 기술에 대한 실증적 조사를 수행합니다. 그들의 기여와 의미는 별개입니다. 그런 다음 우리가 고려하는 많은 작업에서 최첨단 기술을 달성하기 위해 얻은 통찰력을 결합합니다. NLP를 위한 전이 학습은 빠르게 성장하는 연구 분야이므로 가능한 모든 기술이나 아이디어를 다루는 것은 불가능합니다. 우리의 경험적 연구에서 보다 광범위한 문헌 검토를 위해 Ruder et al. (2019). 의 최근 설문 조사를 권장합니다.
우리는 합리적인 기준(섹션 3.1에 설명됨)을 취하고 한 번에 설정의 한 측면을 변경하여 이러한 기여를 체계적으로 연구합니다. 예를 들어 섹션 3.3에서는 나머지 실험 파이프라인을 고정한 상태로 유지하면서 감독되지 않은 다양한 목표의 성능을 측정합니다. 이 "좌표 상승" 접근 방식은 2차 효과를 놓칠 수 있지만(예를 들어, 감독되지 않은 특정 목표는 기준 설정보다 큰 모델에서 가장 잘 작동할 수 있음), 연구의 모든 요소에 대한 조합 탐색을 수행하는 데는 엄청나게 많은 비용이 듭니다. 향후 연구에서는 우리가 연구하는 접근 방식의 조합을 보다 철저하게 고려하는 것이 유익할 것으로 기대합니다.
우리의 목표는 가능한 한 많은 요소를 고정하면서 다양한 작업 집합에 대한 다양한 접근 방식을 비교하는 것입니다. 이 목표를 달성하기 위해 어떤 경우에는 기존 접근 방식을 정확하게 복제하지 않습니다. 예를 들어, BERT(Devlin et al., 2018)와 같은 "인코더 전용" 모델은 입력 토큰당 단일 예측 또는 전체 입력 시퀀스에 대한 단일 예측을 생성하도록 설계되었습니다. 따라서 분류 또는 범위 예측 작업에는 적용할 수 있지만 번역이나 추상 요약과 같은 생성 작업에는 적용할 수 없습니다. 따라서 우리가 고려하는 모델 아키텍처는 BERT와 동일하거나 인코더 전용 구조로 구성되지 않습니다. 대신, 우리는 유사한 접근 방식을 테스트합니다. 예를 들어 섹션 3.3에서 BERT의 "마스크된 언어 모델링" 목표와 유사한 목표를 고려하고 섹션 3.2에서 텍스트 분류 작업에 대해 BERT와 유사하게 작동하는 모델 아키텍처를 고려합니다.
다음 하위 섹션에서 기본 실험 설정을 간략하게 설명한 후 모델 아키텍처(섹션 3.2), 감독되지 않은 목표(섹션 3.3), 사전 학습 데이터 세트(섹션 3.4), 전송 접근 방식(섹션 3.5) 및 확장에 대한 실증적 비교를 수행합니다. (섹션 3.6). 이 섹션의 정점에서 우리는 연구에서 얻은 통찰력을 규모와 결합하여 우리가 고려하는 많은 작업에서 최첨단 결과를 얻습니다(섹션 3.7).
3.1. 기준선
기준에 대한 우리의 목표는 전형적이고 현대적인 관행을 반영하는 것입니다. 간단한 노이즈 제거 목표를 사용하여 표준 Transformer(섹션 2.1에 설명됨)를 사전 훈련한 다음 각 다운스트림 작업을 개별적으로 미세 조정합니다. 다음 하위 섹션에서는 이 실험 설정의 세부 사항을 설명합니다
3.1.1. 모델
우리 모델에서는 Vaswani et al. (2017). 이 제안한 표준 인코더-디코더 Transformer를 사용합니다. NLP를 위한 전이 학습에 대한 많은 최신 접근 방식은 단일 "스택"(예: 언어 모델링(Radford et al., 2018; Dong et al., 2019)) 또는 분류 및 범위 예측(Devlin et al. ., 2018; Yang et al., 2019)), 표준 인코더-디코더 구조를 사용하면 생성 및 분류 작업 모두에서 좋은 결과를 얻을 수 있음을 발견했습니다. 섹션 3.2에서 다양한 모델 아키텍처의 성능을 살펴봅니다.
우리의 기본 모델은 인코더와 디코더가 각각 "BERTBASE"(Devlin et al., 2018) 스택과 크기 및 구성이 유사하도록 설계되었습니다. 특히 인코더와 디코더는 모두 12개의 블록으로 구성됩니다(각 블록은 self-attention, 선택적 인코더-디코더 주의 및 피드포워드 네트워크로 구성됨). 각 블록의 피드포워드 네트워크는 출력 차원이 dff = 3072인 조밀한 레이어와 그 뒤에 오는 ReLU 비선형성 및 또 다른 밀집 레이어. 모든 주의 메커니즘의 "키" 및 "값" 행렬은 dkv = 64의 내부 차원을 가지며 모든 주의 메커니즘에는 12개의 헤드가 있습니다. 다른 모든 하위 레이어와 임베딩의 차원은 dmodel = 768입니다. 전체적으로 약 2억 2천만 개의 매개변수가 있는 모델이 생성됩니다. 기본 모델에는 하나가 아닌 두 개의 레이어 스택이 포함되어 있으므로 이는 BERTBASE 매개변수 수의 대략 두 배입니다. 정규화를 위해 모델에 드롭아웃이 적용되는 모든 곳에서 드롭아웃 확률 0.1을 사용합니다.
3.1.2. 훈련
섹션 2.4에 설명된 대로 모든 작업은 텍스트-텍스트 작업으로 공식화됩니다. 이를 통해 우리는 항상 표준 최대 가능성, 즉 교사 강제(Williams and Zipser, 1989) 및 교차 엔트로피 손실을 사용하여 훈련할 수 있습니다. 최적화를 위해AdaFactor(Shazeer 및 Stern, 2018)를 사용합니다. 테스트 시에는 그리디 디코딩(즉, 모든 단계에서 가장 높은 확률의 로짓 선택)을 사용합니다. 미세 조정하기 전에 C4에서 2^19 = 524,288 단계에 대해 각 모델을 사전 학습합니다. 우리는 최대 시퀀스 길이 512개와 배치 크기 128개 시퀀스를 사용합니다. 가능할 때마다 배치^10의 각 항목에 여러 시퀀스를 "패킹"하여 배치에 대략 2^16 = 65,536개의 토큰이 포함되도록 합니다. 전체적으로 이 배치 크기와 단계 수는 2^35 ≒ 34B 토큰에 대한 사전 학습에 해당합니다. 이는 대략 1370억 개의 토큰을 사용한 BERT(Devlin et al., 2018)나 대략 2.2T 토큰을 사용한 RoBERTa(Liu et al., 2019c)에 비해 상당히 적습니다. 2^35개의 토큰만 사용하면 합리적인 계산 예산을 확보하는 동시에 수용 가능한 성능을 위한 충분한 양의 사전 훈련을 제공합니다. 섹션 3.6 및 3.7에서 추가 단계에 대한 사전 훈련의 효과를 고려합니다. 2^35 토큰은 전체 C4 데이터 세트의 일부만 다루므로 사전 훈련 중에는 데이터를 반복하지 않습니다.
사전 훈련 중에는 "역 제곱근" 학습 속도 일정을 사용합니다: 1/√max(n, k ) 여기서 n은 현재 훈련 반복이고 k는 준비 단계 수입니다(우리의 실험 모두 104로 설정 ). 이는 처음 104개 단계에 대해 0.01의 일정한 학습 속도를 설정한 다음 사전 훈련이 끝날 때까지 학습 속도를 기하급수적으로 감소시킵니다. 우리는 또한 삼각형 학습률(Howard and Ruder, 2018)을 사용하여 실험했는데, 이는 약간 더 나은 결과를 생성했지만 총 훈련 단계 수를 미리 알아야 합니다. 일부 실험에서는 훈련 단계의 수를 다양화할 것이므로 보다 일반적인 역제곱근 일정을 선택합니다.
우리 모델은 모든 작업에서 2^18 = 262,144 단계에 맞게 미세 조정되었습니다. 이 값은 추가적인 미세 조정을 통해 이점을 얻을 수 있는 리소스가 많은 작업(즉, 대규모 데이터 세트가 있는 작업)과 빠르게 초과되는 리소스가 적은 작업(소형 데이터 세트) 간의 절충점으로 선택되었습니다. 미세 조정 중에 길이가 128개이고 시퀀스가 512개인 배치(즉, 배치당 2 16개 토큰)를 계속 사용합니다. 미세 조정 시 일정한 학습률 0.001을 사용합니다. 5,000단계마다 체크포인트를 저장하고, 가장 높은 검증 성능에 해당하는 모델 체크포인트에 대한 결과를 보고합니다. 여러 작업에 대해 미세 조정된 모델의 경우 각 작업에 가장 적합한 체크포인트를 독립적으로 선택합니다. 섹션 3.7의 실험을 제외한 모든 실험에 대해 테스트 세트에서 모델 선택을 수행하지 않도록 검증 세트에 결과를 보고합니다.
3.1.3. 어휘
우리는 SentencePiece(Kudo 및 Richardson, 2018)를 사용하여 텍스트를 WordPiece 토큰으로 인코딩합니다(Sennrich et al., 2015; Kudo, 2018). 모든 실험에서 우리는 32,000개의 단어로 구성된 어휘를 사용합니다. 우리는 궁극적으로 영어에서 독일어, 프랑스어, 루마니아어 번역에 대한 모델을 미세 조정하므로 어휘가 영어가 아닌 언어도 포함해야 합니다. 이 문제를 해결하기 위해 우리는 C4에서 사용되는 Common Crawl 스크랩의 페이지를 독일어, 프랑스어 및 루마니아어로 분류했습니다. 그런 다음 영어 C4 데이터 10개 부분과 독일어, 프랑스어 또는 루마니아어로 분류된 데이터 각각 1개 부분을 혼합하여 SentencePiece 모델을 훈련했습니다. 이 어휘는 모델의 입력과 출력 모두에서 공유되었습니다. 우리의 어휘는 모델이 미리 결정되고 고정된 언어 집합만 처리할 수 있도록 만듭니다.
3.1.4. 비지도 목표
레이블이 지정되지 않은 데이터를 활용하여 모델을 사전 학습하려면 레이블이 필요하지 않지만 (느슨하게 말하면) 다운스트림 작업에 유용할 일반화 가능한 지식을 모델에 가르치는 목표가 필요합니다. NLP 문제에 대한 모든 모델 매개변수를 사전 훈련하고 미세 조정하는 전이 학습 패러다임을 적용한 예비 작업에서는 다음을 사용했습니다. 사전 훈련을 위한 인과 언어 모델링 목표 (Dai and Le, 2015; Peters et al., 2018; Radford et al., 2018; Howard and Ruder, 2018). 그러나 최근 "노이즈 제거" 목표(Devlin et al., 2018; Taylor, 1953)("마스크된 언어 모델링"이라고도 함)가 더 나은 성능을 제공하는 것으로 나타났으며 결과적으로 빠르게 표준이 되었습니다. 잡음 제거 목표에서 모델은 입력에서 누락되거나 손상된 토큰을 예측하도록 훈련됩니다. BERT의 "마스크된 언어 모델링" 목표와 "단어 드롭아웃" 정규화 기술(Bowman et al., 2015)에서 영감을 받아 우리는 무작위로 샘플링한 다음 입력 시퀀스에서 토큰의 15%를 삭제하는 목표를 설계합니다. 삭제된 토큰의 모든 연속 범위는 단일 센티넬 토큰으로 대체됩니다. 각 센티널 토큰에는 시퀀스에 고유한 토큰 ID가 할당됩니다. 센티넬 ID는 우리 어휘에 추가되는 특수 토큰이며 어떤 단어와도 일치하지 않습니다. 그런 다음 대상은 입력 시퀀스에 사용된 동일한 센티널 토큰과 대상 시퀀스의 끝을 표시하는 최종 센티널 토큰으로 구분된 모든 삭제된 토큰 범위에 해당합니다. 연속된 토큰 범위를 마스크하고 누락된 토큰만 예측하는 선택은 사전 훈련의 계산 비용을 줄이기 위해 이루어졌습니다. 우리는 섹션 3.3에서 사전 훈련 목표에 대한 철저한 조사를 수행합니다. 이 목표를 적용한 결과 변환의 예가 그림 2에 나와 있습니다. 우리는 이 목표를 섹션 3.3의 다른 많은 변형과 경험적으로 비교합니다.
그림 2 : 기본 모델에서 사용하는 목표의 개략도입니다. 이 예에서는 “지난주 파티에 초대해 주셔서 감사합니다.”라는 문장을 처리합니다. "for", "inviting" 및 "last"(×로 표시)라는 단어는 손상을 위해 무작위로 선택됩니다. 손상된 토큰의 각 연속 범위는 예제에서 고유한 센티널 토큰(<X> 및 <Y>로 표시)으로 대체됩니다. "for"와 "inviting"이 연속적으로 발생하므로 단일 센티넬 <X>로 대체됩니다. 그런 다음 출력 시퀀스는 입력에서 이를 대체하는 데 사용되는 센티넬 토큰과 최종 센티넬 토큰 <Z>로 구분된 삭제된 범위로 구성됩니다.
3.1.5. 기준 성능
이 섹션에서는 위에서 설명한 기본 실험 절차를 사용하여 결과를 제시하여 일련의 다운스트림 작업에서 어떤 종류의 성능을 기대할 수 있는지 파악합니다. 이상적으로는 연구의 모든 실험을 여러 번 반복하여 결과에 대한 신뢰 구간을 얻습니다. 안타깝게도 우리가 실행하는 수많은 실험으로 인해 이는 엄청나게 많은 비용이 소요될 것입니다. 더 저렴한 대안으로 기본 모델을 처음부터 10번 훈련하고(즉, 다양한 무작위 초기화 및 데이터 세트 셔플링을 사용하여) 이러한 기본 모델 실행에 대한 분산이 각 실험 변형에도 적용된다고 가정합니다. 우리가 수행하는 대부분의 변경 사항은 실행 간 차이에 극적인 영향을 미칠 것으로 예상하지 않으므로 이는 다양한 변경 사항의 중요성에 대한 합리적인 표시를 제공해야 합니다. 이와 별도로, 사전 훈련 없이 모든 다운스트림 작업에 대해 2^18단계(미세 조정에 사용하는 것과 동일한 수)에 대한 모델 훈련 성능도 측정합니다. 이를 통해 기준 설정에서 사전 훈련이 모델에 얼마나 많은 이점을 제공하는지 알 수 있습니다.
표 1 : 기본 모델 및 훈련 절차를 통해 얻은 점수의 평균 및 표준 편차입니다. 비교를 위해 기본 모델을 미세 조정하는 데 사용된 것과 동일한 단계 수에 대해 처음부터(즉, 사전 학습 없이) 각 작업을 학습할 때의 성능도 보고합니다. 이 표의 모든 점수(및 표 14를 제외한 본 논문의 모든 표)는 각 데이터 세트의 검증 세트에 대해 보고됩니다.
본문에 결과를 보고할 때 공간을 절약하고 해석을 쉽게 하기 위해 모든 벤치마크에서 점수의 하위 집합만 보고합니다. GLUE 및 SuperGLUE의 경우 "GLUE" 및 "SGLUE"라는 제목 아래에 공식 벤치마크에 규정된 모든 하위 작업의 평균 점수를 보고합니다. 모든 번역 작업에 대해 "exp" 평활화 및 "intl" 토큰화를 사용하여 SacreBLEU v1.3.0(Post, 2018)에서 제공하는 BLEU 점수(Papineni et al., 2002)를 보고합니다. WMT 영어-독일어, 영어-프랑스어, 영어-루마니아어 점수를 각각 EnDe, EnFr 및 EnRo라고 합니다. CNN/Daily Mail의 경우 ROUGE-1-F, ROUGE-2-F 및 ROUGE-L-F 측정항목(Lin, 2004)에 대한 모델 성능이 높은 상관관계가 있음을 확인하여 ROUGE-2-F 점수를 보고합니다. "CNNDM"이라는 제목 아래 단독으로. 마찬가지로 SQuAD의 경우 "정확한 일치"와 "F1" 점수의 성능이 높은 상관 관계가 있음을 확인하므로 "정확한 일치" 점수만 보고합니다. 표 16, 부록 E의 모든 실험에 대해 모든 작업에서 달성한 모든 점수를 제공합니다.
우리의 결과 테이블은 모두 각 행이 각 벤치마크에 대한 점수를 제공하는 열과 함께 특정 실험 구성에 해당하도록 형식화되었습니다. 대부분의 테이블에는 기준 구성의 평균 성능이 포함됩니다. 기본 구성이 나타날 때마다 이를 표 1의 첫 번째 행과 같이 표시합니다. 또한 주어진 실험에서 최대값(최고값)의 두 표준편차 내에 있는 모든 점수를 확인합니다.
기본 결과는 표 1에 나와 있습니다. 전반적으로 결과는 비슷한 크기의 기존 모델과 비슷합니다. 예를 들어, BERTBASE는 SQuAD에서 80.8의 정확한 일치 점수와 MNLI 일치에서 84.4의 정확도를 달성한 반면, 우리는 각각 80.88과 84.24를 달성했습니다(표 16 참조). 우리의 기준선은 인코더-디코더 모델이고 대략 1/4 단계만큼 사전 훈련되었기 때문에 기준선을 BERTBASE와 직접 비교할 수 없습니다. 당연히 사전 훈련이 거의 모든 벤치마크에서 상당한 이득을 제공한다는 사실을 발견했습니다. 유일한 예외는 WMT 영어에서 프랑스어로, 이는 사전 훈련을 통해 얻을 수 있는 이득이 미미할 정도로 충분히 큰 데이터 세트입니다. 우리는 고자원 체제에서 전이 학습의 동작을 테스트하기 위해 실험에 이 작업을 포함했습니다. 가장 성능이 좋은 체크포인트를 선택하여 조기 중지를 수행하기 때문에 기준과 "사전 훈련 없음" 사이의 큰 차이는 사전 훈련이 제한된 데이터로 작업 성능을 얼마나 향상시키는지 강조합니다. 본 논문에서는 데이터 효율성의 향상을 명시적으로 측정하지는 않지만 이것이 전이 학습 패러다임의 주요 이점 중 하나임을 강조합니다.
그림 3 : 다양한 주의 마스크 패턴을 나타내는 행렬. Self-Attention 메커니즘의 입력과 출력은 각각 x와 y로 표시됩니다. 행 i와 열 j의 어두운 셀은 self-attention 메커니즘이 출력 시간 단계 i에서 입력 요소 j에 참석할 수 있음을 나타냅니다. 밝은 셀은 self-attention 메커니즘이 해당 i 및 j 조합에 참여하는 것이 허용되지 않음을 나타냅니다. 왼쪽: 완전히 표시되는 마스크를 사용하면 self-attention 메커니즘이 모든 출력 단계에서 전체 입력에 주의를 기울일 수 있습니다. 중간: 인과 마스크는 i번째 출력 요소가 "미래"의 입력 요소에 의존하는 것을 방지합니다. 오른쪽: 접두사가 있는 인과 마스킹을 사용하면 self-attention 메커니즘이 입력 시퀀스의 일부에 완전히 표시되는 마스킹을 사용할 수 있습니다.
실행 간 변동의 경우 대부분의 작업에서 실행 간 표준 편차가 작업 기준 점수의 1%보다 작다는 것을 알 수 있습니다. 이 규칙의 예외에는 GLUE 및 SuperGLUE 벤치마크의 리소스가 적은 작업인 CoLA, CB 및 COPA가 포함됩니다. 예를 들어, CB에서 기본 모델의 평균 F1 점수는 91.22이고 표준 편차는 3.237입니다(표 16 참조). 이는 부분적으로 CB의 검증 세트에 56개의 예제만 포함되어 있기 때문일 수 있습니다. GLUE 및 SuperGLUE 점수는 각 벤치마크를 구성하는 작업 전체의 점수 평균으로 계산됩니다. 결과적으로 CoLA, CB 및 COPA의 높은 실행 간 변동으로 인해 GLUE 및 SuperGLUE 점수만 사용하여 모델을 비교하기가 더 어려워질 수 있습니다.
3.2. 아키텍처
Transformer는 원래 인코더-디코더 아키텍처로 도입되었지만 NLP를 위한 전이 학습에 대한 최신 작업에서는 대체 아키텍처를 사용합니다. 이 섹션에서는 이러한 아키텍처 변형을 검토하고 비교합니다.
3.2.1. 모델 구조
다양한 아키텍처를 구별하는 주요 요소는 모델의 다양한 주의 메커니즘에서 사용되는 "마스크"입니다. Transformer의 self-attention 작업은 시퀀스를 입력으로 사용하고 동일한 길이의 새 시퀀스를 출력한다는 점을 기억하세요. 출력 시퀀스의 각 항목은 입력 시퀀스 항목의 가중 평균을 계산하여 생성됩니다. 구체적으로 yi는 출력 시퀀스의 i번째 요소를 나타내고 xj는 입력 시퀀스의 j번째 항목을 나타냅니다. yi는 Σj wi,j xj로 계산됩니다. 여기서 wi,j는 xi 및 xj의 함수로서 self-attention 메커니즘에 의해 생성된 스칼라 가중치입니다. 그런 다음 어텐션 마스크는 주어진 출력 시간 단계에서 어떤 입력 항목을 처리할 수 있는지 제한하기 위해 특정 가중치를 0으로 만드는 데 사용됩니다. 우리가 고려할 마스크의 다이어그램은 그림 3에 나와 있습니다. 예를 들어 인과 마스크(그림 3, 중간)는 j > i인 경우 모든 wi,j를 0으로 설정합니다.
그림 4 : 우리가 고려하는 Transformer 아키텍처 변형의 회로도. 이 다이어그램에서 블록은 시퀀스의 요소를 나타내고 선은 주의 가시성을 나타냅니다. 다양한 색상의 블록 그룹은 다양한 Transformer 레이어 스택을 나타냅니다. 어두운 회색 선은 완전히 보이는 마스킹에 해당하고 밝은 회색 선은 인과 마스킹에 해당합니다. 우리는 사용 "." 예측의 끝을 나타내는 특수 시퀀스 끝 토큰을 나타냅니다. 입력 및 출력 시퀀스는 각각 x와 y로 표시됩니다. 왼쪽: 표준 인코더-디코더 아키텍처는 디코더에서 인과 마스킹과 함께 인코더 및 인코더-디코더 주의에서 완전히 표시되는 마스킹을 사용합니다. 중간: 언어 모델은 단일 Transformer 레이어 스택으로 구성되며 전체적으로 인과 마스크를 사용하여 입력과 대상의 연결이 제공됩니다. 오른쪽: 언어 모델에 접두사를 추가하는 것은 입력에 대해 완전히 표시되는 마스킹을 허용하는 것과 같습니다.
우리가 고려하는 첫 번째 모델 구조는 두 개의 레이어 스택(입력 시퀀스를 제공하는 인코더와 새로운 출력 시퀀스를 생성하는 디코더)으로 구성된 인코더-디코더 변환기입니다. 이 아키텍처 변형의 개략도는 그림 4의 왼쪽 패널에 표시됩니다. 인코더는 "완전히 보이는" 주의 마스크를 사용합니다. 완전히 표시되는 마스킹을 사용하면 출력의 각 항목을 생성할 때 입력의 모든 항목에 주의를 기울이는 자체 주의 메커니즘이 가능합니다. 그림 3(왼쪽)에서 이 마스킹 패턴을 시각화합니다. 이러한 형태의 마스킹은 "접두사", 즉 나중에 예측할 때 사용되는 모델에 제공되는 일부 컨텍스트를 다룰 때 적합합니다. BERT(Devlin et al., 2018)는 또한 완전히 표시되는 마스킹 패턴을 사용하고 특수 "분류" 토큰을 입력에 추가합니다. 분류 토큰에 해당하는 시점의 BERT 출력은 입력 시퀀스 분류를 위한 예측에 사용됩니다.
Transformer 디코더의 self-attention 작업은 "인과적" 마스킹 패턴을 사용합니다. 출력 시퀀스의 i번째 항목을 생성할 때 인과 마스킹은 모델이 j > i에 대한 입력 시퀀스의 j번째 항목에 참석하는 것을 방지합니다. 이는 모델이 출력을 생성할 때 "미래를 볼" 수 없도록 훈련 중에 사용됩니다. 이 마스킹 패턴에 대한 주의 매트릭스는 그림 3의 중앙에 나와 있습니다.
인코더-디코더 변환기의 디코더는 출력 시퀀스를 자동 회귀적으로 생성하는 데 사용됩니다. 즉, 각 출력 시간 단계에서 토큰은 모델의 예측 분포에서 샘플링되고 이 샘플은 다음 출력 시간 단계에 대한 예측을 생성하기 위해 모델로 다시 공급됩니다. 따라서 인코더가 없는 Transformer 디코더는 언어 모델(LM), 즉 다음 단계 예측만을 위해 훈련된 모델로 사용될 수 있습니다(Liu et al., 2018; Radford et al., 2018; Al-Rfou 외, 2019). 이것이 우리가 고려하는 두 번째 모델 구조를 구성합니다. 이 아키텍처의 개략도는 그림 4의 중앙에 나와 있습니다. 실제로 NLP를 위한 전이 학습에 대한 초기 연구에서는 사전 훈련 방법으로 언어 모델링 목표와 함께 이 아키텍처를 사용했습니다(Radford et al., 2018).
언어 모델은 일반적으로 압축 또는 시퀀스 생성에 사용됩니다(Graves, 2013). 그러나 입력과 대상을 연결하기만 하면 텍스트-텍스트 프레임워크에서 사용할 수도 있습니다. 예를 들어 영어에서 독일어로 번역하는 경우를 생각해 보세요. 입력 문장이 "좋습니다"인 훈련 데이터 포인트가 있는 경우입니다. 목표가 "Das ist Gut."인 경우 연결된 입력 시퀀스인 "영어를 독일어로 번역: 좋습니다."에 대한 다음 단계 예측에 대해 모델을 훈련하기만 하면 됩니다. 목표: Das ist Gut.” 이 예에 대한 모델의 예측을 얻으려면 모델에 "영어를 독일어로 번역: 좋습니다."라는 접두사가 제공됩니다. target:” 그리고 시퀀스의 나머지 부분을 자동 회귀적으로 생성하라는 요청을 받습니다. 이러한 방식으로 모델은 입력이 주어지면 출력 순서를 예측할 수 있으며 이는 텍스트-텍스트 작업의 요구 사항을 충족합니다. 이 접근 방식은 최근 언어 모델이 감독 없이 텍스트를 텍스트로 변환하는 작업을 수행하는 방법을 학습할 수 있음을 보여주기 위해 사용되었습니다(Radford et al., 2019).
텍스트-텍스트 설정에서 언어 모델을 사용할 때 기본적이고 자주 인용되는 단점은 인과 마스킹으로 인해 입력 시퀀스의 i번째 항목에 대한 모델 표현이 i까지의 항목에만 의존하게 된다는 것입니다. 이것이 잠재적으로 불리한 이유를 확인하려면 예측을 요청하기 전에 모델에 접두사/컨텍스트가 제공되는 텍스트-텍스트 프레임워크를 고려하십시오(예: 접두사는 영어 문장이고 모델은 독일어 문장을 예측하도록 요청됩니다). 번역). 완전한 인과 마스킹을 사용하면 모델의 접두사 상태 표현은 접두사의 이전 항목에만 의존할 수 있습니다. 따라서 출력 항목을 예측할 때 모델은 불필요하게 제한되는 접두사 표현에 주의를 기울입니다. 시퀀스-투-시퀀스 모델에서 단방향 순환 신경망 인코더를 사용하는 것에 대해 비슷한 주장이 제기되었습니다(Bahdanau et al., 2015).
Transformer 기반 언어 모델에서는 마스킹 패턴을 변경하기만 하면 이 문제를 피할 수 있습니다. 인과 마스크를 사용하는 대신 시퀀스의 접두사 부분에서 완전히 보이는 마스킹을 사용합니다. 이 마스킹 패턴과 결과 "접두사 LM"(우리가 고려하는 세 번째 모델 구조)의 개략도는 각각 그림 3과 4의 가장 오른쪽 패널에 설명되어 있습니다. 위에서 언급한 영어-독일어 번역 예에서는 "영어를 독일어로 번역: 좋습니다."라는 접두사에 완전히 표시되는 마스킹이 적용됩니다. target:” 및 인과 마스킹은 “Das istgut” 목표를 예측하기 위해 훈련 중에 사용됩니다. 텍스트-텍스트 프레임워크에서 접두사 LM을 사용하는 것은 원래 Liu et al. (2018). 에 의해 제안되었습니다. 최근에는 Dong et al. (2019)는 이 아키텍처가 다양한 텍스트-텍스트 작업에 효과적이라는 것을 보여주었습니다. 이 아키텍처는 인코더와 디코더 간에 매개변수가 공유되고 인코더-디코더 주의가 입력 및 대상 시퀀스 전체에 걸쳐 완전한 주의로 대체되는 인코더-디코더 모델과 유사합니다.
텍스트-텍스트 프레임워크를 따를 때 접두사 LM 아키텍처는 분류 작업에 대한 BERT(Devlin et al., 2018)와 매우 유사합니다. 이유를 알아보려면 전제가 "나는 비둘기를 싫어합니다."이고 가설은 "비둘기에 대한 나의 감정은 적개심으로 가득 차 있습니다."인 MNLI 벤치마크의 예를 살펴보세요. 올바른 라벨은 "수반"입니다. 이 예를 언어 모델에 제공하기 위해 이를 "mnli 전제: 나는 비둘기를 싫어합니다."라는 시퀀스로 변환합니다. 가설: 비둘기에 대한 나의 감정은 적개심으로 가득 차 있습니다. 목표 : 수반”. 이 경우 완전히 표시되는 접두사는 "target:"이라는 단어까지의 전체 입력 시퀀스에 해당하며, 이는 BERT에서 사용되는 "분류" 토큰과 유사한 것으로 볼 수 있습니다. 따라서 우리 모델은 전체 입력에 대한 완전한 가시성을 확보한 다음 "수반"이라는 단어를 출력하여 분류를 수행하는 임무를 맡게 됩니다. 모델은 작업 접두사(이 경우 "mnli")가 주어지면 유효한 클래스 레이블 중 하나를 출력하는 방법을 쉽게 배울 수 있습니다. 따라서 접두사 LM과 BERT 아키텍처의 주요 차이점은 분류기가 접두사 LM에 있는 Transformer 디코더의 출력 계층에 단순히 통합된다는 것입니다.
3.2.2. 다양한 모델 구조 비교
이러한 아키텍처 변형을 실험적으로 비교하기 위해 우리는 의미 있는 방식으로 동등하다고 간주되는 각 모델을 원합니다. 두 모델의 매개변수 수가 동일하거나 주어진(입력-시퀀스, 목표-시퀀스) 쌍을 처리하기 위해 대략 동일한 양의 계산이 필요한 경우 두 모델이 동일하다고 말할 수 있습니다. 불행하게도 이 두 가지 기준에 따라 인코더-디코더 모델을 언어 모델 아키텍처(단일 Transformer 스택으로 구성)와 동시에 비교하는 것은 불가능합니다. 그 이유를 알아보기 위해 먼저 인코더에 L 레이어가 있고 디코더에 L 레이어가 있는 인코더-디코더 모델은 2L 레이어가 있는 언어 모델과 거의 동일한 수의 매개 변수를 가집니다. 그러나 동일한 L + L 인코더-디코더 모델은 L 레이어만 있는 언어 모델과 거의 동일한 계산 비용을 갖습니다. 이는 언어 모델의 L 레이어가 입력 및 출력 시퀀스 모두에 적용되어야 하는 반면 인코더는 입력 시퀀스에만 적용되고 디코더는 출력 시퀀스에만 적용된다는 사실에 따른 결과입니다. 이러한 등가성은 대략적인 것입니다. 인코더-디코더 주의로 인해 디코더에 몇 가지 추가 매개변수가 있고 시퀀스 길이가 2차인 주의 레이어에 일부 계산 비용도 있습니다. 그러나 실제로 우리는 L 계층 언어 모델과 L + L 계층 인코더-디코더 모델의 단계 시간이 거의 동일하다는 것을 관찰했으며 이는 대략 동일한 계산 비용을 시사합니다. 또한 우리가 고려하는 모델 크기의 경우 인코더-디코더 주의 레이어의 매개변수 수는 전체 매개변수 수의 약 10%이므로 L + L 레이어 인코더-디코더 모델이 동일하다는 단순화된 가정을 합니다. 2L 계층 언어 모델의 매개변수 수.
합리적인 비교 수단을 제공하기 위해 인코더-디코더 모델에 대한 여러 구성을 고려합니다. BERTBASE 크기의 레이어 스택에 있는 레이어 수와 매개변수를 각각 L과 P라고 하겠습니다. 주어진 입력-대상 쌍을 처리하기 위해 L + L 계층 인코더-디코더 모델 또는 L 계층 디코더 전용 모델에 필요한 FLOP 수를 참조하기 위해 M을 사용합니다. 전체적으로 다음을 비교할 것입니다.
• 인코더에 L 레이어가 있고 디코더에 L 레이어가 있는 인코더-디코더 모델. 이 모델에는 2P 매개변수와 M FLOP의 계산 비용이 있습니다. • 동등한 모델이지만 인코더와 디코더에서 매개변수를 공유하므로 P 매개변수와 M -FLOP 계산 비용이 발생합니다. • 인코더와 디코더에 각각 L/2 레이어가 있는 인코더-디코더 모델로, P 매개변수와 M/2-FLOP 비용을 제공합니다. • L 레이어와 P 매개변수가 포함된 디코더 전용 언어 모델과 결과적으로 M FLOP의 계산 비용이 발생합니다. • 동일한 아키텍처(따라서 동일한 수의 매개변수 및 계산 비용)를 갖지만 입력에 대해 완전히 가시적인 self-attention을 갖는 디코더 전용 접두사 LM입니다.
3.2.3. 목표
비지도 목표로서 기본 언어 모델링 목표와 섹션 3.1.4에 설명된 기본 노이즈 제거 목표를 모두 고려할 것입니다. 사전 훈련 목표로 역사적으로 사용되었기 때문에 언어 모델링 목표를 포함합니다(Dai and Le, 2015; Ramachandran et al., 2016; Howard and Ruder, 2018; Radford et al., 2018; Peters et al., 2018 ) 뿐만 아니라 우리가 고려하는 언어 모델 아키텍처에 자연스럽게 적합합니다. 예측을 하기 전에 접두사를 수집하는 모델(인코더-디코더 모델 및 접두사 LM)의 경우 레이블이 지정되지 않은 데이터 세트에서 텍스트 범위를 샘플링하고 임의의 지점을 선택하여 접두사와 대상 부분으로 분할합니다. 표준 언어 모델의 경우 처음부터 끝까지 전체 범위를 예측하도록 모델을 훈련합니다. 우리의 감독되지 않은 잡음 제거 목표는 텍스트-텍스트 모델을 위해 설계되었습니다. 이를 언어 모델과 함께 사용하기 위해 섹션 3.2.1에 설명된 대로 입력과 대상을 연결합니다.
3.2.4. 결과
우리가 비교하는 각 아키텍처에서 얻은 점수는 표 2에 나와 있습니다. 모든 작업에 대해 잡음 제거 목표가 있는 인코더-디코더 아키텍처가 가장 잘 수행되었습니다. 이 변형은 가장 높은 매개변수 수(2P )를 갖지만 P 매개변수 디코더 전용 모델과 동일한 계산 비용을 갖습니다. 놀랍게도 인코더와 디코더 전체에서 매개변수를 공유하는 경우 거의 비슷한 성능을 발휘한다는 사실을 발견했습니다. 이와 대조적으로 인코더 및 디코더 스택의 레이어 수를 절반으로 줄이면 성능이 크게 저하됩니다. 동시 작업(Lan et al., 2019)에서는 Transformer 블록 전체에서 매개변수를 공유하는 것이 많은 성능을 희생하지 않고 총 매개변수 수를 줄이는 효과적인 수단이 될 수 있다는 사실도 발견했습니다. XLNet은 또한 잡음 제거 목표를 가진 공유 인코더-디코더 접근 방식과 일부 유사합니다(Yang et al., 2019). 또한 공유 매개변수 인코더-디코더는 디코더 전용 접두사 LM보다 성능이 뛰어나며 명시적인 인코더-디코더 주의를 추가하는 것이 유익하다는 것을 나타냅니다. 마지막으로 우리는 잡음 제거 목표를 사용하면 언어 모델링 목표에 비해 항상 더 나은 다운스트림 작업 성능을 얻을 수 있다는 널리 알려진 개념을 확인합니다. 이 관찰은 이전에 Devlin et al. (2018), Voita et al. (2019), Lample 및 Conneau (2019) 등이 있습니다. 다음 섹션에서는 비지도 목표에 대해 더 자세히 살펴보겠습니다.
표 2 : 섹션 3.2.2에 설명된 다양한 아키텍처 변형의 성능. 우리는 P를 사용하여 12계층 기본 변환기 계층 스택의 매개변수 수를 참조하고 M을 사용하여 인코더-디코더 모델을 사용하여 시퀀스를 처리하는 데 필요한 FLOP를 참조합니다. 우리는 잡음 제거 목표(섹션 3.1.4에 설명됨)와 자동 회귀 목표(언어 모델을 훈련하는 데 일반적으로 사용됨)를 사용하여 각 아키텍처 변형을 평가합니다.
3.3. 지원되지 않는 목표
비지도 목표의 선택은 모델이 다운스트림 작업에 적용할 범용 지식을 얻는 메커니즘을 제공하므로 매우 중요합니다. 이로 인해 다양한 사전 훈련 목표가 개발되었습니다(Dai and Le, 2015; Ramachandran et al., 2016; Radford et al., 2018; Devlin et al., 2018; Yang et al., 2019; Liu 등, 2019b, Wang 등, 2019a, Song 등, 2019, Dong 등, 2019, Joshi 등, 2019). 이 섹션에서는 감독되지 않은 목표 공간에 대한 절차적 탐색을 수행합니다. 대부분의 경우 기존 목표를 정확하게 복제하지는 않습니다. 일부는 텍스트-텍스트 인코더-디코더 프레임워크에 맞게 수정되고, 다른 경우에는 여러 공통 접근 방식의 개념을 결합하는 목표를 사용합니다. 전반적으로 모든 목표는 레이블이 지정되지 않은 텍스트 데이터 세트에서 토큰화된 텍스트 범위에 해당하는 일련의 토큰 ID를 수집합니다. 토큰 시퀀스는 (손상된) 입력 시퀀스와 해당 대상을 생성하기 위해 처리됩니다. 그런 다음 모델은 목표 시퀀스를 예측할 가능성을 최대화하여 평소와 같이 훈련됩니다. 우리는 표 3에서 고려하는 많은 목표에 대한 예시를 제공합니다.
3.3.1. 서로 다른 높은 수준의 접근 방식
우선, 일반적으로 사용되는 목표에서 영감을 얻었지만 접근 방식이 크게 다른 세 가지 기술을 비교합니다. 먼저, 섹션 3.2.3에서 사용된 기본 "접두사 언어 모델링" 목표를 포함합니다. 이 기술은 텍스트 범위를 두 개의 구성 요소로 분할합니다. 하나는 인코더에 대한 입력으로 사용하고 다른 하나는 디코더에서 예측할 대상 시퀀스로 사용합니다. 둘째, BERT(Devlin et al., 2018)에서 사용되는 "Masked Language Modeling"(MLM) 목표에서 영감을 받은 목표를 고려합니다. MLM은 일정 범위의 텍스트를 가져와 토큰의 15%를 손상시킵니다. 손상된 토큰의 90%는 특수 마스크 토큰으로 대체되고, 10%는 무작위 토큰으로 대체됩니다. BERT는 인코더 전용 모델이므로 사전 학습 중 목표는 인코더 출력에서 마스킹된 토큰을 재구성하는 것입니다. 인코더-디코더의 경우 손상되지 않은 전체 시퀀스를 대상으로 사용합니다. 이는 손상된 토큰만 대상으로 사용하는 기본 목표와 다릅니다. 섹션 3.3.2에서 이 두 가지 접근 방식을 비교합니다. 마지막으로, 우리는 또한 기본적인 디셔핑 목적을 고려합니다. (Liu et al., 2019a)에서는 잡음 제거 순차 자동 인코더에 적용되었습니다. 이 접근 방식은 일련의 토큰을 가져와서 섞은 다음 원본 디셔플링된 시퀀스를 대상으로 사용합니다. 표 3의 처음 세 행에서는 이 세 가지 방법에 대한 입력 및 목표의 예를 제공합니다.
이 세 가지 목표의 성능은 표 4에 나와 있습니다. 전반적으로 BERT 스타일 목표가 가장 잘 수행되지만 접두사 언어 모델랑 목표는 번역 작업에서 비슷한 성능을 얻습니다. 실제로 BERT 목표의 동기는 언어 모델 기반 사전 훈련을 능가하는 것이었습니다. 디셔플링 목표는 접두사 언어 모델링과 BERT 스타일 목표보다 성능이 상당히 나쁩니다.
표 3 : 입력 텍스트 "지난주에 파티에 초대해 주셔서 감사합니다"에 적용되는 것으로 간주되는 일부 비지도 목표에 의해 생성된 입력 및 목표의 예입니다. 우리의 모든 목표는 토큰화된 텍스트를 처리한다는 점에 유의하세요. 이 특정 문장의 경우 모든 단어는 어휘에 의해 단일 토큰에 매핑되었습니다. 모델이 전체 입력 텍스트를 재구성하는 작업을 수행함을 나타 내기 위해 (원본 텍스트)를 대상으로 씁니다. <M>은 공유 마스크 토큰을 나타내고 <X>, <Y>, <Z>는 고유한 토큰 ID가 할당된 센티널 토큰을 나타냅니다. BERT 스타일 목표(두 번째 행)에는 일부 토큰이 임의의 토큰 ID로 대체되는 손상이 포함되어 있습니다. 회색으로 표시된 단어 apple을 통해 이를 보여줍니다.
표 4 : 섹션 3.3.1에 설명된 세 가지 서로 다른 사전 교육 목표를 수행합니다.
표 5 : BERT 스타일 사전 훈련 목표의 변형 비교. 처음 두 변형에서 모델은 손상되지 않은 원본 텍스트 세그먼트를 재구성하도록 훈련되었습니다. 후자의 경우 모델은 손상된 토큰의 순서만 예측합니다.
3.3.2. BERT 목표 단순화
이전 섹션의 결과를 바탕으로 이제 BERT 스타일 노이즈 제거 목표에 대한 수정을 탐색하는 데 중점을 둘 것입니다. 이 목표는 원래 분류 및 범위 예측을 위해 훈련된 인코더 전용 모델에 대한 사전 훈련 기술로 제안되었습니다. 따라서 인코더-디코더 텍스트-텍스트 설정에서 더 나은 성능을 발휘하거나 더 효율적이도록 수정하는 것이 가능할 수 있습니다. 먼저, 무작위 토큰 교환 단계를 포함하지 않는 BERT 스타일 목표의 간단한 변형을 고려합니다. 결과 목표는 단순히 입력에 있는 토큰의 15%를 마스크 토큰으로 대체하고 모델은 손상되지 않은 원래 시퀀스를 재구성하도록 훈련됩니다. 유사한 마스킹 대물렌즈가 Song et al. (2019) 에 의해 사용되었습니다. 이것이 "MASS"라고 했기 때문에 우리는 이 변형을 "MASS 스타일" 목표라고 부릅니다. 둘째, 디코더의 긴 시퀀스에 대한 self-attention이 필요하기 때문에 손상되지 않은 전체 텍스트 범위를 예측하는 것을 피하는 것이 가능한지 확인하는 데 관심이 있었습니다. 이를 달성하기 위해 두 가지 전략을 고려합니다. 첫째, 손상된 각 토큰을 마스크 토큰으로 교체하는 대신 손상된 토큰의 연속된 각 범위 전체를 고유한 마스크 토큰으로 교체합니다. 그런 다음 대상 시퀀스는 "손상된" 범위의 연결이 되며 각 범위에는 입력에서 이를 대체하는 데 사용되는 마스크 토큰이 앞에 붙습니다. 이는 섹션 3.1.4에 설명된 기준선에서 사용하는 사전 훈련 목표입니다. 둘째, 입력 시퀀스에서 손상된 토큰을 완전히 삭제하고 삭제된 토큰을 순서대로 재구성하는 작업을 모델에 할당하는 변형도 고려합니다. 이러한 접근법의 예는 표 3의 다섯 번째 및 여섯 번째 행에 나와 있습니다.
원래 BERT 스타일 목표와 이 세 가지 대안의 실증적 비교가 표 5에 나와 있습니다. 우리는 설정에서 이러한 모든 변형이 유사하게 수행된다는 것을 발견했습니다. 유일한 예외는 손상된 토큰을 삭제하면 CoLA의 상당히 높은 점수(60.04, 기준 평균 53.84에 비해, 표 16 참조) 덕분에 GLUE 점수가 약간 향상되었다는 것입니다. 이는 CoLA가 주어진 문장이 문법적으로나 구문적으로 허용 가능한지 여부를 분류하고, 토큰이 누락된 시기를 판단할 수 있는 것이 허용 가능성 감지와 밀접한 관련이 있다는 사실 때문일 수 있습니다. 그러나 토큰을 삭제하는 것은 SuperGLUE에서 센티넬 토큰으로 교체하는 것보다 성능이 완전히 나빴습니다. 전체 원본 시퀀스를 예측할 필요가 없는 두 가지 변형("손상된 범위 교체" 및 "손상된 범위 삭제")은 모두 대상 시퀀스를 더 짧게 만들고 결과적으로 훈련을 더 빠르게 만들기 때문에 잠재적으로 매력적입니다. 앞으로 우리는 손상된 범위를 센티넬 토큰으로 대체하고 손상된 토큰만 예측하는 변형을 탐색할 것입니다(기본 목표에서와 같이).
표 6 : i.i.d.의 성능 부패율이 다른 부패 목표.
3.3.3. 부패율 변화
지금까지 우리는 BERT에서 사용되는 가치인 토큰의 15%를 손상시켰습니다(Devlin et al., 2018). 다시 말하지만, 우리의 텍스트-텍스트 프레임워크는 BERT와 다르기 때문에 다른 손상률이 우리에게 더 나은지 확인하는 데 관심이 있습니다. 표 6에서 10%, 15%, 25%, 50%의 부패율을 비교합니다. 전반적으로 부패율이 모델 성능에 제한적인 영향을 미친다는 것을 알 수 있습니다. 유일한 예외는 우리가 고려하는 최대 손상률(50%)이 GLUE 및 SQuAD의 성능을 크게 저하시킨다는 것입니다. 더 높은 손상률을 사용하면 목표가 길어져 잠재적으로 훈련 속도가 느려질 수 있습니다. 이러한 결과와 BERT가 설정한 역사적 선례를 바탕으로 우리는 앞으로 부패율을 15%로 사용할 것입니다.
3.3.4. 스팬 손상
이제 우리는 더 짧은 목표를 예측하여 훈련 속도를 높이는 목표를 향해 나아갑니다. 지금까지 우리가 사용한 접근 방식은 i.i.d. 각 입력 토큰에 대한 손상 여부를 결정합니다. 여러 개의 연속 토큰이 손상된 경우 해당 토큰은 "범위"로 처리되며 단일 고유 마스크 토큰이 전체 범위를 대체하는 데 사용됩니다. 전체 범위를 단일 토큰으로 바꾸면 레이블이 지정되지 않은 텍스트 데이터가 더 짧은 시퀀스로 처리됩니다. 우리는 i.i.d.를 사용하고 있기 때문에 부패 전략에 있어서, 항상 상당한 수의 손상된 토큰이 연속적으로 나타나는 것은 아닙니다.
결과적으로 우리는 i.i.d.의 개별 토큰을 손상시키는 대신 특정 범위의 토큰을 손상시켜 추가적인 속도 향상을 얻습니다. 방법. 부패 범위는 이전에 BERT의 사전 훈련 목표로 간주되었으며 성능을 향상시키는 것으로 밝혀졌습니다 (Joshi et al., 2019).
이 아이디어를 테스트하기 위해 연속적이고 무작위 간격으로 배치된 토큰 범위를 구체적으로 손상시키는 목표를 고려합니다. 이 목표는 손상될 토큰의 비율과 손상된 전체 범위 수에 따라 매개변수화될 수 있습니다. 그런 다음 지정된 매개변수를 충족하기 위해 스팬 길이가 무작위로 선택됩니다. 예를 들어, 500개의 토큰 시퀀스를 처리 중이고 토큰의 15%가 손상되어야 하고 총 25개의 범위가 있어야 한다고 지정한 경우 손상된 토큰의 총 수는 500 × 0.15 = 75가 되며 평균은 500 × 0.15 = 75가 됩니다. 범위 길이는 75/25 = 3입니다. 원래 시퀀스 길이와 손상 비율이 주어지면 이 목표를 평균 범위 길이 또는 전체 범위 수로 동등하게 매개변수화할 수 있습니다.
표 7 : 다양한 평균 범위 길이에 대한 범위 손상 목표(Joshi et al.(2019)에서 영감을 얻음)의 성능. 모든 경우에 원본 텍스트 시퀀스의 15%가 손상되었습니다.
그림 5 : 비지도 목표 탐색의 흐름도. 먼저 섹션 3.3.1에서 몇 가지 서로 다른 접근 방식을 고려하고 BERT 스타일 노이즈 제거 목표가 가장 잘 수행된다는 것을 확인했습니다. 그런 다음 섹션 3.3.2에서 더 짧은 타겟 시퀀스를 생성하도록 BERT 목표를 단순화하는 다양한 방법을 고려합니다. 삭제된 범위를 센티넬 토큰으로 대체하는 것이 잘 수행되고 짧은 대상 시퀀스가 발생한다는 점을 고려하여 섹션 3.3.3에서 다양한 손상 비율을 실험합니다. 마지막으로 섹션 3.3.4에서 연속된 토큰 범위를 의도적으로 손상시키는 목표를 평가합니다.
표 7에서는 범위 손상 목표를 i.i.d 손상 목표와 비교합니다. 우리는 모든 경우에 15%의 손상률을 사용하고 평균 범위 길이 2, 3, 5 및 10을 사용하여 비교합니다. 다시 말하지만, 평균 범위 길이가 10인 버전은 약간 낮은 성능을 보이지만 이러한 목표 사이에는 제한된 차이가 있습니다. 경우에 따라 다른 값. 우리는 또한 특히 평균 스팬 길이 3을 사용하는 것이 i.i.d.보다 약간(그러나 상당히) 성능이 우수하다는 것을 발견했습니다. 대부분의 비번역 벤치마크에 대한 목표입니다. 다행스럽게도 범위 손상 목표는 i.i.d.에 비해 훈련 중에 약간의 속도 향상을 제공합니다. 범위 손상이 평균적으로 더 짧은 시퀀스를 생성하기 때문에 노이즈 접근 방식입니다.
3.3.5. 논의
그림 5는 비지도 목표를 탐색하는 동안 이루어진 선택의 흐름도를 보여줍니다. 전반적으로, 우리가 관찰한 성능에서 가장 중요한 차이점은 잡음 제거 목표가 사전 훈련을 위한 언어 모델링 및 디셔플링보다 성능이 뛰어나다는 것입니다. 우리가 조사한 노이즈 제거 목표의 다양한 변형에서 눈에 띄는 차이는 관찰되지 않았습니다. 그러나 목표(또는 목표의 매개변수화)가 다르면 시퀀스 길이가 달라져 훈련 속도도 달라질 수 있습니다. 이는 여기서 고려한 잡음 제거 목표 중에서 선택하는 것이 주로 계산 비용에 따라 수행되어야 함을 의미합니다. 우리의 결과는 또한 우리가 여기서 고려하는 것과 유사한 목표를 추가로 탐색해도 우리가 고려하는 작업과 모델에 대해 상당한 이익을 얻지 못할 수도 있음을 시사합니다. 대신 레이블이 지정되지 않은 데이터를 활용하는 완전히 다른 방법을 탐색하는 것이 운이 좋을 수도 있습니다.
3.4. 사전 훈련 데이터 세트
비지도 목표와 마찬가지로 사전 훈련 데이터 세트 자체는 전이 학습 파이프라인의 중요한 구성 요소입니다. 그러나 목표 및 벤치마크와 달리 새로운 사전 훈련 데이터 세트는 일반적으로 그 자체로는 중요한 기여로 간주되지 않으며 사전 훈련된 모델 및 코드와 함께 공개되지 않는 경우가 많습니다. 대신 새로운 방법이나 모델을 제시하는 과정에서 소개되는 경우가 많다. 결과적으로, 다양한 사전 학습 데이터 세트에 대한 비교가 상대적으로 적고 사전 학습에 사용되는 "표준" 데이터 세트가 부족했습니다. 최근 주목할만한 일부 예외(Baevski et al., 2019; Liu et al., 2019c; Yang et al., 2019)는 새로운 대규모(종종 Common Crawl 소스) 데이터 세트에 대한 사전 교육을 더 작은 기존 데이터를 사용하는 것과 비교했습니다. 설정합니다(종종 Wikipedia). 사전 훈련 데이터 세트가 성능에 미치는 영향을 더 깊이 조사하기 위해 이 섹션에서는 C4 데이터 세트의 변형과 기타 사전 훈련 데이터 소스를 비교합니다. 우리는 TensorFlow 데이터 세트의 일부로 간주하는 모든 C4 데이터 세트 변형을 출시합니다.
3.4.1. 라벨이 지정되지 않은 데이터 세트
C4를 만들 때 우리는 Common Crawl에서 웹에서 추출된 텍스트를 필터링하기 위해 다양한 경험적 방법을 개발했습니다(설명은 섹션 2.2 참조). 우리는 이 필터링이 다른 필터링 접근 방식 및 일반적인 사전 훈련 데이터 세트와 비교하는 것 외에도 다운스트림 작업의 성능을 향상시키는지 여부를 측정하는 데 관심이 있습니다. 이를 위해 다음 데이터 세트에 대한 사전 학습 후 기본 모델의 성능을 비교합니다.
C4 기준선으로 먼저 섹션 2.2에 설명된 대로 제안된 레이블이 없는 데이터 세트에 대한 사전 훈련을 고려합니다. 필터링되지 않은 C4 C4를 생성하는 데 사용한 경험적 필터링(중복 제거, 나쁜 단어 제거, 문장만 유지 등)의 효과를 측정하기 위해 이 필터링을 생략하는 대체 버전의 C4도 생성합니다. 영어 텍스트를 추출하기 위해 여전히 langDetect를 사용하고 있습니다. 결과적으로 langDetect는 때때로 자연스럽지 않은 영어 텍스트에 낮은 확률을 할당하기 때문에 "필터링되지 않은" 변형에는 여전히 일부 필터링이 포함되어 있습니다.
RealNews와 유사한 최근 연구에서는 뉴스 웹사이트에서 추출한 텍스트 데이터를 사용했습니다(Zellers et al., 2019; Baevski et al., 2019). 이 접근 방식과 비교하기 위해 "RealNews" 데이터 세트에 사용된 도메인 중 하나의 콘텐츠만 포함하도록 C4를 추가로 필터링하여 레이블이 지정되지 않은 또 다른 데이터 세트를 생성합니다(Zellers et al., 2019). 비교의 용이성을 위해 C4에서 사용된 휴리스틱 필터링 방법을 유지합니다. 유일한 차이점은 뉴스가 아닌 콘텐츠를 표면적으로 생략했다는 것입니다.
표 8 : 다양한 데이터 세트에 대한 사전 학습으로 인한 성능입니다. 처음 4개의 변형은 새로운 C4 데이터 세트를 기반으로 합니다.
WebText 유사 마찬가지로 WebText 데이터 세트(Radford et al., 2019)는 콘텐츠 집계 웹사이트 Reddit에 제출되고 최소 3점의 "점수"를 받은 웹페이지의 콘텐츠만 사용합니다. Reddit에 제출된 웹페이지의 점수 웹페이지를 지지(공감)하거나 반대(비추천)한 사용자의 비율을 기준으로 계산됩니다. Reddit 점수를 품질 신호로 사용하는 이유는 사이트 사용자가 고품질 텍스트 콘텐츠에만 찬성한다는 것입니다. 비교 가능한 데이터 세트를 생성하기 위해 우리는 먼저 OpenWebText 노력으로 준비된 목록에 나타난 URL에서 유래하지 않은 모든 콘텐츠를 C4에서 제거하려고 시도했습니다. 그러나 이로 인해 대부분의 콘텐츠가 약 2GB 정도에 불과했습니다. 페이지는 Reddit에 표시되지 않습니다. C4는 한 달 간의 Common Crawl 데이터를 기반으로 생성되었음을 기억하세요. 따라서 우리는 엄청나게 작은 데이터 세트를 사용하지 않기 위해 2018년 8월부터 2019년 7월까지 Common Crawl에서 12개월 간의 데이터를 다운로드하고 C4에 휴리스틱 필터링을 적용한 다음 Reddit 필터를 적용했습니다. 이로 인해 원래 40GB WebText 데이터 세트(Radford et al., 2019)와 비슷한 크기인 17GB WebText와 유사한 데이터 세트가 생성되었습니다.
Wikip edia Wikipedia 웹사이트는 공동으로 작성된 수백만 개의 백과사전 기사로 구성되어 있습니다. 사이트의 콘텐츠는 엄격한 품질 지침을 따르므로 깨끗하고 자연스러운 텍스트의 신뢰할 수 있는 소스로 사용되었습니다. 우리는 기사에서 마크업이나 참조 섹션을 생략한 TensorFlow Datasets13의 영어 Wikipedia 텍스트 데이터를 사용합니다.
Wikip edia + Toronto Bo oks Corpus Wikipedia의 사전 학습 데이터를 사용할 때의 단점은 자연 텍스트(백과사전 기사)의 가능한 도메인을 하나만 나타낸다는 것입니다. 이를 완화하기 위해 BERT(Devlin et al., 2018)는 Wikipedia의 데이터를 Toronto Books Corpus(TBC)(Zhu et al., 2015)와 결합했습니다. TBC에는 자연어의 다양한 영역을 나타내는 eBook에서 추출된 텍스트가 포함되어 있습니다. BERT의 인기로 인해 Wikipedia + TBC 조합이 많은 후속 작업에서 사용되었습니다.
이러한 각 데이터 세트에 대한 사전 학습 후 달성된 결과는 표 8에 나와 있습니다. 첫 번째로 확실한 점은 C4에서 휴리스틱 필터링을 제거하면 성능이 균일하게 저하되고 필터링되지 않은 변형이 모든 작업에서 최악의 성능을 발휘하게 된다는 것입니다. 이 외에도 우리는 어떤 경우에는 더 제한된 도메인을 가진 사전 훈련 데이터 세트가 다양한 C4 데이터 세트보다 성능이 우수하다는 것을 발견했습니다. 예를 들어 Wikipedia + TBC 코퍼스를 사용하면 SuperGLUE 점수 73.24가 생성되어 기준 점수(C4 사용) 71.36을 능가합니다. 이는 거의 전적으로 MultiRC의 Exact Match 점수가 25.78(기준, C4)에서 50.93(Wikipedia + TBC)으로 성능이 향상되었기 때문입니다(표 16 참조). MultiRC는 가장 큰 데이터 소스가 TBC에서 다루는 영역인 소설 책에서 나오는 독해 데이터 세트입니다. 마찬가지로 사전 훈련을 위해 RealNews와 유사한 데이터 세트를 사용하면 뉴스 기사에 대한 독해력을 측정하는 데이터 세트인 ReCoRD의 Exact Match 점수가 68.16에서 73.72로 증가했습니다. 마지막 예로, Wikipedia의 데이터를 사용하면 Wikipedia에서 가져온 구절이 포함된 질문 답변 데이터 세트인 SQuAD에서 상당한(그러나 덜 극적인) 이득을 얻었습니다. 이전 연구에서도 비슷한 관찰이 이루어졌습니다. Beltagyet al. (2019)은 연구 논문의 텍스트에 대해 BERT를 사전 훈련하면 과학 작업에 대한 성능이 향상된다는 것을 발견했습니다. 이러한 발견의 주요 교훈은 도메인 내 레이블이 없는 데이터에 대한 사전 교육이 다운스트림 작업의 성능을 향상시킬 수 있다는 것입니다. 우리의 목표가 임의 영역의 언어 작업에 빠르게 적응할 수 있는 모델을 사전 훈련하는 것이라면 이는 놀라운 일이 아니지만 불만족스럽습니다. Liu et al. (2019c)는 또한 보다 다양한 데이터 세트에 대한 사전 교육을 통해 다운스트림 작업이 개선되는 것을 관찰했습니다. 이 관찰은 또한 자연어 처리를 위한 영역 적응에 대한 평행선 연구에 동기를 부여합니다. 이 분야에 대한 조사는 예를 들어 다음을 참조하십시오. Ruder (2019); Li (2012).
단일 도메인에 대한 사전 훈련의 단점은 결과 데이터 세트가 종종 상당히 작다는 것입니다. 마찬가지로 WebText와 유사한 변종은 기준 설정에서 C4 데이터 세트보다 성능이 더 좋거나 Reddit 기반 필터링은 Common의 12배 더 많은 데이터를 기반으로 함에도 불구하고 C4보다 약 40배 작은 데이터 세트를 생성했습니다. 기다. 그러나 기본 설정에서는 2^35 ≒ 34B 토큰에 대해서만 사전 훈련을 했으며 이는 우리가 고려한 가장 작은 사전 훈련 데이터 세트보다 약 8배 더 큽니다. 다음 섹션에서는 더 작은 사전 학습 데이터 세트를 사용하여 문제가 발생하는 지점을 조사합니다.
3.4.2. 사전 훈련 데이터 세트 크기
C4를 생성하는 데 사용하는 파이프라인은 매우 큰 사전 훈련 데이터 세트를 생성할 수 있도록 설계되었습니다. 너무 많은 데이터에 액세스할 수 있으므로 예제를 반복하지 않고도 모델을 사전 학습할 수 있습니다. 사전 훈련 중에 예제를 반복하는 것이 다운스트림 성능에 도움이 될지 아니면 해로울지는 확실하지 않습니다. 사전 훈련 목표 자체가 확률론적이며 모델이 동일한 정확한 데이터를 여러 번 보는 것을 방지하는 데 도움이 될 수 있기 때문입니다. 제한된 레이블이 없는 데이터 세트 크기의 효과를 테스트하기 위해 우리는 C4의 인위적으로 잘린 버전에서 기본 모델을 사전 훈련했습니다. 우리는 2^35 ≒ 34B 토큰(C4 전체 크기의 작은 부분)에 대해 기본 모델을 사전 훈련했다는 점을 기억하세요. 2^29 , 2^27 , 2^25 및 2^23 토큰으로 구성된 C4의 잘린 변형에 대한 학습을 고려합니다. 이러한 크기는 사전 훈련 과정에서 데이터 세트를 각각 64, 256, 1,024, 4,096회 반복하는 것에 해당합니다.
표 9 : 사전 학습 중 데이터 반복 효과를 측정합니다. 이 실험에서는 C4의 첫 번째 N 토큰(첫 번째 열에 표시된 다양한 N 값 포함)만 사용하지만 여전히 2^35개가 넘는 토큰을 사전 훈련합니다. 이로 인해 사전 훈련 과정에서 데이터 세트가 반복되고(각 실험의 반복 횟수는 두 번째 열에 표시됨) 암기될 수 있습니다(그림 6 참조).
결과적인 다운스트림 성능은 표 9에 나와 있습니다. 예상대로 데이터 세트 크기가 줄어들면 성능이 저하됩니다. 이는 모델이 사전 훈련 데이터 세트를 기억하기 시작하기 때문일 수 있다고 의심됩니다. 이것이 사실인지 측정하기 위해 그림 6에 각 데이터 세트 크기에 대한 훈련 손실을 표시합니다. 실제로 모델은 사전 훈련 데이터 세트의 크기가 줄어들면서 훈련 손실이 상당히 작아져 기억 가능성이 있음을 시사합니다. Baevskiet al. (2019)도 마찬가지로 사전 훈련 데이터 세트 크기를 자르면 다운스트림 작업 성능이 저하될 수 있음을 관찰했습니다. 사전 훈련 데이터 세트가 64회만 반복되면 이러한 효과가 제한된다는 점에 유의하세요. 이는 사전 훈련 데이터를 어느 정도 반복해도 해롭지 않을 수 있음을 나타냅니다. 그러나 추가적인 사전 훈련이 유익할 수 있고(섹션 3.6에서 볼 수 있듯이) 레이블이 없는 추가 데이터를 얻는 것이 저렴하고 쉽다는 점을 고려하면 가능할 때마다 대규모 사전 훈련 데이터 세트를 사용하는 것이 좋습니다. 또한 이 효과는 모델 크기가 클수록 더 두드러질 수 있습니다. 즉, 모델이 클수록 더 작은 사전 학습 데이터 세트에 과적합되는 경향이 더 클 수 있습니다.
3.5. 훈련 전략
지금까지 우리는 모델의 모든 매개변수가 개별 지도 작업에 대해 미세 조정되기 전에 비지도 작업에 대해 사전 훈련되는 설정을 고려했습니다. 이 접근 방식은 간단하지만 다운스트림/감독 작업에 대한 모델을 교육하기 위한 다양한 대체 방법이 제안되었습니다. 이 섹션에서는 여러 작업에 대해 동시에 모델을 훈련하는 접근 방식 외에도 모델을 미세 조정하기 위한 다양한 방식을 비교합니다.
3.5.1. 미세 조정 방법
모델의 모든 매개변수를 미세 조정하면 특히 자원이 부족한 작업에서 차선의 결과를 초래할 수 있다는 주장이 있었습니다(Peters et al., 2019). 텍스트 분류 작업을 위한 전이 학습에 대한 초기 결과는 고정된 사전 훈련된 모델에 의해 생성된 문장 임베딩을 공급받은 소규모 분류기의 매개변수만 미세 조정하는 것을 옹호했습니다(Subra-anian et al., 2018; Kiros et al., 2015; Logeswaran 및 Lee, 2018; Hill 외, 2016; Conneau 외, 2017). 이 접근 방식은 전체 디코더가 주어진 작업에 대한 대상 시퀀스를 출력하도록 훈련되어야 하기 때문에 인코더-디코더 모델에는 덜 적용 가능합니다. 대신, 인코더-디코더 모델 매개변수의 하위 집합만 업데이트하는 두 가지 대체 미세 조정 접근 방식에 중점을 둡니다.
그림 6 : 원본 C4 데이터 세트와 4개의 인위적으로 잘린 버전에 대한 사전 훈련 손실입니다. 나열된 크기는 각 데이터 세트의 토큰 수를 나타냅니다. 고려된 네 가지 크기는 사전 훈련 과정에서 데이터 세트를 64~4,096회 반복하는 것에 해당합니다. 더 작은 데이터 세트 크기를 사용하면 훈련 손실 값이 더 작아지므로 레이블이 없는 데이터 세트를 어느 정도 기억할 수 있습니다.
첫 번째 "어댑터 레이어"(Houlsby et al., 2019; Bapna et al., 2019)는 미세 조정 중에 원래 모델의 대부분을 고정된 상태로 유지하려는 목표에 의해 동기가 부여되었습니다. 어댑터 계층은 Transformer의 각 블록에 있는 기존의 각 피드포워드 네트워크 뒤에 추가되는 추가적인 Dense-ReLU-dense 블록입니다. 이러한 새로운 피드포워드 네트워크는 출력 차원이 입력과 일치하도록 설계되었습니다. 이를 통해 구조나 매개변수를 추가로 변경하지 않고도 네트워크에 삽입할 수 있습니다. 미세 조정 시 어댑터 계층과 계층 정규화 매개변수만 업데이트됩니다. 이 접근 방식의 주요 초매개변수는 피드포워드 네트워크의 내부 차원 d이며, 이는 모델에 추가되는 새 매개변수의 수를 변경합니다. 우리는 d에 대해 다양한 값을 실험합니다.
우리가 고려하는 두 번째 대안 미세 조정 방법은 "점진적 동결 해제"입니다(Howard and Ruder, 2018). 점진적 동결 해제에서는 시간이 지남에 따라 점점 더 많은 모델 매개변수가 미세 조정됩니다. 점진적 동결 해제는 원래 단일 레이어 스택으로 구성된 언어 모델 아키텍처에 적용되었습니다. 이 설정에서는 미세 조정이 시작될 때 최종 레이어의 매개변수만 업데이트되고, 특정 수의 업데이트에 대한 학습 후에는 마지막에서 두 번째 레이어의 매개변수도 포함되는 식으로 전체 레이어가 업데이트될 때까지 계속됩니다. 네트워크의 매개변수가 미세 조정되고 있습니다. 이 접근 방식을 인코더-디코더 모델에 적용하기 위해 두 경우 모두 위에서부터 시작하여 인코더와 디코더의 레이어를 병렬로 점진적으로 고정 해제합니다. 입력 임베딩 행렬과 출력 분류 행렬의 매개변수는 공유되므로 미세 조정 과정에서 이를 업데이트합니다. 기본 모델은 인코더와 디코더에 각각 12개의 레이어로 구성되어 있으며 2^18 단계로 미세 조정되어 있습니다. 따라서 우리는 미세 조정 프로세스를 각각 2^18/12 단계의 12개 에피소드로 세분화하고 n번째 에피소드에서 레이어 12-n부터 12까지 학습합니다. Howard와 Ruder(2018)는 각 학습 에포크 후에 추가 레이어를 미세 조정할 것을 제안했습니다. 그러나 지도 데이터 세트의 크기가 매우 다양하고 다운스트림 작업 중 일부가 실제로 여러 작업(GLUE 및 SuperGLUE)의 혼합이기 때문에 대신 2^18/12 단계마다 추가 레이어를 미세 조정하는 더 간단한 전략을 채택합니다.
표 10 : 모델 매개변수의 하위 집합만 업데이트하는 다양한 대체 미세 조정 방법 비교. 어댑터 레이어의 경우 d는 어댑터의 내부 차원을 나타냅니다.
이러한 미세 조정 접근 방식의 성능 비교는 표 10에 나와 있습니다. 어댑터 레이어의 경우 내부 차원 d 32, 128, 512, 2048을 사용하여 성능을 보고합니다. 과거 결과에 따라(Houlsby et al., 2019 Bapna et al., 2019) SQuAD와 같은 저자원 작업은 작은 d 값으로 잘 작동하는 반면, 고차원 작업은 합리적인 성능을 달성하기 위해 큰 차원성이 필요하다는 것을 발견했습니다. 이는 차원이 작업 크기에 맞게 적절하게 조정되는 한 어댑터 레이어가 더 적은 매개변수로 미세 조정하는 유망한 기술이 될 수 있음을 시사합니다. 우리의 경우 구성 데이터 세트를 연결하여 GLUE와 SuperGLUE를 각각 단일 "작업"으로 처리합니다. 따라서 일부 저차원 데이터 세트로 구성되어 있지만 결합된 데이터 세트는 큰 d 값이 필요할 만큼 충분히 큽니다. 점진적인 동결 해제로 인해 모든 작업에서 성능이 약간 저하되지만 미세 조정 중에는 속도가 약간 향상되는 것으로 나타났습니다. 동결 해제 일정을 더 주의 깊게 조정하면 더 나은 결과를 얻을 수 있습니다.
3.5.2. 다중 작업 학습
지금까지 우리는 각 다운스트림 작업에서 개별적으로 미세 조정하기 전에 단일 비지도 학습 작업에 대해 모델을 사전 훈련했습니다. "다중 작업 학습"(Ruder, 2017; Caruana, 1997)이라는 대안적인 접근 방식은 한 번에 여러 작업에 대해 모델을 훈련하는 것입니다. 이 접근 방식의 목표는 일반적으로 한 번에 많은 작업을 동시에 수행할 수 있는 단일 모델을 교육하는 것입니다. 즉, 모델과 해당 매개변수의 대부분이 모든 작업에서 공유됩니다. 우리는 이 목표를 다소 완화하고 대신 각 개별 작업에서 잘 수행되는 별도의 매개변수 설정을 생성하기 위해 한 번에 여러 작업에 대한 교육 방법을 조사합니다. 예를 들어, 여러 작업에 대해 단일 모델을 훈련할 수 있지만 성능을 보고할 때 각 작업에 대해 서로 다른 체크포인트를 선택할 수 있습니다. 이는 다중 작업 학습 프레임워크를 느슨하게 하고 지금까지 고려한 사전 학습 후 미세 조정 접근 방식에 비해 더 공평한 기반을 마련합니다. 또한 통합된 텍스트-텍스트 프레임워크에서 "다중 작업 학습"은 단순히 데이터 세트를 함께 혼합하는 것에 해당합니다. 따라서 다중 작업 학습을 사용할 때 감독되지 않은 작업을 함께 혼합되는 작업 중 하나로 처리하여 레이블이 지정되지 않은 데이터를 훈련할 수 있습니다. 대조적으로, NLP에 대한 다중 작업 학습의 대부분의 적용은 작업별 분류 네트워크를 추가하거나 각 작업에 대해 서로 다른 손실 함수를 사용합니다(Liu et al., 2019b).
Arivazhagan et al. (2019). 이 지적한 바와 같이 다중 작업 학습에서 매우 중요한 요소는 모델이 훈련되어야 하는 각 작업의 데이터 양입니다. 우리의 목표는 모델을 과소 또는 과도하게 훈련하지 않는 것입니다. 즉, 모델이 주어진 작업에서 작업을 잘 수행할 수 있을 만큼 충분한 데이터를 볼 수 있기를 원하지만, 훈련 세트를 기억할 정도로 많은 데이터를 볼 수는 없습니다. 각 작업에서 나오는 데이터의 비율을 정확히 설정하는 방법은 데이터 세트 크기, 작업 학습의 "어려움"(즉, 작업을 효과적으로 수행하기 전에 모델이 알아야 하는 데이터의 양), 정규화 등 다양한 요소에 따라 달라질 수 있습니다. 추가적인 문제는 한 작업에서 좋은 성과를 달성하는 것이 다른 작업의 성과를 방해할 수 있는 "작업 간섭" 또는 "부정적 전환"의 가능성입니다. 이러한 우려를 고려하여 각 작업에서 나오는 데이터의 비율을 설정하기 위한 다양한 전략을 탐색하는 것부터 시작합니다. 비슷한 탐구가 Wang et al. (2019a). 에 의해 수행되었습니다.
예제 - 비례 혼합 모델이 주어진 작업에 얼마나 빨리 과적합되는지를 결정하는 주요 요인은 작업의 데이터 세트 크기입니다. 따라서 혼합 비율을 설정하는 자연스러운 방법은 각 작업의 데이터 세트 크기에 비례하여 샘플링하는 것입니다. 이는 모든 작업에 대한 데이터 세트를 연결하고 결합된 데이터 세트에서 무작위로 예제를 샘플링하는 것과 같습니다. 그러나 우리는 다른 모든 작업보다 훨씬 더 큰 데이터 세트를 사용하는 비지도 노이즈 제거 작업을 포함하고 있습니다. 따라서 각 데이터 세트의 크기에 비례하여 단순히 샘플링하면 모델이 보는 대부분의 데이터에 레이블이 지정되지 않으며 모든 지도 작업에 대한 훈련이 부족해집니다. 감독되지 않은 작업이 없더라도 일부 작업(예: WMT 영어에서 프랑스어로)은 너무 커서 대부분의 배치가 유사하게 밀려납니다. 이 문제를 해결하기 위해 비율을 계산하기 전에 데이터 세트 크기에 인위적인 "한계"를 설정했습니다. 구체적으로 N개의 작업 데이터 세트 각각에 있는 예시의 수가 en이면 n ∈ {1, . . . , N } 그런 다음 훈련 중에 m번째 작업에서 예제를 샘플링할 확률을 rm = min(e_m , K )/Σ min(e_n , K )로 설정합니다. 여기서 K는 인공 데이터 세트 크기 제한입니다.
온도 규모 혼합 데이터 세트 크기 간의 큰 차이를 완화하는 또 다른 방법은 혼합 속도의 "온도"를 조정하는 것입니다. 이 접근 방식은 모델이 저자원 언어에 대해 충분히 훈련되었는지 확인하기 위해 다국어 BERT에서 사용되었습니다. 온도 T로 온도 스케일링을 구현하기 위해 각 작업의 혼합 속도 rm을 1/T의 거듭제곱으로 높이고 속도를 다시 정규화하여 그 합은 1이 됩니다. T = 1일 때 이 접근 방식은 예제 비례 혼합과 동일하며 T가 증가함에 따라 비율은 동일한 혼합에 가까워집니다. 데이터 세트 크기 제한 K(온도 스케일링 이전에 rm을 얻기 위해 적용됨)를 유지하지만 이를 K = 2^21의 큰 값으로 설정합니다. 온도가 증가하면 가장 큰 데이터 세트의 혼합 속도가 감소하기 때문에 큰 K 값을 사용합니다.
표 11 : 다양한 혼합 전략을 사용한 다중 작업 훈련 비교. 예제-비례 혼합은 최대 데이터 세트 크기에 인위적인 제한(K)을 두고 각 데이터 세트의 전체 크기에 따라 각 데이터 세트에서 예제를 샘플링하는 것을 말합니다. 온도 스케일링 혼합은 샘플링 속도를 온도 T만큼 재조정합니다. 온도 규모 혼합의 경우 인공 데이터 세트 크기 제한 K = 2^21을 사용합니다.
균등 혼합 이 경우 각 작업의 예제를 동일한 확률로 샘플링합니다. 구체적으로, 각 배치의 각 예는 우리가 훈련하는 데이터 세트 중 하나에서 무작위로 균일하게 샘플링됩니다. 모델은 리소스가 적은 작업에서는 빠르게 과적합되고 리소스가 많은 작업에서는 부족해지기 때문에 이는 최적이 아닌 전략일 가능성이 높습니다. 우리는 비율이 차선으로 설정되면 무엇이 잘못될 수 있는지에 대한 참조 지점으로 주로 포함합니다.
이러한 혼합 전략을 기본 사전 학습 후 미세 조정 결과와 동일한 기반에서 비교하기 위해 동일한 총 단계 수
(2^19 + 2^18 = 786,432)에 대해 다중 작업 모델을 학습합니다. 결과를 표 11에 나타내었다. 일반적으로 다중 작업 훈련은 대부분의 작업에 대한 미세 조정이 뒤따르는 사전 훈련보다 성능이 떨어지는 것으로 나타났습니다. 특히 "동일" 혼합 전략은 성능이 크게 저하되는 결과를 가져옵니다. 이는 리소스가 낮은 작업이 과적합되었거나, 리소스가 많은 작업에서 충분한 데이터를 확인하지 못했거나, 모델이 일반 학습을 위한 레이블이 지정되지 않은 데이터를 충분히 확인하지 못했기 때문일 수 있습니다. 목적 언어 능력. 예제-비례 혼합의 경우, 대부분의 작업에서 모델이 최상의 성능을 얻는 K에 대한 "최적 지점"이 있고 K 값이 크거나 작을수록 성능이 저하되는 경향이 있음을 발견했습니다. (우리가 고려한 K 값의 범위에 대한) 예외는 WMT 영어에서 프랑스어로의 번역이었습니다. 이는 자원이 많이 필요한 작업이므로 혼합 비율이 높을수록 항상 이점이 있습니다. 마지막으로, 온도 규모 혼합은 대부분의 경우 T = 2가 가장 좋은 성능을 발휘하면서 대부분의 작업에서 합리적인 성능을 얻을 수 있는 수단을 제공합니다. 다중 작업 모델이 각 개별 작업에 대해 훈련된 별도의 모델에 의해 성능이 우수하다는 사실은 이전에 관찰되었습니다. Arivazhagan 외. (2019) 및 McCann et al. (2018), 다중 작업 설정은 Liu et al. (2019b); 과 매우 유사한 작업 전반에 걸쳐 이점을 제공할 수 있는 것으로 나타났습니다. Ratneret al. (2018). 다음 섹션에서는 다중 작업 훈련과 사전 훈련 후 미세 조정 접근 방식 사이의 격차를 줄이는 방법을 살펴봅니다.
표 12 : 비지도 사전 훈련, 다중 작업 학습 및 다양한 형태의 다중 작업 사전 훈련 비교.
3.5.3. 다중 작업 학습과 미세 조정 결합
우리는 여러 작업이 혼합된 단일 모델을 훈련하지만 모델에 대해 다양한 매개변수 설정 체크포인트를 사용하여 성능을 평가할 수 있는 완화된 버전의 다중 작업 학습을 연구하고 있다는 점을 기억하세요. 모델이 모든 작업에 대해 동시에 사전 훈련된 다음 개별 감독 작업에 대해 미세 조정되는 경우를 고려하여 이 접근 방식을 확장할 수 있습니다. 이는 도입 당시 GLUE 등 벤치마크에서 최고 수준의 성능을 달성한 'MT-DNN'(Liu et al., 2015, 2019b)에서 사용하는 방식이다. 우리는 이 접근법의 세 가지 변형을 고려합니다. 먼저, 각 개별 다운스트림 작업에서 모델을 미세 조정하기 전에 인공 데이터 세트 크기 제한 K = 2^19를 사용하여 예제-비례 혼합에 대해 모델을 사전 훈련합니다. 이는 사전 훈련 중에 감독되지 않은 목표와 함께 감독된 작업을 포함하면 모델이 다운스트림 작업에 대한 유익한 조기 노출을 제공하는지 여부를 측정하는 데 도움이 됩니다. 또한 다양한 감독 소스를 혼합하면 사전 훈련된 모델이 개별 작업에 적용되기 전에 보다 일반적인 "기술" 세트(느슨하게 말하면)를 획득하는 데 도움이 될 수 있기를 바랄 수도 있습니다. 이를 직접 측정하기 위해 이 사전 훈련 혼합물에서 다운스트림 작업 중 하나를 생략한다는 점을 제외하고 동일한 예제-비례 혼합(K = 2^19)에서 모델을 사전 훈련하는 두 번째 변형을 고려합니다. 그런 다음 사전 훈련 중에 제외된 작업에 대해 모델을 미세 조정합니다. 우리가 고려하는 각 다운스트림 작업에 대해 이를 반복합니다.
우리는 이러한 접근 방식을 "leave-one-out" 다중 작업 훈련이라고 부릅니다. 이는 사전 훈련된 모델이 사전 훈련 중에 보지 못한 작업에 대해 미세 조정되는 실제 설정을 시뮬레이션합니다. 다중 작업 사전 훈련은 감독된 작업의 다양한 혼합을 제공합니다. 다른 분야(예: 컴퓨터 비전(Oquab et al., 2014; Jia et al., 2014; Huh et al., 2016; Yosinski et al., 2014))에서는 사전 훈련을 위해 지도 데이터 세트를 사용하므로 우리는 관심이 있었습니다. 다중 작업 사전 훈련 혼합에서 감독되지 않은 작업을 생략해도 여전히 좋은 결과가 나오는지 확인합니다. 따라서 세 번째 변형의 경우 K = 2^19로 고려하는 모든 감독 작업의 예시-비례 혼합에 대해 사전 훈련합니다. 이러한 모든 변형에서 우리는 2^18 단계에 대한 미세 조정 전에 2^19 단계에 대한 사전 학습의 표준 절차를 따릅니다.
표 12에서 이러한 접근 방식의 결과를 비교합니다. 비교를 위해 예제-비례 혼합에 대한 기준(사전 학습 후 미세 조정) 및 표준 다중 작업 학습(미세 조정 없음)에 대한 결과도 포함합니다. K = 2^19 . 다중 작업 사전 훈련 후 미세 조정을 수행하면 기준과 비슷한 성능을 얻을 수 있음을 발견했습니다. 이는 다중 작업 학습 후 미세 조정을 사용하면 섹션 3.5.2에 설명된 다양한 혼합 속도 간의 일부 균형을 완화하는 데 도움이 될 수 있음을 시사합니다. 흥미롭게도 "leave-one-out" 훈련의 성능은 약간 더 나빴습니다. 이는 다양한 작업에 대해 훈련된 모델이 여전히 새로운 작업에 적응할 수 있음을 시사합니다(즉, 다중 작업 사전 훈련은 극적인 결과를 가져오지 못할 수 있음). 작업 간섭). 마지막으로 감독된 다중 작업 사전 훈련은 번역 작업을 제외한 모든 경우에 훨씬 더 나쁜 성능을 보였습니다. 이는 번역 작업이 (영어) 사전 훈련의 이점이 적은 반면 감독되지 않은 사전 훈련은 다른 작업에서 중요한 요소임을 시사할 수 있습니다.
3.6. 스케일링
기계 학습 연구의 "씁쓸한 교훈"은 추가 계산을 활용할 수 있는 일반적인 방법이 궁극적으로 인간의 전문 지식에 의존하는 방법에 비해 승리한다고 주장합니다(Sutton, 2019; Hestness et al., 2017; Shazeer et al., 2017; Jozefowicz et al. ., 2016; Mahajan 등, 2018; Shazeer 등, 2018, 2017; Huang 등, 2018b; Keskar 등, 2019a). 최근 결과는 이것이 NLP의 전이 학습에 적용될 수 있음을 시사합니다(Liu et al., 2019c; Radford et al., 2019; Yang et al., 2019; Lan et al., 2019). 즉, 다음과 같이 반복적으로 나타났습니다. 확장하면 보다 신중하게 설계된 방법에 비해 성능이 향상됩니다. 그러나 더 큰 모델 사용, 더 많은 단계에 대한 모델 학습, 앙상블 등 다양한 확장 방법이 있습니다. 이 섹션에서는 다음 전제를 다루면서 이러한 다양한 접근 방식을 비교합니다. “방금 4배 더 많은 컴퓨팅이 제공되었습니다. 어떻게 사용해야 할까요?” 우리는 220M 매개변수를 갖고 각각 2^19단계와 2^18단계에 대해 사전 훈련 및 미세 조정된 기준 모델로 시작합니다. 인코더와 디코더는 모두 "BERTBASE"와 비슷한 크기입니다. 증가된 모델 크기를 실험하기 위해 "BERTLARGE" Devlin et al. (2018) 의 지침을 따릅니다. dff = 4096, dmodel = 1024, dkv = 64 및 16-헤드 주의 메커니즘을 사용합니다. 그런 다음 인코더와 디코더에서 각각 16개 및 32개 레이어로 구성된 두 가지 변형을 생성하여 원래 모델보다 2배 및 4배 많은 매개변수를 가진 모델을 생성합니다. 이 두 변형은 계산 비용도 대략 2배와 4배입니다. 기준선과 이 두 개의 더 큰 모델을 사용하여 4배 많은 계산을 사용하는 세 가지 방법을 고려합니다. 즉, 4배 더 많은 단계에 대한 학습, 2배 더 큰 모델로 2배 더 많은 단계에 대한 학습, 4배 더 큰 모델 학습입니다. 훈련 단계의 "기준" 수에 대해. 훈련 단계를 늘릴 때 단순화를 위해 사전 훈련 단계와 미세 조정 단계를 모두 확장합니다. 사전 훈련 단계 수를 늘리면 C4가 너무 커서 2^23단계를 훈련할 때에도 데이터에 대한 한 번의 전달을 완료하지 못하므로 더 많은 사전 훈련 데이터를 효과적으로 포함하게 됩니다.
모델이 4배 많은 데이터를 볼 수 있는 또 다른 방법은 배치 크기를 4배로 늘리는 것입니다. 이렇게 하면 더 효율적인 병렬화로 인해 잠재적으로 더 빠른 훈련이 가능해질 수 있습니다. 그러나 4배 더 큰 배치 크기를 사용한 교육은 4배 많은 단계에 대한 교육과 다른 결과를 얻을 수 있습니다(Shallue et al., 2018). 우리는 이 두 가지 사례를 비교하기 위해 4배 더 큰 배치 크기로 기본 모델을 훈련하는 추가 실험을 포함합니다. 우리가 고려하는 많은 벤치마크에서는 모델 앙상블을 사용하여 훈련하고 평가하여 추가 성능을 끌어내는 것이 일반적인 관행입니다. 이는 추가 계산을 사용하는 직교 방법을 제공합니다. 다른 스케일링 방법과 앙상블을 비교하기 위해 별도로 사전 훈련되고 미세 조정된 4개 모델의 앙상블 성능도 측정합니다. 우리는 총체적인 예측을 얻기 위해 출력 소프트맥스 비선형성에 로짓을 공급하기 전에 앙상블 전체의 로짓을 평균화합니다. 4개의 개별 모델을 사전 훈련하는 대신, 사전 훈련된 단일 모델을 사용하여 4개의 별도의 미세 조정 버전을 생성하는 것이 더 저렴한 대안입니다. 이는 전체 4배 계산 예산을 사용하지 않지만 이 방법을 포함하여 다른 확장 방법에 비해 경쟁력 있는 성능을 제공하는지 확인합니다.
표 13 : 기본 모델을 확장하는 다양한 방법 비교. 미세 조정 모델 앙상블을 제외한 모든 방법은 4배의 계산을 기준으로 사용합니다. "크기"는 모델의 매개변수 수를 나타내고 "훈련 시간"은 사전 훈련과 미세 조정에 사용되는 단계 수를 나타냅니다.
이러한 다양한 스케일링 방법을 적용한 후 달성된 성능은 표 13에 나와 있습니다. 당연히 훈련 시간 및/또는 모델 크기를 늘리면 기준선이 지속적으로 향상됩니다. 4배 많은 단계에 대한 훈련과 4배 더 큰 배치 크기를 사용하는 것 사이에는 확실한 승자가 없었지만 둘 다 유익했습니다. 일반적으로 모델 크기를 늘리면 훈련 시간이나 배치 크기만 늘리는 것에 비해 성능이 추가로 향상됩니다. 우리가 연구한 작업에서 2배 더 큰 모델을 2배 더 오랫동안 훈련하는 것과 4배 더 큰 모델을 훈련하는 것 사이에는 큰 차이가 관찰되지 않았습니다. 이는 훈련 시간을 늘리고 모델 크기를 늘리는 것이 성능 향상을 위한 보완적인 수단이 될 수 있음을 시사합니다. 우리의 결과는 또한 앙상블이 규모를 통해 성능을 향상시키는 직교적이고 효과적인 수단을 제공한다는 것을 시사합니다. 일부 작업(CNN/DM, WMT 영어-독일어, WMT 영어-루마니아어)에서는 완전히 개별적으로 훈련된 4개의 모델을 앙상블하는 것이 다른 모든 확장 접근 방식보다 훨씬 뛰어난 성능을 보였습니다. 함께 사전 훈련되었지만 개별적으로 미세 조정된 앙상블 모델도 기준선에 비해 상당한 성능 향상을 제공했으며 이는 성능을 향상시키는 더 저렴한 방법을 제안합니다. 유일한 예외는 SuperGLUE였는데, 두 가지 앙상블 접근 방식 모두 기준선에 비해 크게 개선되지 않았습니다. 다양한 확장 방법에는 성능과 별개로 서로 다른 절충안이 있다는 점에 유의하세요. 예를 들어 더 큰 모델을 사용하면 다운스트림 미세 조정 및 추론 비용이 더 높아질 수 있습니다. 대조적으로, 소규모 모델을 더 오랫동안 사전 훈련하는 비용은 많은 다운스트림 작업에 적용되면 효과적으로 상각됩니다. 이와 별도로, N개의 개별 모델을 앙상블하는 것은 N × 더 높은 계산 비용을 갖는 모델을 사용하는 것과 비슷한 비용을 갖는다는 점에 주목합니다. 결과적으로, 확장 방법 중에서 선택할 때 모델의 최종 사용에 대한 몇 가지 고려 사항이 중요합니다.
3.7. 함께 모아서
이제 우리는 체계적인 연구에서 얻은 통찰력을 활용하여 인기 있는 NLP 벤치마크에서 성능을 얼마나 향상시킬 수 있는지 결정합니다. 우리는 또한 대량의 데이터에 대해 더 큰 모델을 훈련함으로써 NLP에 대한 전이 학습의 현재 한계를 탐색하는 데 관심이 있습니다. 기본 교육 접근 방식부터 시작하여 다음과 같이 변경합니다.
목표 i.i.d를 교체합니다. SpanBERT(Joshi et al., 2019)에서 느슨하게 영감을 받은 섹션 3.3.4에 설명된 범위 손상 목표에 대한 기준선의 노이즈 제거 목표입니다. 구체적으로 우리는 평균 범위 길이 3을 사용하고 원본 시퀀스의 15%를 손상시켰습니다. 우리는 이 목표가 더 짧은 목표 시퀀스 길이로 인해 약간 더 계산적으로 효율적이면서 약간 더 나은 성능을 생성한다는 것을 발견했습니다(표 7).
더 긴 훈련 우리의 기준 모델은 상대적으로 적은 양의 사전 훈련을 사용합니다(BERT 의 1/4(Devlin et al., 2018), XLNet(Yang et al., 2019)의 1/16, 1/64) RoBERTa(Liu et al., 2019c) 등)만큼. 다행스럽게도 C4는 데이터 반복 없이 상당히 오랫동안 훈련할 수 있을 만큼 충분히 큽니다(섹션 3.4.2에서 볼 수 있듯이 해로울 수 있음). 우리는 섹션 3.6에서 추가 사전 훈련이 실제로 도움이 될 수 있으며 배치 크기를 늘리고 훈련 단계 수를 늘리는 것이 이러한 이점을 제공할 수 있음을 발견했습니다. 따라서 우리는 길이가 512인 211개 시퀀스의 배치 크기에서 100만 단계에 대해 모델을 사전 훈련합니다. 이는 총 약 1조 개의 사전 훈련 토큰(기준의 약 32배)에 해당합니다. 섹션 3.4.1에서 우리는 RealNews와 유사한 WebText와 Wikipedia + TBC 데이터 세트에 대한 사전 훈련이 몇 가지 다운스트림 작업에서 C4에 대한 사전 훈련보다 성능이 우수하다는 것을 보여주었습니다. 그러나 이러한 데이터 세트 변형은 1조 개의 토큰에 대한 사전 훈련 과정에서 수백 번 반복될 만큼 충분히 작습니다. 섹션 3.4.2에서 이러한 반복이 해로울 수 있음을 보여주었기 때문에 대신 C4 데이터 세트를 계속 사용하기로 결정했습니다.
모델 크기 섹션 3.6에서는 기본 모델 크기를 확장하면 성능이 어떻게 향상되는지 보여주었습니다. 그러나 미세 조정이나 추론에 사용할 수 있는 계산 리소스가 제한된 환경에서는 더 작은 모델을 사용하는 것이 도움이 될 수 있습니다. 이러한 요소를 기반으로 우리는 다양한 크기의 모델을 교육합니다.
• 베이스. 이는 섹션 3.1.1에 하이퍼파라미터가 설명된 기본 모델입니다. 대략 2억 2천만 개의 매개변수가 있습니다. • 작은. 우리는 dmodel = 512, dff = 2,048, 8-headed attention, 인코더와 디코더 각각에 6개의 레이어만 사용하여 기준선을 축소하는 더 작은 모델을 고려합니다. 이 변형에는 약 6천만 개의 매개변수가 있습니다. • 크기가 큰. 우리의 기준선은 BERTBASE 크기의 인코더와 디코더를 사용하므로 인코더와 디코더의 크기와 구조가 모두 BERTLARGE와 유사한 변형도 고려합니다. 구체적으로 이 변형은 dmodel = 1,024, dff = 4,096, dkv = 64, 16-headed attention, 인코더와 디코더 각각의 24개 레이어를 사용하여 약 7억 7천만 개의 매개변수를 생성합니다. • 3B 및 11B. 어떤 종류의 성능이 가능한지 더 자세히 알아보기 위해 더 큰 모델을 사용하여 두 가지 추가 변형을 고려합니다. 두 경우 모두 dmodel = 1024, 24 레이어 인코더 및 디코더, dkv = 128을 사용합니다. "3B" 변형의 경우 dff = 16,384를 32개 방향 주의로 사용하여 약 28억 개의 매개변수를 생성합니다. "11B"의 경우 dff = 65,536을 사용하고 128개 방향의 Attention을 사용하여 약 110억 개의 매개변수가 있는 모델을 생성합니다. 우리는 특히 현대 가속기(예: 모델을 훈련하는 TPU)가 Transformer의 피드포워드 네트워크와 같은 대규모 조밀 행렬 곱셈에 가장 효율적이기 때문에 dff를 확장하기로 결정했습니다.
다중 작업 사전 훈련 섹션 3.5.3에서 우리는 미세 조정 전에 감독되지 않은 작업과 감독된 작업이 혼합된 다중 작업에 대한 사전 훈련과 감독되지 않은 작업에 대한 사전 훈련이 효과적이라는 것을 보여주었습니다. 이것이 "MT-DNN"(Liu et al., 2015, 2019b)이 옹호하는 접근 방식입니다. 또한 단지 미세 조정이 아닌 전체 교육 기간 동안 "다운스트림" 성능을 모니터링할 수 있다는 실질적인 이점도 있습니다. 따라서 우리는 최종 실험 세트에서 다중 작업 사전 훈련을 사용했습니다. 우리는 더 오랫동안 훈련된 더 큰 모델이 더 작은 훈련 데이터 세트에 과적합될 가능성이 높기 때문에 레이블이 지정되지 않은 더 많은 비율의 데이터로부터 이익을 얻을 수 있다고 가정합니다. 그러나 섹션 3.5.3의 결과는 다중 작업 사전 훈련 후 미세 조정을 통해 레이블이 지정되지 않은 데이터의 최적이 아닌 비율을 선택함으로써 발생할 수 있는 일부 문제를 완화할 수 있음을 시사합니다. 이러한 아이디어를 기반으로 표준 예제-비례 혼합(섹션 3.5.2에 설명됨)을 사용하기 전에 레이블이 없는 데이터를 다음과 같은 인공 데이터 세트 크기로 대체합니다. 소형의 경우 710,000, 기본의 경우 2,620,000, 대형의 경우 8,660,000, 3B의 경우 33,500,000, 11B의 경우 133,000,000입니다. 모든 모델 변형에 대해 사전 훈련 중에 WMT 영어-프랑스어 및 WMT 영어-독일어 데이터 세트의 유효 데이터 세트 크기를 100만 개 예시로 제한했습니다.
개별 GLUE 및 SuperGLUE 작업 미세 조정 지금까지 GLUE 및 SuperGLUE를 미세 조정할 때 GLUE에 대해 한 번, SuperGLUE에 대해 한 번만 모델을 미세 조정하도록 각 벤치마크의 모든 데이터 세트를 연결했습니다. 이 접근 방식은 우리의 연구를 논리적으로 더 단순하게 만들지만, 개별적으로 작업을 미세 조정하는 것과 비교하여 일부 작업에서는 성능이 약간 희생된다는 것을 발견했습니다. 개별 작업을 미세 조정할 때 발생하는 잠재적인 문제(한 번에 모든 작업에 대한 교육을 통해 완화될 수 있음)는 리소스가 적은 작업에 빠르게 과적합할 수 있다는 것입니다. 예를 들어, 길이 211개, 시퀀스 512개의 대규모 배치 크기로 인해 리소스가 적은 GLUE 및 SuperGLUE 작업 중 다수에 대해 각 배치에서 전체 데이터 세트가 여러 번 표시됩니다. 따라서 우리는 각 GLUE 및 SuperGLUE 작업에 대한 미세 조정 중에 8개 길이-512 시퀀스의 더 작은 배치 크기를 사용합니다. 또한 모델이 과적합되기 전에 모델 매개변수에 액세스할 수 있도록 5,000단계가 아닌 1,000단계마다 체크포인트를 저장합니다.
빔 검색 이전 결과는 모두 그리디 디코딩을 사용하여 보고되었습니다. 출력 시퀀스가 긴 작업의 경우 빔 검색을 사용하면 성능이 향상되는 것으로 나타났습니다(Sutskever et al., 2014). 특히 WMT 변환 및 CNN/DM 요약 작업에 빔 폭 4와 길이 페널티 α = 0.6(Wu et al., 2016)을 사용합니다.
테스트 세트 이것이 최종 실험 세트이므로 검증 세트가 아닌 테스트 세트에 대한 결과를 보고합니다. CNN/Daily Mail의 경우 데이터 세트와 함께 배포된 표준 테스트 세트를 사용합니다. WMT 작업의 경우 이는 영어-독일어의 경우 newstest2014, 영어-프랑스어의 경우 newstest2015, 영어-루마니아어의 경우 newstest2016을 사용하는 것에 해당합니다. GLUE 및 SuperGLUE의 경우 벤치마크 평가 서버를 사용하여공식 테스트 세트 점수 계산. 15, 16 SQuAD의 경우 테스트 세트를 평가하려면 벤치마크 서버에서 추론을 실행해야 합니다. 불행하게도 이 서버의 계산 리소스는 가장 큰 모델에서 예측을 얻기에는 부족합니다. 결과적으로 우리는 대신 SQuAD 검증 세트에 대한 성능을 계속 보고합니다. 다행스럽게도 SQuAD 테스트 세트에서 가장 높은 성능을 보인 모델이 검증 세트에서도 결과를 보고했기 때문에 여전히 표면적으로는 최첨단과 비교할 수 있습니다.
위에서 언급한 변경 사항 외에도 우리는 기준과 동일한 훈련 절차와 하이퍼파라미터(AdaFactor 최적화 프로그램, 사전 훈련을 위한 역제곱근 학습 속도 일정, 미세 조정을 위한 일정한 학습 속도, 드롭아웃 정규화, 어휘 등)를 사용합니다. 참고로 이러한 세부 사항은 섹션 2에 설명되어 있습니다. 이 최종 실험 세트의 결과는 표 14에 나와 있습니다. 전반적으로 우리는 고려한 24개 작업 중 18개 작업에서 최첨단 성능을 달성했습니다. 예상대로 우리의 가장 큰(110억 매개변수) 모델은 모든 작업에 걸쳐 모델 크기 변형 중에서 가장 좋은 성능을 보였습니다.
우리의 T5-3B 모델 변형은 몇 가지 작업에서 이전 기술 수준을 능가했지만, 모델 크기를 110억 개의 매개변수로 확장하는 것이 최고의 성능을 달성하는 데 가장 중요한 요소였습니다. 이제 각 개별 벤치마크에 대한 결과를 분석합니다. 우리는 최첨단 평균 GLUE 점수 90.3을 달성했습니다. 특히, 자연어 추론 작업 MNLI, RTE 및 WNLI에 대한 성능은 이전 최첨단 기술보다 훨씬 향상되었습니다. RTE와 WNLI는 기계 성능이 역사적으로 각각 93.6과 95.9인 인간 성능보다 뒤처진 두 가지 작업입니다(Wang et al., 2018). 매개변수 수 측면에서 볼 때 11B 모델 변형은 GLUE 벤치마크에 제출된 모델 중 가장 큰 모델입니다. 그러나 가장 높은 점수를 받은 제출물은 대부분 예측을 생성하기 위해 많은 양의 앙상블 및 계산을 사용합니다. 예를 들어, ALBERT의 최고 성능 변형(Lan et al., 2019)은 3B 변형과 크기 및 아키텍처가 유사한 모델을 사용합니다(영리한 매개변수 공유로 인해 매개변수가 극적으로 적음). GLUE에서 인상적인 성능을 생성하기 위해 ALBERT 작성자는 작업에 따라 "6~17" 모델을 앙상블했습니다. 이로 인해 T5-11B보다 ALBERT 앙상블을 사용하여 예측을 생성하는 데 계산 비용이 더 많이 들 수 있습니다.
SQuAD의 경우 Exact Match 점수에서 이전 최첨단 기술(ALBERT(Lan et al., 2019))을 1점 이상 능가했습니다. SQuAD는 3년 전에 만들어진 오랜 벤치마크이며, 가장 최근의 개선으로 인해 최첨단 기술이 몇 퍼센트 포인트만 향상되었을 뿐입니다. 테스트 세트에 대한 결과가 보고될 때 일반적으로 모델 앙상블을 기반으로 하거나 외부 데이터 세트를 활용합니다(예: TriviaQA(Joshi et al., 2017) 또는 NewsQA(Trischler et al., 2016)) 작은 SQuAD 훈련 세트를 보강합니다. SQuAD의 인간 성능은 Exact Match 및 F1 측정 항목에 대해 각각 82.30 및 91.22로 추정되므로(Rajpurkar et al., 2016), 이 벤치마크의 추가 개선이 의미가 있는지는 확실하지 않습니다.
표 14 : 우리가 연구하는 모든 작업에 대한 T5 변형의 성능. 소형, 기본, 대형, 3B 및 11B는 각각 6천만, 2억 2천만, 7억 7천만, 30억 및 110억 개의 매개변수를 갖는 모델 구성을 나타냅니다. 각 표의 첫 번째 행에는 작업에 대한 최신 기술(2019년 10월 24일 기준)이 보고되어 있으며 위 첨자는 이 캡션 끝에 나열된 참고 자료와 소스를 나타냅니다. 검증 세트를 사용하는 SQuAD를 제외한 모든 결과는 테스트 세트에 보고됩니다. a(Lan 등, 2019) b(Wang 등, 2019c) c(Zhu 등, 2019) d(Liu 등, 2019c) e(Edunov 등, 2018) f(Lample 및 Conneau , 2019) g (동 외, 2019)
SuperGLUE의 경우 평균 점수 84.6(Liu et al., 2019c)에서 88.9로 큰 차이로 최첨단 기술을 개선했습니다. SuperGLUE는 "현재 최첨단 시스템의 범위를 벗어나지만 대부분의 대학 교육을 받은 영어 사용자가 해결할 수 있는" 작업을 포함하도록 설계되었습니다(Wang et al., 2019b). 우리는 인간의 성능 89.8과 거의 일치합니다(Wang et al., 2019b). 흥미롭게도 독해 작업(MultiRC 및 ReCoRD)에서 우리는 인간의 성능을 크게 능가하며 이러한 작업에 사용되는 평가 지표가 기계가 만든 예측에 편향될 수 있음을 시사합니다. 반면 인간은 COPA와 WSC 모두에서 100% 정확도를 달성했는데, 이는 우리 모델의 성능보다 훨씬 더 좋습니다. 이는 특히 자원이 부족한 환경에서 우리 모델이 완벽하게 하기 어려운 언어 작업이 남아 있음을 시사합니다.
우리는 WMT 번역 작업에서 최고의 성능을 달성하지 못했습니다. 이는 부분적으로 영어로만 레이블이 지정되지 않은 데이터 세트를 사용했기 때문일 수 있습니다. 또한 이러한 작업에 대한 최상의 결과 대부분은 정교한 데이터 확대 체계인 역번역(Edunov et al., 2018; Lample and Conneau, 2019)을 사용한다는 점에 주목합니다. 자원이 적은 영어-루마니아어 벤치마크의 최신 기술에서는 추가 형태의 교차 언어 비지도 학습도 사용합니다(Lample and Conneau, 2019). 우리의 결과는 규모와 영어 사전 훈련이 이러한 보다 정교한 방법의 성능을 맞추기에는 부족할 수 있음을 시사합니다. 좀 더 구체적으로 말하자면, 영어-독일어 newstest2014 세트에서 가장 좋은 결과는 WMT 2018(Edunov et al., 2018)의 훨씬 더 큰 훈련 세트를 사용하므로 결과와 직접 비교하기가 어렵습니다.
마지막으로 CNN/Daily Mail에서는 ROUGE-2-F 점수에서 상당한 수준에 불과했지만 최첨단 성능을 얻었습니다. ROUGE 점수의 개선이 반드시 더 일관된 요약과 일치하는 것은 아닌 것으로 나타났습니다(Paulus et al., 2017). 또한 CNN/Daily Mail은 추상적인 요약 벤치마크로 제시되지만 순수 추출적인 접근 방식이 잘 작동하는 것으로 나타났습니다(Liu, 2019). 또한 최대 가능성으로 훈련된 생성 모델은 반복적인 요약을 생성하는 경향이 있다는 주장도 있었습니다(See et al., 2017). 이러한 잠재적인 문제에도 불구하고 우리는 우리 모델이 일관되고 대체로 정확한 요약을 생성한다는 것을 발견했습니다. 부록 C에서는 체리가 선택되지 않은 검증 세트의 예를 제공합니다.
강력한 결과를 얻기 위해 T5는 실험 연구에서 얻은 통찰력을 전례 없는 규모와 결합합니다. 섹션 3.6에서 우리는 기본 모델의 사전 훈련 양이나 크기를 확장하면 상당한 이득을 얻을 수 있다는 것을 발견했습니다. 이를 고려하여 우리는 T5에 도입한 "비확장" 변경 사항이 T5의 강력한 성능에 얼마나 기여했는지 측정하는 데 관심이 있었습니다. 따라서 우리는 다음 세 가지 구성을 비교하는 최종 실험을 수행했습니다. 첫째, 2^35 ≒ 34B 토큰에 대해 사전 훈련된 표준 기준 모델입니다. 둘째, 기준선은 약 1조 개의 토큰(즉, T5에 사용된 것과 동일한 양의 사전 훈련)에 대해 훈련되었으며, 이를 "기준-1T"라고 합니다. 셋째, T5-Base입니다. 기준선-1T와 T5-Base 간의 차이점은 T5를 설계할 때 적용한 "비스케일링" 변경 사항으로 구성됩니다. 따라서 이 두 모델의 성능을 비교하면 체계적인 연구에서 얻은 통찰력의 영향을 구체적으로 측정할 수 있습니다.
이 세 가지 모델 구성의 성능은 표 15에 나와 있습니다. 섹션 3.6의 결과와 일치하여 추가 사전 훈련이 기준에 비해 성능을 향상시키는 것으로 나타났습니다. 그럼에도 불구하고 T5-Base는 모든 다운스트림 작업에서 기준선-1T보다 훨씬 뛰어난 성능을 발휘합니다. 이는 규모만이 T5의 성공에 기여하는 유일한 요소가 아님을 시사합니다. 우리는 더 큰 모델이 증가된 크기뿐만 아니라 이러한 비척도적 요인으로부터도 이익을 얻는다고 가정합니다.
표 15 : T5-Base의 성능을 논문의 나머지 부분에 사용된 기본 실험 설정과 비교합니다. 결과는 검증 세트에 대해 보고됩니다. "Baseline-1T"는 2^35 ≒ 34B 토큰(기준에 사용된 것과 동일) 대신 1조 토큰(T5 모델 변형에 사용된 것과 동일한 수)에서 기준 모델을 사전 훈련하여 달성한 성능을 나타냅니다.
4. 고찰
체계적인 연구를 마친 후 가장 중요한 발견 중 일부를 요약하여 마무리합니다. 우리의 결과는 어느 정도 유망한 연구 방법에 대한 높은 수준의 관점을 제공합니다. 결론적으로, 우리는 이 분야를 더욱 발전시키기 위한 효과적인 접근 방식을 제공할 수 있다고 생각되는 몇 가지 주제에 대해 간략히 설명합니다.
4.1. 핵심사항
텍스트-텍스트 우리의 텍스트-텍스트 프레임워크는 동일한 손실 함수 및 디코딩 절차를 사용하여 다양한 텍스트 작업에 대한 단일 모델을 교육하는 간단한 방법을 제공합니다. 우리는 이 접근 방식이 추상 요약과 같은 생성 작업, 자연어 추론과 같은 분류 작업, STS-B와 같은 회귀 작업에 어떻게 성공적으로 적용될 수 있는지 보여주었습니다. 단순함에도 불구하고 텍스트-텍스트 프레임워크는 작업별 아키텍처와 비슷한 성능을 얻었으며 궁극적으로 규모와 결합 시 최첨단 결과를 생성했습니다.
아키텍처 NLP를 위한 전이 학습에 대한 일부 작업에서는 Transformer의 아키텍처 변형을 고려했지만 원래 인코더-디코더 형식이 텍스트-텍스트 프레임워크에서 가장 잘 작동한다는 것을 발견했습니다. 인코더-디코더 모델은 "인코더 전용"(예: BERT) 또는 "디코더 전용"(언어 모델) 아키텍처보다 두 배 더 많은 매개변수를 사용하지만 계산 비용은 비슷합니다. 또한 인코더와 디코더에서 매개변수를 공유해도 전체 매개변수 수를 절반으로 줄이면서 성능이 크게 떨어지지 않는다는 것을 보여주었습니다.
지원되지 않는 목표 전반적으로 우리는 무작위로 손상된 텍스트를 재구성하도록 모델을 훈련시키는 대부분의 "노이즈 제거" 목표가 텍스트-텍스트 설정에서 유사하게 수행된다는 것을 발견했습니다. 결과적으로, 감독되지 않은 사전 훈련이 계산적으로 더 효율적이도록 짧은 목표 시퀀스를 생성하는 목표를 사용하는 것이 좋습니다.
데이터 세트 우리는 Common Crawl 웹 덤프에서 경험적으로 정리된 텍스트로 구성된 "Colossal Clean Crawled Corpus"(C4)를 도입했습니다. 추가 필터링을 사용하는 데이터 세트와 C4를 비교할 때 도메인 내 레이블이 없는 데이터에 대한 교육이 몇 가지 다운스트림 작업의 성능을 향상시킬 수 있다는 것을 발견했습니다. 그러나 단일 도메인으로 제한하면 일반적으로 데이터 세트가 더 작아집니다. 우리는 레이블이 지정되지 않은 데이터 세트가 사전 훈련 과정에서 여러 번 반복될 만큼 작은 경우 성능이 저하될 수 있음을 별도로 보여주었습니다. 이는 일반적인 언어 이해 작업을 위해 C4와 같은 크고 다양한 데이터 세트를 사용하도록 동기를 부여합니다.
훈련 전략 우리는 미세 조정 중에 사전 훈련된 모델의 모든 매개변수를 업데이트하는 기본 접근 방식이 모든 매개변수를 업데이트하는 데 가장 비용이 많이 들지만 더 적은 수의 매개변수를 업데이트하도록 설계된 방법보다 성능이 우수하다는 것을 발견했습니다. 또한 한 번에 여러 작업에 대해 모델을 훈련하기 위한 다양한 접근 방식을 실험했습니다. 이는 텍스트 대 텍스트 설정에서 단순히 배치를 구성할 때 서로 다른 데이터 세트의 예제를 혼합하는 것에 해당합니다. 다중 작업 학습의 주요 관심사는 훈련할 각 작업의 비율을 설정하는 것입니다. 우리는 궁극적으로 감독되지 않은 사전 훈련과 감독된 미세 조정의 기본 접근 방식의 성능과 일치하는 혼합 비율을 설정하기 위한 전략을 찾지 못했습니다. 그러나 우리는 혼합 작업에 대한 사전 훈련 후 미세 조정이 감독되지 않은 사전 훈련과 비슷한 성능을 제공한다는 것을 발견했습니다.
확장 더 많은 데이터에 대한 모델 훈련, 더 큰 모델 훈련, 모델 앙상블 사용을 포함하여 추가 컴퓨팅을 활용하기 위한 다양한 전략을 비교했습니다. 더 많은 데이터로 더 작은 모델을 훈련하는 것이 더 적은 단계로 더 큰 모델을 훈련하는 것보다 성능이 더 좋은 경우가 많았음에도 불구하고 우리는 각 접근 방식이 성능을 크게 향상시키는 것을 발견했습니다. 또한 모델 앙상블이 추가 계산을 활용하는 직교 수단을 제공하는 단일 모델보다 훨씬 더 나은 결과를 제공할 수 있음을 보여주었습니다. 동일한 기본 사전 학습 모델에서 미세 조정된 앙상블 모델은 사전 학습 및 모든 모델을 완전히 개별적으로 미세 조정하는 것보다 성능이 나빴지만, 미세 조정 전용 앙상블은 여전히 단일 모델보다 성능이 훨씬 뛰어났습니다.
한계 극복 우리는 위의 통찰력을 결합하고 훨씬 더 큰 모델(최대 110억 개의 매개변수)을 훈련하여 우리가 고려한 많은 벤치마크에서 최첨단 결과를 달성했습니다. 비지도 학습의 경우 C4 데이터 세트에서 텍스트를 추출하고 연속 토큰 범위를 손상시키는 노이즈 제거 목표를 적용했습니다. 우리는 개별 작업을 미세 조정하기 전에 다중 작업 혼합에 대해 사전 교육했습니다. 전반적으로 우리 모델은 1조 개가 넘는 토큰에 대해 훈련되었습니다. 결과의 복제, 확장 및 적용을 촉진하기 위해 우리는 각 T5 변형에 대해 코드, C4 데이터 세트 및 사전 훈련된 모델 가중치를 공개합니다.
4.2. 시야
대형 모델의 불편함 우리 연구의 놀랍지도 않지만 중요한 결과는 대형 모델이 더 나은 성능을 발휘하는 경향이 있다는 것입니다. 이러한 모델을 실행하는 데 사용되는 하드웨어가 지속적으로 저렴해지고 강력해지고 있다는 사실은 확장이 더 나은 성능을 달성하기 위한 유망한 방법이 될 수 있음을 시사합니다(Sutton, 2019). 그러나 클라이언트 측 추론 또는 연합 학습을 수행할 때와 같이 더 작거나 저렴한 모델을 사용하는 것이 도움이 되는 애플리케이션 및 시나리오는 항상 존재합니다(Konečn`y et al., 2015, 2016). 이와 관련하여 전이 학습의 한 가지 유익한 용도는 리소스가 적은 작업에서 좋은 성과를 얻을 수 있다는 것입니다. 정의에 따라 더 많은 데이터에 라벨을 붙일 자산이 부족한 환경에서는 리소스가 부족한 작업이 자주 발생합니다. 따라서 리소스가 부족한 애플리케이션은 추가 비용이 발생할 수 있는 계산 리소스에 대한 액세스가 제한되는 경우가 많습니다. 결과적으로 우리는 전이 학습이 가장 큰 영향을 미치는 곳에 적용될 수 있도록 더 저렴한 모델로 더 강력한 성능을 달성하는 방법에 대한 연구를 옹호합니다. 이러한 라인에 따른 일부 현재 작업에는 증류(Hinton et al., 2015; Sanh et al., 2019; Jiao et al., 2019), 매개변수 공유(Lan et al., 2019) 및 조건부 계산(Shazeer et al. , 2017).
보다 효율적인 지식 추출 사전 훈련의 목표 중 하나는 (느슨하게 말하면) 다운스트림 작업의 성능을 향상시키는 범용 "지식"을 모델에 제공하는 것임을 상기하십시오. 현재 일반적인 관행인 이 작업에서 우리가 사용하는 방법은 손상된 텍스트 범위의 노이즈를 제거하도록 모델을 훈련시키는 것입니다. 우리는 이 단순한 기법이 모델 범용 지식을 가르치는 데 매우 효율적인 방법이 아닐 수 있다고 의심합니다. 보다 구체적으로, 먼저 1조 개의 텍스트 토큰에 대해 모델을 교육할 필요 없이 우수한 미세 조정 성능을 얻을 수 있으면 유용할 것입니다. 이러한 라인에 따른 일부 동시 작업은 실제 텍스트와 기계 생성 텍스트를 구별하기 위해 모델을 사전 학습하여 효율성을 향상시킵니다(Clark et al., 2020).
작업 간의 유사성 공식화 우리는 레이블이 지정되지 않은 도메인 내 데이터에 대한 사전 교육이 다운스트림 작업의 성능을 향상시킬 수 있음을 관찰했습니다(섹션 3.4). 이 발견은 주로 SQuAD가 Wikipedia의 데이터를 사용하여 만들어졌다는 사실과 같은 기본적인 관찰에 의존합니다. 사전 학습 작업과 다운스트림 작업 간의 "유사성"에 대한 보다 엄격한 개념을 공식화하여 사용할 레이블이 없는 데이터 소스에 대해 보다 원칙적인 선택을 할 수 있도록 하는 것이 유용할 것입니다.
컴퓨터 비전 분야에서는 이러한 맥락을 따르는 몇 가지 초기 경험적 연구가 있습니다(Huh et al., 2016; Kornblith et al., 2018; He et al., 2018). 작업의 관련성에 대한 더 나은 개념은 감독된 사전 훈련 작업을 선택하는 데 도움이 될 수도 있으며, 이는 GLUE 벤치마크에 도움이 되는 것으로 나타났습니다(Phang et al., 2018).
언어에 구애받지 않는 모델 우리는 영어만 사용한 사전 훈련이 우리가 연구한 번역 작업에서 최고 수준의 결과를 얻지 못했다는 사실에 실망했습니다. 우리는 또한 어휘가 어떤 언어를 인코딩할 수 있는지 미리 지정해야 하는 논리적인 어려움을 피하는 데 관심이 있습니다. 이러한 문제를 해결하기 위해 우리는 언어에 구애받지 않는 모델, 즉 텍스트의 언어에 관계없이 좋은 성능으로 주어진 NLP 작업을 수행할 수 있는 모델을 추가로 조사하는 데 관심이 있습니다. 영어가 세계 인구 대다수의 모국어가 아니라는 점을 고려하면 이는 특히 적절한 문제입니다. 이 논문의 동기는 NLP를 위한 전이 학습에 대한 최근 연구의 분주함이었습니다. 우리가 이 작업을 시작하기 전에 이러한 발전은 이미 학습 기반 방법이 아직 효과적이지 않은 환경에서 획기적인 발전을 가능하게 했습니다. 예를 들어, 현대 전이 학습 파이프라인에서는 어렵도록 특별히 설계된 작업인 SuperGLUE 벤치마크에서 인간 수준의 성능과 거의 일치함으로써 이러한 추세를 계속할 수 있게 되어 기쁘게 생각합니다. 우리의 결과는 간단하고 통합된 텍스트-텍스트 프레임워크, 새로운 C4 데이터 세트 및 체계적인 연구에서 얻은 통찰력의 조합에서 비롯됩니다. 추가적으로, 우리는 해당 분야에 대한 경험적 개요와 그것이 어디에 있는지에 대한 관점을 제공했습니다. 우리는 일반적인 언어 이해라는 목표를 향해 전이 학습을 사용하는 지속적인 작업을 보게 되어 기쁩니다.
- BERT는 input sequence 토큰의 15%를 pre-processing 단계에서 선택
- 선택된 토큰 중 80% special token[MASK]로 교체, 10% 그대로, 10% random token으로 교체
- 한 번 선택된 마스킹 구성으로 pre-trainig 내내 학습되지 않도록, 데이터를 복제해서 다르게 마스킹
- 더 자주 마스킹을 다르게 해주면 유리하지 않을까?
• Next Sentenxe Prediction(NSP) : 삭제
- 목표 : input으로 받은 2개 segment X, Y가 연속된 문장인지 여부 판단
- IsNext : 한 코퍼스에서 연속된 두 문장 추출해 쌍을 만듦
- NotNext : 두 번째 문장은 다른 문서에서 추출해 쌍을 만듦
- 두 문장 관계를 이해한 모델이 Question Answering(QA), Natural Language Inference(NLI) task에서 더 나은 성능을 보였음
- 충분히 잘 학습된 BERT 모델은 여전히 NSP를 필요로 할까?
2.4 Optimization
비교항목
BERT
RoBERTa
Mini batch size
256
8K
Update
1,000,000
500K
Adam
β1 = 0.9 β2 = 0.999 ∈ = 1e-6
학습이 Adam epsilon에 민간 β2 = 0.98 batch size 클때도 안정적으로 학습
Learning rate
Warm up 10,000 steps Peak value : 1e-4, 선형 감소
Warm up 30K steps Peak value : 4e-4, 선형 감소
Dropout
0.1 for all layers
Activation function
GELU
2.5 Pre-train data : 기존 포함 10배 확장
• Pre-training data가 많으면 end-task 성능 개선에 도움을 줄 수 있음(Baevski ei al. 2019)
• RoBERTa는 더 많고, 더 다양한 도메인으로 학습 데이터 구축
BERT(16GB)
RoBERTa(160GB)
• BOOKCORPUS + English WIKIPEDIA, 16GB
• BOOKCORPUS + English WIKIPEDIA, 16GB • CC-NEWS(from CommonCrawl), 76GB 2016.9 ~ 2019.2 630만개 영문 뉴스 기사 • OPEN WEB TEXT, 38GB Reddit에서 좋아요 3개 이상 받은 웹 콘텐츠 • STORIES(from CommanCrawl), 31GB Winograd schemas 형식의 데이터
3. Evaluation
• GLUE : General Language Understanding Evaluation benchmark
언어 모델 사전 학습으로 성능이 크게 향상되었지만 서로 다른 접근 방식을 주의 깊게 비교하는 것은 어렵습니다. 훈련은 계산 비용이 많이 들고 종종 다른 개인 데이터 세트에서 수행됩니다. 그리고 앞으로 보여주겠지만 하이퍼파라미터 선택은 최종 결과에 상당한 영향을 미칩니다. 우리는 많은 주요 하이퍼파라미터와 훈련 데이터 크기의 영향을 주의 깊게 측정하는 BERT 사전 훈련(Devlin et al., 2019)에 대한 복제 연구를 제시합니다. 우리는 BERT가 상당히 훈련이 부족하다는 것을 발견했습니다. 또는 그 이후에 출시된 모든 모델의 성능을 능가합니다. 우리의 최고의 모델은 GLUE, RACE 및 SQuAD에서 최첨단 결과를 달성합니다. 이러한 결과는 이전에 간과되었던 설계 선택의 중요성을 강조하고 최근 보고된 개선 사항의 출처에 대한 의문을 제기합니다. 우리는 모델과 코드를 공개합니다.
1. 서론 ELMo(Peters et al., 2018), GPT(Radford et al., 2018), BERT(Devlin et al., 2019), XLM(Lample and Conneau, 2019), XLNet(Yang et al., 2019)과 같은 자가 훈련 방법은 상당한 성능 향상을 가져왔지만 방법의 어떤 측면이 가장 크게 기여했는지 판단하는 것은 어려울 수 있습니다. 훈련은 계산 비용이 많이 들고 수행할 수 있는 조정의 양이 제한되며 다양한 크기의 개인 훈련 데이터로 수행되는 경우가 많아 모델링 발전의 효과를 측정하는 능력이 제한됩니다.
우리는 하이퍼파라미터 튜닝 및 훈련 세트 크기의 효과에 대한 신중한 평가를 포함하는 BERT 사전 훈련(Devlin et al., 2019)에 대한 복제 연구를 제시합니다. 우리는 BERT가 상당히 과소평가되었음을 발견하고 모든 포스트-BERT 방법의 성능과 일치하거나 이를 능가할 수 있는 RoBERTa라고 부르는 BERT 모델 교육을 위한 개선된 레시피를 제안합니다. 수정 사항은 간단합니다. (1) 더 많은 데이터에 대해 더 큰 배치로 모델을 더 오랫동안 훈련합니다. (2) 다음 문장 예측 목표를 제거하는 단계; (3) 더 긴 시퀀스에 대한 훈련; (4) 훈련 데이터에 적용된 마스킹 패턴을 동적으로 변경하는 것. 또한 훈련 세트 크기 효과를 더 잘 제어하기 위해 다른 개인용 데이터 세트와 비슷한 크기의 대규모 새 데이터 세트(CC-NEWS)를 수집합니다.
훈련 데이터를 제어할 때 개선된 훈련 절차는 GLUE 및 SQuAD 모두에 게시된 BERT 결과를 개선합니다. 추가 데이터에 대해 더 오랫동안 훈련했을 때 우리 모델은 공개 GLUE 순위표에서 88.5점을 달성했으며 이는 Yang et al (2019). 이 보고한 88.4점과 일치합니다. 우리 모델은 MNLI, QNLI, RTE 및 STS-B와 같은 GLUE 작업의 4/9에 대한 새로운 최첨단 기술을 확립합니다. 또한 SQuAD 및 RACE의 최신 결과도 일치시킵니다. 전반적으로 우리는 BERT의 마스크된 언어 모델 훈련 목표가 교란된 자동 회귀 언어 모델링과 같은 최근 제안된 다른 훈련 목표와 경쟁적이라는 것을 다시 확립했습니다(Yang et al., 2019).
요약하면, 이 문서의 기여는 다음과 같습니다. (1) 중요한 BERT 설계 선택 및 교육 전략 세트를 제시하고 더 나은 다운스트림 작업 성능으로 이어지는 대안을 소개합니다. (2) 우리는 새로운 데이터 세트인 CCNEWS를 사용하고 사전 훈련에 더 많은 데이터를 사용하면 다운스트림 작업의 성능이 더욱 향상된다는 것을 확인합니다. (3) 우리의 훈련 개선 사항은 올바른 설계 선택 하에서 마스크된 언어 모델 사전 훈련이 최근에 발표된 다른 모든 방법과 경쟁력이 있음을 보여줍니다. 우리는 PyTorch에서 구현된 모델, 사전 훈련 및 미세 조정 코드를 출시합니다(Paszke et al., 2017).
2. 배경 이 섹션에서는 BERT(Devlin et al., 2019) 사전 훈련 접근 방식에 대한 간략한 개요와 다음 섹션에서 실험적으로 검토할 훈련 선택 사항 중 일부를 제공합니다.
2.1 설정 BERT는 두 세그먼트(토큰 시퀀스) x1,...,xN 및 y1,...,yM의 연결을 입력으로 사용합니다. 세그먼트는 일반적으로 하나 이상의 자연 문장으로 구성됩니다. 두 개의 세그먼트 이를 구분하는 특수 토큰을 사용하여 BERT에 대한 단일 입력 시퀀스로 제공됩니다. [CLS], x1, . . . , xN, [SEP], y1, . . . , yM, [EOS]. M과 N은 M + N < T로 제한됩니다. 여기서 T는 훈련 중 최대 시퀀스 길이를 제어하는 매개변수입니다. 모델은 먼저 레이블이 지정되지 않은 대규모 텍스트 코퍼스에서 사전 학습된 후 최종 작업 레이블이 지정된 데이터를 사용하여 미세 조정됩니다.
2.2 아키텍처 BERT는 현재 유비쿼터스적인 변환기 아키텍처(Vaswani et al., 2017)를 사용하는데, 이에 대해서는 자세히 검토하지 않겠습니다. 우리는 L 레이어가 있는 변환기 아키텍처를 사용합니다. 각 블록은 A self-attention 헤드와 숨겨진 차원 H를 사용합니다.
2.3 교육 목표 사전 훈련 중에 BERT는 마스크된 언어 모델링과 다음 문장 예측이라는 두 가지 목표를 사용합니다.
마스크된 언어 모델(MLM) 입력 시퀀스에서 토큰의 무작위 샘플이 선택되고 특수 토큰 [MASK]로 대체됩니다. MLM 목표는 마스킹된 토큰 예측에 대한 교차 엔트로피 손실입니다. BERT를 균일하게 가능한 교체를 위해 입력 토큰의 15%를 선택합니다. 선택된 토큰 중 80%는 [MASK]로 대체되고, 10%는 변경되지 않고 남아 있으며, 10%는 무작위로 선택된 어휘 토큰으로 대체됩니다. 원래 구현에서는 무작위 마스킹 및 교체가 처음에 한 번 수행되고 훈련 기간 동안 저장되지만 실제로는 데이터가 복제되므로 마스크가 모든 훈련 문장에 대해 항상 동일하지는 않습니다(섹션 4.1 참조).
NSP(Next Sentence Prediction) NSP는 두 문장이 일치하는지 예측하기 위한 이진 분류 손실입니다. 세그먼트는 원본 텍스트에서 서로 이어집니다. 긍정적인 예는 텍스트 코퍼스에서 연속된 문장을 취하여 생성됩니다. 부정적인 예는 서로 다른 문서의 세그먼트를 쌍으로 만들어 생성됩니다. 긍정적인 예와 부정적인 예는 동일한 확률로 샘플링됩니다. NSP 목표는 문장 쌍 간의 관계에 대한 추론이 필요한 자연어 추론(Bowman et al., 2015)과 같은 다운스트림 작업의 성능을 향상하도록 설계되었습니다.
2.4 최적화 BERT는 다음 매개변수를 사용하여 Adam(Kingma and Ba, 2015)으로 최적화되었습니다: β1 = 0.9, β2 = 0.999, τ = 1e-6 및 L2 가중치 감쇠 0.01. 학습률은 처음 10,000단계에 걸쳐 최대값 1e-4까지 예열된 다음 선형적으로 감소합니다. BERT는 모든 레이어와 Attention Weight에서 0.1의 드롭아웃과 GELU 활성화 함수를 사용하여 훈련합니다 (Hendrycks and Gimpel, 2016).
모델은 S = 1,000,000 업데이트에 대해 사전 학습되었으며, 미니 배치에는 최대 길이 T = 512개 토큰의 B = 256개 시퀀스가 포함되어 있습니다.
2.5 데이터 BERT는 BOOKCORPUS(Zhu et al., 2015)와 영어 WIKIPEDIA(총 16GB의 비압축 텍스트)의 조합으로 훈련되었습니다.
3 실험 설정 이 섹션에서는 BERT의 복제 연구를 위한 실험 설정을 설명합니다.
3.1 구현 FAIRSEQ에서 BERT를 다시 구현합니다(Ott et al., 2019). 각 설정에 대해 개별적으로 조정되는 최대 학습 속도와 준비 단계 수를 제외하고는 주로 섹션 2에 제공된 원래 BERT 최적화 하이퍼 매개변수를 따릅니다. 우리는 또한 훈련이 Adam 엡실론 항에 매우 민감하다는 것을 발견했으며 어떤 경우에는 조정 후 더 나은 성능이나 안정성을 얻었습니다. 마찬가지로, 큰 배치 크기로 훈련할 때 안정성을 향상시키기 위해 β2 = 0.98을 설정하는 것을 발견했습니다. 우리는 최대 T = 512개의 토큰 시퀀스로 사전 훈련합니다. Devlin et al. (2019), 우리는 짧은 시퀀스를 무작위로 주입하지 않으며 업데이트의 처음 90%에 대해 줄어든 시퀀스 길이로 훈련하지 않습니다. 우리는 전체 길이의 시퀀스로만 훈련합니다. 우리는 Infiniband로 상호 연결된 8 × 32GB Nvidia V100 GPU를 갖춘 DGX-1 시스템에서 혼합 정밀 부동 소수점 연산을 사용하여 교육합니다(Micikevicius et al., 2018).
3.2 데이터 BERT 스타일 사전 훈련은 대량의 텍스트에 결정적으로 의존합니다. Baevskiet al. (2019)은 데이터 크기가 증가하면 최종 작업 성능이 향상될 수 있음을 보여줍니다. 원래 BERT보다 더 크고 다양한 데이터 세트에 대한 여러 가지 노력이 이루어졌습니다(Radford et al., 2019; Yang et al., 2019; Zellers et al., 2019). 불행하게도 모든 추가 데이터 세트가 공개적으로 공개될 수는 없습니다. 우리 연구에서는 실험을 위해 최대한 많은 데이터를 수집하는 데 중점을 두어 전반적인 품질과 각 비교에 적합한 데이터의 양. 우리는 크기와 도메인이 다양한 5개의 영어 말뭉치(총 160GB가 넘는 비압축 텍스트)를 고려합니다. 우리는 다음과 같은 텍스트 말뭉치를 사용합니다:
• BOOKCORPUS(Zhu et al., 2015) 및 영어 WIKIPEDIA. BERT 학습에 사용된 원본 데이터입니다. (16 기가 바이트). • CommonCrawl News 데이터세트의 영어 부분에서 수집한 CC-NEWS(Nagel, 2016). 해당 데이터에는 2016년 9월부터 2019년 2월 사이에 크롤링된 6,300만 개의 영어 뉴스 기사가 포함되어 있습니다. (필터링 후 76GB) • OPENWEBTEXT(Gokaslan 및 Cohen, 2019), Radford et al.에 설명된 WebText 코퍼스를 오픈 소스로 재현한 것입니다. (2019). 텍스트는 최소 3개의 찬성표를 얻은 Reddit에서 공유된 URL에서 추출된 웹 콘텐츠입니다. (38GB). • STORIES는 Winograd 스키마의 스토리 스타일과 일치하도록 필터링된 CommonCrawl 데이터의 하위 집합을 포함하는 Trinh and Le(2018)에 소개된 데이터세트입니다. (31GB).
3.3 평가 이전 작업에 이어 다음 세 가지 벤치마크를 사용하여 다운스트림 작업에 대한 사전 훈련된 모델을 평가합니다.
GLUE GLUE(General Language Understanding Evaluation) 벤치마크(Wang et al., 2019b)는 평가를 위한 9개 데이터세트 모음입니다. 자연어 이해 시스템. 작업은 단일 문장 분류 또는 문장 쌍 분류 작업으로 구성됩니다. GLUE 조직자는 교육 및 개발 데이터 분할은 물론 참가자가 비공개 테스트 데이터를 통해 자신의 시스템을 평가하고 비교할 수 있는 제출 서버와 리더보드를 제공합니다. 섹션 4의 복제 연구에서는 해당 단일 작업 훈련 데이터(즉, 다중 작업 훈련이나 앙상블링 없이)에 대해 사전 훈련된 모델을 미세 조정한 후 개발 세트에 대한 결과를 보고합니다. 우리의 미세 조정 절차는 원본 BERT 논문(Devlin et al., 2019)을 따릅니다. 섹션 5에서는 공개 리더보드에서 얻은 테스트 세트 결과를 추가로 보고합니다. 이러한 결과는 섹션 5.1에서 설명하는 여러 작업별 수정에 따라 달라집니다.
SQuAD SQuAD(Stanford Question Answering Dataset)는 컨텍스트 단락과 질문을 제공합니다. 작업은 컨텍스트에서 관련 범위를 추출하여 질문에 대답하는 것입니다. 우리는 SQuAD의 두 가지 버전인 V1.1과 V2.0을 평가합니다(Rajpurkar et al., 2016, 2018). V1.1에서는 컨텍스트에 항상 답변이 포함되어 있는 반면, V2.0에서는 제공된 컨텍스트에서 일부 질문에 대한 답변이 제공되지 않아 작업이 더욱 어려워집니다.
SQuAD V1.1에서는 BERT와 동일한 범위 예측 방법을 채택합니다(Devlin et al., 2019). SQuAD V2.0의 경우 질문에 답할 수 있는지 예측하기 위해 추가 이진 분류기를 추가하고 분류 및 범위 손실 항을 합산하여 공동으로 훈련합니다. 평가 중에는 응답 가능한 것으로 분류된 쌍의 범위 지수만 예측합니다.
RACE RACE(ReAding Comprehension from Examinations)(Lai et al., 2017) 작업은 대규모 독해 데이터세트입니다. 28,000개가 넘는 구절과 거의 100,000개의 질문이 있습니다. 데이터 세트는 중, 고등학생을 대상으로 설계된 중국의 영어 시험에서 수집되었습니다. RACE에서는 각 구절이 여러 질문과 연결되어 있습니다. 모든 질문에 대한 작업은 네 가지 옵션 중에서 하나의 정답을 선택하는 것입니다. RACE는 다른 인기 있는 독해 데이터 세트보다 훨씬 더 긴 맥락을 갖고 있으며 추론이 필요한 질문의 비율이 매우 큽니다.
4 훈련 절차 분석 이 섹션에서는 BERT 모델을 성공적으로 사전 훈련하는 데 중요한 선택 사항을 탐색하고 정량화합니다. 우리는 모델 아키텍처를 고정된 상태로 유지합니다. 구체적으로 BERTBASE와 동일한 구성(L = 12, H = 768, A = 12, 110M 매개변수)으로 BERT 모델을 훈련하는 것으로 시작합니다.
4.1 정적 마스킹과 동적 마스킹 섹션 2에서 설명한 것처럼 BERT는 토큰을 무작위로 마스킹하고 예측하는 데 의존합니다. 원래 BERT 구현은 마스킹을 수행했습니다. 데이터 전처리 중에 한 번, 단일 정적 마스크가 생성됩니다. 모든 에포크의 각 훈련 인스턴스에 동일한 마스크를 사용하지 않기 위해 훈련 데이터를 10번 복제하여 40개의 훈련 에포크 동안 각 시퀀스가 10가지 다른 방식으로 마스크되었습니다. 따라서 각 훈련 시퀀스는 훈련 중에 동일한 마스크를 4번 사용하는 것으로 나타났습니다. 우리는 이 전략을 모델에 시퀀스를 제공할 때마다 마스킹 패턴을 생성하는 동적 마스킹과 비교합니다. 이는 더 많은 단계나 더 큰 데이터 세트를 위해 사전 훈련할 때 중요합니다.
표 1: BERTBASE의 정적 마스킹과 동적 마스킹 비교. SQuAD에 대해서는 F1을 보고하고 MNLI-m 및 SST-2에 대해서는 정확도를 보고합니다. 보고된 결과는 5번의 무작위 초기화(시드)에 대한 중앙값입니다. 참고 결과는 Yang et al. (2019).
결과 표 1은 Devlin et al.(2019)에서 게시된 BERTBASE 결과를 정적 또는 동적 마스킹을 사용한 재구현과 비교합니다. 정적 마스킹을 사용한 재구현은 원래 BERT 모델과 유사하게 수행되며 동적 마스킹은 정적 마스킹과 비슷하거나 약간 더 우수하다는 것을 확인했습니다. 이러한 결과와 동적 마스킹의 추가 효율성 이점을 고려하여 나머지 실험에서는 동적 마스킹을 사용합니다.
4.2 모델 입력 형식과 다음 문장 예측 원래 BERT 사전 학습 절차에서 모델은 동일한 문서(p = 0.5) 또는 서로 다른 문서에서 연속적으로 샘플링되는 두 개의 연결된 문서 세그먼트를 관찰합니다. 마스킹된 언어 모델링 목표 외에도 모델은 보조 NSP(다음 문장 예측) 손실을 통해 관찰된 문서 세그먼트가 동일한 문서에서 왔는지 아니면 별개의 문서에서 왔는지 예측하도록 훈련됩니다. NSP 손실은 원래 BERT 모델을 훈련하는 데 중요한 요소인 것으로 가정되었습니다. Devlin et al.(2019)은 NSP를 제거하면 성능이 저하되고 QNLI, MNLI 및 SQuAD 1.1에서 상당한 성능 저하가 발생한다는 사실을 관찰했습니다. 그러나 최근 일부 연구에서는 NSP 손실의 필요성에 의문을 제기했습니다(Lample and Conneau, 2019; Yang et al., 2019; Joshi et al., 2019). 이러한 불일치를 더 잘 이해하기 위해 몇 가지 대체 교육 형식을 비교합니다.
• SEGMENT-PAIR+NSP: 이는 BERT(Devlin et al., 2019)에서 사용되는 원래 입력 형식을 따르며 NSP 손실이 있습니다. 각 입력에는 한 쌍의 세그먼트가 있으며 각 세그먼트에는 여러 개의 자연산이 포함될 수 있습니다. 문장이지만 총 결합 길이는 토큰 512개 미만이어야 합니다.
표 2: BOOKCORPUS 및 WIKIPEDIA를 통해 사전 훈련된 기본 모델에 대한 개발 세트 결과. 모든 모델은 배치 크기가 256개 시퀀스인 1M 단계에 대해 학습되었습니다. SQuAD의 경우 F1을 보고하고 MNLI-m, SST-2 및 RACE의 정확도를 보고합니다. 보고된 결과는 5번의 무작위 초기화(시드)에 대한 중앙값입니다. BERTBASE 및 XLNetBASE에 대한 결과는 Yang et al.(2019)에서 가져온 것입니다.
• SENTENCE-PAIR+NSP: 각 입력에는 한 문서의 인접한 부분이나 별도의 문서에서 샘플링된 자연 문장 쌍이 포함됩니다. 이러한 입력은 512개 토큰보다 훨씬 짧기 때문에 총 토큰 수가 SEGMENT-PAIR+NSP와 유사하게 유지되도록 배치 크기를 늘립니다. 우리는 NSP 손실을 유지합니다. • 전체 문장: 각 입력은 하나 이상의 문서에서 연속적으로 샘플링된 전체 문장으로 구성됩니다. 즉, 총 길이는 최대 512개 토큰입니다. 입력 내용이 문서 경계를 넘을 수 있습니다. 한 문서의 끝에 도달하면 다음 문서에서 문장 샘플링을 시작하고 문서 사이에 추가 구분 기호 토큰을 추가합니다. NSP 손실을 제거합니다. • DOC-SENTENCES: 입력은 문서 경계를 넘을 수 없다는 점을 제외하면 FULL-SENTENCES와 유사하게 구성됩니다. 문서 끝부분에서 샘플링된 입력은 512개 토큰보다 짧으므로 이러한 경우 FULLSENTENCES와 비슷한 총 토큰 수를 달성하기 위해 배치 크기를 동적으로 늘립니다. NSP 손실을 제거합니다.
결과 표 2는 네 가지 다른 설정에 대한 결과를 보여줍니다. 먼저 Devlin et al. (2019)의 원래 SEGMENT-PAIR 입력 형식을 SENTENCE-PAIR 형식과 비교합니다. 두 형식 모두 NSP 손실을 유지하지만 후자는 단일 문장을 사용합니다. 개별 문장을 사용하면 다운스트림 작업의 성능이 저하된다는 사실을 발견했습니다. 이는 모델이 장거리 종속성을 학습할 수 없기 때문이라고 가정합니다.
다음으로 NSP 손실 없는 훈련과 단일 문서(DOC-SENTENCES)의 텍스트 블록을 사용한 훈련을 비교합니다. 우리는 이 설정이 원래 게시된 BERTBASE 결과보다 성능이 뛰어나고 Devlin et al.(2019)과 달리 NSP 손실을 제거하면 다운스트림 작업 성능이 일치하거나 약간 향상된다는 것을 발견했습니다. 원래 BERT 구현은 SEGMENT-PAIR 입력 형식을 유지하면서 손실 항만 제거했을 가능성이 있습니다. 마지막으로 우리는 단일 문서(DOC-SENTENCES)에서 시퀀스를 제한하는 것이 여러 문서(FULL-SENTENCES)에서 시퀀스를 패킹하는 것보다 약간 더 나은 성능을 발휘한다는 것을 발견했습니다. 그러나 DOC-SENTENCES 형식으로 인해 배치 크기가 다양해지기 때문에 관련 작업과 더 쉽게 비교할 수 있도록 나머지 실험에서는 FULLSENTENCES를 사용합니다.
4.3 대규모 배치를 사용한 훈련 신경 기계 번역의 과거 연구에 따르면 매우 큰 미니 배치를 사용한 교육은 학습 속도가 적절하게 증가할 때 최적화 속도와 최종 작업 성능을 모두 향상시킬 수 있는 것으로 나타났습니다(Ott et al., 2018). 최근 작업에는 BERT는 대규모 배치 훈련에도 적합하다는 것을 보여주었습니다(You et al., 2019). Devlin et al.(2019)은 원래 배치 크기가 256개 시퀀스인 1M 단계에 대해 BERTBASE를 교육했습니다. 이는 그라디언트 누적을 통한 계산 비용 측면에서 배치 크기가 2K 시퀀스인 125K 단계 또는 배치 크기가 8K인 31K 단계에 대한 교육과 동일합니다.
표 3: 다양한 배치 크기(bsz)를 사용하여 BOOKCORPUS 및 WIKIPEDIA를 통해 훈련된 기본 모델에 대한 보유 훈련 데이터(ppl) 및 개발 세트 정확도에 대한 혼란. 각 설정에 대해 학습률(lr)을 조정합니다. 모델은 데이터(에포크)에 대해 동일한 수의 패스를 수행하고 동일한 계산 비용을 갖습니다.
표 3에서는 훈련 데이터를 통과하는 횟수를 제어하면서 배치 크기를 늘리면서 BERTBASE의 복잡성과 최종 작업 성능을 비교합니다. 우리는 대규모 배치를 사용한 교육이 마스크된 언어 모델링 목표에 대한 복잡성과 최종 작업 정확도를 향상시키는 것을 관찰했습니다. 또한 대규모 배치는 분산 데이터 병렬 훈련을 통해 병렬화하기가 더 쉽고, 이후 실험에서는 8K 시퀀스 배치로 훈련합니다. 특히 You et al.(2019)은 최대 32K 시퀀스의 훨씬 더 큰 배치 크기로 BERT를 교육합니다. 대규모 배치 훈련의 한계에 대한 추가 탐구는 향후 작업에 맡깁니다.
4.4 텍스트 인코딩 바이트 쌍 인코딩(BPE)(Sennrich et al., 2016)은 자연어 말뭉치에서 흔히 볼 수 있는 대규모 어휘를 처리할 수 있는 문자 수준 표현과 단어 수준 표현 간의 하이브리드입니다. 전체 단어 대신 BPE는 훈련 코퍼스의 통계 분석을 수행하여 추출된 하위 단어 단위에 의존합니다. BPE 어휘 크기는 일반적으로 10K-100K 하위 단어 단위입니다. 그러나 유니코드 문자는 이 작업에서 고려되는 것과 같이 크고 다양한 말뭉치를 모델링할 때 이 어휘의 상당 부분을 차지할 수 있습니다. Radfordet al. (2019)에서는 유니코드 문자 대신 바이트를 기본 하위 단어 단위로 사용하는 영리한 BPE 구현을 소개합니다. 바이트를 사용하면 "알 수 없는" 토큰을 도입하지 않고도 입력 텍스트를 인코딩할 수 있는 적당한 크기(50K 단위)의 하위 단어 어휘를 학습할 수 있습니다.
원래 BERT 구현(Devlin et al., 2019)은 30K 크기의 문자 수준 BPE 어휘를 사용합니다. 경험적 토큰화 규칙을 사용하여 입력을 전처리한 후 Radford et al.(2019)에 이어, 대신 입력의 추가 전처리나 토큰화 없이 50K 하위 단어 단위가 포함된 더 큰 바이트 수준 BPE 어휘로 BERT를 교육하는 것을 고려합니다. 이는 BERTBASE 및 BERTLARGE에 대해 각각 약 15M 및 20M의 추가 매개변수를 추가합니다. 초기 실험에서는 이러한 인코딩 간에 약간의 차이만 나타났으며 Radford et al.(2019) BPE는 약간의 달성을 보였습니다. 일부 작업에서는 최종 작업 성능이 저하됩니다. 그럼에도 불구하고 우리는 범용 인코딩 체계의 장점이 성능 저하보다 더 크다고 믿고 나머지 실험에서는 이 인코딩을 사용합니다. 이러한 인코딩에 대한 보다 자세한 비교는 향후 작업에 남아 있습니다.
5 RoBERTa 이전 섹션에서 우리는 최종 작업 성능을 향상시키는 BERT 사전 훈련 절차에 대한 수정을 제안했습니다. 이제 이러한 개선 사항을 집계하고 결합된 영향을 평가합니다. 강력하게 최적화된 BERT 접근 방식을 위해 이 구성을 RoBERTa라고 부릅니다. 특히 RoBERTa는 동적 마스킹으로 훈련되었습니다. (섹션 4.1), NSP 손실 없는 FULL-SENTENCES(섹션 4.2), 대규모 미니 배치(섹션 4.3) 및 더 큰 바이트 수준 BPE(섹션 4.4). 또한 이전 작업에서 덜 강조된 두 가지 중요한 요소인 (1) 사전 훈련에 사용되는 데이터와 (2) 데이터를 통과하는 훈련 횟수를 조사합니다. 예를 들어 최근 제안된 XLNet 아키텍처(Yang et al., 2019)는 원래 BERT(Devlin et al., 2019)보다 거의 10배 더 많은 데이터를 사용하여 사전 학습되었습니다. 또한 최적화 단계의 절반에 대해 8배 더 큰 배치 크기로 훈련되므로 BERT에 비해 사전 훈련에서 4배 더 많은 시퀀스를 볼 수 있습니다.
이러한 요소의 중요성을 다른 모델링 선택(예: 사전 훈련 목표)과 분리하는 데 도움이 되도록 BERTLARGE 아키텍처(L = 24, H = 1024, A = 16, 355M 매개변수)에 따라 RoBERTa를 훈련하는 것으로 시작합니다. 우리는 Devlin et al. (2019)에서 사용된 것과 유사한 BOOKCORPUS 및 WIKIPEDIA 데이터세트에 대해 100,000단계에 대해 사전 훈련합니다. 우리는 약 하루 동안 1024개의 V100 GPU를 사용하여 모델을 사전 훈련했습니다.
표 4: 더 많은 데이터(16GB~160GB 텍스트)를 사전 학습하고 더 오랫동안(100K! 300K! 500K 단계) 사전 학습한 RoBERTa의 개발 세트 결과. 각 행에는 위 행의 개선 사항이 누적됩니다. RoBERTa는 BERTLARGE의 아키텍처 및 교육 목표와 일치합니다. BERTLARGE 및 XLNetLARGE에 대한 결과는 Devlin et al. (2019) 및 Yang et al. (2019) 각각. 모든 GLUE 작업에 대한 전체 결과는 부록에서 확인할 수 있습니다.
결과 표 4에 결과를 제시합니다. 훈련 데이터를 제어할 때 RoBERTa가 원래 보고된 BERTLARGE 결과에 비해 큰 개선을 제공하는 것을 관찰하여 섹션 4에서 살펴본 설계 선택의 중요성을 재확인했습니다. 다음으로, 이 데이터를 섹션 3.2에 설명된 세 가지 추가 데이터 세트와 결합합니다. 이전과 동일한 수(100K)의 훈련 단계를 사용하여 결합된 데이터에 대해 RoBERTa를 훈련합니다. 전체적으로 우리는 160GB가 넘는 텍스트를 사전 학습합니다. 우리는 모든 다운스트림 작업에서 성능이 더욱 향상되는 것을 관찰하여 사전 훈련에서 데이터 크기와 다양성의 중요성을 검증했습니다. 마지막으로 RoBERTa를 훨씬 더 오랫동안 사전 훈련하여 사전 훈련 단계 수를 100K에서 300K, 그리고 500K로 늘렸습니다. 다운스트림 작업 성능이 크게 향상되었으며 300K 및 500K 단계 모델이 대부분의 작업에서 XLNetLARGE보다 성능이 뛰어났습니다. 가장 오랫동안 훈련된 모델이라도 데이터에 과적합되지 않는 것으로 보이며 추가 훈련을 통해 이점을 얻을 가능성이 높습니다. 나머지 문서에서는 GLUE, SQuaD 및 RACE의 세 가지 벤치마크에서 최고의 RoBERTa 모델을 평가합니다. 구체적으로 우리는 RoBERTa가 섹션 3.2에 소개된 5개 데이터세트 모두에 대해 500K 단계에 대해 훈련되었다고 생각합니다..
5.1 GLUE 결과 GLUE의 경우 두 가지 미세 조정 설정을 고려합니다. 첫 번째 설정(단일 작업, 개발)에서는 해당 작업에 대한 훈련 데이터만 사용하여 각 GLUE 작업에 대해 별도로 RoBERTa를 미세 조정합니다. 제한된 하이퍼파라미터를 고려합니다. 각 작업에 대한 스윕(배치 크기 2 {16, 32} 및 학습률 2 {1e−5, 2e−5, 3e−5}), 단계의 처음 6%에 대한 선형 준비 후 0으로 선형 감소 10개의 에포크 동안 미세 조정하고 개발 세트에 대한 각 작업의 평가 지표를 기반으로 조기 중지를 수행합니다. 나머지 하이퍼파라미터는 사전 훈련과 동일하게 유지됩니다. 이 설정에서는 모델 앙상블 없이 5번의 무작위 초기화를 통해 각 작업에 대한 중앙값 개발 세트 결과를 보고합니다. 두 번째 설정(앙상블, 테스트)에서는 GLUE 리더보드를 통해 RoBERTa를 테스트 세트의 다른 접근 방식과 비교합니다.
GLUE 리더보드에 제출되는 많은 항목은 다중 작업 미세 조정에 의존하지만 우리의 제출은 단일 작업 미세 조정에만 의존합니다. RTE, STS 및 MRPC의 경우 사전 훈련된 기본 RoBERTa보다는 MNLI 단일 작업 모델에서 시작하여 미세 조정하는 것이 도움이 된다는 것을 알았습니다. 부록에 설명된 약간 더 넓은 하이퍼파라미터 공간을 탐색하고 작업당 5~7개 모델 사이의 앙상블을 탐색합니다.
표 5: GLUE 결과. 모든 결과는 24레이어 아키텍처를 기반으로 합니다. BERTLARGE 및 XLNetLARGE 결과는 Devlin et al. (2019) 및 Yang et al. (2019) 각각. 개발 세트의 RoBERTa 결과는 5회 실행에 대한 중앙값입니다. 테스트 세트의 RoBERTa 결과는 단일 작업 모델의 앙상블입니다. RTE, STS 및 MRPC의 경우 기본 사전 학습 모델 대신 MNLI 모델부터 미세 조정합니다. 평균은 GLUE 순위표에서 얻습니다.
작업별 수정 GLUE 작업 중 두 가지는 경쟁력 있는 리더보드 결과를 달성하기 위해 작업별 미세 조정 접근 방식이 필요합니다.
QNLI: GLUE 순위표에 대한 최근 제출은 QNLI 작업에 대한 쌍별 순위 공식을 채택합니다. 여기서 후보 답변은 훈련 세트에서 마이닝되어 서로 비교되고 단일(질문, 후보) 쌍은 긍정적으로 분류됩니다(Liu et al. al., 2019b,a; Yang 외, 2019). 이 공식은 작업을 크게 단순화하지만 BERT와 직접적으로 비교할 수는 없습니다(Devlin et al., 2019). 최근 작업에 따라 테스트 제출에 순위 지정 접근 방식을 채택했지만 BERT와의 직접 비교를 위해 순수 분류 접근 방식을 기반으로 개발 세트 결과를 보고합니다.
WNLI: 제공된 NLI 형식 데이터가 작업하기 어렵다는 것을 알았습니다. 대신 우리는 쿼리 대명사와 지시 대상의 범위를 나타내는 Super-GLUE(Wang et al., 2019a)의 형식이 변경된 WNLI 데이터를 사용합니다. Kocijan et al. (2019) 의 마진 순위 손실을 사용하여 RoBERTa를 미세 조정합니다. 주어진 입력 문장에 대해 spaCy(Honnibal and Montani, 2017)를 사용하여 문장에서 추가 후보 명사 문구를 추출하고 모델을 미세 조정하여 생성된 부정 후보 문구보다 긍정적 지시 문구에 더 높은 점수를 할당합니다. 이 공식의 불행한 결과 중 하나는 제공된 훈련 예제의 절반 이상을 제외하는 긍정적인 훈련 예제만 사용할 수 있다는 것입니다.
결과 우리는 결과를 표 5에 제시합니다. 첫 번째 설정(단일 작업, 개발)에서 RoBERTa는 9개의 GLUE 작업 개발 세트 모두에서 최첨단 결과를 달성합니다. 결정적으로 RoBERTa는 BERTLARGE와 동일한 마스크된 언어 모델링 사전 학습 목표 및 아키텍처를 사용하면서도 지속적으로 BERTLARGE 및 XLNetLARGE보다 성능이 뛰어납니다. 이는 모델 아키텍처와 사전 학습의 상대적 중요성에 대한 의문을 제기합니다. 이 작업에서 탐색하는 데이터 세트 크기 및 훈련 시간과 같은 보다 일상적인 세부 사항과 비교됩니다. 두 번째 설정(앙상블, 테스트)에서는 RoBERTa를 GLUE 리더보드에 제출하고 9개 작업 중 4개 작업에서 최고 결과와 현재까지 가장 높은 평균 점수를 달성합니다. RoBERTa는 대부분의 다른 상위 제출물과 달리 다중 작업 미세 조정에 의존하지 않기 때문에 특히 흥미롭습니다. 우리는 앞으로의 작업이 더욱 발전할 것으로 기대합니다 보다 정교한 다중 작업 미세 조정 절차를 통합하여 이러한 결과를 개선합니다.
5.2 스쿼드 결과 우리는 이전 작업에 비해 SQuAD에 대해 훨씬 간단한 접근 방식을 채택합니다. 특히 BERT(Devlin et al., 2019)와 XLNet(Yang et al., 2019)은 모두 추가 QA 데이터 세트를 사용하여 교육 데이터를 강화하지만 우리는 미세 조정만 합니다. 제공된 SQuAD 훈련 데이터를 사용하는 RoBERTa. Yang et al.(2019)은 XLNet을 미세 조정하기 위해 사용자 정의 레이어별 학습 속도 일정을 사용했으며 모든 레이어에 동일한 학습 속도를 사용했습니다. SQuAD v1.1의 경우 Devlin et al.(2019)과 동일한 미세 조정 절차를 따릅니다. SQuAD v2.0에서는 주어진 질문에 답변할 수 있는지 여부를 추가로 분류합니다. 분류 및 범위 손실 항을 합산하여 범위 예측기와 함께 이 분류기를 훈련합니다.
표 6: SQuAD 결과. †은 추가 외부 훈련 데이터에 의존하는 결과를 나타냅니다. RoBERTa는 개발 및 테스트 설정 모두에서 제공된 SQuAD 데이터만 사용합니다. BERTLARGE 및 XLNetLARGE 결과는 각각 Devlin et al.(2019) 및 Yang et al.(2019)에서 가져온 것입니다.
결과 우리는 결과를 표 6에 제시합니다. SQuAD v1.1 개발 세트에서 RoBERTa는 XLNet의 최첨단 세트와 일치합니다. SQuAD v2.0 개발 세트에서 RoBERTa는 XLNet에 비해 0.4포인트(EM) 및 0.6포인트(F1) 향상되는 새로운 최첨단 기술을 설정합니다. 또한 공개 SQuAD 2.0 리더보드에 RoBERTa를 제출하고 다른 시스템과 비교하여 성능을 평가합니다. 대부분의 최고 시스템은 BERT(Devlin et al., 2019) 또는 XLNet(Yang et al., 2019)을 기반으로 구축되며, 둘 다 추가 외부 교육 데이터에 의존합니다. 대조적으로, 우리의 제출물은 추가 데이터를 사용하지 않습니다. 우리의 단일 RoBERTa 모델은 단일 모델 제출 중 하나를 제외한 모든 모델보다 성능이 뛰어나며 데이터 증강에 의존하지 않는 모델 중에서 최고 점수 시스템입니다.
5.3 레이스 결과 RACE에서는 시스템에 텍스트 구절, 관련 질문 및 4개의 후보 답변이 제공됩니다. 네 가지 후보 답변 중 어느 것이 올바른지 분류하려면 시스템이 필요합니다. 우리는 각 후보 답변을 해당 질문 및 구절과 연결하여 이 작업을 위해 RoBERTa를 수정합니다. 그런 다음 이 네 가지 시퀀스를 각각 인코딩하고 정답을 예측하는 데 사용되는 완전 연결 레이어를 통해 결과 [CLS] 표현을 전달합니다. 128개 토큰보다 긴 질문-답변 쌍을 자르고 필요한 경우 전체 길이가 최대 512개 토큰이 되도록 통로를 자릅니다. RACE 테스트 세트의 결과는 표 7에 나와 있습니다. RoBERTa는 중학교와 고등학교 환경 모두에서 최첨단 결과를 달성합니다.
표 7: RACE 테스트 세트의 결과. BERTLARGE 및 XLNetLARGE 결과는 Yang et al. (2019).
6 관련 작업 사전 훈련 방법은 언어 모델링(Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018), 기계 번역(McCann et al., 2017), 마스크된 언어 모델링(McCann et al., 2017)을 포함한 다양한 훈련 목표로 설계되었습니다. Devlin 외, 2019; Lample 및 Conneau, 2019). 최근의 많은 논문에서는 각 최종 작업에 대해 모델을 미세 조정하는 기본 방법을 사용했으며(Howard and Ruder, 2018; Radford et al., 2018), 마스크된 언어 모델 목표의 일부 변형을 사용하여 사전 학습했습니다. 그러나 새로운 방법은 다중 작업 미세 조정(Dong et al., 2019), 엔터티 임베딩(Sun et al., 2019), 범위 예측(Joshi et al., 2019) 및 자동 회귀의 여러 변형을 통합하여 성능을 향상했습니다. 사전 훈련(Song et al., 2019; Chan et al., 2019; Yang et al., 2019). 또한 일반적으로 더 많은 데이터에 대해 더 큰 모델을 훈련함으로써 성능이 향상됩니다(Devlin et al., 2019; Baevski et al., 2019; Yang et al., 2019; Radford et al., 2019). 우리의 목표는 이러한 모든 방법의 상대적 성능을 더 잘 이해하기 위한 기준점으로 BERT 교육을 복제, 단순화 및 더 잘 조정하는 것이었습니다.
7 결론 우리는 BERT 모델을 사전 훈련할 때 여러 가지 설계 결정을 신중하게 평가합니다. 우리는 더 많은 데이터에 대해 더 큰 배치를 사용하여 모델을 더 오랫동안 훈련함으로써 성능이 크게 향상될 수 있음을 발견했습니다. 다음 문장 예측 목표를 제거하는 단계; 더 긴 시퀀스에 대한 훈련; 훈련 데이터에 적용된 마스킹 패턴을 동적으로 변경하는 단계를 포함한다. RoBERTa라고 하는 개선된 사전 훈련 절차는 GLUE에 대한 다중 작업 미세 조정이나 SQuAD에 대한 추가 데이터 없이 GLUE, RACE 및 SQuAD에 대한 최첨단 결과를 달성합니다. 이러한 결과는 이전에 간과된 설계 결정의 중요성을 보여주고 BERT의 사전 훈련 목표가 최근 제안된 대안과 경쟁력을 유지하고 있음을 시사합니다. 우리는 또한 새로운 데이터 세트인 CC-NEWS를 사용하고 사전 훈련 및 미세 조정을 위한 모델과 코드를 다음 위치에 공개합니다. https://github.com/pytorch/fairseq
표 8: RoBERTa의 다양한 구성에 대한 GLUE 작업에 대한 개발 세트 결과.
표 9: RoBERTaLARGE 및 RoBERTaBASE 사전 훈련을 위한 하이퍼파라미터.
표 10: RACE, SQuAD 및 GLUE에서 RoBERTaLARGE를 미세 조정하기 위한 하이퍼파라미터.
자연어 이해는 텍스트 수반, 질문 응답, 의미 유사성 평가, 문서 분류 등 광범위한 다양한 작업으로 구성됩니다. 레이블이 지정되지 않은 대규모 텍스트 말뭉치는 풍부하지만 이러한 특정 작업을 학습하기 위한 레이블이 지정된 데이터는 부족하므로 차별적으로 훈련된 모델이 적절하게 수행하기가 어렵습니다. 우리는 레이블이 지정되지 않은 다양한 텍스트 모음에 대한 언어 모델의 생성적 사전 학습과 각 특정 작업에 대한 차별적인 미세 조정을 통해 이러한 작업에 대한 큰 이득을 실현할 수 있음을 보여줍니다. 이전 접근 방식과 달리 모델 아키텍처에 대한 변경을 최소화하면서 효과적인 전송을 달성하기 위해 미세 조정 중에 작업 인식 입력 변환을 사용합니다. 우리는 자연어 이해를 위한 광범위한 벤치마크에서 우리 접근 방식의 효율성을 입증합니다. 우리의 일반적인 작업 불가지론 모델은 각 작업에 맞게 특별히 제작된 아키텍처를 사용하는 차별적으로 훈련된 모델보다 성능이 뛰어나며 연구된 12개 작업 중 9개 작업에서 최첨단 수준을 크게 향상시킵니다. 예를 들어, 상식 추론(Stories Cloze Test)에서 8.9%, 질문 답변(RACE)에서 5.7%, 텍스트 수반(MultiNLI)에서 1.5%의 절대적인 향상을 달성했습니다.
1. 서론
원시 텍스트로부터 효과적으로 학습하는 능력은 자연어 처리(NLP)에서 지도 학습에 대한 의존성을 완화하는 데 매우 중요합니다. 대부분의 딥러닝 방법에는 상당한 양의 수동으로 레이블이 지정된 데이터가 필요하므로 주석이 달린 리소스가 부족한 많은 도메인에서의 적용 가능성이 제한됩니다[61]. 이러한 상황에서 레이블이 지정되지 않은 데이터의 언어 정보를 활용할 수 있는 모델은 시간과 비용이 많이 소요될 수 있는 더 많은 주석을 수집하는 데 대한 귀중한 대안을 제공합니다. 또한 상당한 감독이 가능한 경우에도 감독되지 않은 방식으로 좋은 표현을 학습하면 상당한 성능 향상을 제공할 수 있습니다. 지금까지 이에 대한 가장 설득력 있는 증거는 다양한 NLP 작업[8, 11, 26, 45]의 성능을 향상시키기 위해 사전 훈련된 단어 임베딩[10, 39, 42]을 광범위하게 사용했다는 것입니다.
그러나 레이블이 지정되지 않은 텍스트에서 단어 수준 이상의 정보를 활용하는 것은 두 가지 주요 이유로 어렵습니다. 첫째, 전송에 유용한 텍스트 표현을 학습하는 데 어떤 유형의 최적화 목표가 가장 효과적인지 불분명합니다. 최근 연구에서는 언어 모델링[44], 기계 번역[38], 담화 일관성[22]과 같은 다양한 목표를 조사했으며, 각 방법은 서로 다른 작업에서 다른 방법보다 성능이 뛰어납니다. 둘째, 가장 효과적인 방법에 대한 합의가 없습니다. 학습된 표현을 대상 작업으로 전송합니다. 기존 기술에는 모델 아키텍처에 대한 작업별 변경[43, 44], 복잡한 학습 체계 사용[21] 및 보조 학습 목표 추가[50]의 조합이 포함됩니다. 이러한 불확실성으로 인해 언어 처리를 위한 효과적인 준지도 학습 접근법을 개발하는 것이 어려워졌습니다.
본 논문에서는 비지도 사전 훈련과 지도 미세 조정의 조합을 사용하여 언어 이해 작업에 대한 준지도 접근 방식을 탐구합니다. 우리의 목표는 광범위한 작업에 거의 적응하지 않고 전환되는 보편적인 표현을 배우는 것입니다. 우리는 레이블이 지정되지 않은 대규모 텍스트 모음과 수동으로 주석이 달린 훈련 예제(대상 작업)가 있는 여러 데이터세트에 대한 액세스를 가정합니다. 우리의 설정에서는 이러한 대상 작업이 레이블이 없는 코퍼스와 동일한 도메인에 있을 필요가 없습니다. 우리는 2단계 교육 절차를 사용합니다. 먼저, 레이블이 지정되지 않은 데이터에 대한 언어 모델링 목표를 사용하여 신경망 모델의 초기 매개변수를 학습합니다. 그 후, 해당 감독 목표를 사용하여 이러한 매개 변수를 대상 작업에 적용합니다.
모델 아키텍처의 경우 기계 번역[62], 문서 생성[34] 및 구문 분석[29]과 같은 다양한 작업에서 강력한 성능을 발휘하는 것으로 알려진 Transformer[62]를 사용합니다. 이 모델 선택은 순환 네트워크와 같은 대안에 비해 텍스트의 장기 종속성을 처리하기 위한 보다 구조화된 메모리를 제공하여 다양한 작업 전반에 걸쳐 강력한 전송 성능을 제공합니다. 전송 중에 구조화된 텍스트 입력을 단일 연속 토큰 시퀀스로 처리하는 순회 스타일 접근 방식[52]에서 파생된 작업별 입력 적응을 활용합니다. 실험에서 보여주듯이 이러한 적응을 통해 사전 훈련된 모델의 아키텍처를 최소한으로 변경하면서 효과적으로 미세 조정할 수 있습니다.
우리는 자연어 추론, 질문 응답, 의미 유사성 및 텍스트 분류의 네 가지 유형의 언어 이해 작업에 대한 접근 방식을 평가합니다. 우리의 일반적인 작업 불가지론 모델은 각 작업에 맞게 특별히 제작된 아키텍처를 사용하는 차별적으로 훈련된 모델보다 성능이 뛰어나며 연구된 12개 작업 중 9개 작업에서 최첨단 수준을 크게 향상시킵니다. 예를 들어, 우리는 상식 추론(Stories Cloze Test)[40]에서 8.9%, 질문 답변(RACE)[30]에서 5.7%, 텍스트 수반(MultiNLI)[66]에서 5.5%의 절대적 개선을 달성했습니다. 최근 GLUE 다중 작업 벤치마크를 도입했습니다[64]. 또한 네 가지 다른 설정에서 사전 훈련된 모델의 제로샷 동작을 분석하고 다운스트림 작업에 유용한 언어 지식을 획득한다는 것을 보여주었습니다.
2. 관련 작업
NLP를 위한 준지도 학습 우리의 작업은 대체로 자연어에 대한 준지도 학습 범주에 속합니다. 이 패러다임은 서열 라벨링[24, 33, 57] 또는 텍스트 분류[41, 70]와 같은 작업에 적용되면서 상당한 관심을 끌었습니다. 초기 접근 방식은 레이블이 지정되지 않은 데이터를 사용하여 단어 수준 또는 구문 수준 통계를 계산한 다음 지도 모델의 기능으로 사용했습니다[33]. 지난 몇 년 동안 연구자들은 라벨이 지정되지 않은 말뭉치에 대해 훈련된 단어 임베딩[11, 39, 42]을 사용하여 다양한 작업의 성능을 향상시키는 이점을 입증했습니다[8, 11, 26, 45]. 그러나 이러한 접근 방식은 주로 단어 수준 정보를 전송하는 반면, 우리는 더 높은 수준의 의미를 포착하는 것을 목표로 합니다.
최근 접근 방식에서는 레이블이 지정되지 않은 데이터에서 단어 수준 이상의 의미를 학습하고 활용하는 방법을 조사했습니다. 레이블이 지정되지 않은 코퍼스를 사용하여 훈련할 수 있는 구문 수준 또는 문장 수준 임베딩은 텍스트를 다양한 대상 작업에 적합한 벡터 표현으로 인코딩하는 데 사용되었습니다[28, 32, 1, 36, 22, 12, 56, 31]
비지도 사전 훈련 비지도 사전 훈련은 지도 학습 목표를 수정하는 대신 좋은 초기화 지점을 찾는 것이 목표인 준지도 학습의 특별한 경우입니다. 초기 연구에서는 이미지 분류[20, 49, 63] 및 회귀 작업[3]에서 이 기술의 사용을 탐구했습니다. 후속 연구[15]에서는 사전 훈련이 정규화 방식으로 작용하여 심층 신경망에서 더 나은 일반화가 가능하다는 것을 보여주었습니다. 최근 연구에서 이 방법은 이미지 분류[69], 음성 인식[68], 엔터티 명확화[17] 및 기계 번역[48]과 같은 다양한 작업에서 심층 신경망을 훈련하는 데 도움이 되었습니다.
우리 작업에 가장 가까운 작업 라인은 언어 모델링 목표를 사용하여 신경망을 사전 훈련한 다음 감독을 통해 대상 작업에 맞게 미세 조정하는 것입니다. Daiet al. [13]과 Howard 및 Ruder [21]는 텍스트 분류를 개선하기 위해 이 방법을 따릅니다. 그러나 사전 훈련 단계는 일부 언어 정보를 캡처하는 데 도움이 되지만 LSTM 모델을 사용하면 예측 능력이 짧은 범위로 제한됩니다. 대조적으로, 우리가 선택한 변환기 네트워크를 사용하면 실험에서 입증된 것처럼 더 긴 범위의 언어 구조를 캡처할 수 있습니다. 또한 자연어 추론, 의역 감지, 스토리 완성 등 광범위한 작업에 대한 모델의 효율성도 입증합니다. 다른 접근법[43, 44, 38]은 사전 훈련된 언어 또는 기계 번역 모델의 숨겨진 표현을 보조 기능으로 사용하는 동시에 대상 작업에 대한 지도 모델을 훈련합니다. 여기에는 각각의 개별 대상 작업에 대한 상당한 양의 새로운 매개변수가 포함되는 반면, 전송 중에 모델 아키텍처에 대한 변경은 최소화됩니다.
보조 훈련 목표 보조 비지도 훈련 목표를 추가하는 것은 준지도 학습의 대체 형태입니다. Collobert와 Weston[10]의 초기 작업에서는 의미론적 역할 레이블 지정을 개선하기 위해 POS 태깅, 청킹, 명명된 엔터티 인식 및 언어 모델링과 같은 다양한 보조 NLP 작업을 사용했습니다. 최근 Rei [50]는 목표 작업 목표에 보조 언어 모델링 목표를 추가하고 시퀀스 레이블링 작업에서 성능 향상을 입증했습니다. 우리의 실험은 또한 보조 목표를 사용하지만, 우리가 보여주듯이 감독되지 않은 사전 훈련은 이미 목표 작업과 관련된 여러 언어적 측면을 학습합니다.
3 프레임워크
우리의 훈련 절차는 두 단계로 구성됩니다. 첫 번째 단계는 대규모 텍스트 모음에서 대용량 언어 모델을 학습하는 것입니다. 그 다음에는 레이블이 지정된 데이터를 사용하여 식별 작업에 모델을 적용하는 미세 조정 단계가 이어집니다.
3.1 감독되지 않은 사전 훈련
감독되지 않은 토큰 코퍼스 U = {u1, . . . , un}, 표준 언어 모델링 목표를 사용하여 다음 가능성을 최대화합니다.
여기서 k는 컨텍스트 창의 크기이고 조건부 확률 P는 매개변수 Θ가 있는 신경망을 사용하여 모델링됩니다. 이러한 매개변수는 확률적 경사 하강법을 사용하여 훈련됩니다[51].
우리 실험에서는 언어 모델로 Transformer [62]의 변형인 다층 Transformer 디코더 [34]를 사용했습니다. 이 모델은 입력 컨텍스트 토큰에 대해 다중 방향 self-attention 작업을 적용한 다음 위치별 피드포워드 레이어를 적용하여 대상 토큰에 대한 출력 분포를 생성합니다.
여기서 U = (u-k,...,u-1)은 토큰의 컨텍스트 벡터이고, n은 레이어 수, We는 토큰 임베딩 행렬, Wp는 위치 임베딩 행렬입니다.
3.2 감독된 미세 조정
"Eq. 1"의 목표를 사용하여 모델을 훈련한 후 감독 대상 작업에 매개변수를 적용합니다. 각 인스턴스가 레이블 y와 함께 일련의 입력 토큰 "x1, . . . , xm"으로 구성되는 레이블이 지정된 데이터 세트 C를 가정합니다. 입력은 사전 훈련된 모델을 통해 전달되어 최종 변환기 블록의 활성화 hl^m을 얻은 다음 y를 예측하기 위해 매개변수 Wy가 있는 추가 선형 출력 레이어에 공급됩니다.
이는 우리에게 다음과 같은 최대화 목표를 제공합니다.
또한 우리는 미세 조정에 대한 보조 목표로 언어 모델링을 포함시키는 것이 (a) 지도 모델의 일반화를 개선하고 (b) 수렴을 가속화함으로써 학습에 도움이 된다는 것을 발견했습니다. 이는 이러한 보조 목적으로 향상된 성능을 관찰한 이전 연구[50, 43]와 일치합니다. 구체적으로 다음 목표를 최적화합니다(가중치 λ 사용).
전반적으로 미세 조정 중에 필요한 유일한 추가 매개변수는 Wy와 구분 기호 토큰에 대한 임베딩입니다(아래 섹션 3.3에서 설명).
그림 1: (왼쪽) 이 작업에 사용된 Transformer 아키텍처 및 교육 목표. (오른쪽) 다양한 작업의 미세 조정을 위한 입력 변환. 모든 구조화된 입력을 토큰 시퀀스로 변환하여 사전 학습된 모델에서 처리한 다음 선형+소프트맥스 레이어를 처리합니다.
3.3 작업별 입력 변환
텍스트 분류와 같은 일부 작업의 경우 위에서 설명한 대로 모델을 직접 미세 조정할 수 있습니다. 질문 답변 또는 텍스트 수반과 같은 특정 작업에는 순서가 지정된 문장 쌍 또는 문서, 질문 및 답변의 세 쌍과 같은 구조화된 입력이 있습니다. 사전 훈련된 모델 이후 연속된 텍스트 시퀀스에 대해 학습되었으므로 이러한 작업에 적용하려면 몇 가지 수정이 필요합니다. 이전 연구에서는 전송된 표현 위에 학습 작업별 아키텍처를 제안했습니다[44]. 이러한 접근 방식은 상당한 양의 작업별 사용자 정의를 다시 도입하고 이러한 추가 아키텍처 구성 요소에 대해 전이 학습을 사용하지 않습니다. 대신에 우리는 구조화된 입력을 사전 훈련된 모델이 처리할 수 있는 순서가 지정된 시퀀스로 변환하는 순회 스타일 접근 방식[52]을 사용합니다. 이러한 입력 변환을 통해 작업 전반에 걸쳐 아키텍처를 광범위하게 변경하는 것을 피할 수 있습니다. 아래에서는 이러한 입력 변환에 대한 간략한 설명을 제공하며 그림 1은 시각적 설명을 제공합니다. 모든 변환에는 무작위로 초기화된 시작 및 종료 토큰(<s>, <e>) 추가가 포함됩니다.
텍스트 수반 수반 작업의 경우 전제 p와 가설 h 토큰 시퀀스를 사이에 구분 기호 토큰($)을 사용하여 연결합니다.
유사성 유사성 작업의 경우 비교되는 두 문장의 고유한 순서가 없습니다. 이를 반영하기 위해 입력 시퀀스를 수정하여 가능한 문장 순서(사이에 구분 기호 포함)를 모두 포함하고 각각을 독립적으로 처리하여 선형 출력 레이어에 공급되기 전에 요소별로 추가되는 두 개의 시퀀스 표현 hl^m을 생성합니다.
질문 응답 및 상식 추론 이러한 작업을 위해 컨텍스트 문서 z, 질문 q 및 가능한 답변 세트 {ak}가 제공됩니다. 문서 컨텍스트와 질문을 가능한 각 답변과 연결하고 그 사이에 구분 기호 토큰을 추가하여 [z; q; $; ak]. 이러한 각 시퀀스는 모델과 독립적으로 처리된 다음 소프트맥스 레이어를 통해 정규화되어 가능한 답변에 대한 출력 분포를 생성합니다.
4 실험
4.1 설정
감독되지 않은 사전 훈련 우리는 언어 모델 훈련을 위해 BooksCorpus 데이터 세트 [71]를 사용합니다. 모험, 판타지, 로맨스 등 다양한 장르의 독특한 미출판 도서 7,000권이 포함되어 있습니다. 결정적으로, 여기에는 긴 연속 텍스트가 포함되어 있어 생성 모델이 장거리 정보를 조건으로 하는 방법을 학습할 수 있습니다. 비슷한 접근 방식인 ELMo[44]에서 사용되는 대체 데이터 세트인 1B Word Benchmark는 크기는 거의 같지만 문장 수준에서 섞이므로 장거리 구조가 파괴됩니다. 우리의 언어 모델은 이 코퍼스에서 18.4라는 매우 낮은 토큰 수준의 혼란을 달성합니다.
표 1: 실험에 사용된 다양한 작업 및 데이터 세트 목록
모델 사양 우리 모델은 원래의 변압기 작업을 크게 따랐습니다[62]. 우리는 마스크된 self-attention 헤드(768차원 상태 및 12개 attention 헤드)가 있는 12층 디코더 전용 변환기를 훈련했습니다. 위치별 피드포워드 네트워크의 경우 3072차원 내부 상태를 사용했습니다. 우리는 최대 학습률이 2.5e-4인 Adam 최적화 체계 [27]를 사용했습니다. 학습률은 처음 2000번의 업데이트 동안 0에서 선형적으로 증가했으며 코사인 일정을 사용하여 0으로 어닐링되었습니다. 무작위로 샘플링된 64개의 미니배치, 512개 토큰의 연속 시퀀스에 대해 100세대 동안 훈련합니다. layernorm [2]는 모델 전반에 걸쳐 광범위하게 사용되므로 N(0, 0.02)의 간단한 가중치 초기화로 충분합니다. 우리는 정규화를 위해 40,000개의 병합[53]과 잔여, 임베딩 및 주의 드롭아웃 비율이 0.1인 바이트쌍 인코딩(BPE) 어휘를 사용했습니다. 우리는 또한 모든 비편향 또는 이득 가중치에 대해 w = 0.01인 [37]에서 제안된 L2 정규화의 수정된 버전을 사용했습니다. 활성화 함수로는 GELU(Gaussian Error Linear Unit)[18]를 사용했습니다. 우리는 원래 작업에서 제안된 정현파 버전 대신 학습된 위치 임베딩을 사용했습니다. 우리는 ftfy 라이브러리를 사용하여 BooksCorpus의 원시 텍스트를 정리하고 일부 구두점과 공백을 표준화하며 spaCy 토크나이저를 사용합니다.
세부 조정 지정하지 않는 한, 감독되지 않은 사전 훈련의 하이퍼파라미터 설정을 재사용합니다. 0.1의 비율로 분류기에 드롭아웃을 추가합니다. 대부분의 작업에 대해 우리는 6.25e-5의 학습률과 32의 배치 크기를 사용합니다. 우리의 모델은 빠르게 미세 조정되었으며 대부분의 경우 3번의 훈련으로 충분했습니다. 훈련의 0.2%가 넘는 워밍업이 포함된 선형 학습률 감소 일정을 사용합니다. λ는 0.5로 설정되었습니다.
4.2 감독된 미세 조정
자연어 추론, 질문 답변, 의미 유사성, 텍스트 분류 등 다양한 지도 작업에 대한 실험을 수행합니다. 이러한 작업 중 일부는 우리가 활용하는 최근 출시된 GLUE 다중 작업 벤치마크[64]의 일부로 제공됩니다. 그림 1은 모든 작업과 데이터 세트의 개요를 제공합니다.
자연어 추론 텍스트 수반 인식이라고도 알려진 자연어 추론(NLI) 작업에는 한 쌍의 문장을 읽고 수반, 모순 또는 중립 중 하나에서 문장 간의 관계를 판단하는 작업이 포함됩니다. 최근 많은 관심이 있었지만 [58, 35, 44], 어휘 수반, 상호 참조, 어휘 및 구문 모호성과 같은 다양한 현상이 존재하기 때문에 작업은 여전히 어려운 과제입니다. 우리는 이미지 캡션(SNLI), 전사된 연설, 대중 소설, 정부 보고서(MNLI), Wikipedia 기사(QNLI), 과학 시험(SciTail) 또는 뉴스 기사(RTE)를 포함한 다양한 소스를 갖춘 5개의 데이터 세트를 평가합니다.
표 2는 우리 모델과 이전의 최첨단 접근 방식에 대한 다양한 NLI 작업에 대한 다양한 결과를 자세히 설명합니다. 우리의 방법은 5개 데이터 세트 중 4개에 대한 기준보다 훨씬 뛰어난 성능을 발휘하여 이전 최고 결과에 비해 MNLI에서 최대 1.5%, SciTail에서 5%, QNLI에서 5.8%, SNLI에서 0.6%의 절대적인 개선을 달성했습니다. 이는 여러 문장에 대해 더 나은 추론을 수행하고 언어적 모호함의 측면을 처리하는 모델의 능력을 보여줍니다. 우리가 평가하는 소규모 데이터세트 중 하나인 RTE(예제 2490개)에서는 56%의 정확도를 달성했는데, 이는 다중 작업 biLSTM 모델에서 보고한 61.7%보다 낮습니다. 더 큰 NLI 데이터 세트에 대한 우리 접근 방식의 강력한 성능을 고려할 때 우리 모델은 다중 작업 훈련에서도 이점을 얻을 가능성이 높지만 현재는 이에 대해 조사하지 않았습니다.
표 2: 자연어 추론 작업에 대한 실험 결과, 우리 모델을 현재 최첨단 방법과 비교합니다. 5x는 5개 모델의 앙상블을 나타냅니다. 모든 데이터 세트는 정확도를 평가 지표로 사용합니다.
표 3: 우리 모델과 현재의 최신 방법을 비교한 질문 답변 및 상식 추론 결과. 9x는 9개 모델의 앙상블을 의미합니다.
질문 응답 및 상식 추론 단일 및 다중 문장 추론 측면이 필요한 또 다른 작업은 질문 응답입니다. 우리는 중학교 및 고등학교 시험과 관련된 질문이 있는 영어 지문으로 구성된 최근 발표된 RACE 데이터세트[30]를 사용합니다. 이 코퍼스에는 CNN[19] 또는 SQuaD[47]와 같은 다른 데이터 세트보다 더 많은 추론 유형 질문이 포함되어 장거리 컨텍스트를 처리하도록 훈련된 모델에 대한 완벽한 평가를 제공하는 것으로 나타났습니다. 또한 두 가지 옵션 중에서 여러 문장으로 구성된 이야기의 올바른 결말을 선택하는 Story Cloze Test[40]를 평가합니다. 이러한 작업에서 우리 모델은 Story Cloze에서 최대 8.9%, RACE에서 전체 5.7%의 상당한 마진으로 이전의 최고 결과를 다시 능가합니다. 이는 장거리 상황을 효과적으로 처리하는 모델의 능력을 보여줍니다.
의미 유사성 의미 유사성(또는 의역 감지) 작업에는 두 문장이 의미상 동일한지 여부를 예측하는 작업이 포함됩니다. 문제는 개념의 변경을 인식하고, 부정을 이해하고, 구문적 모호성을 처리하는 데 있습니다. 이 작업에는 MRPC(Microsoft Paraphrase corpus)[14](뉴스 소스에서 수집), QQP(Quora Question 쌍) 데이터 세트[9] 및 STS-B(의미적 텍스트 유사성 벤치마크)의 세 가지 데이터 세트를 사용합니다. 우리는 STS-B에서 1포인트 절대 이득을 사용하여 세 가지 의미 유사성 작업 중 두 가지(표 4)에 대한 최첨단 결과를 얻었습니다. QQP의 성능 차이는 상당하며 단일 작업 BiLSTM + ELMo + Attn에 비해 4.2% 절대적인 향상이 있습니다.
분류 마지막으로 두 가지 다른 텍스트 분류 작업에 대해서도 평가합니다. CoLA(언어적 수용성 코퍼스) [65]에는 문장이 문법적인지 여부에 대한 전문가 판단이 포함되어 있으며 훈련된 모델의 타고난 언어적 편향을 테스트합니다. 반면에 Stanford Sentiment Treebank(SST-2)[54]는 표준 이진 분류 작업입니다. 우리 모델은 CoLA에서 45.4점을 얻었는데, 이는 이전의 최고 결과인 35.0보다 특히 큰 도약으로, 우리 모델이 학습한 타고난 언어적 편견을 보여줍니다. 이 모델은 SST-2에서도 91.3%의 정확도를 달성해 최첨단 결과와 경쟁력을 갖췄다. 또한 GLUE 벤치마크에서 전체 점수 72.8점을 달성했는데, 이는 이전 최고 점수인 68.9점보다 훨씬 향상된 수치입니다.
표 4: 우리 모델을 현재 최첨단 방법과 비교한 의미론적 유사성 및 분류 결과. 이 표의 모든 작업 평가는 GLUE 벤치마크를 사용하여 수행되었습니다. (mc= 매튜스 상관관계, acc=정확도, pc=피어슨 상관관계)
전반적으로 우리의 접근 방식은 평가 대상인 12개 데이터 세트 중 9개에서 새로운 최첨단 결과를 달성했으며 많은 경우 앙상블보다 뛰어난 성능을 보였습니다. 우리의 결과는 또한 우리의 접근 방식이 STS-B(5.7k 훈련 예제)와 같은 작은 데이터 세트부터 가장 큰 SNLI(550k 훈련 예제)에 이르기까지 다양한 크기의 데이터 세트에서 잘 작동한다는 것을 나타냅니다.
5 분석
전송된 레이어 수의 영향 우리는 감독되지 않은 사전 훈련에서 감독된 대상 작업으로 다양한 수의 레이어를 전송하는 것의 영향을 관찰했습니다. 그림 2(왼쪽)는 전송된 레이어 수에 따른 MultiNLI 및 RACE 접근 방식의 성능을 보여줍니다. 우리는 임베딩을 전송하면 성능이 향상되고 각 변환기 레이어는 MultiNLI의 전체 전송에 대해 최대 9%의 추가 이점을 제공한다는 표준 결과를 관찰했습니다. 이는 사전 훈련된 모델의 각 계층에 목표 작업을 해결하는 데 유용한 기능이 포함되어 있음을 나타냅니다.
그림 2: (왼쪽) RACE 및 MultiNLI에 대한 사전 학습된 언어 모델에서 점점 더 많은 수의 레이어를 전송하는 효과. (오른쪽) LM 사전 훈련 업데이트의 기능으로 다양한 작업에서 제로샷 성능의 진화를 보여주는 플롯. 작업당 성능은 단일 모델을 사용하여 무작위 추측 기준과 현재 최첨단 사이에서 정규화됩니다.
제로샷 동작 우리는 변환기의 언어 모델 사전 훈련이 효과적인 이유를 더 잘 이해하고 싶습니다. 가설은 기본 생성 모델이 언어 모델링 기능을 향상시키기 위해 우리가 평가하는 많은 작업을 수행하는 방법을 학습하고 변환기의 보다 구조화된 주의 기억이 LSTM에 비해 전송을 지원한다는 것입니다. 우리는 감독된 미세 조정 없이 작업을 수행하기 위해 기본 생성 모델을 사용하는 일련의 경험적 솔루션을 설계했습니다. 우리는 그림 2(오른쪽)에서 생성적 사전 훈련 과정에서 이러한 경험적 솔루션의 효율성을 시각화합니다. 우리는 이러한 경험적 방법의 성능이 훈련에 비해 안정적이고 꾸준히 증가한다는 것을 관찰했습니다. 이는 생성적 사전 훈련이 다양한 작업 관련 기능의 학습을 지원한다는 것을 시사합니다. 또한 LSTM이 제로 샷 성능에서 더 높은 분산을 나타내는 것을 관찰했는데, 이는 Transformer 아키텍처의 유도 바이어스가 전송을 돕는다는 것을 의미합니다.
표 5: 다양한 작업에 대한 다양한 모델 절제 분석. 평균 점수는 모든 결과의 비가중 평균입니다. (mc= 매튜스 상관관계, acc=정확도, pc=피어슨 상관관계)
CoLA(언어적 수용성)의 경우 예제는 생성 모델이 할당하는 평균 토큰 로그 확률로 점수가 매겨지고 예측은 임계값에 의해 이루어집니다. SST-2(감정 분석)의 경우 각 예에 토큰을 매우 추가하고 언어 모델의 출력 분포를 긍정적이고 부정적인 단어로만 제한하고 더 높은 확률을 예측으로 할당하는 토큰을 추측합니다. RACE(질문 응답)의 경우 생성 모델이 문서 및 질문에 대해 조건을 지정할 때 가장 높은 평균 토큰 로그 확률을 할당하는 답변을 선택합니다. DPRD [46](winograd 스키마)의 경우, 우리는 명확한 대명사를 두 개의 가능한 참조로 대체하고 생성 모델이 대체 후 나머지 시퀀스에 더 높은 평균 토큰 로그 확률을 할당하는 해결 방법을 예측합니다.
절제 연구 우리는 세 가지 다른 절제 연구를 수행합니다(표 5). 먼저, 미세 조정 중에 보조 LM 대물렌즈 없이 방법의 성능을 검사합니다. 우리는 보조 목표가 NLI 작업과 QQP에 도움이 된다는 것을 관찰합니다. 전반적으로 추세는 더 큰 데이터 세트가 보조 목표의 이점을 누리지만 더 작은 데이터 세트는 그렇지 않다는 것을 시사합니다. 둘째, 동일한 프레임워크를 사용하는 단일 레이어 2048 단위 LSTM과 비교하여 Transformer의 효과를 분석합니다. Transformer 대신 LSTM을 사용할 때 평균 점수가 5.6 하락하는 것을 관찰했습니다. LSTM은 MRPC라는 하나의 데이터세트에서만 Transformer보다 성능이 뛰어납니다. 마지막으로 사전 훈련 없이 지도 대상 작업에 대해 직접 훈련된 변환기 아키텍처와도 비교합니다. 사전 훈련이 부족하면 모든 작업에서 성능이 저하되어 전체 모델에 비해 14.8% 감소하는 것으로 나타났습니다.
6 결론
우리는 생성적 사전 훈련과 차별적인 미세 조정을 통해 단일 작업 불가지론 모델로 강력한 자연어 이해를 달성하기 위한 프레임워크를 도입했습니다. 긴 연속 텍스트가 포함된 다양한 코퍼스에 대한 사전 훈련을 통해 우리 모델은 중요한 세계 지식과 장거리 종속성을 처리할 수 있는 능력을 습득한 다음 질문 답변, 의미 유사성 평가, 수반 결정, 텍스트 분류를 통해 우리가 연구하는 12개 데이터 세트 중 9개에 대한 최신 기술을 개선했습니다. 감독되지 않은 (사전) 훈련을 사용하여 판별 작업의 성능을 높이는 것은 오랫동안 기계 학습 연구의 중요한 목표였습니다. 우리의 연구는 상당한 성능 향상을 달성하는 것이 실제로 가능하다는 것을 시사하고 이 접근 방식에 가장 적합한 모델(변환기) 및 데이터 세트(장거리 종속성이 있는 텍스트)에 대한 힌트를 제공합니다. 우리는 이것이 자연어 이해 및 기타 영역 모두에 대한 비지도 학습에 대한 새로운 연구를 가능하게 하고 비지도 학습이 언제 어떻게 작동하는지에 대한 이해를 더욱 향상시키는 데 도움이 되기를 바랍니다.
신경 기계 번역은 최근 제안된 기계 번역 접근 방식입니다. 기존의 통계적 기계 번역과 달리 신경 기계 번역은 번역 성능을 극대화하기 위해 공동으로 조정될 수 있는 단일 신경망 구축을 목표로 합니다. 신경 기계 번역을 위해 최근 제안된 모델은 종종 인코더-디코더 제품군에 속하며 디코더가 번역을 생성하는 고정 길이 벡터로 소스 문장을 인코딩합니다. 본 논문에서 우리는 고정 길이 벡터의 사용이 이 기본 인코더-디코더 아키텍처의 성능을 향상시키는 데 병목 현상이 된다고 추측하고 모델이 부품을 자동으로 (소프트) 검색하도록 허용하여 이를 확장할 것을 제안합니다. 이러한 부분을 명시적으로 하드 세그먼트로 구성할 필요 없이 타겟 단어 예측과 관련된 소스 문장을 생성합니다. 이 새로운 접근 방식을 통해 우리는 영어-프랑스어 번역 작업에 대해 기존의 최첨단 구문 기반 시스템에 필적하는 번역 성능을 달성합니다. 더욱이, 정성적 분석은 모델에서 발견된 (소프트) 정렬이 우리의 직관과 잘 일치한다는 것을 보여줍니다.
1. 서론
신경 기계 번역은 최근 Kalchbrenner 및 Blunsom(2013), Sutskever 등이 제안한 기계 번역에 대한 새롭게 떠오르는 접근 방식입니다. (2014) 및 Cho et al. (2014b). 개별적으로 조정되는 많은 작은 하위 구성요소로 구성된 전통적인 구문 기반 번역 시스템(예: Koehn et al., 2003 참조)과 달리 신경 기계 번역은 다음을 읽는 단일의 대규모 신경망을 구축하고 훈련하려고 시도합니다. 문장을 출력하고 올바른 번역을 출력합니다.
제안된 신경 기계 번역 모델의 대부분은 각 언어에 대한 인코더와 디코더가 있는 인코더-디코더 제품군(Sutskever et al., 2014; Cho et al., 2014a)에 속하거나 언어별 번역을 포함합니다. 출력이 비교되는 각 문장에 인코더가 적용됩니다(Hermann 및 Blunsom, 2014). 인코더 신경망은 소스 문장을 읽고 고정 길이 벡터로 인코딩합니다. 그런 다음 디코더는 인코딩된 벡터에서 번역을 출력합니다. 언어 쌍에 대한 인코더와 디코더로 구성된 전체 인코더-디코더 시스템은 주어진 소스 문장에서 올바른 번역의 확률을 최대화하도록 공동으로 훈련됩니다.
이 인코더-디코더 접근 방식의 잠재적인 문제는 신경망이 소스 문장의 모든 필수 정보를 고정 길이 벡터로 압축할 수 있어야 한다는 것입니다. 이로 인해 신경망이 긴 문장, 특히 훈련 코퍼스의 문장보다 긴 문장에 대처하기 어려울 수 있습니다. Cho et al. (2014b)은 입력 문장의 길이가 길어질수록 기본 인코더-디코더의 성능이 급격히 저하되는 것을 보여주었습니다.
이 문제를 해결하기 위해 공동으로 정렬하고 변환하는 방법을 학습하는 인코더-디코더 모델의 확장을 도입합니다. 제안된 모델은 번역에서 단어를 생성할 때마다 원본 문장에서 가장 관련성이 높은 정보가 집중된 위치 집합을 (소프트) 검색합니다. 그런 다음 모델은 이러한 소스 위치 및 이전에 생성된 모든 대상 단어와 관련된 컨텍스트 벡터를 기반으로 대상 단어를 예측합니다.
기본 인코더-디코더와 이 접근 방식의 가장 중요한 차이점은 전체 입력 문장을 단일 고정 길이 벡터로 인코딩하려고 시도하지 않는다는 것입니다. 대신, 입력 문장을 일련의 벡터로 인코딩하고 번역을 디코딩하는 동안 적응적으로 이러한 벡터의 하위 집합을 선택합니다. 이를 통해 신경 번역 모델은 길이에 관계없이 원본 문장의 모든 정보를 고정 길이 벡터로 압축할 필요가 없습니다. 우리는 이것이 모델이 긴 문장에 더 잘 대처할 수 있음을 보여줍니다.
본 논문에서는 제안된 정렬 및 변환 공동 학습 접근 방식이 기본 인코더-디코더 접근 방식에 비해 번역 성능이 크게 향상되었음을 보여줍니다. 개선 효과는 긴 문장에서 더 분명하게 나타나지만 어떤 길이의 문장에서도 관찰할 수 있습니다. 영어-프랑스어 번역 작업에서 제안된 접근 방식은 단일 모델을 사용하여 기존 구문 기반 시스템과 비슷하거나 유사한 번역 성능을 달성합니다. 또한, 질적 분석을 통해 제안된 모델이 원본 문장과 해당 대상 문장 사이에 언어적으로 그럴듯한 (연성) 정렬을 찾는 것으로 나타났습니다.
2. 배경 : 신경 기계 번역
확률론적 관점에서 번역은 소스 문장 x가 주어졌을 때 y의 조건부 확률을 최대화하는 목표 문장 y, 즉 arg maxy p(y | x)를 찾는 것과 동일합니다. 신경 기계 번역에서는 병렬 훈련 코퍼스를 사용하여 문장 쌍의 조건부 확률을 최대화하기 위해 매개변수화된 모델을 적합합니다. 번역 모델에 의해 조건부 분포가 학습되면, 소스 문장이 주어지면 조건부 확률이 최대화되는 문장을 검색하여 해당 번역이 생성될 수 있습니다.
최근 많은 논문에서 이러한 조건 분포를 직접 학습하기 위해 신경망을 사용할 것을 제안했습니다(예: Kalchbrenner 및 Blunsom, 2013; Cho et al., 2014a; Sutskever et al., 2014; Cho et al. , 2014b, Forcada 및 Neco, 1997). 이 신경 기계 번역 접근 방식은 일반적으로 두 가지 구성 요소로 구성됩니다. 첫 번째 구성 요소는 소스 문장 x를 인코딩하고 두 번째 구성 요소는 대상 문장 y로 디코딩합니다. 예를 들어 Cho et al., 2014a와 Sutskever et al., 2014에서는 두 개의 순환 신경망(RNN)을 사용하여 가변 길이 소스 문장을 고정 길이 벡터로 인코딩하고 벡터를 가변 길이 목표 문장.
상당히 새로운 접근 방식임에도 불구하고 신경 기계 번역은 이미 유망한 결과를 보여주었습니다. Sutskeveret al. (2014)는 장단기 기억(LSTM) 단위를 갖춘 RNN을 기반으로 한 신경 기계 번역이 영어-프랑스어 번역에서 기존 구문 기반 기계 번역 시스템의 SOTA 성능에 가까운 성능을 달성했다고 보고했습니다. 번역 작업.1 예를 들어 구문 테이블에서 구문 쌍의 점수를 매기거나(Cho et al., 2014a) 후보 번역의 순위를 다시 지정하기 위해(Sutskever et al., 2014) 기존 번역 시스템에 신경 구성 요소를 추가하면 다음이 가능해졌습니다. 이전의 SOTA 성능 수준을 능가합니다.
2.1 RNN 인코더-디코더
여기에서는 Cho et al.이 제안한 RNN Encoder-Decoder라는 기본 프레임워크를 간략하게 설명합니다. (2014a) 및 Sutskever et al. (2014) 이를 바탕으로 정렬과 번역을 동시에 학습하는 새로운 아키텍처를 구축했습니다. 인코더-디코더 프레임워크에서 인코더는 입력 문장, 즉 일련의 벡터 x = (x1 , · · · , xTx )를 벡터 c로 읽어옵니다. 가장 일반적인 접근 방식은 다음과 같이 RNN을 사용하는 것입니다.
여기서 ht ∈ Rn은 시간 t에서의 숨겨진 상태이고, c는 숨겨진 상태의 시퀀스에서 생성된 벡터입니다. f와 q는 일부 비선형 함수입니다. Sutskeveret al. (2014)는 예를 들어 LSTM을 f 및 q ({h1 , · · · , hT }) = hT 로 사용했습니다.
디코더는 컨텍스트 벡터 c와 이전에 예측된 모든 단어 {y1 , · · · , yt −1 }가 주어지면 다음 단어 yt를 예측하도록 훈련되는 경우가 많습니다. 즉, 디코더는 결합 확률을 순서가 지정된 조건문으로 분해하여 변환 y에 대한 확률을 정의합니다.
여기서 y = y1 , · · · , yTy 입니다. RNN을 사용하면 각 조건부 확률은 다음과 같이 모델링됩니다.
여기서 g는 yt의 확률을 출력하는 비선형, 잠재적으로 다중 계층 함수이고, st는 RNN의 숨겨진 상태입니다. RNN과 de-convolutional 신경망의 하이브리드와 같은 다른 아키텍처를 사용할 수 있다는 점에 유의해야 합니다. (Kalchbrenner 및 Blunsom, 2013).
3. 정렬 및 번역 학습
이 섹션에서는 신경 기계 번역을 위한 새로운 아키텍처를 제안합니다. 새로운 아키텍처는 인코더(Sec. 3.2)인 양방향 RNN과 번역을 디코딩하는 동안 소스 문장을 통한 검색을 에뮬레이트하는 디코더(Sec. 3.1)로 구성됩니다.
3.1 디코더: 일반 설명
새로운 모델 아키텍처에서 우리는 Eq.에서 각 조건부 확률을 정의합니다. (2) 다음과 같이:
여기서 si는 시간 i에 대한 RNN 숨겨진 상태이며 다음과 같이 계산됩니다.
그림 1: 주어진 소스 문장(x1, x2, ..., xT)에서 t번째 대상 단어 yt를 생성하려고 시도하는 제안 모델의 그래픽 설명입니다.
기존 인코더-디코더 접근 방식(Eq. (2) 참조)과 달리 여기서 확률은 각 대상 단어 yi에 대해 고유한 컨텍스트 벡터 ci에 따라 조건이 지정됩니다.
컨텍스트 벡터 ci는 인코더가 입력 문장을 매핑하는 주석 시퀀스(h1 , · · · , hTx )에 따라 달라집니다. 각 주석 hi에는 입력 시퀀스의 i번째 단어를 둘러싼 부분에 중점을 두고 전체 입력 시퀀스에 대한 정보가 포함됩니다. 다음 섹션에서 주석이 어떻게 계산되는지 자세히 설명합니다.
그런 다음 컨텍스트 벡터 ci는 다음 주석 hi의 가중 합계로 계산됩니다
각 주석 hj의 가중치 αij는 다음과 같이 계산됩니다
위치 j 주변의 입력과 위치 i의 출력이 얼마나 잘 일치하는지 점수를 매기는 정렬 모델입니다. 점수는 RNN 숨겨진 상태 si−1(yi를 방출하기 직전, 식(4))과 입력 문장의 j번째 주석 hj를 기반으로 합니다.
우리는 정렬 모델 a를 제안된 시스템의 다른 모든 구성 요소와 공동으로 훈련되는 피드포워드 신경망으로 매개변수화합니다. 전통적인 기계 번역과 달리 정렬은 잠재 변수로 간주되지 않습니다. 대신 정렬 모델은 소프트 정렬을 직접 계산하여 비용 함수의 기울기를 역전파할 수 있습니다. 이 그래디언트는 정렬 모델뿐만 아니라 전체 번역 모델을 공동으로 훈련하는 데 사용될 수 있습니다.
예상되는 정렬이 예상되는 주석을 계산하는 것처럼 모든 주석의 가중 합계를 취하는 접근 방식을 이해할 수 있습니다. αij를 대상 단어 yi가 소스 단어 xj에 정렬되거나 소스 단어에서 번역될 확률로 설정합니다. 그러면 i번째 컨텍스트 벡터 ci는 확률이 αij인 모든 주석에 대해 예상되는 주석입니다.
확률 αij 또는 관련 에너지 eij는 다음 상태 si를 결정하고 yi를 생성할 때 이전 숨겨진 상태 si−1에 대한 주석 hj의 중요성을 반영합니다. 직관적으로 이는 디코더에서 주목 메커니즘을 구현합니다. 디코더는 주의를 기울일 원본 문장의 부분을 결정합니다. 디코더에 어텐션 메커니즘을 부여함으로써 소스 문장의 모든 정보를 고정 길이 벡터로 인코딩해야 하는 부담에서 인코더를 덜어줍니다. 이 새로운 접근 방식을 사용하면 정보가 주석 시퀀스 전체에 분산될 수 있으며 이에 따라 디코더가 이를 선택적으로 검색할 수 있습니다.
3.2 인코더: 주석 시퀀스를 위한 양방향 RNN
반적인 RNN은 Eq. (1)은 첫 번째 기호 x1부터 마지막 기호 xTx까지 순서대로 입력 시퀀스 x를 읽습니다. 그러나 제안된 방식에서는 각 단어의 주석을 통해 앞의 단어뿐만 아니라 뒤따르는 단어도 요약하기를 원합니다. 따라서, 우리는 최근 음성 인식에 성공적으로 사용된 양방향 RNN(BiRNN, Schuster and Paliwal, 1997)을 사용할 것을 제안합니다(예: Graves et al., 2013 참조).
우리는 순방향 은닉 상태 hj →와 역방향 은닉 상태 hj←를 연결하여 각 단어 xj에 대한 주석을 얻습니다. 즉, hj =htj→; htj←. 이러한 방식으로 주석 hj에는 이전 단어와 다음 단어의 요약이 모두 포함됩니다. RNN이 최근 입력을 더 잘 나타내는 경향으로 인해 주석 hj는 xj 주변의 단어에 초점을 맞춥니다. 이 주석 시퀀스는 디코더와 정렬 모델이 나중에 컨텍스트 벡터를 계산하는 데 사용됩니다(Eqs. (5)-(6)).
제안된 모델의 그래픽 설명은 그림 1을 참조하세요.
4. 실험 설정
우리는 영어-프랑스어 번역 작업에 대해 제안된 접근 방식을 평가합니다. 우리는 ACL WMT ’14.3에서 제공하는 이중 언어, 병렬 말뭉치를 사용합니다. 비교를 위해 최근 Cho et al.(2014a)이 제안한 RNN 인코더-디코더의 성능도 보고합니다. 우리는 두 모델 모두에 대해 동일한 훈련 절차와 동일한 데이터 세트를 사용합니다.
4 .1 데이터 세트
WMT ’14에는 Europarl(6100만 단어), 뉴스 논평(550만 단어), UN(421M), 각각 9천만 단어와 2억 7250만 단어로 구성된 두 개의 크롤링된 말뭉치(총 850M 단어)가 포함됩니다. Cho et al.(2014a)에서 설명한 절차에 따라 Axelrod et al.(2011)의 데이터 선택 방법을 사용하여 결합 코퍼스의 크기를 348M 단어로 줄였습니다. 인코더를 사전 학습시키기 위해 훨씬 더 큰 단일 언어 코퍼스를 사용하는 것이 가능할 수도 있지만 언급된 병렬 말뭉치 이외의 단일 언어 데이터는 사용하지 않습니다. 우리는 news-test-2012와 news-test-2013을 연결하여 개발(검증) 세트를 만들고 WMT '14의 테스트 세트(뉴스-테스트-2014)에서 모델을 평가합니다. 이 세트는 WMT '14에 없는 3003개의 문장으로 구성됩니다. 훈련 데이터
일반적인 토큰화 이후 각 언어에서 가장 자주 사용되는 단어 30,000개의 최종 후보 목록을 사용하여 모델을 교육합니다. 후보 목록에 포함되지 않은 모든 단어는 특수 토큰([UNK])에 매핑됩니다. 우리는 데이터에 소문자 변환이나 형태소 분석과 같은 다른 특별한 전처리를 적용하지 않습니다.
그림 2: 문장 길이에 따라 테스트 세트에서 생성된 번역의 BLEU 점수입니다. 결과가 나와 있어요. 모델에 알려지지 않은 단어가 포함된 문장을 포함하는 전체 테스트 세트입니다.
4.2 모델
우리는 두 가지 유형의 모델을 훈련합니다. 첫 번째는 RNN Encoder-Decoder(RNNencdec, Cho et al., 2014a)이고, 다른 하나는 RNNsearch라고 하는 제안된 모델입니다. 각 모델을 두 번 훈련합니다. 먼저 최대 30단어 길이의 문장(RNNencdec-30, RNNsearch-30)으로, 그런 다음 최대 50단어 길이의 문장(RNNencdec-50, RNNsearch-50)으로 학습합니다.
RNNencdec의 인코더와 디코더에는 각각 1000개의 숨겨진 유닛이 있습니다. RNNsearch의 인코더는 각각 1000개의 숨겨진 유닛이 있는 순방향 및 역방향 순환 신경망(RNN)으로 구성됩니다. 디코더에는 1000개의 숨겨진 유닛이 있습니다. 두 경우 모두 단일 최대 출력(Goodfellow et al., 2013) 숨겨진 레이어가 있는 다층 네트워크를 사용하여 각 대상 단어의 조건부 확률을 계산합니다(Pascanu et al., 2014).
우리는 Adadelta(Zeiler, 2012)와 함께 미니배치 SGD(확률적 경사하강법) 알고리즘을 사용하여 각 모델을 훈련합니다. 각 SGD 업데이트 방향은 80개 문장의 미니 배치를 사용하여 계산됩니다. 우리는 각 모델을 약 5일 동안 훈련했습니다.
모델이 훈련되면 빔 검색을 사용하여 조건부 확률을 대략 최대화하는 변환을 찾습니다(예: Graves, 2012; Boulanger-Lewandowski et al., 2013 참조). Sutskever et al.(2014)은 이 접근 방식을 사용하여 신경 기계 번역 모델에서 번역을 생성했습니다. 실험에 사용된 모델의 아키텍처와 훈련 절차에 대한 자세한 내용은 부록 A와 B를 참조하세요.
5 결과
5.1 정량적 결과
표 1에는 BLEU 점수로 측정된 번역 성능을 나열합니다. 모든 경우에 제안된 RNNsearch가 기존 RNNencdec보다 성능이 우수하다는 것이 표에서 분명합니다. 더 중요한 것은 알려진 단어로 구성된 문장만 고려할 때 RNN 검색의 성능이 기존 구문 기반 번역 시스템(Moses)만큼 높다는 것입니다. 이는 Moses가 RNNsearch 및 RNNencdec를 훈련하는데 사용한 병렬 말뭉치 외에 별도의 단일 언어 말뭉치(418M 단어)를 사용한다는 점을 고려하면 중요한 성과입니다.
그림 3: RNNsearch-50에서 찾은 4개의 샘플 정렬. 각 플롯의 x축과 y축은 각각 원본 문장(영어) 및 생성된 번역(프랑스어)의 단어에 해당합니다. 각 픽셀은 i번째 소스 단어에 대한 j번째 소스 단어 주석의 가중치 αij를 나타냅니다. 회색조(0: 검정색, 1: 흰색)의 대상 단어(식(6) 참조). (a) 임의의 문장. (b–d) 알 수 없는 단어가 없고 테스트 세트에서 길이가 10~20 단어 사이인 문장 중에서 무작위로 선택된 3개의 샘플입니다.
제안된 접근 방식의 동기 중 하나는 기본 인코더-디코더 접근 방식에서 고정 길이 컨텍스트 벡터를 사용하는 것입니다. 우리는 이러한 제한으로 인해 기본 인코더-디코더 접근 방식이 긴 문장에서 성능이 저하될 수 있다고 추측했습니다. 그림 2에서 문장의 길이가 길어질수록 RNNencdec의 성능이 급격히 떨어지는 것을 볼 수 있습니다. 반면에 RNNsearch-30과 RNNsearch-50은 모두 문장 길이에 더 강력합니다. 특히 RNNsearch-50은 문장 길이가 50개 이상인 경우에도 성능 저하가 나타나지 않습니다. 기본 인코더-디코더에 비해 제안된 모델의 이러한 우월성은 RNNsearch-30이 RNNencdec-50보다 성능이 뛰어나다는 사실로 더욱 확인됩니다(표 1 참조).
표 1: 테스트 세트에서 계산된 훈련된 모델의 BLEU 점수. 두 번째와 세 번째 열에는 각각 모든 문장의 점수가 표시되고, 자체적으로 알 수 없는 단어가 없는 문장과 참조 번역에 대한 점수가 표시됩니다. RNNsearch-50은 개발 세트의 성능이 향상되지 않을 때까지 훨씬 더 오랫동안 훈련되었습니다. (◦) 알 수 없는 단어가 없는 문장만 평가할 때 모델이 [UNK] 토큰을 생성하는 것을 허용하지 않았습니다(마지막 열).
5.2 정성적 분석
5.2.1 정렬
제안된 접근 방식은 생성된 번역의 단어와 원본 문장의 단어 사이의 (소프트) 정렬을 검사하는 직관적인 방법을 제공합니다. 이는 Eq.로부터 주석 가중치 αij를 시각화함으로써 수행됩니다. (6), 그림 3과 같습니다. 각 플롯의 행렬의 각 행은 주석과 관련된 가중치를 나타냅니다. 이를 통해 목표 단어를 생성할 때 원본 문장의 어느 위치가 더 중요하게 고려되었는지 알 수 있습니다.
그림 3의 정렬에서 영어와 프랑스어 사이의 단어 정렬이 대체로 단조롭다는 것을 알 수 있습니다. 각 행렬의 대각선을 따라 강한 가중치가 표시됩니다. 그러나 우리는 또한 사소하지 않고 단조롭지 않은 정렬도 많이 관찰합니다. 형용사와 명사는 일반적으로 프랑스어와 영어의 순서가 다르며 그림 3(a)에 그 예가 나와 있습니다. 이 그림에서 모델이 [European Economic Area]라는 문구를 [zone economique Europeen]으로 올바르게 번역한다는 것을 알 수 있습니다. RNNsearch는 [zone]을 [Area]와 올바르게 정렬하여 두 단어([European] 및 [Economic])를 건너뛴 다음 한 번에 한 단어씩 뒤로 찾아 전체 구문 [zone economique Europeenne]을 완성할 수 있었습니다.
예를 들어, 그림 3(d)에서는 하드 정렬과 반대되는 소프트 정렬의 강도가 분명합니다. [l' homme]으로 번역된 원본 문구 [the man]을 생각해 보세요. 모든 하드 정렬은 [the]를 [l']로, [man]을 [homme]으로 매핑합니다. 이는 번역에 도움이 되지 않습니다. [le], [la], [les] 또는 [l']로 번역할지 여부를 결정하려면 [the] 뒤에 오는 단어를 고려해야 합니다. 우리의 소프트 정렬은 모델이 [the]와 [man]을 모두 보도록 하여 이 문제를 자연스럽게 해결하며, 이 예에서는 모델이 [the]를 [l']로 올바르게 변환할 수 있음을 알 수 있습니다. 우리는 그림 3에 제시된 모든 사례에서 유사한 동작을 관찰합니다. 소프트 정렬의 추가 이점은 일부 단어를 또는 에 매핑하는 반직관적인 방법을 요구하지 않고 서로 다른 길이의 소스 및 대상 구문을 자연스럽게 처리한다는 것입니다. 아무데도([NULL])(예: Koehn, 2010의 4장 및 5장 참조)
5.2.2 긴 문장
그림 2에서 명확하게 볼 수 있듯이 제안된 모델(RNNsearch)은 긴 문장을 번역하는 데 기존 모델(RNNencdec)보다 훨씬 좋습니다. 이는 RNNsearch가 긴 문장을 고정 길이 벡터로 완벽하게 인코딩할 필요가 없고 특정 단어를 둘러싸는 입력 문장 부분만 정확하게 인코딩하기 때문일 수 있습니다.
예를 들어, 테스트 세트의 다음 소스 문장을 고려해보세요.
입원 특권은 병원의 의료 종사자로서의 지위에 따라 진단이나 시술을 수행하기 위해 환자를 병원이나 의료 센터에 입원시킬 수 있는 의사의 권리입니다.
RNNencdec-50은 이 문장을 다음과 같이 번역했습니다.
입원 특권은 의사가 병원이나 의료 센터에서 환자를 인정하여 진단을 받거나 환자의 건강 상태에 따라 진단을 내릴 수 있는 권리입니다.
RNNencdec-50은 [의료센터]까지 원본 문장을 정확하게 번역했습니다. 그러나 거기서부터(밑줄 친 부분) 원문의 본래 의미에서 벗어났다. 예를 들어, 원본 문장의 [병원의 의료 종사자로서의 지위에 따라]를 [그의 건강 상태에 따라](“그의 건강 상태에 따라”)로 대체했습니다.
반면 RNNsearch-50은 세부 사항을 생략하지 않고 입력 문장의 전체 의미를 보존하면서 다음과 같은 올바른 번역을 생성했습니다.
입원 특권은 의료 종사자로서의 지위에 따라 진단이나 시술을 수행하기 위해 환자를 '병원 또는 의료 센터'에 입원시킬 수 있는 의사의 권리입니다.
테스트 세트의 또 다른 문장을 고려해 보겠습니다.
이러한 종류의 경험은 "시리즈의 수명을 연장하고 점점 더 중요해지고 있는 디지털 플랫폼을 통해 관객과 새로운 관계를 구축하려는" 디즈니 노력의 일환이라고 그는 덧붙였습니다.
RNNencdec-50에 의한 번역은 다음과 같습니다.
이러한 유형의 경험은 "뉴스의 수명을 연장하고 점점 더 복잡해지고 있는 "디지털 독자"와의 연결을 개발하려는 Disney의 계획의 일부입니다.
이전 예와 마찬가지로 RNNencdec은 약 30개의 단어를 생성한 이후부터 원본 문장의 실제 의미에서 벗어나기 시작했습니다(밑줄 친 문장 참조). 그 이후에는 닫는 인용 부호가 없는 등 기본적인 실수로 번역 품질이 저하됩니다.
이번에도 RNNsearch-50은 이 긴 문장을 올바르게 번역할 수 있었습니다.
이러한 종류의 경험은 "시리즈의 수명을 연장하고 점점 더 중요해지는 디지털 플랫폼을 통해 관객과 새로운 관계를 구축"하려는 디즈니의 노력의 일환이라고 그는 덧붙였습니다.
이미 제시된 정량적 결과와 함께 이러한 정성적 관찰은 RNNsearch 아키텍처가 표준 RNNencdec 모델보다 긴 문장을 훨씬 더 안정적으로 번역할 수 있다는 가설을 확인시켜 줍니다. 부록 C에서는 참조 번역과 함께 RNNencdec-50, RNNsearch-50 및 Google Translate에서 생성된 긴 소스 문장의 샘플 번역을 몇 가지 더 제공합니다.
6. 관련작업
6.1 정렬 학습
최근 Graves(2013)는 필기 합성의 맥락에서 출력 기호를 입력 기호와 정렬하는 유사한 접근 방식을 제안했습니다. 필기 합성은 모델이 주어진 문자 시퀀스의 필기를 생성하도록 요청하는 작업입니다. 그의 작업에서 그는 혼합 가우스 커널을 사용하여 주석의 가중치를 계산했으며, 여기서 각 커널의 위치, 너비 및 혼합 계수는 정렬 모델에서 예측되었습니다. 보다 구체적으로, 그의 정렬은 위치가 단조롭게 증가하도록 위치를 예측하도록 제한되었습니다.
우리 접근 방식과의 주요 차이점은 (Graves, 2013)에서 주석 가중치 모드가 한 방향으로만 이동한다는 것입니다. 기계 번역의 경우 문법적으로 올바른 번역(예: 영어-독일어)을 생성하려면 (장거리) 재정렬이 필요한 경우가 많기 때문에 이는 심각한 제한 사항입니다.
반면에 우리의 접근 방식에서는 번역의 각 단어에 대해 원본 문장의 모든 단어에 대한 주석 가중치를 계산해야 합니다. 대부분의 입력 및 출력 문장이 15~40 단어에 불과한 번역 작업에서는 이러한 단점이 심각하지 않습니다. 그러나 이로 인해 제안된 방식을 다른 작업에 적용하는 것이 제한될 수 있습니다.
6.2 기계 번역을 위한 신경망
Bengio et al.(2003)은 고정된 수의 선행 단어가 주어졌을 때 단어의 조건부 확률을 모델링하기 위해 신경망을 사용하는 신경 확률적 언어 모델을 도입한 이후 신경망이 기계 번역에 널리 사용되었습니다. 그러나 신경망의 역할은 단순히 기존 통계 기계 번역 시스템에 단일 기능을 제공하거나 기존 시스템에서 제공하는 후보 번역 목록의 순위를 다시 지정하는 것으로 크게 제한되었습니다.
예를 들어, Schwenk(2012)는 피드포워드 신경망을 사용하여 소스 및 대상 문구 쌍의 점수를 계산하고 해당 점수를 문구 기반 통계 기계 번역 시스템의 추가 기능으로 사용할 것을 제안했습니다. 최근에는 Kalchbrenner 및 Blunsom(2013)과 Devlin et al.(2014)이 기존 번역 시스템의 하위 구성 요소로 신경망을 성공적으로 사용했다고 보고했습니다. 전통적으로 타겟 측 언어 모델로 훈련된 신경망은 후보 번역 목록의 점수를 다시 매기거나 순위를 다시 매기는 데 사용되었습니다(예: Schwenk et al., 2006 참조).
위의 접근 방식은 최첨단 기계 번역 시스템에 비해 번역 성능을 향상시키는 것으로 나타났지만, 우리는 신경망을 기반으로 완전히 새로운 번역 시스템을 설계하려는 보다 야심찬 목표에 더 관심이 있습니다. 따라서 우리가 이 논문에서 고려하는 신경 기계 번역 접근 방식은 이전 연구에서 근본적으로 벗어났습니다. 기존 시스템의 일부로 신경망을 사용하는 대신 우리 모델은 자체적으로 작동하여 원본 문장에서 직접 번역을 생성합니다.
7. 결론
인코더-디코더 접근법이라고 불리는 신경 기계 번역에 대한 기존 접근법은 전체 입력 문장을 번역이 디코딩될 고정 길이 벡터로 인코딩합니다. 우리는 Cho et al.(2014b)와 Pouget-Abadie et al.(2014)이 보고한 최근 실증적 연구를 기반으로 고정 길이 컨텍스트 벡터의 사용이 긴 문장을 번역하는 데 문제가 있다고 추측했습니다.
본 논문에서는 이 문제를 해결하는 새로운 아키텍처를 제안했습니다. 우리는 각 대상 단어를 생성할 때 모델이 입력 단어 세트 또는 인코더에 의해 계산된 주석을 (소프트) 검색하도록 하여 기본 인코더-디코더를 확장했습니다. 이를 통해 모델은 전체 소스 문장을 고정 길이 벡터로 인코딩할 필요가 없으며 모델은 다음 대상 단어 생성과 관련된 정보에만 집중할 수 있습니다. 이는 신경 기계 번역 시스템이 긴 문장에서 좋은 결과를 산출하는 능력에 큰 긍정적인 영향을 미칩니다. 기존 기계 번역 시스템과 달리 정렬 메커니즘을 포함한 번역 시스템의 모든 부분은 올바른 번역을 생성할 수 있는 더 나은 로그 확률을 향해 공동으로 훈련됩니다.
우리는 영어-프랑스어 번역 작업에 대해 RNNsearch라는 제안된 모델을 테스트했습니다. 실험을 통해 제안된 RNNsearch는 문장 길이에 관계없이 기존 인코더-디코더 모델(RNNencdec)보다 훨씬 뛰어난 성능을 발휘하며 소스 문장 길이에 비해 훨씬 더 강력하다는 사실이 밝혀졌습니다. RNNsearch에서 생성된 (소프트) 정렬을 조사한 정성적 분석을 통해 모델이 생성된 소스 문장의 관련 단어 또는 해당 주석과 각 대상 단어를 올바르게 정렬할 수 있다는 결론을 내릴 수 있었습니다. 올바른 번역.
아마도 더 중요한 것은 제안된 접근 방식이 기존 구문 기반 통계 기계 번역에 필적하는 번역 성능을 달성했다는 것입니다. 제안된 아키텍처 또는 전체 신경 기계 번역 제품군이 최근 올해에야 제안되었다는 점을 고려하면 이는 놀라운 결과입니다. 우리는 여기에 제안된 아키텍처가 더 나은 기계 번역과 일반적으로 자연어에 대한 더 나은 이해를 향한 유망한 단계라고 믿습니다.
앞으로 남은 과제 중 하나는 알려지지 않은 단어나 희귀한 단어를 더 잘 처리하는 것입니다. 이는 모델이 더 널리 사용되고 모든 상황에서 현재 SOTA 기계 번역 시스템의 성능을 일치시키기 위해 필요합니다.
A. 모델 아키텍처
A.1 아키텍처 선택
3장에서 제안하는 방식은 순환 신경망(RNN)의 활성화 함수 f와 정렬 모델 a 등을 자유롭게 정의할 수 있는 일반적인 프레임워크입니다. 여기서는 이 문서의 실험을 위해 선택한 사항을 설명합니다.
A.1.1 순환 신경망
RNN의 활성화 함수 f를 위해 최근 Cho et al.(2014a)이 제안한 Gated Hidden Unit을 사용합니다. Gated Hidden Unit은 요소별 tanh와 같은 기존의 단순 단위에 대한 대안입니다. 단위는 Hochreiter와 Schmidhuber(1997)가 이전에 제안한 장단기 기억(LSTM) 단위와 유사하며 장기 종속성을 더 잘 모델링하고 학습할 수 있는 기능을 공유합니다. 이는 다음과 같은 계산 경로를 가짐으로써 가능해집니다. 도함수의 곱이 1에 가까운 펼쳐진 RNN입니다. 이러한 경로를 사용하면 소실 효과를 크게 겪지 않고 기울기가 쉽게 뒤로 흐를 수 있습니다(Hochreiter, 1991; Bengio et al., 1994; Pascanu et al., 2013a). 따라서 Sutskever et al. (2014).
n개의 게이트 은닉 유닛을 사용하는 RNN의 새로운 상태 si는 다음과 같이 계산됩니다.
여기서 ◦는 요소별 곱셈이고 zi는 업데이트 게이트의 출력입니다(아래 참조). 제안된 업데이트 상태 s~i는 다음과 같이 계산됩니다.
여기서 e(yi−1 ) ∈ Rm은 단어 yi−1 의 m차원 임베딩이고 ri는 재설정 게이트의 출력입니다(아래 참조). yi가 1-K 벡터로 표현되면 e(yi)는 단순히 임베딩 행렬 E ∈ Rm×K 의 열입니다. 가능할 때마다 방정식을 덜 복잡하게 만들기 위해 편향 항을 생략합니다.
업데이트 게이트 zi는 각 숨겨진 유닛이 이전 활성화를 유지할 수 있도록 하며, 재설정 게이트 ri는 이전 상태에서 재설정해야 하는 정보의 양과 정보를 제어합니다. 우리는 그것을 다음과 같이 계산합니다.
여기서 σ(·)는 로지스틱 시그모이드 함수입니다.
디코더의 각 단계에서 출력 확률(식(4))을 다층 함수로 계산합니다(Pascanu et al., 2014). 우리는 maxout 단위의 단일 숨겨진 레이어(Goodfellow et al., 2013)를 사용하고 소프트맥스 함수(Eq. (6) 참조)를 사용하여 출력 확률(각 단어당 하나씩)을 정규화합니다.
A.1.2 정렬 모델
Tx 및 Ty 길이의 각 문장 쌍에 대해 모델이 Tx × Ty 횟수를 평가해야 한다는 점을 고려하여 정렬 모델을 설계해야 합니다. 계산을 줄이기 위해 단일 레이어 다층 퍼셉트론을 사용합니다.
여기서 Wa ∈ Rn×n , Ua ∈ Rn×2n 및 va ∈ Rn은 가중치 행렬입니다. Ua hj는 i에 의존하지 않기 때문에 계산 비용을 최소화하기 위해 미리 계산할 수 있습니다.
A.2 모델에 대한 자세한 설명
A.2.1 인코더
이 섹션에서는 실험에 사용된 제안 모델(RNNsearch)의 아키텍처를 자세히 설명합니다(섹션 4-5 참조). 이제부터는 가독성을 높이기 위해 모든 편향 용어를 생략합니다. 모델은 1-of-K 코드 단어 벡터의 소스 문장을 입력으로 사용합니다.
1-of-K 코드어 벡터의 번역된 문장을 출력합니다.
여기서 Kx와 Ky는 각각 소스 언어와 대상 언어의 어휘 크기입니다. Tx와 Ty는 각각 소스 문장과 타겟 문장의 길이를 나타냅니다.
먼저 BiRNN(양방향 순환 신경망)의 순방향 상태가 계산됩니다.
Eㅡ ∈ Rm×Kx는 단어 임베딩 행렬입니다. W→, Wz→, Wr→ ∈ R^n*m, U→, Uz→, Ur→ ∈ R^n*n은 가중치 행렬입니다. m과 n은 각각 단어 임베딩 차원과 숨겨진 단위의 수입니다. σ(·)는 평소와 같이 로지스틱 시그모이드 함수입니다.
역방향 상태(h1←,...,hTx←)도 비슷하게 계산됩니다. 가중치 행렬과 달리 순방향 RNN과 역방향 RNN 간에 단어 임베딩 행렬 Eㅡ를 공유합니다.
주석(h1, h2,···, hTx)을 얻기 위해 순방향 상태와 역방향 상태를 연결합니다.
A.2.2 디코더
인코더의 주석이 주어진 디코더의 숨겨진 상태 si는 다음과 같이 계산됩니다.
E는 대상 언어에 대한 단어 임베딩 매트릭스입니다. W, Wz , Wr ∈ Rn×m , U, Uz , Ur ∈ Rn×n , C, Cz , Cr ∈ Rn×2n 은 가중치입니다. 다시 말하지만, m과 n은 각각 단어 임베딩 차원과 숨겨진 단위의 수입니다. 초기 은닉 상태 s0은 s0 = tanh (Wsh1←)로 계산됩니다. 여기서 Ws ∈ Rn×n
컨텍스트 벡터 ci는 정렬 모델에 의해 각 단계에서 다시 계산됩니다.
표 2: 학습 통계 및 관련 정보. 각 업데이트는 단일 미니배치를 사용하여 매개변수를 한 번 업데이트하는 것에 해당합니다. 한 에포크는 훈련 세트를 한 번 통과하는 것입니다. NLL은 훈련 세트 또는 개발 세트에 있는 문장의 평균 조건부 로그 확률입니다. 문장의 길이가 다르므로 주의하세요.
hj는 원본 문장의 j 번째 주석입니다(식(7) 참조). va ∈ R^n', Wa ∈ R^n'×n 및 Ua ∈ R^n' ×2n은 가중치 행렬입니다. ci를 h Tx→로 고정하면 모델은 RNN Encoder-Decoder(Cho et al., 2014a)가 됩니다.
디코더 상태 si−1, 컨텍스트 ci 및 마지막 생성된 단어 yi−1을 사용하여 대상 단어 yi의 확률을 다음과 같이 정의합니다.
t~i,k는 다음과 같이 계산되는 벡터 t~i의 k 번째 요소입니다
Wo ∈ R^Ky ×l , Uo ∈ R^2l×n , Vo ∈ R^2l×m 및 Co ∈ R^2l×2n은 가중치 행렬입니다. 이는 단일 최대 출력 히든 레이어(Goodfellow et al., 2013)를 사용하여 깊은 출력(Pascanu et al., 2014)을 갖는 것으로 이해될 수 있습니다.
B. 훈련 절차
B.1 매개변수 초기화
순환 가중치 행렬 U, Uz , Ur , U← , U z← , U r← , U→ , U z→ 및 U r→ 을 무작위로 초기화했습니다. 토고날 행렬. Wa와 Ua의 경우 평균 0과 분산 0.0012의 가우스 분포에서 각 요소를 샘플링하여 초기화했습니다. Va의 모든 요소와 모든 바이어스 벡터는 0으로 초기화되었습니다. 다른 가중치 행렬은 평균 0, 분산 0.012의 가우스 분포에서 샘플링하여 초기화되었습니다.
B.2 훈련
확률적 경사하강법(SGD) 알고리즘을 사용했습니다. Adadelta(Zeiler, 2012)는 각 매개변수(=10−6 및 ρ=0.95)의 학습률을 자동으로 조정하는 데 사용되었습니다. 우리는 노름이 임계값보다 클 때 매번 비용 함수 기울기의 L2 표준을 사전 정의된 임계값 1 이하로 명시적으로 정규화했습니다(Pascanu et al., 2013b). 각 SGD 업데이트 방향은 80개 문장의 미니배치로 계산되었습니다.
업데이트할 때마다 구현에는 미니배치에서 가장 긴 문장의 길이에 비례하는 시간이 필요합니다. 따라서 계산 낭비를 최소화하기 위해 매 20번째 업데이트 전에 1600개의 문장 쌍을 검색하여 길이에 따라 정렬하고 20개의 미니배치로 분할했습니다. 훈련 데이터는 훈련 전에 한 번 섞이고 이러한 방식으로 순차적으로 탐색되었습니다. 표 2에서는 실험에 사용된 모든 모델의 훈련과 관련된 통계를 제시합니다.
본 논문에서는 인코더, 디코더 사용 LSTM을 사용 멀티 4 Layers 쌓아서 구현 영어를 불어로 번역 사용된 데이터셋 : WMT’14
BLEU : 기계번역 성능지표
LSTM을 사용하면 긴 문장도 높은성능으로 잘 번역 : 34.8%(BLEU) 통계적기계번역 시스템 : 33.3% 통계적기계번역 시스템 + 딥러닝 자연어처리기법(LSTM) : 36.5%
LSTM 입력문장의 순서를 바꾸는 것이 학습 난이도를 낮춰 성능이 높아졌다.
1. 서론
DNN 복잡한 함수 학습하는 것에서 성능이 좋다. 경사하강법을 사용 하면 복잡한 함수도 잘 찾아 학습을 진행한다. 입력과 출력의 차원이 고정되어있다.
이전까지의 모델들은 입력과 출력의 차원이 고정되어 있어 연속적인 시퀀스 데이터를 처리하는것은 쉽지 않다. 번역과같이Sequencial한데이터를처리할때 입력과 출력의 길이가 가변적으로바뀔필요가있다.
LSTM만으로 Sequence to Sequence 문제를 해결할수 있다. 인코딩을 통해 입력된 데이터에 대해 큰 크기에 고정된 컨텍스트 벡터를 뽑은 뒤 디코더가 이를 입력으로 받아 출력 시퀀스를 뽑는 동작을 하면 충분히 좋은 성능을 낼수 있다. LSTM 장기의존성 없이 잘 처리할수 있다.
LSTM은 장기의존성 문제 해결
새로운 입력과 이전 상태 참조하여 현재의 상태를 결정하는 것 Forget gate : 얼마나 잊어 버릴 것인지 결정 Input gate : 얼마의 비율로 사용할 것인지 결정 Cell state : 이 둘을 적절히 섞는다. 일련의 정보들을 모두 종합해서 Output gate로 넘겨준다.
인코더, 디코더
LSTM와 SMT기법을 같이 사용하니 가장 성능이 좋았다. LSTM을 사용하면 문장일 길어도 잘 처리했다.
SMT 기법
2. 모델
인코딩 LSTM 과 디코딩 LSTM는 서로 다른 파라미터를 가진다. 4개의 layer로 중첩하여 사용하였고 마지막으로 입력 문장의 순서를 바꾸는 것이 성능향상이 되었다.
임베딩 : 독일어를 영어로 바꾼다고 하면 독일어에서 등장빈도 높은 단어가 2만개 정도 있다고 가정하면 매 단어를 2만 차원의 원핫 인코딩으로 하면 차원의 크기가 너무 커질수 있어 1천차원 2천차원으로 상대적으로 적은 데이터로 표현할수 있도록 차원을 줄임
3. 실험
학습
Source(문장)가 들어오면 타켓 문장 선택
테스트
가장 확률높은 타겟 문장 출력
트레이닝 정보 LSTM 4Layers
임베딩 1,000차원 LSTM 파라미터 -0.08 ~ 0.08 값으로 유니폼 분포를 따른다. 그라디언트 배치 사이즈 128만큼 설정(문장의 개수 128개)
매번 문장이 들어올때마다 가장 확률이 높은 타켓 문장을 출력 beam search 활용 : 단순히 매번 가장 확률이 높은 것만 뽑는것이 아니라 특정 깊이 만큼 더 들어갈수 있게 만들어 출력 문장이 확률이 더 높아질수 있도록 적용 beam search를 활용 EOS가 나올때까지 타켓 문장중에 가장 확률값이 높은 경우를 고름 beam search : 평가값이 우수한 일정 개수의 확장 가능한 노드만을 메모리에 관리하면서 최상 우선 탐색을 적용하는 기법이다.
통계적 기계번역시스템과같이사용하면성능이좋았다. 처음들어온 문장은 더 잘 맞추고 나중에 들어오는 문장일수록 덜 맞추지만 그럼에도 불구하고 성능이 좋았다.
하나의 용어 눈(eye, snow)에 대해 사용법이 두가지라면 두가지의 관점에 대해 임베딩이 달라야 된다.
"play"를 보면 GloVe로 사용한 임베딩 벡터를 가지고 보면 약간은 스포츠에 치우쳐 진것을 볼수 있는데 biLM (ELMo 실제 구조)는 "play "가 첫번째 예시는 스포츠, 두번째 예시는 연극에서 사용하는 상황중 어느 상황에서 쓰였는지 용법을 통해 파악할 수 있다.
ELMo
각각의 토큰들이 representation(전체의 입력문장을 이용)을 받는다.
사용하는 임베딩 벡터는 biLSTM을 가지고 오고 LM에 대해 목적함수를 가지고 학습이 된다.
ELMo 가지고 특징은 deep 한 representation이고 biLM는 모든 다양한 Layer에서 나오는 히든 벡터들을 결합한다.
stacked above each
가장 top LSTM layer만 사용한 representation보다 다운스크림 태스크들에 대한 성능이 향상되었다.
여러 단계의 representation을 사용함으로 인해서 위쪽에 대응하는 representation 벡터들은 context-dependent한 단어를 판별, 표현할 수 있다.
보다 낮은 레벨의 히든 state는 구문 분석에 대해 해당하는 피처를 포함하고 있다.
각 Layer 마다 가지고 있는 정보의 깊이가 다르기 때문에 syntax 분석을 수행해야 된다면 더 낮은 Layer에 대한 가중치를 더 높게 설정하고 만약에 의미가 필요한 task에서는 좀더 상위 레벨의 히든 벡터들의 가중치를 크게 둠으로써 task에 따라 어떻게 여러층의 정보들을 결합하냐를 결정을 해줌으로써 ELMo가 유연하고 여러 다운스트림 task의 성능을 높게 나타내는 representation를 생성할 수 있다.
ELMo가 가지는 방식은 기본적인 구조는 Language Modeling로 지금 까지 주어진 단어의 시퀀스들을 통해 다음 단어를 예측하는 구조이다.
ELMo는 bi-directional LSTM을 이용하여 forward, backward 언어 모델 둘다를 같이 학습을 시킨다.
예시로 "stick" 단어가 존재하는 시점에서의 위치가 forward와 backward 모델에서 같아야 하고 각각의 같은 동일한 레벨에 있는 임베딩 값 또는 히든 state 벡터들을 Concatenation 한다.
task-specific 한 가중치를 학습을 시키는 것이 좋다. 감마는 task에 대한 스퀘어 벡터로 전체 가중합이 된 ELMo의 사전학습된 벡터를 얼마만큼 증폭, 축소시키냐를 결정하는 요소이다.
forward direction LM
k토큰을 예측하기 위해서는 k번째 단어 이전에 존재하는 모든 단어들을 조건부를 삼아 k번째 단어가 등장할 확률을 계산한다음 전부 곱해준다. 각각의 단어들의 대해서 먼저 생성된 단어들에 대해서만 영향을 받는다.
Glove는 context-independent로 문장에 상관없이 이미 Glove에 의해 사전학습된 워드 벡터를 사용하는데 ELMo는 context-dependent로 L개의 Layer을 가지고 가장 top LSTM의 아웃풋(L번째 Layer)이 다음번 토큰을 예측하는데 사용이 된다.
backward direction LM
forward와 비슷하고 순서만 다르다.
forward, backward LM의 likelihood를 함께 최대화 해야된다.
2L(순방향, 역방향)+1(x에 대한 representation)
모든 벡터들을 하나의 싱글 벡터로 collapses 시킨다. 가중치를 이용해 가중합을 만든다. (가중치를 모두 더하면 1이 된다.) 감마 task는 전체 ELMo벡터들에 대해 전반적인 scale을 해준다.
ELMo를 사용하면 성능향상이 되는데 숫자가 중요한것이 아니고 굉장히 다양한 다운스트림 태스크들에 대해서 모두(1차원적인 평면적인 임베딩을 사용한것 보다) 훨씬 더 성능이 좋았다.
task에 대해 specific하게 w를 조절하는게 좋다. 가장 top layer hidden state를 쓰는게 낮은 layer 쓰는것 보다 좋다.