1. 지도학습
[선형 회귀 (Linear Regression)]
알려진 다른 관련 데이터 값을 사용하여 알 수 없는 데이터의 값을 예측하는 데이터 분석 기법
종속 변수 y와 한 개 이상의 독립 변수 X와의 선형 상관 관계를 모델링하는 회귀분석 기법
| - 회귀를 사용하여 데이터가 어떤 범주에 속할 확률을 0에서 1 사이의 값으로 예측하고 그 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해주는 지도 학습 알고리즘 |
[다항 회귀 (Polynomial Regression)]
회귀식의 독립변수가 2차, 3차 방정식 같은 다항식으로 표현되는 것
단순한 비례관계로 표현되는게 편하지만 수많은 데이터 표현할 때는 그렇지 않기 때문에 다항 회귀를 사용
[LMS(Least Mean Square) - 최소 평균 제곱 알고리즘]
많은 데이터가 주어졌을때 그 데이터들이 이루는 그래프를 산출해내기 위하여 사용하는 방법
미분의 개념을 최적화 문제에 적용한 방법중 하나로 함수의 local minimum을 찾는 방법중 하나
정교한 방식으로 확률적 경사 하강을 사용하는 기계 학습에 사용되는 필터 유형
[퍼셉트론 (Perceptron)]
인공 신경망(Aritificial Neural Network, ANN)의 구성 요소(unit)로서 다수의 값을 입력받아 하나의 값으로 출력하는 알고리즘
[최소제곱법 (Least Square Method)]
목적 변수 y와 일반 선형회귀 모형으로 추정한 yhat의 차이가 최소가 되도록 하는 회귀 계수를 구하는 방식
[소프트맥스 회귀 (Softmax Regression)]
로지스틱 회귀 중에서도 다중분류를 위한 회귀
로직스틱 회귀가 0또는 1, 성공 또는 실패 등의 두개의 라벨을 분류한다면 소프트맥스 회귀는 A 또는 B 또는 C처럼 3개 이상의 라벨을 분류하는데 쓰일 수 있다.
[판별 분석 (Discriminant Analysis)]
두 개 이상의 모집단에서 추출된 표본들이 지니고 있는 정보는 이용하여 이 표본들이 어느 모집단에서 추출된 것인지를 결정해 줄 수 있는 기준을 찾는 분석법
[다변량 정규분포 (Multivariate Vaussian Normal distribution, MVN)]
정규분포를 다차원 공간에 대해 확장한 분포
[선형판별분석 (Linear Discriminant Anaylysis, LDA)]
두 개 이상의 모집단에서 표집된 표본들의 데이터분포를 이용하여 이 표본들이 어느 모집단에서 추출된 것인지 분류 예측을 할수 있도록 기준을 찾는 분석법
클래스 분리를 위해 클래스 평균값간의 거리를 최대화시키고, 겹치는 오류를 최소화 시킨다.
[나이브 베이즈 분류 (Naive Bayes Classification)]
데이터가 각 클래스에 속할 특징 확률을 계산하는 조건부 확률 기반 분류 방법
나이브 : 예측한 특징이 상호 독립적이라는 가정 하에 확률 계산을 단순화
베이즈 : 입력 특징이 클래스 전체의 확률 분포 대비 특정 클래스에 속할 확률을 베이즈 정리 기반으로 계산
[라플라스 스무딩 (Laplace Smoothing)]
만약 기존에 없는 새로운 단어가 입력된다면 해당 단어에 대한 확률이 0이기 때문에 모든 확률이 0이 되는 문제가 발생하는데 이를 해결하기 위한 기법
| - 각 분자에 1을 더함으로 이를 해결 |
| - 분모에는 중복을 제거한 모든 데이터의 수를 더해줌 |
[서포트 벡터 머신 (Support Vector Machine, SVM)]
데이터 집합 바탕으로 새로운 데이터가 어느 카테고리에 속할지 초평면, 마진 통한 데이터를 분류하는 지도학습 알고리즘
데이터가 어느 카테고리에 속할지 판단하는 이진 선형 분류 모델
2. 딥러닝
[신경망 (neural network)]
뉴런이라는 기본유닛이 여러겹 놓여있고 가중치를 통해 연결관계를 표현하고 입력층, 은닉측, 출력층 순서로 결과를 출력하는 인간의 두뇌를 모방하는 인공 지능 방식
[역전파 (Backpropagation)]
계산 결과와 정답의 오차를 구해 이 오차에 관여하는 값들의 가중치를 수정하여 오차가 작아지는 방향으로 일정 횟수를 반복해 수정하는 방법
출력층에서 입력층 방향으로 오차를 전파시키며 각 층의 가중치를 업데이트
3. 일반화 및 정규화
[Variance Trade-off (편향-분산 트레이드 오프)]
모델이 복잡해질 수록 편향(Bias)은 작아지고, 분산(Variance)은 커져서 over-fitting 됨
모델이 단순해질수록 편향은 커지고, 분산은 작아짐, under-fitting 됨
무조건 편향만 줄일 수도, 무조건 분산만 줄일 수도 없음, 오류를 최소화하려면 편향과 분산의 합이 최소가 되는 적당한 지점을 찾아야 함
[일반화 (Generalization)]
이전에 본 적 없는 새로운 데이터에 대해 정확하게 예측할 수 있는 능력
[정규화 (normalization)]
데이터는 그 값이 너무 크거나 작지 않고 적당한 범위 (-1에서 ~ 1사이)에 있어야 모델의 정확도가 높아짐
| - 입력 변수 X를 최소값은 0, 최댓값은 1이 되게 1차 함수를 통해서 변환 |
[표준화 (standardization)]
입력 변수 X를 평균이 0, 분산이 1인 정규 분포가 되도록 1차 함수를 통해서 변환
데이터에 이상값이 포함되었을 가능성이 높다면, 표준화를 적용하면 하고
반대로. 이미지 데이터처럼 최솟값과 최대값을 미리 알 수 있는 경우에는 정규화를 사용
4. 비지도 학습
[클러스터링 (Clustering)]
하나의 데이터를 여러개의 부분집합 (clusters) 으로 분할하는 것을 의미
[k-means 알고리즘]
특정한 임의의 지점을 선택해 군집 중심점을 설정하고, 해당 중심에 가장 가까운 포인트 들을 선택하여 k개의 클러스터로 묶는 알고리즘
[기댓감 최대화 알고리즘 (Expectation-Maximization algorithm, EM algorithm)]
관측되지 않는 잠재변수에 의존하는 확률 모델에서 최대우도나 최대사후확률을 갖는 매개변수를 찾는 반복적인 알고리즘
[주성분 분석 (Principal Component Analysis, PCA)]
데이터의 분산을 최대한 보존하면서 서로 직교하는 축을 찾아, 고차원 공간의 표본들을 선형 연관성이 없는 저차원 공간으로 변환하는 기법
[독립성분분석 (Independent Component Analysis, ICA)]
주어진 다변량 신호를 독립적인 비정규분포(Non-Gaussia)의 신호들로 분해하는 기법
[자기지도학습 (Self-supervised learning)]
최소한의 데이터만으로 스스로 규칙을 찾아 분석하는 AI 기술
[제로샷 학습 (Zero-shot learning)]
모델이 학습 과정에서 배우지 않은 작업을 수행하는 것
[사전학습 (Pre-training)]
이미 방대한 양의 학습 데이터를 이용해서 학습을 완료한 모델
[전이학습 (Transfer Learning)]
하나의 작업을 위해 훈련된 모델을 유사 작업 수행 모델의 시작점으로 활용하는 딥러닝 접근법
[Fine-tuning]
기존에 학습되어져 있는 모델을 기반으로 아키텍쳐를 새로운 목적에 맞게 변형하고 이미 학습된 모델의 가중치를 미세하게 조정하여 학습시키는 방법
| - 기존에 학습이 된 레이어에 데이터를 추가로 학습시켜 파라미터를 업데이트 |
5. 강화 학습
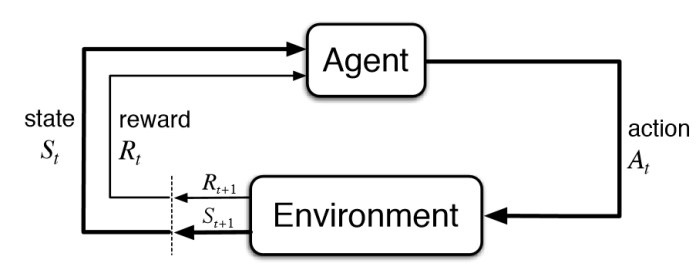
[Reinforcement Learning]
상태(State)에서 어떤 행동(Action)을 취하는 것이 최적인지를 학습하는 방법, 행동을 취할 때마다 외부 환경에서 보상(Reward)이 주어지는데, 이러한 보상을 최대화 하는 방향으로 학습하는 방법
[MDP (Markov Decision Process)]
순차적 행동 결정 문제를 수학적으로 정의하는 것으로 상태, 행동, 상태 전이 확률, 보상, 감가율로 구성된다. 각 상태에서 최적의 행동을 찾는 것으로 더 좋은 정책을 찾는 과정