구글(Google)이 GPT-4 뛰어넘는 멀티모달 AI 모델 ‘제미나이(Gemini)’를 공개했습니다.
기자간담회에서 공개한 내용은 이미지, 영상, 텍스트(사용자의 말) 정보를 동시에 포괄적으로 이해, 사람과 자유자재로 대화가 가능하고, 예측, 합리적 추론에 대한 답을 얻을 수 있습니다.
가장 큰 모델 제미나이 울트라는 32개 학술 벤치마크(benchmark, 성능 지표) 중 30개에서 GPT-4를 능가합니다.
특히 수학, 물리학, 역사, 법률, 의학, 윤리 등 57개 과목을 조합해 지식, 문제 해결 능력을 테스트하는 ‘MMLU(대규모 다중 작업 언어 이해)’에서 90.0%의 점수를 획득, 최초로 인간 전문가를 넘어섰습니다. (GPT-4의 MMLU 점수는 86.4%)
수학 능력을 측정하는 GSM8K에서도 94.4%의 점수 획득(GPT-4는 92%), 코드 작성 능력(HumanEval)은 74.4%(GPT-4는 67.0%) 달성했습니다.
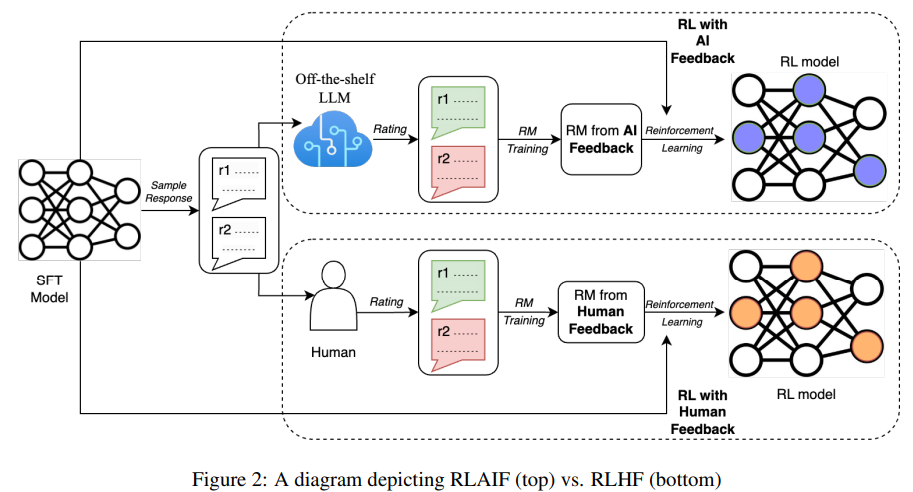
그리고 추가적으로 '인간 피드백에 기반한 강화 학습(RLHF)'을, 'AI 피드백에 기반한 강화 학습(RLAIF)'으로 대체하여 더 빠르고 저렴하게 AI를 학습시킬 수 있는 방법을 Google Research에서 revision을 12월 1일에 발표했습니다. (1차는 9월에)
용어 설명을 하자면 RLHF는 LLM의 성능을 크게 높여주고 특히 인간의 선호도에 맞춘(alignment) 답변을 할 수 있도록 만드는 데 필수적인 기법으로 자리 잡았으며, LLM을 chat model에 맞게 chat data를 훈련하여 성능을 올렸습니다.
하지만 RLHF로 학습을 시키려면 인간 레이블러를 통해 지속적으로 고품질 학습 데이터를 만들어야 하는데, 이 데이터를 만드는 일은 시간과 비용이 굉장히 많이 드는 일입니다.
그런데 인간 대신 강력한 기성 LLM (e.g.,PaLM 2)을 사용하여 레이블링을 하는 방식으로 대신해보았더니, 인간의 레이블을 통해 학습하는 방법과 성능 차이가 거의 없었고, 심지어 무해성은 더 높은 성능을 가지는 것으로 나타났습니다.
아직 초기 단계의 연구이긴 하지만, 최고 성능의 모델이 조금 더 좋아지고, 이에 따라 RLAIF가 RLHF보다 확실하게 더 높은 성능을 보이게 되는 날이 오면, 안전하고 높은 수준의 AI를 쉽게 만들 수 있는 것으로 보여집니다.
RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback - https://arxiv.org/abs/2309.00267
RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Reinforcement learning from human feedback (RLHF) has proven effective in aligning large language models (LLMs) with human preferences. However, gathering high-quality human preference labels can be a time-consuming and expensive endeavor. RL from AI Feedb
arxiv.org
'학습' 카테고리의 다른 글
| GPT 모델 개선한 Mamba 등장? (0) | 2024.01.23 |
|---|---|
| GPTs 해킹가능성 (1) | 2024.01.22 |
| 강화학습이란? (0) | 2024.01.22 |
| 파이썬 List와 Tupple 생성해보기 (0) | 2023.07.05 |
| 인공지능 토픽 정의 (0) | 2023.07.04 |