개요
모델이 다운스트림 작업에서 미세 조정되기 전에 데이터가 풍부한 작업에 대해 먼저 사전 훈련되는 전이 학습은 자연어 처리(NLP)에서 강력한 기술로 부상했습니다. 전이 학습의 효율성으로 인해 접근 방식, 방법론 및 실습이 다양해졌습니다. 본 논문에서는 모든 텍스트 기반 언어 문제를 텍스트 대 텍스트 형식으로 변환하는 통합 프레임워크를 도입하여 NLP를 위한 전이 학습 기술의 환경을 탐구합니다. 우리의 체계적인 연구는 수십 가지 언어 이해 작업에 대한 사전 훈련 목표, 아키텍처, 레이블이 없는 데이터 세트, 전송 접근 방식 및 기타 요소를 비교합니다. 탐색에서 얻은 통찰력과 규모 및 새로운 "Colossal Clean Crawled Corpus"를 결합하여 요약, 질문 답변, 텍스트 분류 등을 다루는 많은 벤치마크에서 최첨단 결과를 달성합니다. NLP를 위한 전이 학습에 대한 향후 작업을 촉진하기 위해 데이터 세트, 사전 훈련된 모델 및 코드를 출시합니다.
키워드: 전이 학습, 자연어 처리, 다중 작업 학습, 주의 기반 모델, 심층 학습
1. 서론
자연어 처리(NLP) 작업을 수행하기 위해 기계 학습 모델을 훈련하려면 모델이 다운스트림 학습에 적합한 방식으로 텍스트를 처리할 수 있어야 하는 경우가 많습니다. 이는 모델이 텍스트를 "이해"할 수 있도록 하는 범용 지식을 개발하는 것으로 느슨하게 볼 수 있습니다. 이러한 지식은 낮은 수준(예: 단어의 철자 또는 의미)부터 높은 수준(예: 튜바가 너무 커서 대부분의 배낭에 들어갈 수 없음)까지 다양합니다.
현대 기계 학습 실무에서 이러한 지식을 명시적으로 제공하는 경우는 거의 없습니다. 대신 보조 작업의 일부로 학습되는 경우가 많습니다. 예를 들어, 역사적으로 일반적인 접근 방식은 단어 벡터(Mikolov et al., 2013b,a; Pennington et al., 2014)를 사용하여 단어 정체성을 연속 표현으로 매핑하는 것입니다. 여기서 이상적으로는 유사한 단어가 유사한 벡터에 매핑됩니다. 이러한 벡터는 종종 연속 공간에서 동시 발생하는 단어가 근처에 위치하도록 장려하는 목표를 통해 학습됩니다(Mikolov et al., 2013b).
최근에는 데이터가 풍부한 작업에 대해 전체 모델을 사전 학습하는 것이 점점 일반화되었습니다. 이상적으로는 이러한 사전 훈련을 통해 모델이 범용 능력과 지식을 개발하고 이를 다운스트림 작업으로 전송할 수 있습니다. 컴퓨터 비전에 대한 전이 학습의 적용(Oquab et al., 2014; Jia et al., 2014; Huh et al., 2016; Yosinski et al., 2014)에서 사전 훈련은 일반적으로 대규모 환경에서 지도 학습을 통해 수행됩니다. ImageNet과 같은 레이블이 지정된 데이터 세트(Russakovsky et al., 2015; Deng et al., 2009) 이와 대조적으로 NLP의 전이 학습을 위한 현대 기술은 레이블이 지정되지 않은 데이터에 대한 비지도 학습을 사용하여 사전 훈련하는 경우가 많습니다.
이 접근 방식은 최근 가장 일반적인 NLP 벤치마크에서 최첨단 결과를 얻는 데 사용되었습니다(Devlin et al., 2018; Yang et al., 2019; Dong et al., 2019; Liu et al. , 2019c; Lan et al., 2019). 경험적 강점 외에도 NLP에 대한 감독되지 않은 사전 훈련은 인터넷 덕분에 레이블이 지정되지 않은 텍스트 데이터를 대량으로 사용할 수 있기 때문에 특히 매력적입니다. 예를 들어 Common Crawl 프로젝트2는 매달 웹 페이지에서 추출된 약 20TB의 텍스트 데이터를 생성합니다. 이는 놀라운 확장성을 나타내는 것으로 알려진 신경망에 자연스러운 적합성입니다. 즉, 더 큰 데이터 세트에서 더 큰 모델을 훈련함으로써 더 나은 성능을 달성하는 것이 종종 가능합니다(Hestness et al., 2017; Shazeer et al. , 2017; Jozefowicz 등, 2016; Mahajan 등, 2018; Radford 등, 2019; Shazeer 등, 2018; Huang 등, 2018b; Keskar 등, 2019a).
이러한 시너지 효과로 인해 NLP에 대한 전이 학습 방법론을 개발하는 최근의 많은 작업이 이루어졌으며, 이는 사전 훈련 목표의 광범위한 환경을 생성했습니다(Howard and Ruder, 2018; Devlin et al., 2018; Yang et al., 2019; Dong 등, 2019), 레이블이 지정되지 않은 데이터 세트(Yang 등, 2019; Liu 등, 2019c; Zellers 등, 2019), 벤치마크(Wang 등, 2019b, 2018; Conneau 및 Kiela, 2018 ), 미세 조정 방법(Howard and Ruder, 2018; Houlsby et al., 2019; Peters et al., 2019) 등이 있습니다. 이 급성장하는 분야의 빠른 발전 속도와 기술의 다양성으로 인해 다양한 알고리즘을 비교하고, 새로운 기여의 효과를 분석하고, 전이 학습을 위한 기존 방법의 공간을 이해하는 것이 어려울 수 있습니다. 보다 엄격한 이해에 대한 필요성에 동기를 부여받아, 우리는 다양한 접근 방식을 체계적으로 연구하고 해당 분야의 현재 한계를 뛰어넘을 수 있는 전이 학습에 대한 통합 접근 방식을 활용합니다.
우리 작업의 기본 아이디어는 모든 텍스트 처리 문제를 "텍스트 대 텍스트" 문제로 처리하는 것입니다. 즉, 텍스트를 입력으로 사용하고 새 텍스트를 출력으로 생성하는 것입니다. 이 접근 방식은 모든 텍스트 문제를 질문 답변으로 캐스팅(McCann et al., 2018), 언어 모델링(Radford et al., 2019) 또는 범위 추출 Keskar et al. (2019b) 작업을 포함하여 NLP 작업을 위한 이전 통합 프레임워크에서 영감을 받았습니다. 결정적으로, 텍스트-텍스트 프레임워크를 통해 우리가 고려하는 모든 작업에 동일한 모델, 목표, 훈련 절차 및 디코딩 프로세스를 직접 적용할 수 있습니다. 우리는 질문 답변, 문서 요약, 감정 분류 등 다양한 영어 기반 NLP 문제에 대한 성과를 평가함으로써 이러한 유연성을 활용합니다. 이러한 통합 접근 방식을 사용하면 이전에 고려했던 것 이상으로 모델과 데이터 세트를 확장하여 NLP에 대한 전이 학습의 한계를 탐색하는 동시에 다양한 전이 학습 목표, 레이블이 지정되지 않은 데이터 세트 및 기타 요인의 효율성을 비교할 수 있습니다.
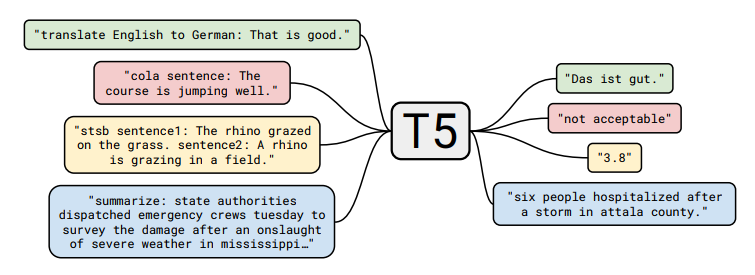
그림 1 : 텍스트-텍스트 프레임워크의 다이어그램. 번역, 질문 답변 및 분류를 포함하여 우리가 고려하는 모든 작업은 모델 텍스트를 입력으로 제공하고 일부 대상 텍스트를 생성하도록 훈련시키는 것으로 캐스팅됩니다. 이를 통해 다양한 작업 세트에서 동일한 모델, 손실 함수, 하이퍼파라미터 등을 사용할 수 있습니다. 또한 실증적 조사에 포함된 방법에 대한 표준 테스트베드를 제공합니다. "T5"는 "텍스트-텍스트 전송 변환기"라고 불리는 우리 모델을 나타냅니다.
우리는 우리의 목표가 새로운 방법을 제안하는 것이 아니라 해당 분야가 어디에 있는지에 대한 포괄적인 관점을 제공하는 것임을 강조합니다. 따라서 우리의 작업은 주로 기존 기술에 대한 조사, 탐색 및 실증적 비교로 구성됩니다. 또한 체계적인 연구(교육)에서 얻은 통찰력을 확장하여 현재 접근 방식의 한계를 탐구합니다.
우리가 고려하는 많은 작업에서 최첨단 결과를 얻기 위해 최대 110억 개의 매개변수를 모델링합니다. 이 규모의 실험을 수행하기 위해 웹에서 스크랩한 수백 기가바이트의 깨끗한 영어 텍스트로 구성된 데이터 세트 "Colossal Clean Crawled Corpus"(C4)를 소개합니다. 전이 학습의 주요 유틸리티는 데이터가 부족한 환경에서 사전 훈련된 모델을 활용할 수 있다는 점을 인식하여 코드, 데이터 세트 및 사전 훈련된 모델을 출시합니다.
논문의 나머지 부분은 다음과 같이 구성됩니다. 다음 섹션에서는 기본 모델과 그 구현, 모든 텍스트 처리 문제를 텍스트 대 텍스트 작업으로 공식화하는 절차, 그리고 우리가 고려하는 작업 세트에 대해 논의합니다. 섹션 3에서는 NLP의 전이 학습 분야를 탐구하는 대규모 실험 세트를 제시합니다. 섹션 끝(섹션 3.7)에서는 체계적인 연구에서 얻은 통찰력을 결합하여 다양한 벤치마크에서 최첨단 결과를 얻습니다. 마지막으로 4장에서 결과를 요약하고 미래에 대한 전망으로 마무리합니다.
2. 설정
대규모 실증적 연구 결과를 제시하기 전에 Transformer 모델 아키텍처 및 평가 대상인 다운스트림 작업을 포함하여 결과를 이해하는 데 필요한 배경 주제를 검토합니다. 또한 모든 문제를 텍스트 대 텍스트 작업으로 처리하는 접근 방식을 소개하고 레이블이 지정되지 않은 텍스트 데이터의 소스로 만든 Common Crawl 기반 데이터 세트 "Colossal Clean Crawled Corpus"(C4)에 대해 설명합니다. 우리는 모델과 프레임워크를 "텍스트-텍스트 전송 변환기"(T5)라고 부릅니다.
2.1. 모델
NLP에 대한 전이 학습의 초기 결과는 순환 신경망을 활용했지만(Peters et al., 2018; Howard and Ruder, 2018), 최근에는 "Transformer" 아키텍처(Vaswani et al., 2017) 기반 모델을 사용하는 것이 더 일반화되었습니다. Transformer는 처음에는 기계 번역에 효과적인 것으로 나타났지만 이후 다양한 NLP 설정에서 사용되었습니다(Radford et al., 2018; Devlin et al., 2018; McCann et al., 2018; Yu et al. ., 2018). 보편성이 증가함에 따라 우리가 연구하는 모든 모델은 Transformer 아키텍처를 기반으로 합니다. 아래에 언급된 세부 사항과 섹션 3.2에서 살펴보는 변형을 제외하고는 원래 제안된 대로 이 아키텍처에서 크게 벗어나지 않습니다. 이 모델에 대한 포괄적인 정의를 제공하는 대신 관심 있는 독자에게 원본 논문(Vaswani et al., 2017) 또는 후속 튜토리얼 3, 4를 참조하여 더 자세한 소개를 제공합니다.
Transformer의 주요 구성 요소는 self-attention입니다(Cheng et al., 2016). Self-attention은 각 요소를 나머지 시퀀스의 가중 평균으로 대체하여 시퀀스를 처리하는 Attention의 변형입니다(Graves, 2013; Bahdanau et al., 2015). 원래 Transformer는 인코더-디코더 아키텍처로 구성되었으며 시퀀스 간(Sutskever et al., 2014; Kalchbrenner et al., 2014) 작업을 위해 고안되었습니다. 최근에는 언어 모델링에 적합한 아키텍처를 생성하는 데 사용되는 다양한 형태의 self-attention과 함께 단일 Transformer 레이어 스택으로 구성된 모델을 사용하는 것이 일반화되었습니다(Radford et al., 2018; Al-Rfou et al., 2019). 분류 및 범위 예측 작업(Devlin et al., 2018; Yang et al., 2019). 우리는 섹션 3.2에서 이러한 아키텍처 변형을 경험적으로 탐색합니다.
전반적으로 우리의 인코더-디코더 Transformer 구현은 원래 제안된 형식(Vaswani et al., 2017)을 밀접하게 따릅니다. 먼저, 토큰의 입력 시퀀스가 임베딩 시퀀스에 매핑된 다음 인코더로 전달됩니다. 인코더는 "블록"의 스택으로 구성되며, 각 블록은 두 개의 하위 구성 요소, 즉 self-attention 레이어와 작은 피드포워드 네트워크로 구성됩니다. 레이어 정규화(Ba et al., 2016)는 각 하위 구성요소의 입력에 적용됩니다. 우리는 활성화의 크기만 조정하고 추가 바이어스는 적용하지 않는 단순화된 버전의 레이어 정규화를 사용합니다. 레이어 정규화 후 잔여 건너뛰기 연결(He et al., 2016)은 각 하위 구성 요소의 입력을 출력에 추가합니다. 드롭아웃(Srivastava et al., 2014)은 피드포워드 네트워크 내, 스킵 연결, 주의 가중치, 전체 스택의 입력 및 출력에 적용됩니다. 디코더는 인코더의 출력에 참여하는 각 self-attention 계층 뒤에 표준 주의 메커니즘을 포함한다는 점을 제외하면 구조가 인코더와 유사합니다. 디코더의 self-attention 메커니즘은 모델이 과거 출력에만 주의를 기울이는 것을 허용하는 autoregressive 또는 causal self-attention의 형태도 사용합니다. 최종 디코더 블록의 출력은 소프트맥스 출력이 있는 밀집 레이어로 공급되며, 해당 가중치는 입력 임베딩 행렬과 공유됩니다. Transformer의 모든 주의 메커니즘은 추가 처리 전에 출력이 연결되는 독립적인 "헤드"로 분할됩니다.
self-attention은 순서에 독립적이므로(즉, 세트에 대한 작업이므로) Transformer에 명시적인 위치 신호를 제공하는 것이 일반적입니다. 원래 Transformer는 정현파 위치 신호 또는 학습된 위치 임베딩을 사용했지만 최근에는 상대 위치 임베딩을 사용하는 것이 더 일반적이 되었습니다(Shaw et al., 2018; Huang et al., 2018a).
각 위치에 고정 임베딩을 사용하는 대신 상대 위치 임베딩은 self-attention 메커니즘에서 비교되는 "키"와 "쿼리" 사이의 오프셋에 따라 다른 학습 임베딩을 생성합니다. 우리는 각 "임베딩"이 단순히 주의 가중치를 계산하는 데 사용되는 해당 로짓에 추가되는 스칼라인 단순화된 형태의 위치 임베딩을 사용합니다. 효율성을 위해 모델의 모든 레이어에서 위치 임베딩 매개변수를 공유하지만, 주어진 레이어 내에서 각 어텐션 헤드는 서로 다른 학습된 위치 임베딩을 사용합니다. 일반적으로 고정된 수의 임베딩이 학습되며, 각각은 가능한 키 쿼리 오프셋 범위에 해당합니다. 이 작업에서는 모든 상대 위치를 동일한 임베딩에 할당하는 오프셋 128까지 대수적으로 크기가 증가하는 범위의 모든 모델에 대해 32개의 임베딩을 사용합니다. 주어진 레이어는 128개 토큰을 초과하는 상대 위치에 민감하지 않지만 후속 레이어는 이전 레이어의 로컬 정보를 결합하여 더 큰 오프셋에 대한 민감도를 구축할 수 있습니다.
요약하자면, 우리 모델은 Vaswani 등이 제안한 원래 Transformer와 거의 동일합니다. (2017), Layer Norm 바이어스를 제거하고, 레이어 정규화를 잔여 경로 외부에 배치하고, 다른 위치 임베딩 방식을 사용하는 것을 제외하고 이러한 아키텍처 변경은 전이 학습에 대한 실증적 조사에서 고려한 실험적 요소와 직교하므로 향후 작업에 대한 영향을 제거합니다.
연구의 일환으로 우리는 이러한 모델의 확장성, 즉 더 많은 매개변수나 레이어를 갖게 되면서 성능이 어떻게 변하는지 실험합니다. 대규모 모델을 훈련하는 것은 단일 시스템에 적합하지 않고 많은 양의 계산이 필요할 수 있으므로 쉽지 않을 수 있습니다. 결과적으로 우리는 모델과 데이터 병렬 처리의 조합을 사용하고 Cloud TPU Pod의 '슬라이스'에서 모델을 교육합니다. TPU Pod는 고속 2D 메시 상호 연결을 통해 연결된 1,024개의 TPU v3 칩을 포함하는 다중 랙 ML 슈퍼컴퓨터입니다. CPU 호스트 시스템을 지원합니다. 우리는 모델 병렬성과 데이터 병렬성(Krizhevsky, 2014)을 쉽게 구현하기 위해 Mesh TensorFlow 라이브러리(Shazeer et al., 2018)를 활용합니다.
2.2. 거대하고 깨끗하게 크롤링된 코퍼스
NLP를 위한 전이 학습에 대한 이전 연구의 대부분은 비지도 학습을 위해 레이블이 지정되지 않은 대규모 데이터 세트를 사용했습니다. 본 논문에서는 레이블이 지정되지 않은 데이터의 품질, 특성 및 크기의 효과를 측정하는 데 관심이 있습니다. 우리의 요구 사항을 충족하는 데이터 세트를 생성하기 위해 Common Crawl을 웹에서 스크랩한 텍스트 소스로 활용합니다. Common Crawl은 이전에 NLP용 텍스트 데이터 소스로 사용되었습니다(예: n-gram 언어 모델 훈련(Buck et al., 2014)), 상식 추론을 위한 훈련 데이터(Trinh and Le, 2018), 마이닝 기계 번역을 위한 병렬 텍스트(Smith et al., 2013), 사전 훈련 데이터 세트(Grave et al., 2018; Zellers et al., 2019; Liu et al., 2019c), 심지어는 단순히 거인으로서 최적화 도구 테스트를 위한 텍스트 코퍼스(Anil et al., 2019).
Common Crawl은 스크랩된 HTML 파일에서 마크업 및 기타 텍스트가 아닌 콘텐츠를 제거하여 "웹에서 추출된 텍스트"를 제공하는 공개적으로 사용 가능한 웹 아카이브입니다. 이 프로세스를 통해 매월 약 20TB의 스크랩된 텍스트 데이터가 생성됩니다. 불행하게도 결과 텍스트의 대부분은 자연어가 아닙니다. 대신 메뉴, 오류 메시지 또는 중복 텍스트와 같은 횡설수설 또는 상용구 텍스트로 주로 구성됩니다. 게다가 스크랩된 텍스트의 상당 부분에는 우리가 고려하는 작업(공격적인 언어, 자리 표시자 텍스트, 소스 코드 등)에 도움이 되지 않을 것 같은 콘텐츠가 포함되어 있습니다. 이러한 문제를 해결하기 위해 우리는 Common Crawl의 웹 추출 텍스트를 정리하기 위해 다음 경험적 방법을 사용했습니다.
• 끝 구두점(예: 마침표, 느낌표, 물음표 또는 끝 따옴표)으로 끝나는 줄만 유지했습니다.
• 문장이 5개 미만인 페이지는 모두 삭제하고 단어가 3개 이상 포함된 줄만 유지했습니다.
• "더러운, 버릇없는, 음란한 또는 기타 나쁜 단어 목록"에 있는 단어가 포함된 모든 페이지를 제거했습니다.
• 스크랩된 페이지 중 상당수에는 Javascript를 활성화해야 한다는 경고가 포함되어 있으므로 Javascript라는 단어가 포함된 줄을 모두 제거했습니다.
• 일부 페이지에는 자리 표시자 "lorem ipsum" 텍스트가 있습니다. 우리는 "lorem ipsum"이라는 문구가 표시된 모든 페이지를 제거했습니다.
• 일부 페이지에 실수로 코드가 포함되어 있습니다. 중괄호 "{"는 많은 프로그래밍 언어(예: 웹에서 널리 사용되는 Javascript)에 표시되지만 자연 텍스트에는 표시되지 않으므로 중괄호가 포함된 모든 페이지를 제거했습니다.
• 데이터 세트의 중복을 제거하기 위해 데이터 세트에서 두 번 이상 발생하는 세 문장 범위 중 하나만 제외하고 모두 삭제했습니다.
또한 대부분의 다운스트림 작업은 영어 텍스트에 중점을 두기 때문에 langDetect7을 사용하여 영어로 분류되지 않은 페이지를 최소 0.99의 확률로 필터링했습니다. 우리의 휴리스틱은 Common Crawl을 NLP의 데이터 소스로 사용하는 과거 작업에서 영감을 얻었습니다. 예를 들어 Grave et al. (2018)은 또한 자동 언어 탐지기를 사용하여 텍스트를 필터링하고 짧은 줄을 삭제하며 Smith et al. (2013); Graveet al. (2018) 둘 다 라인 수준 중복 제거를 수행합니다. 그러나 이전 데이터 세트는 보다 제한된 필터링 휴리스틱 세트를 사용하고, 공개적으로 사용할 수 없거나 범위가 다르기 때문에(예: 뉴스 데이터로 제한됨(Zellers et al., 2019; Liu et al., 2019c)는 Creative Commons 콘텐츠로만 구성되거나(Habernal et al., 2016) 기계 번역을 위한 병렬 교육 데이터에 중점을 둡니다(Smith et al., 2013).
기본 데이터 세트를 구성하기 위해 2019년 4월의 웹 추출 텍스트를 다운로드하고 앞서 언급한 필터링을 적용했습니다. 이는 사전 훈련에 사용되는 대부분의 데이터 세트(약 750GB)보다 훨씬 클 뿐만 아니라 합리적으로 깨끗하고 자연스러운 영어 텍스트로 구성된 텍스트 모음을 생성합니다. 우리는 이 데이터 세트를 "Colossal Clean Crawled Corpus"(또는 줄여서 C4)라고 명명하고 TensorFlow 데이터 세트의 일부로 출시합니다. 우리는 섹션 3.4에서 이 데이터 세트의 다양한 대체 버전을 사용할 때의 영향을 고려합니다.
2.3. 다운스트림 작업
본 논문의 목표는 일반적인 언어 학습 능력을 측정하는 것입니다. 따라서 우리는 기계 번역, 질문 답변, 추상 요약 및 텍스트 분류를 포함한 다양한 벤치마크 세트에 대한 다운스트림 성능을 연구합니다. 특히 GLUE 및 SuperGLUE 텍스트 분류 메타 벤치마크에 대한 성능을 측정합니다. CNN/Daily Mail 추상 요약; SQuAD 질문 답변; WMT 영어를 독일어, 프랑스어, 루마니아어로 번역합니다. 모든 데이터는 TensorFlow 데이터세트에서 가져왔습니다.
GLUE(Wang et al., 2018) 및 SuperGLUE(Wang et al., 2019b)는 각각 일반적인 언어 이해 능력을 테스트하기 위한 텍스트 분류 작업 모음으로 구성됩니다.
• 문장 수용성 판단(CoLA(Warstadt et al., 2018))
• 감성 분석(SST-2(Socher et al., 2013))
• 의역/문장 유사성(MRPC(Dolan and Brockett, 2005), STS-B(Cer et al., 2017), QQP(Iyer et al., 2017))
• 자연어 추론 (MNLI(Williams et al., 2017), QNLI(Rajpurkar et al., 2016), RTE(Dagan et al., 2005), CB(De Marneff et al., 2019))
• 상호참조 해결(WNLI 및 WSC(Levesque et al., 2012))
• 문장 완성(COPA(Roemmele et al., 2011))
• 단어 의미 명확성(WIC(Pilehvar and Camacho-Collados, 2018))
• 질의응답(MultiRC(Khashabi et al., 2018), ReCoRD(Zhang et al., 2018), BoolQ(Clark et al., 2019))
우리는 GLUE 및 SuperGLUE 벤치마크에 의해 배포된 데이터 세트를 사용합니다. 단순화를 위해 미세 조정 시 모든 구성 데이터 세트를 연결하여 GLUE 벤치마크(SuperGLUE의 경우와 유사)의 모든 작업을 단일 작업으로 처리합니다. Kocijan et al. (2019)이 제안한대로 결합된 SuperGLUE 작업에 DPR(Definite Pronoun Resolution) 데이터 세트(Rahman and Ng, 2012)도 포함됩니다.
CNN/Daily Mail(Hermann et al., 2015) 데이터 세트는 질문 답변 작업으로 도입되었지만 Nallapati et al. (2016); 은 텍스트 요약에 적용했습니다. 우리는 See et al. (2017)의 익명화되지 않은 버전을 사용합니다. 추상 요약 작업으로. SQuAD(Rajpurkar et al., 2016)는 일반적인 질문 답변 벤치마크입니다. 우리의 실험에서 모델은 질문과 그 컨텍스트를 제공받고 토큰별로 답변을 생성하도록 요청받습니다. WMT 영어에서 독일어로의 경우 (Vaswani et al., 2017)(예: News Commentary v13, Common Crawl, Europarl v7) 및 newstest2013과 동일한 학습 데이터를 검증 세트로 사용합니다(Bojar et al., 2014). 영어에서 프랑스어로의 경우 2015년과 newstest2014의 표준 훈련 데이터를 검증 세트로 사용합니다(Bojar et al., 2015). 표준 저자원 기계 번역 벤치마크인 영어에서 루마니아어로의 경우 WMT 2016(Bojar et al., 2016)의 학습 및 검증 세트를 사용합니다. 우리는 영어 데이터에 대해서만 사전 훈련하므로 특정 모델을 번역하는 방법을 배우려면 새로운 언어로 텍스트를 생성하는 방법을 배워야 합니다.
2.4. 입력 및 출력 형식
위에서 설명한 다양한 작업 세트에 대한 단일 모델을 훈련하기 위해 우리는 고려하는 모든 작업을 "텍스트 대 텍스트" 형식으로 캐스팅합니다. 조건을 지정하고 일부 출력 텍스트를 생성하라는 요청을 받습니다. 이 프레임워크는 사전 훈련과 미세 조정 모두에 대해 일관된 훈련 목표를 제공합니다.
특히 모델은 작업에 관계없이 최대 우도 목표("교사 강제"(Williams and Zipser, 1989) 사용)로 훈련됩니다. 모델이 수행해야 하는 작업을 지정하기 위해 모델에 입력하기 전에 원래 입력 시퀀스에 작업별(텍스트) 접두사를 추가합니다.
예를 들어, 모델에게 "That is good"이라는 문장을 번역해 달라고 요청하는 것입니다. 영어에서 독일어로, 모델에는 "영어를 독일어로 번역: 좋습니다."라는 시퀀스가 제공됩니다. 그리고 "Das ist Gut"를 출력하도록 훈련될 것입니다. 텍스트 분류 작업의 경우 모델은 단순히 대상 레이블에 해당하는 단일 단어를 예측합니다. 예를 들어,
MNLI 벤치마크(Williams et al., 2017)의 목표는 전제가 가설을 암시하는지("수반"), 모순되는지("모순"), 둘 다인지("중립")를 예측하는 것입니다. 전처리를 통해 입력 시퀀스는 "mnli 전제: 나는 비둘기를 싫어합니다."가 됩니다. 가설: 비둘기에 대한 나의 감정은 적개심으로 가득 차 있습니다.” 해당 타겟 단어로
“수반”. 모델이 가능한 레이블 중 어느 것과도 일치하지 않는 텍스트 분류 작업에서 텍스트를 출력하는 경우 문제가 발생합니다(예를 들어 작업에 대해 가능한 유일한 레이블이 "수반", "중립"인 경우 모델이 "햄버거"를 출력하는 경우). "또는 "모순"). 이 경우 우리는 항상 모델의 출력을 잘못된 것으로 간주합니다.
훈련된 모델에서는 이러한 동작을 관찰한 적이 없습니다. 주어진 작업에 사용되는 텍스트 접두사의 선택은 본질적으로 하이퍼파라미터입니다. 우리는 접두사의 정확한 표현을 변경하는 것이 미치는 영향이 제한적이므로 다양한 접두사 선택에 대한 광범위한 실험을 수행하지 않았다는 것을 발견했습니다. 몇 가지 입력/출력 예제가 포함된 텍스트-텍스트 프레임워크 다이어그램이 그림 1에 나와 있습니다. 부록 D에서 연구한 모든 작업에 대해 전처리된 입력의 전체 예제를 제공합니다.
우리의 텍스트-텍스트 프레임워크는 여러 NLP 작업을 공통 형식으로 변환하는 이전 작업인 McCann et al. (2018) 을 따릅니다. 이것은 10가지 NLP 작업에 대해 일관된 질문 답변 형식을 사용하는 벤치마크인 "Natural Language Decathlon"을 제안했습니다. Natural Language Decathlon은 또한 모든 모델이 다중 작업이어야 한다고 규정합니다. 즉, 모든 작업을 동시에 처리할 수 있어야 합니다. 대신 우리는 각 개별 작업에 대한 모델을 별도로 미세 조정하고 명시적인 질문-답변 형식 대신 짧은 작업 접두사를 사용합니다. Radfordet al. (2019)는 모델에 일부 입력을 접두사로 제공한 다음 자동 회귀 방식으로 출력을 샘플링하여 언어 모델의 제로샷 학습 기능을 평가합니다. 예를 들어, 자동 요약은 문서 뒤에 "TL;DR:"(일반적인 약어인 "너무 길어, 읽지 않음"의 줄임말) 텍스트를 입력하여 수행된 다음 자동 회귀 디코딩을 통해 요약을 예측합니다. 별도의 디코더로 출력을 생성하기 전에 인코더로 입력을 명시적으로 처리하는 모델을 주로 고려하며, 제로샷 학습보다는 전이 학습에 중점을 둡니다. 마지막으로 Keskar et al. (2019b)는 많은 NLP 작업을 "범위 추출"로 통합합니다. 여기서 가능한 출력 선택에 해당하는 텍스트가 입력에 추가되고 모델은 올바른 선택에 해당하는 입력 범위를 추출하도록 훈련됩니다. 대조적으로, 우리의 프레임워크는 가능한 모든 출력 선택을 열거하는 것이 불가능한 기계 번역 및 추상적인 요약과 같은 생성 작업도 허용합니다.
우리는 1과 5 사이의 유사성 점수를 예측하는 것이 목표인 회귀 작업인 STS-B를 제외하고 우리가 고려한 모든 작업을 텍스트-텍스트 형식으로 간단하게 캐스팅할 수 있었습니다. 이러한 점수의 대부분은 0.2 단위로 주석이 달렸으므로 모든 점수를 가장 가까운 0.2 단위로 반올림하고 결과를 숫자의 리터럴 문자열 표현으로 변환했습니다(예: 부동 소수점 값 2.57은 문자열 " 2.6”). 테스트 시 모델이 1에서 5 사이의 숫자에 해당하는 문자열을 출력하면 이를 부동 소수점 값으로 변환합니다. 그렇지 않으면 모델의 예측이 잘못된 것으로 간주됩니다. 이는 STS-B 회귀 문제를 21 클래스 분류 문제로 효과적으로 재구성합니다.
이와 별도로 Winograd 작업(GLUE의 WNLI, Super-GLUE의 WSC, SuperGLUE에 추가하는 DPR 데이터 세트)을 텍스트-텍스트 프레임워크에 더 적합한 간단한 형식으로 변환합니다. Winograd 작업의 예는 구절에 있는 명사구 중 하나 이상을 나타낼 수 있는 모호한 대명사가 포함된 텍스트 구절로 구성됩니다. 예를 들어, “시의원은 폭력이 두려워 시위대의 허가를 거부했다.”라는 구절에는 “시의원” 또는 “시위대”를 지칭할 수 있는 모호한 대명사 “그들”이 포함될 수 있습니다. 우리는 텍스트 구절에서 모호한 대명사를 강조하고 그것이 참조하는 명사를 예측하도록 모델에 요청하여 WNLI, WSC 및 DPR 작업을 텍스트 대 텍스트 문제로 분류합니다. 위에서 언급한 예는 “시의회 의원이 제안을 거부했습니다.”라는 입력으로 변환됩니다.
*그들*은 폭력을 두려워했기 때문에 시위자들은 허가를 받았습니다.” 모델은 대상 텍스트 "시의원"을 예측하도록 훈련됩니다.
WSC의 경우 예에는 구절, 모호한 대명사, 후보 명사 및 후보가 대명사와 일치하는지 여부를 반영하는 참/거짓 레이블(관사 무시)이 포함됩니다. "False" 레이블이 있는 예에 대한 올바른 명사 대상을 모르기 때문에 "True" 레이블이 있는 예에 대해서만 훈련합니다. 평가를 위해 모델 출력의 단어가 후보 명사구에 있는 단어의 하위 집합인 경우(또는 그 반대) "True" 레이블을 할당하고 그렇지 않은 경우 "False" 레이블을 할당합니다. 이는 WSC 훈련 세트의 대략 절반을 제거하지만 DPR 데이터 세트는 약 1,000개의 대명사 분해 예를 추가합니다. DPR의 예에는 올바른 참조 명사가 주석으로 추가되어 위에 나열된 형식으로 이 데이터 세트를 쉽게 사용할 수 있습니다. WNLI 훈련 및 검증 세트는 WSC 훈련 세트와 상당히 중복됩니다. 검증 예제가 훈련 데이터에 누출되는 것을 방지하기 위해(섹션 3.5.2의 다중 작업 실험의 특정 문제) 따라서 우리는 WNLI에 대해 훈련하지 않으며 WNLI 검증 세트에 대한 결과를 보고하지 않습니다. WNLI 검증 세트에서 결과를 생략하는 것은 훈련 세트와 관련하여 "적대적"이라는 사실로 인해 표준 관행입니다(Devlin et al., 2018). 즉, 검증 예제는 모두 반대되는 훈련 예제의 약간 교란된 버전입니다. 상표. 따라서 검증 세트(결과가 테스트 세트에 표시되는 섹션 3.7을 제외한 모든 섹션)에 대해 보고할 때마다 평균 GLUE 점수에 WNLI를 포함하지 않습니다. WNLI의 예를 위에 설명된 "참조 명사 예측" 변형으로 변환하는 작업은 좀 더 복잡합니다. 이 프로세스는 부록 B에서 설명합니다.
3. 실험
NLP를 위한 전이 학습의 최근 발전은 새로운 사전 훈련 목표, 모델 아키텍처, 레이블이 지정되지 않은 데이터 세트 등과 같은 다양한 개발에서 비롯되었습니다. 이 섹션에서는 놀리기를 바라며 이러한 기술에 대한 실증적 조사를 수행합니다.
그들의 기여와 의미는 별개입니다. 그런 다음 우리가 고려하는 많은 작업에서 최첨단 기술을 달성하기 위해 얻은 통찰력을 결합합니다. NLP를 위한 전이 학습은 빠르게 성장하는 연구 분야이므로 가능한 모든 기술이나 아이디어를 다루는 것은 불가능합니다.
우리의 경험적 연구에서 보다 광범위한 문헌 검토를 위해 Ruder et al. (2019). 의 최근 설문 조사를 권장합니다.
우리는 합리적인 기준(섹션 3.1에 설명됨)을 취하고 한 번에 설정의 한 측면을 변경하여 이러한 기여를 체계적으로 연구합니다. 예를 들어 섹션 3.3에서는 나머지 실험 파이프라인을 고정한 상태로 유지하면서 감독되지 않은 다양한 목표의 성능을 측정합니다. 이 "좌표 상승" 접근 방식은 2차 효과를 놓칠 수 있지만(예를 들어, 감독되지 않은 특정 목표는 기준 설정보다 큰 모델에서 가장 잘 작동할 수 있음), 연구의 모든 요소에 대한 조합 탐색을 수행하는 데는 엄청나게 많은 비용이 듭니다. 향후 연구에서는 우리가 연구하는 접근 방식의 조합을 보다 철저하게 고려하는 것이 유익할 것으로 기대합니다.
우리의 목표는 가능한 한 많은 요소를 고정하면서 다양한 작업 집합에 대한 다양한 접근 방식을 비교하는 것입니다. 이 목표를 달성하기 위해 어떤 경우에는 기존 접근 방식을 정확하게 복제하지 않습니다. 예를 들어, BERT(Devlin et al., 2018)와 같은 "인코더 전용" 모델은 입력 토큰당 단일 예측 또는 전체 입력 시퀀스에 대한 단일 예측을 생성하도록 설계되었습니다. 따라서 분류 또는 범위 예측 작업에는 적용할 수 있지만 번역이나 추상 요약과 같은 생성 작업에는 적용할 수 없습니다.
따라서 우리가 고려하는 모델 아키텍처는 BERT와 동일하거나 인코더 전용 구조로 구성되지 않습니다. 대신, 우리는 유사한 접근 방식을 테스트합니다. 예를 들어 섹션 3.3에서 BERT의 "마스크된 언어 모델링" 목표와 유사한 목표를 고려하고 섹션 3.2에서 텍스트 분류 작업에 대해 BERT와 유사하게 작동하는 모델 아키텍처를 고려합니다.
다음 하위 섹션에서 기본 실험 설정을 간략하게 설명한 후 모델 아키텍처(섹션 3.2), 감독되지 않은 목표(섹션 3.3), 사전 학습 데이터 세트(섹션 3.4), 전송 접근 방식(섹션 3.5) 및 확장에 대한 실증적 비교를 수행합니다. (섹션 3.6). 이 섹션의 정점에서 우리는 연구에서 얻은 통찰력을 규모와 결합하여 우리가 고려하는 많은 작업에서 최첨단 결과를 얻습니다(섹션 3.7).
3.1. 기준선
기준에 대한 우리의 목표는 전형적이고 현대적인 관행을 반영하는 것입니다. 간단한 노이즈 제거 목표를 사용하여 표준 Transformer(섹션 2.1에 설명됨)를 사전 훈련한 다음 각 다운스트림 작업을 개별적으로 미세 조정합니다. 다음 하위 섹션에서는 이 실험 설정의 세부 사항을 설명합니다
3.1.1. 모델
우리 모델에서는 Vaswani et al. (2017). 이 제안한 표준 인코더-디코더 Transformer를 사용합니다. NLP를 위한 전이 학습에 대한 많은 최신 접근 방식은 단일 "스택"(예: 언어 모델링(Radford et al., 2018; Dong et al., 2019)) 또는 분류 및 범위 예측(Devlin et al. ., 2018; Yang et al., 2019)), 표준 인코더-디코더 구조를 사용하면 생성 및 분류 작업 모두에서 좋은 결과를 얻을 수 있음을 발견했습니다. 섹션 3.2에서 다양한 모델 아키텍처의 성능을 살펴봅니다.
우리의 기본 모델은 인코더와 디코더가 각각 "BERTBASE"(Devlin et al., 2018) 스택과 크기 및 구성이 유사하도록 설계되었습니다. 특히 인코더와 디코더는 모두 12개의 블록으로 구성됩니다(각 블록은 self-attention, 선택적 인코더-디코더 주의 및 피드포워드 네트워크로 구성됨). 각 블록의 피드포워드 네트워크는 출력 차원이 dff = 3072인 조밀한 레이어와 그 뒤에 오는 ReLU 비선형성 및 또 다른 밀집 레이어. 모든 주의 메커니즘의 "키" 및 "값" 행렬은 dkv = 64의 내부 차원을 가지며 모든 주의 메커니즘에는 12개의 헤드가 있습니다. 다른 모든 하위 레이어와 임베딩의 차원은 dmodel = 768입니다. 전체적으로 약 2억 2천만 개의 매개변수가 있는 모델이 생성됩니다. 기본 모델에는 하나가 아닌 두 개의 레이어 스택이 포함되어 있으므로 이는 BERTBASE 매개변수 수의 대략 두 배입니다. 정규화를 위해 모델에 드롭아웃이 적용되는 모든 곳에서 드롭아웃 확률 0.1을 사용합니다.
3.1.2. 훈련
섹션 2.4에 설명된 대로 모든 작업은 텍스트-텍스트 작업으로 공식화됩니다. 이를 통해 우리는 항상 표준 최대 가능성, 즉 교사 강제(Williams and Zipser, 1989) 및 교차 엔트로피 손실을 사용하여 훈련할 수 있습니다. 최적화를 위해AdaFactor(Shazeer 및 Stern, 2018)를 사용합니다. 테스트 시에는 그리디 디코딩(즉, 모든 단계에서 가장 높은 확률의 로짓 선택)을 사용합니다.
미세 조정하기 전에 C4에서 2^19 = 524,288 단계에 대해 각 모델을 사전 학습합니다. 우리는 최대 시퀀스 길이 512개와 배치 크기 128개 시퀀스를 사용합니다. 가능할 때마다 배치^10의 각 항목에 여러 시퀀스를 "패킹"하여 배치에 대략 2^16 = 65,536개의 토큰이 포함되도록 합니다. 전체적으로 이 배치 크기와 단계 수는 2^35 ≒ 34B 토큰에 대한 사전 학습에 해당합니다. 이는 대략 1370억 개의 토큰을 사용한 BERT(Devlin et al., 2018)나 대략 2.2T 토큰을 사용한 RoBERTa(Liu et al., 2019c)에 비해 상당히 적습니다. 2^35개의 토큰만 사용하면 합리적인 계산 예산을 확보하는 동시에 수용 가능한 성능을 위한 충분한 양의 사전 훈련을 제공합니다. 섹션 3.6 및 3.7에서 추가 단계에 대한 사전 훈련의 효과를 고려합니다. 2^35 토큰은 전체 C4 데이터 세트의 일부만 다루므로 사전 훈련 중에는 데이터를 반복하지 않습니다.
사전 훈련 중에는 "역 제곱근" 학습 속도 일정을 사용합니다: 1/√max(n, k ) 여기서 n은 현재 훈련 반복이고 k는 준비 단계 수입니다(우리의 실험 모두 104로 설정 ). 이는 처음 104개 단계에 대해 0.01의 일정한 학습 속도를 설정한 다음 사전 훈련이 끝날 때까지 학습 속도를 기하급수적으로 감소시킵니다. 우리는 또한 삼각형 학습률(Howard and Ruder, 2018)을 사용하여 실험했는데, 이는 약간 더 나은 결과를 생성했지만 총 훈련 단계 수를 미리 알아야 합니다. 일부 실험에서는 훈련 단계의 수를 다양화할 것이므로 보다 일반적인 역제곱근 일정을 선택합니다.
우리 모델은 모든 작업에서 2^18 = 262,144 단계에 맞게 미세 조정되었습니다. 이 값은 추가적인 미세 조정을 통해 이점을 얻을 수 있는 리소스가 많은 작업(즉, 대규모 데이터 세트가 있는 작업)과 빠르게 초과되는 리소스가 적은 작업(소형 데이터 세트) 간의 절충점으로 선택되었습니다. 미세 조정 중에 길이가 128개이고 시퀀스가 512개인 배치(즉, 배치당 2 16개 토큰)를 계속 사용합니다. 미세 조정 시 일정한 학습률 0.001을 사용합니다. 5,000단계마다 체크포인트를 저장하고, 가장 높은 검증 성능에 해당하는 모델 체크포인트에 대한 결과를 보고합니다. 여러 작업에 대해 미세 조정된 모델의 경우 각 작업에 가장 적합한 체크포인트를 독립적으로 선택합니다. 섹션 3.7의 실험을 제외한 모든 실험에 대해 테스트 세트에서 모델 선택을 수행하지 않도록 검증 세트에 결과를 보고합니다.
3.1.3. 어휘
우리는 SentencePiece(Kudo 및 Richardson, 2018)를 사용하여 텍스트를 WordPiece 토큰으로 인코딩합니다(Sennrich et al., 2015; Kudo, 2018). 모든 실험에서 우리는 32,000개의 단어로 구성된 어휘를 사용합니다. 우리는 궁극적으로 영어에서 독일어, 프랑스어, 루마니아어 번역에 대한 모델을 미세 조정하므로 어휘가 영어가 아닌 언어도 포함해야 합니다.
이 문제를 해결하기 위해 우리는 C4에서 사용되는 Common Crawl 스크랩의 페이지를 독일어, 프랑스어 및 루마니아어로 분류했습니다. 그런 다음 영어 C4 데이터 10개 부분과 독일어, 프랑스어 또는 루마니아어로 분류된 데이터 각각 1개 부분을 혼합하여 SentencePiece 모델을 훈련했습니다. 이 어휘는 모델의 입력과 출력 모두에서 공유되었습니다. 우리의 어휘는 모델이 미리 결정되고 고정된 언어 집합만 처리할 수 있도록 만듭니다.
3.1.4. 비지도 목표
레이블이 지정되지 않은 데이터를 활용하여 모델을 사전 학습하려면 레이블이 필요하지 않지만 (느슨하게 말하면) 다운스트림 작업에 유용할 일반화 가능한 지식을 모델에 가르치는 목표가 필요합니다. NLP 문제에 대한 모든 모델 매개변수를 사전 훈련하고 미세 조정하는 전이 학습 패러다임을 적용한 예비 작업에서는 다음을 사용했습니다.
사전 훈련을 위한 인과 언어 모델링 목표 (Dai and Le, 2015; Peters et al., 2018; Radford et al., 2018; Howard and Ruder, 2018). 그러나 최근 "노이즈 제거" 목표(Devlin et al., 2018; Taylor, 1953)("마스크된 언어 모델링"이라고도 함)가 더 나은 성능을 제공하는 것으로 나타났으며 결과적으로 빠르게 표준이 되었습니다.
잡음 제거 목표에서 모델은 입력에서 누락되거나 손상된 토큰을 예측하도록 훈련됩니다. BERT의 "마스크된 언어 모델링" 목표와 "단어 드롭아웃" 정규화 기술(Bowman et al., 2015)에서 영감을 받아 우리는 무작위로 샘플링한 다음 입력 시퀀스에서 토큰의 15%를 삭제하는 목표를 설계합니다. 삭제된 토큰의 모든 연속 범위는 단일 센티넬 토큰으로 대체됩니다. 각 센티널 토큰에는 시퀀스에 고유한 토큰 ID가 할당됩니다. 센티넬 ID는 우리 어휘에 추가되는 특수 토큰이며 어떤 단어와도 일치하지 않습니다. 그런 다음 대상은 입력 시퀀스에 사용된 동일한 센티널 토큰과 대상 시퀀스의 끝을 표시하는 최종 센티널 토큰으로 구분된 모든 삭제된 토큰 범위에 해당합니다. 연속된 토큰 범위를 마스크하고 누락된 토큰만 예측하는 선택은 사전 훈련의 계산 비용을 줄이기 위해 이루어졌습니다. 우리는 섹션 3.3에서 사전 훈련 목표에 대한 철저한 조사를 수행합니다. 이 목표를 적용한 결과 변환의 예가 그림 2에 나와 있습니다. 우리는 이 목표를 섹션 3.3의 다른 많은 변형과 경험적으로 비교합니다.

그림 2 : 기본 모델에서 사용하는 목표의 개략도입니다. 이 예에서는 “지난주 파티에 초대해 주셔서 감사합니다.”라는 문장을 처리합니다. "for", "inviting" 및 "last"(×로 표시)라는 단어는 손상을 위해 무작위로 선택됩니다. 손상된 토큰의 각 연속 범위는 예제에서 고유한 센티널 토큰(<X> 및 <Y>로 표시)으로 대체됩니다. "for"와 "inviting"이 연속적으로 발생하므로 단일 센티넬 <X>로 대체됩니다. 그런 다음 출력 시퀀스는 입력에서 이를 대체하는 데 사용되는 센티넬 토큰과 최종 센티넬 토큰 <Z>로 구분된 삭제된 범위로 구성됩니다.
3.1.5. 기준 성능
이 섹션에서는 위에서 설명한 기본 실험 절차를 사용하여 결과를 제시하여 일련의 다운스트림 작업에서 어떤 종류의 성능을 기대할 수 있는지 파악합니다.
이상적으로는 연구의 모든 실험을 여러 번 반복하여 결과에 대한 신뢰 구간을 얻습니다. 안타깝게도 우리가 실행하는 수많은 실험으로 인해 이는 엄청나게 많은 비용이 소요될 것입니다. 더 저렴한 대안으로 기본 모델을 처음부터 10번 훈련하고(즉, 다양한 무작위 초기화 및 데이터 세트 셔플링을 사용하여) 이러한 기본 모델 실행에 대한 분산이 각 실험 변형에도 적용된다고 가정합니다. 우리가 수행하는 대부분의 변경 사항은 실행 간 차이에 극적인 영향을 미칠 것으로 예상하지 않으므로 이는 다양한 변경 사항의 중요성에 대한 합리적인 표시를 제공해야 합니다. 이와 별도로, 사전 훈련 없이 모든 다운스트림 작업에 대해 2^18단계(미세 조정에 사용하는 것과 동일한 수)에 대한 모델 훈련 성능도 측정합니다.
이를 통해 기준 설정에서 사전 훈련이 모델에 얼마나 많은 이점을 제공하는지 알 수 있습니다.

표 1 : 기본 모델 및 훈련 절차를 통해 얻은 점수의 평균 및 표준 편차입니다. 비교를 위해 기본 모델을 미세 조정하는 데 사용된 것과 동일한 단계 수에 대해 처음부터(즉, 사전 학습 없이) 각 작업을 학습할 때의 성능도 보고합니다. 이 표의 모든 점수(및 표 14를 제외한 본 논문의 모든 표)는 각 데이터 세트의 검증 세트에 대해 보고됩니다.
본문에 결과를 보고할 때 공간을 절약하고 해석을 쉽게 하기 위해 모든 벤치마크에서 점수의 하위 집합만 보고합니다. GLUE 및 SuperGLUE의 경우 "GLUE" 및 "SGLUE"라는 제목 아래에 공식 벤치마크에 규정된 모든 하위 작업의 평균 점수를 보고합니다. 모든 번역 작업에 대해 "exp" 평활화 및 "intl" 토큰화를 사용하여 SacreBLEU v1.3.0(Post, 2018)에서 제공하는 BLEU 점수(Papineni et al., 2002)를 보고합니다. WMT 영어-독일어, 영어-프랑스어, 영어-루마니아어 점수를 각각 EnDe, EnFr 및 EnRo라고 합니다. CNN/Daily Mail의 경우 ROUGE-1-F, ROUGE-2-F 및 ROUGE-L-F 측정항목(Lin, 2004)에 대한 모델 성능이 높은 상관관계가 있음을 확인하여 ROUGE-2-F 점수를 보고합니다. "CNNDM"이라는 제목 아래 단독으로. 마찬가지로 SQuAD의 경우 "정확한 일치"와 "F1" 점수의 성능이 높은 상관 관계가 있음을 확인하므로 "정확한 일치" 점수만 보고합니다. 표 16, 부록 E의 모든 실험에 대해 모든 작업에서 달성한 모든 점수를 제공합니다.
우리의 결과 테이블은 모두 각 행이 각 벤치마크에 대한 점수를 제공하는 열과 함께 특정 실험 구성에 해당하도록 형식화되었습니다. 대부분의 테이블에는 기준 구성의 평균 성능이 포함됩니다. 기본 구성이 나타날 때마다 이를 표 1의 첫 번째 행과 같이 표시합니다. 또한 주어진 실험에서 최대값(최고값)의 두 표준편차 내에 있는 모든 점수를 확인합니다.
기본 결과는 표 1에 나와 있습니다. 전반적으로 결과는 비슷한 크기의 기존 모델과 비슷합니다. 예를 들어, BERTBASE는 SQuAD에서 80.8의 정확한 일치 점수와 MNLI 일치에서 84.4의 정확도를 달성한 반면, 우리는 각각 80.88과 84.24를 달성했습니다(표 16 참조). 우리의 기준선은 인코더-디코더 모델이고 대략 1/4 단계만큼 사전 훈련되었기 때문에 기준선을 BERTBASE와 직접 비교할 수 없습니다. 당연히 사전 훈련이 거의 모든 벤치마크에서 상당한 이득을 제공한다는 사실을 발견했습니다. 유일한 예외는 WMT 영어에서 프랑스어로, 이는 사전 훈련을 통해 얻을 수 있는 이득이 미미할 정도로 충분히 큰 데이터 세트입니다. 우리는 고자원 체제에서 전이 학습의 동작을 테스트하기 위해 실험에 이 작업을 포함했습니다. 가장 성능이 좋은 체크포인트를 선택하여 조기 중지를 수행하기 때문에 기준과 "사전 훈련 없음" 사이의 큰 차이는 사전 훈련이 제한된 데이터로 작업 성능을 얼마나 향상시키는지 강조합니다. 본 논문에서는 데이터 효율성의 향상을 명시적으로 측정하지는 않지만 이것이 전이 학습 패러다임의 주요 이점 중 하나임을 강조합니다.
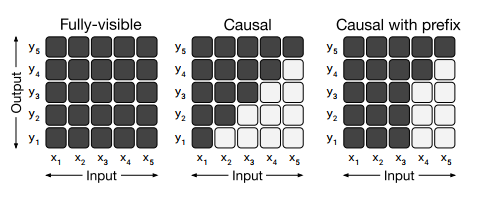
그림 3 : 다양한 주의 마스크 패턴을 나타내는 행렬. Self-Attention 메커니즘의 입력과 출력은 각각 x와 y로 표시됩니다. 행 i와 열 j의 어두운 셀은 self-attention 메커니즘이 출력 시간 단계 i에서 입력 요소 j에 참석할 수 있음을 나타냅니다. 밝은 셀은 self-attention 메커니즘이 해당 i 및 j 조합에 참여하는 것이 허용되지 않음을 나타냅니다. 왼쪽: 완전히 표시되는 마스크를 사용하면 self-attention 메커니즘이 모든 출력 단계에서 전체 입력에 주의를 기울일 수 있습니다. 중간: 인과 마스크는 i번째 출력 요소가 "미래"의 입력 요소에 의존하는 것을 방지합니다. 오른쪽: 접두사가 있는 인과 마스킹을 사용하면 self-attention 메커니즘이 입력 시퀀스의 일부에 완전히 표시되는 마스킹을 사용할 수 있습니다.
실행 간 변동의 경우 대부분의 작업에서 실행 간 표준 편차가 작업 기준 점수의 1%보다 작다는 것을 알 수 있습니다. 이 규칙의 예외에는 GLUE 및 SuperGLUE 벤치마크의 리소스가 적은 작업인 CoLA, CB 및 COPA가 포함됩니다. 예를 들어, CB에서 기본 모델의 평균 F1 점수는 91.22이고 표준 편차는 3.237입니다(표 16 참조). 이는 부분적으로 CB의 검증 세트에 56개의 예제만 포함되어 있기 때문일 수 있습니다. GLUE 및 SuperGLUE 점수는 각 벤치마크를 구성하는 작업 전체의 점수 평균으로 계산됩니다. 결과적으로 CoLA, CB 및 COPA의 높은 실행 간 변동으로 인해 GLUE 및 SuperGLUE 점수만 사용하여 모델을 비교하기가 더 어려워질 수 있습니다.
3.2. 아키텍처
Transformer는 원래 인코더-디코더 아키텍처로 도입되었지만 NLP를 위한 전이 학습에 대한 최신 작업에서는 대체 아키텍처를 사용합니다. 이 섹션에서는 이러한 아키텍처 변형을 검토하고 비교합니다.
3.2.1. 모델 구조
다양한 아키텍처를 구별하는 주요 요소는 모델의 다양한 주의 메커니즘에서 사용되는 "마스크"입니다. Transformer의 self-attention 작업은 시퀀스를 입력으로 사용하고 동일한 길이의 새 시퀀스를 출력한다는 점을 기억하세요. 출력 시퀀스의 각 항목은 입력 시퀀스 항목의 가중 평균을 계산하여 생성됩니다. 구체적으로 yi는 출력 시퀀스의 i번째 요소를 나타내고 xj는 입력 시퀀스의 j번째 항목을 나타냅니다. yi는 Σj wi,j xj로 계산됩니다. 여기서 wi,j는 xi 및 xj의 함수로서 self-attention 메커니즘에 의해 생성된 스칼라 가중치입니다. 그런 다음 어텐션 마스크는 주어진 출력 시간 단계에서 어떤 입력 항목을 처리할 수 있는지 제한하기 위해 특정 가중치를 0으로 만드는 데 사용됩니다. 우리가 고려할 마스크의 다이어그램은 그림 3에 나와 있습니다. 예를 들어 인과 마스크(그림 3, 중간)는 j > i인 경우 모든 wi,j를 0으로 설정합니다.
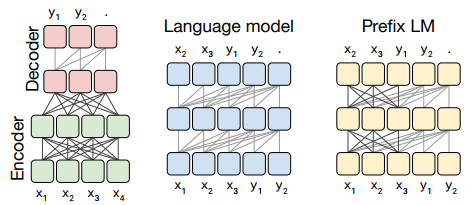
그림 4 : 우리가 고려하는 Transformer 아키텍처 변형의 회로도. 이 다이어그램에서 블록은 시퀀스의 요소를 나타내고 선은 주의 가시성을 나타냅니다. 다양한 색상의 블록 그룹은 다양한 Transformer 레이어 스택을 나타냅니다. 어두운 회색 선은 완전히 보이는 마스킹에 해당하고 밝은 회색 선은 인과 마스킹에 해당합니다. 우리는 사용 "." 예측의 끝을 나타내는 특수 시퀀스 끝 토큰을 나타냅니다. 입력 및 출력 시퀀스는 각각 x와 y로 표시됩니다. 왼쪽: 표준 인코더-디코더 아키텍처는 디코더에서 인과 마스킹과 함께 인코더 및 인코더-디코더 주의에서 완전히 표시되는 마스킹을 사용합니다. 중간: 언어 모델은 단일 Transformer 레이어 스택으로 구성되며 전체적으로 인과 마스크를 사용하여 입력과 대상의 연결이 제공됩니다. 오른쪽: 언어 모델에 접두사를 추가하는 것은 입력에 대해 완전히 표시되는 마스킹을 허용하는 것과 같습니다.
우리가 고려하는 첫 번째 모델 구조는 두 개의 레이어 스택(입력 시퀀스를 제공하는 인코더와 새로운 출력 시퀀스를 생성하는 디코더)으로 구성된 인코더-디코더 변환기입니다. 이 아키텍처 변형의 개략도는 그림 4의 왼쪽 패널에 표시됩니다.
인코더는 "완전히 보이는" 주의 마스크를 사용합니다. 완전히 표시되는 마스킹을 사용하면 출력의 각 항목을 생성할 때 입력의 모든 항목에 주의를 기울이는 자체 주의 메커니즘이 가능합니다. 그림 3(왼쪽)에서 이 마스킹 패턴을 시각화합니다. 이러한 형태의 마스킹은 "접두사", 즉 나중에 예측할 때 사용되는 모델에 제공되는 일부 컨텍스트를 다룰 때 적합합니다. BERT(Devlin et al., 2018)는 또한 완전히 표시되는 마스킹 패턴을 사용하고 특수 "분류" 토큰을 입력에 추가합니다. 분류 토큰에 해당하는 시점의 BERT 출력은 입력 시퀀스 분류를 위한 예측에 사용됩니다.
Transformer 디코더의 self-attention 작업은 "인과적" 마스킹 패턴을 사용합니다. 출력 시퀀스의 i번째 항목을 생성할 때 인과 마스킹은 모델이 j > i에 대한 입력 시퀀스의 j번째 항목에 참석하는 것을 방지합니다. 이는 모델이 출력을 생성할 때 "미래를 볼" 수 없도록 훈련 중에 사용됩니다. 이 마스킹 패턴에 대한 주의 매트릭스는 그림 3의 중앙에 나와 있습니다.
인코더-디코더 변환기의 디코더는 출력 시퀀스를 자동 회귀적으로 생성하는 데 사용됩니다. 즉, 각 출력 시간 단계에서 토큰은 모델의 예측 분포에서 샘플링되고 이 샘플은 다음 출력 시간 단계에 대한 예측을 생성하기 위해 모델로 다시 공급됩니다. 따라서 인코더가 없는 Transformer 디코더는 언어 모델(LM), 즉 다음 단계 예측만을 위해 훈련된 모델로 사용될 수 있습니다(Liu et al., 2018; Radford et al., 2018; Al-Rfou 외, 2019). 이것이 우리가 고려하는 두 번째 모델 구조를 구성합니다. 이 아키텍처의 개략도는 그림 4의 중앙에 나와 있습니다. 실제로 NLP를 위한 전이 학습에 대한 초기 연구에서는 사전 훈련 방법으로 언어 모델링 목표와 함께 이 아키텍처를 사용했습니다(Radford et al., 2018).
언어 모델은 일반적으로 압축 또는 시퀀스 생성에 사용됩니다(Graves, 2013). 그러나 입력과 대상을 연결하기만 하면 텍스트-텍스트 프레임워크에서 사용할 수도 있습니다. 예를 들어 영어에서 독일어로 번역하는 경우를 생각해 보세요. 입력 문장이 "좋습니다"인 훈련 데이터 포인트가 있는 경우입니다. 목표가 "Das ist Gut."인 경우 연결된 입력 시퀀스인 "영어를 독일어로 번역: 좋습니다."에 대한 다음 단계 예측에 대해 모델을 훈련하기만 하면 됩니다. 목표: Das ist Gut.” 이 예에 대한 모델의 예측을 얻으려면 모델에 "영어를 독일어로 번역: 좋습니다."라는 접두사가 제공됩니다. target:” 그리고 시퀀스의 나머지 부분을 자동 회귀적으로 생성하라는 요청을 받습니다. 이러한 방식으로 모델은 입력이 주어지면 출력 순서를 예측할 수 있으며 이는 텍스트-텍스트 작업의 요구 사항을 충족합니다. 이 접근 방식은 최근 언어 모델이 감독 없이 텍스트를 텍스트로 변환하는 작업을 수행하는 방법을 학습할 수 있음을 보여주기 위해 사용되었습니다(Radford et al., 2019).
텍스트-텍스트 설정에서 언어 모델을 사용할 때 기본적이고 자주 인용되는 단점은 인과 마스킹으로 인해 입력 시퀀스의 i번째 항목에 대한 모델 표현이 i까지의 항목에만 의존하게 된다는 것입니다. 이것이 잠재적으로 불리한 이유를 확인하려면 예측을 요청하기 전에 모델에 접두사/컨텍스트가 제공되는 텍스트-텍스트 프레임워크를 고려하십시오(예: 접두사는 영어 문장이고 모델은 독일어 문장을 예측하도록 요청됩니다). 번역). 완전한 인과 마스킹을 사용하면 모델의 접두사 상태 표현은 접두사의 이전 항목에만 의존할 수 있습니다. 따라서 출력 항목을 예측할 때 모델은 불필요하게 제한되는 접두사 표현에 주의를 기울입니다. 시퀀스-투-시퀀스 모델에서 단방향 순환 신경망 인코더를 사용하는 것에 대해 비슷한 주장이 제기되었습니다(Bahdanau et al., 2015).
Transformer 기반 언어 모델에서는 마스킹 패턴을 변경하기만 하면 이 문제를 피할 수 있습니다. 인과 마스크를 사용하는 대신 시퀀스의 접두사 부분에서 완전히 보이는 마스킹을 사용합니다. 이 마스킹 패턴과 결과 "접두사 LM"(우리가 고려하는 세 번째 모델 구조)의 개략도는 각각 그림 3과 4의 가장 오른쪽 패널에 설명되어 있습니다. 위에서 언급한 영어-독일어 번역 예에서는 "영어를 독일어로 번역: 좋습니다."라는 접두사에 완전히 표시되는 마스킹이 적용됩니다. target:” 및 인과 마스킹은 “Das istgut” 목표를 예측하기 위해 훈련 중에 사용됩니다. 텍스트-텍스트 프레임워크에서 접두사 LM을 사용하는 것은 원래 Liu et al. (2018). 에 의해 제안되었습니다. 최근에는 Dong et al. (2019)는 이 아키텍처가 다양한 텍스트-텍스트 작업에 효과적이라는 것을 보여주었습니다. 이 아키텍처는 인코더와 디코더 간에 매개변수가 공유되고 인코더-디코더 주의가 입력 및 대상 시퀀스 전체에 걸쳐 완전한 주의로 대체되는 인코더-디코더 모델과 유사합니다.
텍스트-텍스트 프레임워크를 따를 때 접두사 LM 아키텍처는 분류 작업에 대한 BERT(Devlin et al., 2018)와 매우 유사합니다. 이유를 알아보려면 전제가 "나는 비둘기를 싫어합니다."이고 가설은 "비둘기에 대한 나의 감정은 적개심으로 가득 차 있습니다."인 MNLI 벤치마크의 예를 살펴보세요. 올바른 라벨은 "수반"입니다.
이 예를 언어 모델에 제공하기 위해 이를 "mnli 전제: 나는 비둘기를 싫어합니다."라는 시퀀스로 변환합니다. 가설: 비둘기에 대한 나의 감정은 적개심으로 가득 차 있습니다. 목표 : 수반”. 이 경우 완전히 표시되는 접두사는 "target:"이라는 단어까지의 전체 입력 시퀀스에 해당하며, 이는 BERT에서 사용되는 "분류" 토큰과 유사한 것으로 볼 수 있습니다. 따라서 우리 모델은 전체 입력에 대한 완전한 가시성을 확보한 다음 "수반"이라는 단어를 출력하여 분류를 수행하는 임무를 맡게 됩니다. 모델은 작업 접두사(이 경우 "mnli")가 주어지면 유효한 클래스 레이블 중 하나를 출력하는 방법을 쉽게 배울 수 있습니다. 따라서 접두사 LM과 BERT 아키텍처의 주요 차이점은 분류기가 접두사 LM에 있는 Transformer 디코더의 출력 계층에 단순히 통합된다는 것입니다.
3.2.2. 다양한 모델 구조 비교
이러한 아키텍처 변형을 실험적으로 비교하기 위해 우리는 의미 있는 방식으로 동등하다고 간주되는 각 모델을 원합니다. 두 모델의 매개변수 수가 동일하거나 주어진(입력-시퀀스, 목표-시퀀스) 쌍을 처리하기 위해 대략 동일한 양의 계산이 필요한 경우 두 모델이 동일하다고 말할 수 있습니다. 불행하게도 이 두 가지 기준에 따라 인코더-디코더 모델을 언어 모델 아키텍처(단일 Transformer 스택으로 구성)와 동시에 비교하는 것은 불가능합니다. 그 이유를 알아보기 위해 먼저 인코더에 L 레이어가 있고 디코더에 L 레이어가 있는 인코더-디코더 모델은 2L 레이어가 있는 언어 모델과 거의 동일한 수의 매개 변수를 가집니다. 그러나 동일한 L + L 인코더-디코더 모델은 L 레이어만 있는 언어 모델과 거의 동일한 계산 비용을 갖습니다. 이는 언어 모델의 L 레이어가 입력 및 출력 시퀀스 모두에 적용되어야 하는 반면 인코더는 입력 시퀀스에만 적용되고 디코더는 출력 시퀀스에만 적용된다는 사실에 따른 결과입니다. 이러한 등가성은 대략적인 것입니다. 인코더-디코더 주의로 인해 디코더에 몇 가지 추가 매개변수가 있고 시퀀스 길이가 2차인 주의 레이어에 일부 계산 비용도 있습니다. 그러나 실제로 우리는 L 계층 언어 모델과 L + L 계층 인코더-디코더 모델의 단계 시간이 거의 동일하다는 것을 관찰했으며 이는 대략 동일한 계산 비용을 시사합니다. 또한 우리가 고려하는 모델 크기의 경우 인코더-디코더 주의 레이어의 매개변수 수는 전체 매개변수 수의 약 10%이므로 L + L 레이어 인코더-디코더 모델이 동일하다는 단순화된 가정을 합니다. 2L 계층 언어 모델의 매개변수 수.
합리적인 비교 수단을 제공하기 위해 인코더-디코더 모델에 대한 여러 구성을 고려합니다. BERTBASE 크기의 레이어 스택에 있는 레이어 수와 매개변수를 각각 L과 P라고 하겠습니다. 주어진 입력-대상 쌍을 처리하기 위해 L + L 계층 인코더-디코더 모델 또는 L 계층 디코더 전용 모델에 필요한 FLOP 수를 참조하기 위해 M을 사용합니다. 전체적으로 다음을 비교할 것입니다.
• 인코더에 L 레이어가 있고 디코더에 L 레이어가 있는 인코더-디코더 모델. 이 모델에는 2P 매개변수와 M FLOP의 계산 비용이 있습니다.
• 동등한 모델이지만 인코더와 디코더에서 매개변수를 공유하므로 P 매개변수와 M -FLOP 계산 비용이 발생합니다.
• 인코더와 디코더에 각각 L/2 레이어가 있는 인코더-디코더 모델로, P 매개변수와 M/2-FLOP 비용을 제공합니다.
• L 레이어와 P 매개변수가 포함된 디코더 전용 언어 모델과 결과적으로 M FLOP의 계산 비용이 발생합니다.
• 동일한 아키텍처(따라서 동일한 수의 매개변수 및 계산 비용)를 갖지만 입력에 대해 완전히 가시적인 self-attention을 갖는 디코더 전용 접두사 LM입니다.
3.2.3. 목표
비지도 목표로서 기본 언어 모델링 목표와 섹션 3.1.4에 설명된 기본 노이즈 제거 목표를 모두 고려할 것입니다. 사전 훈련 목표로 역사적으로 사용되었기 때문에 언어 모델링 목표를 포함합니다(Dai and Le, 2015; Ramachandran et al., 2016; Howard and Ruder, 2018; Radford et al., 2018; Peters et al., 2018 ) 뿐만 아니라 우리가 고려하는 언어 모델 아키텍처에 자연스럽게 적합합니다. 예측을 하기 전에 접두사를 수집하는 모델(인코더-디코더 모델 및 접두사 LM)의 경우 레이블이 지정되지 않은 데이터 세트에서 텍스트 범위를 샘플링하고 임의의 지점을 선택하여 접두사와 대상 부분으로 분할합니다. 표준 언어 모델의 경우 처음부터 끝까지 전체 범위를 예측하도록 모델을 훈련합니다. 우리의 감독되지 않은 잡음 제거 목표는 텍스트-텍스트 모델을 위해 설계되었습니다. 이를 언어 모델과 함께 사용하기 위해 섹션 3.2.1에 설명된 대로 입력과 대상을 연결합니다.
3.2.4. 결과
우리가 비교하는 각 아키텍처에서 얻은 점수는 표 2에 나와 있습니다. 모든 작업에 대해 잡음 제거 목표가 있는 인코더-디코더 아키텍처가 가장 잘 수행되었습니다. 이 변형은 가장 높은 매개변수 수(2P )를 갖지만 P 매개변수 디코더 전용 모델과 동일한 계산 비용을 갖습니다. 놀랍게도 인코더와 디코더 전체에서 매개변수를 공유하는 경우 거의 비슷한 성능을 발휘한다는 사실을 발견했습니다. 이와 대조적으로 인코더 및 디코더 스택의 레이어 수를 절반으로 줄이면 성능이 크게 저하됩니다. 동시 작업(Lan et al., 2019)에서는 Transformer 블록 전체에서 매개변수를 공유하는 것이 많은 성능을 희생하지 않고 총 매개변수 수를 줄이는 효과적인 수단이 될 수 있다는 사실도 발견했습니다. XLNet은 또한 잡음 제거 목표를 가진 공유 인코더-디코더 접근 방식과 일부 유사합니다(Yang et al., 2019). 또한 공유 매개변수 인코더-디코더는 디코더 전용 접두사 LM보다 성능이 뛰어나며 명시적인 인코더-디코더 주의를 추가하는 것이 유익하다는 것을 나타냅니다. 마지막으로 우리는 잡음 제거 목표를 사용하면 언어 모델링 목표에 비해 항상 더 나은 다운스트림 작업 성능을 얻을 수 있다는 널리 알려진 개념을 확인합니다. 이 관찰은 이전에 Devlin et al. (2018), Voita et al. (2019), Lample 및 Conneau (2019) 등이 있습니다. 다음 섹션에서는 비지도 목표에 대해 더 자세히 살펴보겠습니다.
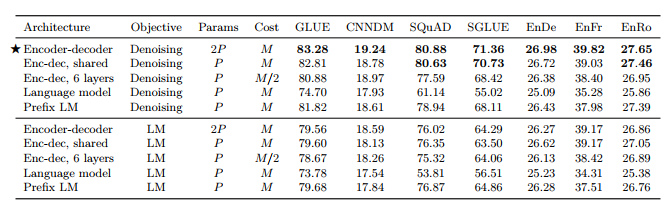
표 2 : 섹션 3.2.2에 설명된 다양한 아키텍처 변형의 성능. 우리는 P를 사용하여 12계층 기본 변환기 계층 스택의 매개변수 수를 참조하고 M을 사용하여 인코더-디코더 모델을 사용하여 시퀀스를 처리하는 데 필요한 FLOP를 참조합니다. 우리는 잡음 제거 목표(섹션 3.1.4에 설명됨)와 자동 회귀 목표(언어 모델을 훈련하는 데 일반적으로 사용됨)를 사용하여 각 아키텍처 변형을 평가합니다.
3.3. 지원되지 않는 목표
비지도 목표의 선택은 모델이 다운스트림 작업에 적용할 범용 지식을 얻는 메커니즘을 제공하므로 매우 중요합니다. 이로 인해 다양한 사전 훈련 목표가 개발되었습니다(Dai and Le, 2015; Ramachandran et al., 2016; Radford et al., 2018; Devlin et al., 2018; Yang et al., 2019; Liu 등, 2019b, Wang 등, 2019a, Song 등, 2019, Dong 등, 2019, Joshi 등, 2019).
이 섹션에서는 감독되지 않은 목표 공간에 대한 절차적 탐색을 수행합니다. 대부분의 경우 기존 목표를 정확하게 복제하지는 않습니다. 일부는 텍스트-텍스트 인코더-디코더 프레임워크에 맞게 수정되고, 다른 경우에는 여러 공통 접근 방식의 개념을 결합하는 목표를 사용합니다.
전반적으로 모든 목표는 레이블이 지정되지 않은 텍스트 데이터 세트에서 토큰화된 텍스트 범위에 해당하는 일련의 토큰 ID를 수집합니다. 토큰 시퀀스는 (손상된) 입력 시퀀스와 해당 대상을 생성하기 위해 처리됩니다. 그런 다음 모델은 목표 시퀀스를 예측할 가능성을 최대화하여 평소와 같이 훈련됩니다. 우리는 표 3에서 고려하는 많은 목표에 대한 예시를 제공합니다.
3.3.1. 서로 다른 높은 수준의 접근 방식
우선, 일반적으로 사용되는 목표에서 영감을 얻었지만 접근 방식이 크게 다른 세 가지 기술을 비교합니다. 먼저, 섹션 3.2.3에서 사용된 기본 "접두사 언어 모델링" 목표를 포함합니다. 이 기술은 텍스트 범위를 두 개의 구성 요소로 분할합니다. 하나는 인코더에 대한 입력으로 사용하고 다른 하나는 디코더에서 예측할 대상 시퀀스로 사용합니다. 둘째, BERT(Devlin et al., 2018)에서 사용되는 "Masked Language Modeling"(MLM) 목표에서 영감을 받은 목표를 고려합니다. MLM은 일정 범위의 텍스트를 가져와 토큰의 15%를 손상시킵니다. 손상된 토큰의 90%는 특수 마스크 토큰으로 대체되고, 10%는 무작위 토큰으로 대체됩니다. BERT는 인코더 전용 모델이므로 사전 학습 중 목표는 인코더 출력에서 마스킹된 토큰을 재구성하는 것입니다. 인코더-디코더의 경우 손상되지 않은 전체 시퀀스를 대상으로 사용합니다. 이는 손상된 토큰만 대상으로 사용하는 기본 목표와 다릅니다. 섹션 3.3.2에서 이 두 가지 접근 방식을 비교합니다. 마지막으로, 우리는 또한 기본적인 디셔핑 목적을 고려합니다. (Liu et al., 2019a)에서는 잡음 제거 순차 자동 인코더에 적용되었습니다. 이 접근 방식은 일련의 토큰을 가져와서 섞은 다음 원본 디셔플링된 시퀀스를 대상으로 사용합니다. 표 3의 처음 세 행에서는 이 세 가지 방법에 대한 입력 및 목표의 예를 제공합니다.
이 세 가지 목표의 성능은 표 4에 나와 있습니다. 전반적으로 BERT 스타일 목표가 가장 잘 수행되지만 접두사 언어 모델랑 목표는 번역 작업에서 비슷한 성능을 얻습니다. 실제로 BERT 목표의 동기는 언어 모델 기반 사전 훈련을 능가하는 것이었습니다. 디셔플링 목표는 접두사 언어 모델링과 BERT 스타일 목표보다 성능이 상당히 나쁩니다.

표 3 : 입력 텍스트 "지난주에 파티에 초대해 주셔서 감사합니다"에 적용되는 것으로 간주되는 일부 비지도 목표에 의해 생성된 입력 및 목표의 예입니다. 우리의 모든 목표는 토큰화된 텍스트를 처리한다는 점에 유의하세요. 이 특정 문장의 경우 모든 단어는 어휘에 의해 단일 토큰에 매핑되었습니다. 모델이 전체 입력 텍스트를 재구성하는 작업을 수행함을 나타 내기 위해 (원본 텍스트)를 대상으로 씁니다. <M>은 공유 마스크 토큰을 나타내고 <X>, <Y>, <Z>는 고유한 토큰 ID가 할당된 센티널 토큰을 나타냅니다. BERT 스타일 목표(두 번째 행)에는 일부 토큰이 임의의 토큰 ID로 대체되는 손상이 포함되어 있습니다. 회색으로 표시된 단어 apple을 통해 이를 보여줍니다.

표 4 : 섹션 3.3.1에 설명된 세 가지 서로 다른 사전 교육 목표를 수행합니다.
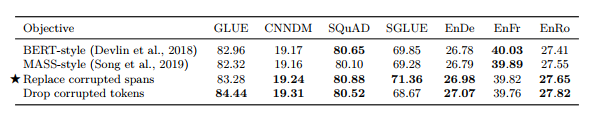
표 5 : BERT 스타일 사전 훈련 목표의 변형 비교. 처음 두 변형에서 모델은 손상되지 않은 원본 텍스트 세그먼트를 재구성하도록 훈련되었습니다. 후자의 경우 모델은 손상된 토큰의 순서만 예측합니다.
3.3.2. BERT 목표 단순화
이전 섹션의 결과를 바탕으로 이제 BERT 스타일 노이즈 제거 목표에 대한 수정을 탐색하는 데 중점을 둘 것입니다. 이 목표는 원래 분류 및 범위 예측을 위해 훈련된 인코더 전용 모델에 대한 사전 훈련 기술로 제안되었습니다. 따라서 인코더-디코더 텍스트-텍스트 설정에서 더 나은 성능을 발휘하거나 더 효율적이도록 수정하는 것이 가능할 수 있습니다.
먼저, 무작위 토큰 교환 단계를 포함하지 않는 BERT 스타일 목표의 간단한 변형을 고려합니다. 결과 목표는 단순히 입력에 있는 토큰의 15%를 마스크 토큰으로 대체하고 모델은 손상되지 않은 원래 시퀀스를 재구성하도록 훈련됩니다. 유사한 마스킹 대물렌즈가 Song et al. (2019) 에 의해 사용되었습니다. 이것이 "MASS"라고 했기 때문에 우리는 이 변형을 "MASS 스타일" 목표라고 부릅니다. 둘째, 디코더의 긴 시퀀스에 대한 self-attention이 필요하기 때문에 손상되지 않은 전체 텍스트 범위를 예측하는 것을 피하는 것이 가능한지 확인하는 데 관심이 있었습니다. 이를 달성하기 위해 두 가지 전략을 고려합니다. 첫째, 손상된 각 토큰을 마스크 토큰으로 교체하는 대신 손상된 토큰의 연속된 각 범위 전체를 고유한 마스크 토큰으로 교체합니다. 그런 다음 대상 시퀀스는 "손상된" 범위의 연결이 되며 각 범위에는 입력에서 이를 대체하는 데 사용되는 마스크 토큰이 앞에 붙습니다. 이는 섹션 3.1.4에 설명된 기준선에서 사용하는 사전 훈련 목표입니다. 둘째, 입력 시퀀스에서 손상된 토큰을 완전히 삭제하고 삭제된 토큰을 순서대로 재구성하는 작업을 모델에 할당하는 변형도 고려합니다. 이러한 접근법의 예는 표 3의 다섯 번째 및 여섯 번째 행에 나와 있습니다.
원래 BERT 스타일 목표와 이 세 가지 대안의 실증적 비교가 표 5에 나와 있습니다. 우리는 설정에서 이러한 모든 변형이 유사하게 수행된다는 것을 발견했습니다. 유일한 예외는 손상된 토큰을 삭제하면 CoLA의 상당히 높은 점수(60.04, 기준 평균 53.84에 비해, 표 16 참조) 덕분에 GLUE 점수가 약간 향상되었다는 것입니다. 이는 CoLA가 주어진 문장이 문법적으로나 구문적으로 허용 가능한지 여부를 분류하고, 토큰이 누락된 시기를 판단할 수 있는 것이 허용 가능성 감지와 밀접한 관련이 있다는 사실 때문일 수 있습니다.
그러나 토큰을 삭제하는 것은 SuperGLUE에서 센티넬 토큰으로 교체하는 것보다 성능이 완전히 나빴습니다. 전체 원본 시퀀스를 예측할 필요가 없는 두 가지 변형("손상된 범위 교체" 및 "손상된 범위 삭제")은 모두 대상 시퀀스를 더 짧게 만들고 결과적으로 훈련을 더 빠르게 만들기 때문에 잠재적으로 매력적입니다. 앞으로 우리는 손상된 범위를 센티넬 토큰으로 대체하고 손상된 토큰만 예측하는 변형을 탐색할 것입니다(기본 목표에서와 같이).
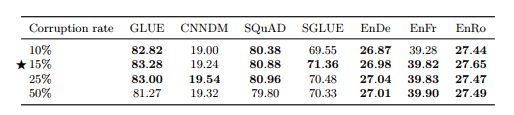
표 6 : i.i.d.의 성능 부패율이 다른 부패 목표.
3.3.3. 부패율 변화
지금까지 우리는 BERT에서 사용되는 가치인 토큰의 15%를 손상시켰습니다(Devlin et al., 2018). 다시 말하지만, 우리의 텍스트-텍스트 프레임워크는 BERT와 다르기 때문에 다른 손상률이 우리에게 더 나은지 확인하는 데 관심이 있습니다. 표 6에서 10%, 15%, 25%, 50%의 부패율을 비교합니다. 전반적으로 부패율이 모델 성능에 제한적인 영향을 미친다는 것을 알 수 있습니다. 유일한 예외는 우리가 고려하는 최대 손상률(50%)이 GLUE 및 SQuAD의 성능을 크게 저하시킨다는 것입니다.
더 높은 손상률을 사용하면 목표가 길어져 잠재적으로 훈련 속도가 느려질 수 있습니다. 이러한 결과와 BERT가 설정한 역사적 선례를 바탕으로 우리는 앞으로 부패율을 15%로 사용할 것입니다.
3.3.4. 스팬 손상
이제 우리는 더 짧은 목표를 예측하여 훈련 속도를 높이는 목표를 향해 나아갑니다. 지금까지 우리가 사용한 접근 방식은 i.i.d. 각 입력 토큰에 대한 손상 여부를 결정합니다. 여러 개의 연속 토큰이 손상된 경우 해당 토큰은 "범위"로 처리되며 단일 고유 마스크 토큰이 전체 범위를 대체하는 데 사용됩니다.
전체 범위를 단일 토큰으로 바꾸면 레이블이 지정되지 않은 텍스트 데이터가 더 짧은 시퀀스로 처리됩니다. 우리는 i.i.d.를 사용하고 있기 때문에 부패 전략에 있어서, 항상 상당한 수의 손상된 토큰이 연속적으로 나타나는 것은 아닙니다.
결과적으로 우리는 i.i.d.의 개별 토큰을 손상시키는 대신 특정 범위의 토큰을 손상시켜 추가적인 속도 향상을 얻습니다. 방법. 부패 범위는 이전에 BERT의 사전 훈련 목표로 간주되었으며 성능을 향상시키는 것으로 밝혀졌습니다 (Joshi et al., 2019).
이 아이디어를 테스트하기 위해 연속적이고 무작위 간격으로 배치된 토큰 범위를 구체적으로 손상시키는 목표를 고려합니다. 이 목표는 손상될 토큰의 비율과 손상된 전체 범위 수에 따라 매개변수화될 수 있습니다. 그런 다음 지정된 매개변수를 충족하기 위해 스팬 길이가 무작위로 선택됩니다. 예를 들어, 500개의 토큰 시퀀스를 처리 중이고 토큰의 15%가 손상되어야 하고 총 25개의 범위가 있어야 한다고 지정한 경우 손상된 토큰의 총 수는 500 × 0.15 = 75가 되며 평균은 500 × 0.15 = 75가 됩니다. 범위 길이는 75/25 = 3입니다. 원래 시퀀스 길이와 손상 비율이 주어지면 이 목표를 평균 범위 길이 또는 전체 범위 수로 동등하게 매개변수화할 수 있습니다.
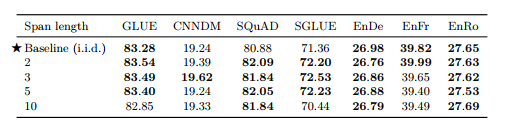
표 7 : 다양한 평균 범위 길이에 대한 범위 손상 목표(Joshi et al.(2019)에서 영감을 얻음)의 성능. 모든 경우에 원본 텍스트 시퀀스의 15%가 손상되었습니다.
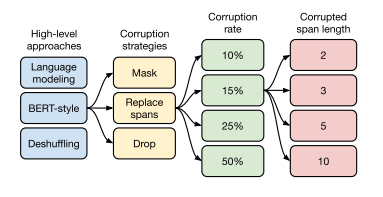
그림 5 : 비지도 목표 탐색의 흐름도. 먼저 섹션 3.3.1에서 몇 가지 서로 다른 접근 방식을 고려하고 BERT 스타일 노이즈 제거 목표가 가장 잘 수행된다는 것을 확인했습니다. 그런 다음 섹션 3.3.2에서 더 짧은 타겟 시퀀스를 생성하도록 BERT 목표를 단순화하는 다양한 방법을 고려합니다. 삭제된 범위를 센티넬 토큰으로 대체하는 것이 잘 수행되고 짧은 대상 시퀀스가 발생한다는 점을 고려하여 섹션 3.3.3에서 다양한 손상 비율을 실험합니다. 마지막으로 섹션 3.3.4에서 연속된 토큰 범위를 의도적으로 손상시키는 목표를 평가합니다.
표 7에서는 범위 손상 목표를 i.i.d 손상 목표와 비교합니다.
우리는 모든 경우에 15%의 손상률을 사용하고 평균 범위 길이 2, 3, 5 및 10을 사용하여 비교합니다. 다시 말하지만, 평균 범위 길이가 10인 버전은 약간 낮은 성능을 보이지만 이러한 목표 사이에는 제한된 차이가 있습니다. 경우에 따라 다른 값.
우리는 또한 특히 평균 스팬 길이 3을 사용하는 것이 i.i.d.보다 약간(그러나 상당히) 성능이 우수하다는 것을 발견했습니다. 대부분의 비번역 벤치마크에 대한 목표입니다. 다행스럽게도 범위 손상 목표는 i.i.d.에 비해 훈련 중에 약간의 속도 향상을 제공합니다. 범위 손상이 평균적으로 더 짧은 시퀀스를 생성하기 때문에 노이즈 접근 방식입니다.
3.3.5. 논의
그림 5는 비지도 목표를 탐색하는 동안 이루어진 선택의 흐름도를 보여줍니다. 전반적으로, 우리가 관찰한 성능에서 가장 중요한 차이점은 잡음 제거 목표가 사전 훈련을 위한 언어 모델링 및 디셔플링보다 성능이 뛰어나다는 것입니다. 우리가 조사한 노이즈 제거 목표의 다양한 변형에서 눈에 띄는 차이는 관찰되지 않았습니다. 그러나 목표(또는 목표의 매개변수화)가 다르면 시퀀스 길이가 달라져 훈련 속도도 달라질 수 있습니다. 이는 여기서 고려한 잡음 제거 목표 중에서 선택하는 것이 주로 계산 비용에 따라 수행되어야 함을 의미합니다. 우리의 결과는 또한 우리가 여기서 고려하는 것과 유사한 목표를 추가로 탐색해도 우리가 고려하는 작업과 모델에 대해 상당한 이익을 얻지 못할 수도 있음을 시사합니다. 대신 레이블이 지정되지 않은 데이터를 활용하는 완전히 다른 방법을 탐색하는 것이 운이 좋을 수도 있습니다.
3.4. 사전 훈련 데이터 세트
비지도 목표와 마찬가지로 사전 훈련 데이터 세트 자체는 전이 학습 파이프라인의 중요한 구성 요소입니다. 그러나 목표 및 벤치마크와 달리 새로운 사전 훈련 데이터 세트는 일반적으로 그 자체로는 중요한 기여로 간주되지 않으며 사전 훈련된 모델 및 코드와 함께 공개되지 않는 경우가 많습니다. 대신 새로운 방법이나 모델을 제시하는 과정에서 소개되는 경우가 많다. 결과적으로, 다양한 사전 학습 데이터 세트에 대한 비교가 상대적으로 적고 사전 학습에 사용되는 "표준" 데이터 세트가 부족했습니다. 최근 주목할만한 일부 예외(Baevski et al., 2019; Liu et al., 2019c; Yang et al., 2019)는 새로운 대규모(종종 Common Crawl 소스) 데이터 세트에 대한 사전 교육을 더 작은 기존 데이터를 사용하는 것과 비교했습니다. 설정합니다(종종 Wikipedia). 사전 훈련 데이터 세트가 성능에 미치는 영향을 더 깊이 조사하기 위해 이 섹션에서는 C4 데이터 세트의 변형과 기타 사전 훈련 데이터 소스를 비교합니다. 우리는 TensorFlow 데이터 세트의 일부로 간주하는 모든 C4 데이터 세트 변형을 출시합니다.
3.4.1. 라벨이 지정되지 않은 데이터 세트
C4를 만들 때 우리는 Common Crawl에서 웹에서 추출된 텍스트를 필터링하기 위해 다양한 경험적 방법을 개발했습니다(설명은 섹션 2.2 참조). 우리는 이 필터링이 다른 필터링 접근 방식 및 일반적인 사전 훈련 데이터 세트와 비교하는 것 외에도 다운스트림 작업의 성능을 향상시키는지 여부를 측정하는 데 관심이 있습니다. 이를 위해 다음 데이터 세트에 대한 사전 학습 후 기본 모델의 성능을 비교합니다.
C4 기준선으로 먼저 섹션 2.2에 설명된 대로 제안된 레이블이 없는 데이터 세트에 대한 사전 훈련을 고려합니다.
필터링되지 않은 C4 C4를 생성하는 데 사용한 경험적 필터링(중복 제거, 나쁜 단어 제거, 문장만 유지 등)의 효과를 측정하기 위해 이 필터링을 생략하는 대체 버전의 C4도 생성합니다. 영어 텍스트를 추출하기 위해 여전히 langDetect를 사용하고 있습니다. 결과적으로 langDetect는 때때로 자연스럽지 않은 영어 텍스트에 낮은 확률을 할당하기 때문에 "필터링되지 않은" 변형에는 여전히 일부 필터링이 포함되어 있습니다.
RealNews와 유사한 최근 연구에서는 뉴스 웹사이트에서 추출한 텍스트 데이터를 사용했습니다(Zellers et al., 2019; Baevski et al., 2019). 이 접근 방식과 비교하기 위해 "RealNews" 데이터 세트에 사용된 도메인 중 하나의 콘텐츠만 포함하도록 C4를 추가로 필터링하여 레이블이 지정되지 않은 또 다른 데이터 세트를 생성합니다(Zellers et al., 2019). 비교의 용이성을 위해 C4에서 사용된 휴리스틱 필터링 방법을 유지합니다. 유일한 차이점은 뉴스가 아닌 콘텐츠를 표면적으로 생략했다는 것입니다.
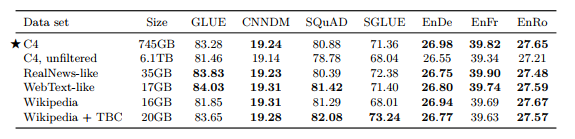
표 8 : 다양한 데이터 세트에 대한 사전 학습으로 인한 성능입니다. 처음 4개의 변형은 새로운 C4 데이터 세트를 기반으로 합니다.
WebText 유사 마찬가지로 WebText 데이터 세트(Radford et al., 2019)는 콘텐츠 집계 웹사이트 Reddit에 제출되고 최소 3점의 "점수"를 받은 웹페이지의 콘텐츠만 사용합니다. Reddit에 제출된 웹페이지의 점수 웹페이지를 지지(공감)하거나 반대(비추천)한 사용자의 비율을 기준으로 계산됩니다. Reddit 점수를 품질 신호로 사용하는 이유는 사이트 사용자가 고품질 텍스트 콘텐츠에만 찬성한다는 것입니다. 비교 가능한 데이터 세트를 생성하기 위해 우리는 먼저 OpenWebText 노력으로 준비된 목록에 나타난 URL에서 유래하지 않은 모든 콘텐츠를 C4에서 제거하려고 시도했습니다. 그러나 이로 인해 대부분의 콘텐츠가 약 2GB 정도에 불과했습니다. 페이지는 Reddit에 표시되지 않습니다. C4는 한 달 간의 Common Crawl 데이터를 기반으로 생성되었음을 기억하세요.
따라서 우리는 엄청나게 작은 데이터 세트를 사용하지 않기 위해 2018년 8월부터 2019년 7월까지 Common Crawl에서 12개월 간의 데이터를 다운로드하고 C4에 휴리스틱 필터링을 적용한 다음 Reddit 필터를 적용했습니다. 이로 인해 원래 40GB WebText 데이터 세트(Radford et al., 2019)와 비슷한 크기인 17GB WebText와 유사한 데이터 세트가 생성되었습니다.
Wikip edia Wikipedia 웹사이트는 공동으로 작성된 수백만 개의 백과사전 기사로 구성되어 있습니다. 사이트의 콘텐츠는 엄격한 품질 지침을 따르므로 깨끗하고 자연스러운 텍스트의 신뢰할 수 있는 소스로 사용되었습니다. 우리는 기사에서 마크업이나 참조 섹션을 생략한 TensorFlow Datasets13의 영어 Wikipedia 텍스트 데이터를 사용합니다.
Wikip edia + Toronto Bo oks Corpus Wikipedia의 사전 학습 데이터를 사용할 때의 단점은 자연 텍스트(백과사전 기사)의 가능한 도메인을 하나만 나타낸다는 것입니다.
이를 완화하기 위해 BERT(Devlin et al., 2018)는 Wikipedia의 데이터를 Toronto Books Corpus(TBC)(Zhu et al., 2015)와 결합했습니다. TBC에는 자연어의 다양한 영역을 나타내는 eBook에서 추출된 텍스트가 포함되어 있습니다. BERT의 인기로 인해 Wikipedia + TBC 조합이 많은 후속 작업에서 사용되었습니다.
이러한 각 데이터 세트에 대한 사전 학습 후 달성된 결과는 표 8에 나와 있습니다. 첫 번째로 확실한 점은 C4에서 휴리스틱 필터링을 제거하면 성능이 균일하게 저하되고 필터링되지 않은 변형이 모든 작업에서 최악의 성능을 발휘하게 된다는 것입니다. 이 외에도 우리는 어떤 경우에는 더 제한된 도메인을 가진 사전 훈련 데이터 세트가 다양한 C4 데이터 세트보다 성능이 우수하다는 것을 발견했습니다. 예를 들어 Wikipedia + TBC 코퍼스를 사용하면 SuperGLUE 점수 73.24가 생성되어 기준 점수(C4 사용) 71.36을 능가합니다. 이는 거의 전적으로 MultiRC의 Exact Match 점수가 25.78(기준, C4)에서 50.93(Wikipedia + TBC)으로 성능이 향상되었기 때문입니다(표 16 참조). MultiRC는 가장 큰 데이터 소스가 TBC에서 다루는 영역인 소설 책에서 나오는 독해 데이터 세트입니다. 마찬가지로 사전 훈련을 위해 RealNews와 유사한 데이터 세트를 사용하면 뉴스 기사에 대한 독해력을 측정하는 데이터 세트인 ReCoRD의 Exact Match 점수가 68.16에서 73.72로 증가했습니다. 마지막 예로, Wikipedia의 데이터를 사용하면 Wikipedia에서 가져온 구절이 포함된 질문 답변 데이터 세트인 SQuAD에서 상당한(그러나 덜 극적인) 이득을 얻었습니다.
이전 연구에서도 비슷한 관찰이 이루어졌습니다. Beltagyet al. (2019)은 연구 논문의 텍스트에 대해 BERT를 사전 훈련하면 과학 작업에 대한 성능이 향상된다는 것을 발견했습니다. 이러한 발견의 주요 교훈은 도메인 내 레이블이 없는 데이터에 대한 사전 교육이 다운스트림 작업의 성능을 향상시킬 수 있다는 것입니다. 우리의 목표가 임의 영역의 언어 작업에 빠르게 적응할 수 있는 모델을 사전 훈련하는 것이라면 이는 놀라운 일이 아니지만 불만족스럽습니다. Liu et al. (2019c)는 또한 보다 다양한 데이터 세트에 대한 사전 교육을 통해 다운스트림 작업이 개선되는 것을 관찰했습니다. 이 관찰은 또한 자연어 처리를 위한 영역 적응에 대한 평행선 연구에 동기를 부여합니다. 이 분야에 대한 조사는 예를 들어 다음을 참조하십시오. Ruder (2019); Li (2012).
단일 도메인에 대한 사전 훈련의 단점은 결과 데이터 세트가 종종 상당히 작다는 것입니다. 마찬가지로 WebText와 유사한 변종은 기준 설정에서 C4 데이터 세트보다 성능이 더 좋거나 Reddit 기반 필터링은 Common의 12배 더 많은 데이터를 기반으로 함에도 불구하고 C4보다 약 40배 작은 데이터 세트를 생성했습니다. 기다. 그러나 기본 설정에서는 2^35 ≒ 34B 토큰에 대해서만 사전 훈련을 했으며 이는 우리가 고려한 가장 작은 사전 훈련 데이터 세트보다 약 8배 더 큽니다. 다음 섹션에서는 더 작은 사전 학습 데이터 세트를 사용하여 문제가 발생하는 지점을 조사합니다.
3.4.2. 사전 훈련 데이터 세트 크기
C4를 생성하는 데 사용하는 파이프라인은 매우 큰 사전 훈련 데이터 세트를 생성할 수 있도록 설계되었습니다. 너무 많은 데이터에 액세스할 수 있으므로 예제를 반복하지 않고도 모델을 사전 학습할 수 있습니다. 사전 훈련 중에 예제를 반복하는 것이 다운스트림 성능에 도움이 될지 아니면 해로울지는 확실하지 않습니다. 사전 훈련 목표 자체가 확률론적이며 모델이 동일한 정확한 데이터를 여러 번 보는 것을 방지하는 데 도움이 될 수 있기 때문입니다.
제한된 레이블이 없는 데이터 세트 크기의 효과를 테스트하기 위해 우리는 C4의 인위적으로 잘린 버전에서 기본 모델을 사전 훈련했습니다. 우리는 2^35 ≒ 34B 토큰(C4 전체 크기의 작은 부분)에 대해 기본 모델을 사전 훈련했다는 점을 기억하세요. 2^29 , 2^27 , 2^25 및 2^23 토큰으로 구성된 C4의 잘린 변형에 대한 학습을 고려합니다. 이러한 크기는 사전 훈련 과정에서 데이터 세트를 각각 64, 256, 1,024, 4,096회 반복하는 것에 해당합니다.
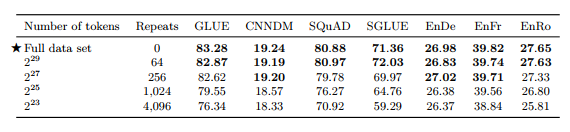
표 9 : 사전 학습 중 데이터 반복 효과를 측정합니다. 이 실험에서는 C4의 첫 번째 N 토큰(첫 번째 열에 표시된 다양한 N 값 포함)만 사용하지만 여전히 2^35개가 넘는 토큰을 사전 훈련합니다. 이로 인해 사전 훈련 과정에서 데이터 세트가 반복되고(각 실험의 반복 횟수는 두 번째 열에 표시됨) 암기될 수 있습니다(그림 6 참조).
결과적인 다운스트림 성능은 표 9에 나와 있습니다. 예상대로 데이터 세트 크기가 줄어들면 성능이 저하됩니다. 이는 모델이 사전 훈련 데이터 세트를 기억하기 시작하기 때문일 수 있다고 의심됩니다. 이것이 사실인지 측정하기 위해 그림 6에 각 데이터 세트 크기에 대한 훈련 손실을 표시합니다. 실제로 모델은 사전 훈련 데이터 세트의 크기가 줄어들면서 훈련 손실이 상당히 작아져 기억 가능성이 있음을 시사합니다. Baevskiet al. (2019)도 마찬가지로 사전 훈련 데이터 세트 크기를 자르면 다운스트림 작업 성능이 저하될 수 있음을 관찰했습니다.
사전 훈련 데이터 세트가 64회만 반복되면 이러한 효과가 제한된다는 점에 유의하세요. 이는 사전 훈련 데이터를 어느 정도 반복해도 해롭지 않을 수 있음을 나타냅니다. 그러나 추가적인 사전 훈련이 유익할 수 있고(섹션 3.6에서 볼 수 있듯이) 레이블이 없는 추가 데이터를 얻는 것이 저렴하고 쉽다는 점을 고려하면 가능할 때마다 대규모 사전 훈련 데이터 세트를 사용하는 것이 좋습니다. 또한 이 효과는 모델 크기가 클수록 더 두드러질 수 있습니다. 즉, 모델이 클수록 더 작은 사전 학습 데이터 세트에 과적합되는 경향이 더 클 수 있습니다.
3.5. 훈련 전략
지금까지 우리는 모델의 모든 매개변수가 개별 지도 작업에 대해 미세 조정되기 전에 비지도 작업에 대해 사전 훈련되는 설정을 고려했습니다. 이 접근 방식은 간단하지만 다운스트림/감독 작업에 대한 모델을 교육하기 위한 다양한 대체 방법이 제안되었습니다. 이 섹션에서는 여러 작업에 대해 동시에 모델을 훈련하는 접근 방식 외에도 모델을 미세 조정하기 위한 다양한 방식을 비교합니다.
3.5.1. 미세 조정 방법
모델의 모든 매개변수를 미세 조정하면 특히 자원이 부족한 작업에서 차선의 결과를 초래할 수 있다는 주장이 있었습니다(Peters et al., 2019). 텍스트 분류 작업을 위한 전이 학습에 대한 초기 결과는 고정된 사전 훈련된 모델에 의해 생성된 문장 임베딩을 공급받은 소규모 분류기의 매개변수만 미세 조정하는 것을 옹호했습니다(Subra-anian et al., 2018; Kiros et al., 2015; Logeswaran 및 Lee, 2018; Hill 외, 2016; Conneau 외, 2017). 이 접근 방식은 전체 디코더가 주어진 작업에 대한 대상 시퀀스를 출력하도록 훈련되어야 하기 때문에 인코더-디코더 모델에는 덜 적용 가능합니다. 대신, 인코더-디코더 모델 매개변수의 하위 집합만 업데이트하는 두 가지 대체 미세 조정 접근 방식에 중점을 둡니다.
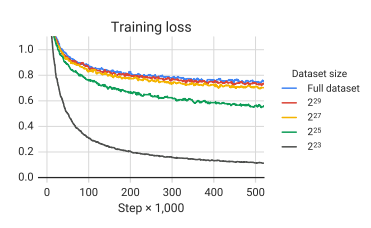
그림 6 : 원본 C4 데이터 세트와 4개의 인위적으로 잘린 버전에 대한 사전 훈련 손실입니다. 나열된 크기는 각 데이터 세트의 토큰 수를 나타냅니다. 고려된 네 가지 크기는 사전 훈련 과정에서 데이터 세트를 64~4,096회 반복하는 것에 해당합니다. 더 작은 데이터 세트 크기를 사용하면 훈련 손실 값이 더 작아지므로 레이블이 없는 데이터 세트를 어느 정도 기억할 수 있습니다.
첫 번째 "어댑터 레이어"(Houlsby et al., 2019; Bapna et al., 2019)는 미세 조정 중에 원래 모델의 대부분을 고정된 상태로 유지하려는 목표에 의해 동기가 부여되었습니다. 어댑터 계층은 Transformer의 각 블록에 있는 기존의 각 피드포워드 네트워크 뒤에 추가되는 추가적인 Dense-ReLU-dense 블록입니다. 이러한 새로운 피드포워드 네트워크는 출력 차원이 입력과 일치하도록 설계되었습니다. 이를 통해 구조나 매개변수를 추가로 변경하지 않고도 네트워크에 삽입할 수 있습니다. 미세 조정 시 어댑터 계층과 계층 정규화 매개변수만 업데이트됩니다. 이 접근 방식의 주요 초매개변수는 피드포워드 네트워크의 내부 차원 d이며, 이는 모델에 추가되는 새 매개변수의 수를 변경합니다. 우리는 d에 대해 다양한 값을 실험합니다.
우리가 고려하는 두 번째 대안 미세 조정 방법은 "점진적 동결 해제"입니다(Howard and Ruder, 2018). 점진적 동결 해제에서는 시간이 지남에 따라 점점 더 많은 모델 매개변수가 미세 조정됩니다. 점진적 동결 해제는 원래 단일 레이어 스택으로 구성된 언어 모델 아키텍처에 적용되었습니다. 이 설정에서는 미세 조정이 시작될 때 최종 레이어의 매개변수만 업데이트되고, 특정 수의 업데이트에 대한 학습 후에는 마지막에서 두 번째 레이어의 매개변수도 포함되는 식으로 전체 레이어가 업데이트될 때까지 계속됩니다. 네트워크의 매개변수가 미세 조정되고 있습니다. 이 접근 방식을 인코더-디코더 모델에 적용하기 위해 두 경우 모두 위에서부터 시작하여 인코더와 디코더의 레이어를 병렬로 점진적으로 고정 해제합니다. 입력 임베딩 행렬과 출력 분류 행렬의 매개변수는 공유되므로 미세 조정 과정에서 이를 업데이트합니다. 기본 모델은 인코더와 디코더에 각각 12개의 레이어로 구성되어 있으며 2^18 단계로 미세 조정되어 있습니다. 따라서 우리는 미세 조정 프로세스를 각각 2^18/12 단계의 12개 에피소드로 세분화하고 n번째 에피소드에서 레이어 12-n부터 12까지 학습합니다. Howard와 Ruder(2018)는 각 학습 에포크 후에 추가 레이어를 미세 조정할 것을 제안했습니다. 그러나 지도 데이터 세트의 크기가 매우 다양하고 다운스트림 작업 중 일부가 실제로 여러 작업(GLUE 및 SuperGLUE)의 혼합이기 때문에 대신 2^18/12 단계마다 추가 레이어를 미세 조정하는 더 간단한 전략을 채택합니다.
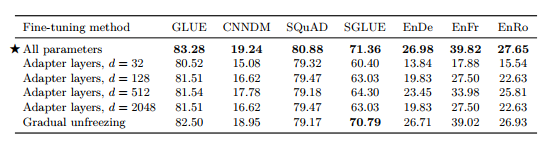
표 10 : 모델 매개변수의 하위 집합만 업데이트하는 다양한 대체 미세 조정 방법 비교. 어댑터 레이어의 경우 d는 어댑터의 내부 차원을 나타냅니다.
이러한 미세 조정 접근 방식의 성능 비교는 표 10에 나와 있습니다. 어댑터 레이어의 경우 내부 차원 d 32, 128, 512, 2048을 사용하여 성능을 보고합니다. 과거 결과에 따라(Houlsby et al., 2019 Bapna et al., 2019) SQuAD와 같은 저자원 작업은 작은 d 값으로 잘 작동하는 반면, 고차원 작업은 합리적인 성능을 달성하기 위해 큰 차원성이 필요하다는 것을 발견했습니다. 이는 차원이 작업 크기에 맞게 적절하게 조정되는 한 어댑터 레이어가 더 적은 매개변수로 미세 조정하는 유망한 기술이 될 수 있음을 시사합니다. 우리의 경우 구성 데이터 세트를 연결하여 GLUE와 SuperGLUE를 각각 단일 "작업"으로 처리합니다. 따라서 일부 저차원 데이터 세트로 구성되어 있지만 결합된 데이터 세트는 큰 d 값이 필요할 만큼 충분히 큽니다. 점진적인 동결 해제로 인해 모든 작업에서 성능이 약간 저하되지만 미세 조정 중에는 속도가 약간 향상되는 것으로 나타났습니다. 동결 해제 일정을 더 주의 깊게 조정하면 더 나은 결과를 얻을 수 있습니다.
3.5.2. 다중 작업 학습
지금까지 우리는 각 다운스트림 작업에서 개별적으로 미세 조정하기 전에 단일 비지도 학습 작업에 대해 모델을 사전 훈련했습니다. "다중 작업 학습"(Ruder, 2017; Caruana, 1997)이라는 대안적인 접근 방식은 한 번에 여러 작업에 대해 모델을 훈련하는 것입니다. 이 접근 방식의 목표는 일반적으로 한 번에 많은 작업을 동시에 수행할 수 있는 단일 모델을 교육하는 것입니다. 즉, 모델과 해당 매개변수의 대부분이 모든 작업에서 공유됩니다. 우리는 이 목표를 다소 완화하고 대신 각 개별 작업에서 잘 수행되는 별도의 매개변수 설정을 생성하기 위해 한 번에 여러 작업에 대한 교육 방법을 조사합니다. 예를 들어, 여러 작업에 대해 단일 모델을 훈련할 수 있지만 성능을 보고할 때 각 작업에 대해 서로 다른 체크포인트를 선택할 수 있습니다.
이는 다중 작업 학습 프레임워크를 느슨하게 하고 지금까지 고려한 사전 학습 후 미세 조정 접근 방식에 비해 더 공평한 기반을 마련합니다. 또한 통합된 텍스트-텍스트 프레임워크에서 "다중 작업 학습"은 단순히 데이터 세트를 함께 혼합하는 것에 해당합니다. 따라서 다중 작업 학습을 사용할 때 감독되지 않은 작업을 함께 혼합되는 작업 중 하나로 처리하여 레이블이 지정되지 않은 데이터를 훈련할 수 있습니다. 대조적으로, NLP에 대한 다중 작업 학습의 대부분의 적용은 작업별 분류 네트워크를 추가하거나 각 작업에 대해 서로 다른 손실 함수를 사용합니다(Liu et al., 2019b).
Arivazhagan et al. (2019). 이 지적한 바와 같이 다중 작업 학습에서 매우 중요한 요소는 모델이 훈련되어야 하는 각 작업의 데이터 양입니다. 우리의 목표는 모델을 과소 또는 과도하게 훈련하지 않는 것입니다. 즉, 모델이 주어진 작업에서 작업을 잘 수행할 수 있을 만큼 충분한 데이터를 볼 수 있기를 원하지만, 훈련 세트를 기억할 정도로 많은 데이터를 볼 수는 없습니다. 각 작업에서 나오는 데이터의 비율을 정확히 설정하는 방법은 데이터 세트 크기, 작업 학습의 "어려움"(즉, 작업을 효과적으로 수행하기 전에 모델이 알아야 하는 데이터의 양), 정규화 등 다양한 요소에 따라 달라질 수 있습니다. 추가적인 문제는 한 작업에서 좋은 성과를 달성하는 것이 다른 작업의 성과를 방해할 수 있는 "작업 간섭" 또는 "부정적 전환"의 가능성입니다. 이러한 우려를 고려하여 각 작업에서 나오는 데이터의 비율을 설정하기 위한 다양한 전략을 탐색하는 것부터 시작합니다. 비슷한 탐구가 Wang et al. (2019a). 에 의해 수행되었습니다.
예제 - 비례 혼합 모델이 주어진 작업에 얼마나 빨리 과적합되는지를 결정하는 주요 요인은 작업의 데이터 세트 크기입니다. 따라서 혼합 비율을 설정하는 자연스러운 방법은 각 작업의 데이터 세트 크기에 비례하여 샘플링하는 것입니다. 이는 모든 작업에 대한 데이터 세트를 연결하고 결합된 데이터 세트에서 무작위로 예제를 샘플링하는 것과 같습니다. 그러나 우리는 다른 모든 작업보다 훨씬 더 큰 데이터 세트를 사용하는 비지도 노이즈 제거 작업을 포함하고 있습니다. 따라서 각 데이터 세트의 크기에 비례하여 단순히 샘플링하면 모델이 보는 대부분의 데이터에 레이블이 지정되지 않으며 모든 지도 작업에 대한 훈련이 부족해집니다. 감독되지 않은 작업이 없더라도 일부 작업(예: WMT 영어에서 프랑스어로)은 너무 커서 대부분의 배치가 유사하게 밀려납니다. 이 문제를 해결하기 위해 비율을 계산하기 전에 데이터 세트 크기에 인위적인 "한계"를 설정했습니다. 구체적으로 N개의 작업 데이터 세트 각각에 있는 예시의 수가 en이면 n ∈ {1, . . . , N } 그런 다음 훈련 중에 m번째 작업에서 예제를 샘플링할 확률을 rm = min(e_m , K )/Σ min(e_n , K )로 설정합니다. 여기서 K는 인공 데이터 세트 크기 제한입니다.
온도 규모 혼합 데이터 세트 크기 간의 큰 차이를 완화하는 또 다른 방법은 혼합 속도의 "온도"를 조정하는 것입니다. 이 접근 방식은 모델이 저자원 언어에 대해 충분히 훈련되었는지 확인하기 위해 다국어 BERT에서 사용되었습니다. 온도 T로 온도 스케일링을 구현하기 위해 각 작업의 혼합 속도 rm을 1/T의 거듭제곱으로 높이고 속도를 다시 정규화하여 그 합은 1이 됩니다. T = 1일 때 이 접근 방식은 예제 비례 혼합과 동일하며 T가 증가함에 따라 비율은 동일한 혼합에 가까워집니다. 데이터 세트 크기 제한 K(온도 스케일링 이전에 rm을 얻기 위해 적용됨)를 유지하지만 이를 K = 2^21의 큰 값으로 설정합니다. 온도가 증가하면 가장 큰 데이터 세트의 혼합 속도가 감소하기 때문에 큰 K 값을 사용합니다.
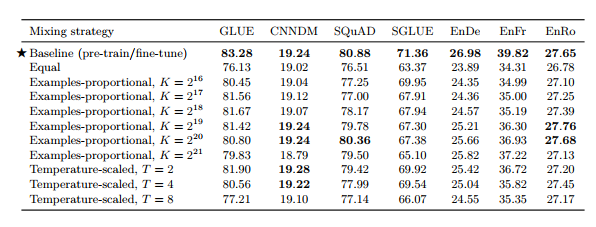
표 11 : 다양한 혼합 전략을 사용한 다중 작업 훈련 비교. 예제-비례 혼합은 최대 데이터 세트 크기에 인위적인 제한(K)을 두고 각 데이터 세트의 전체 크기에 따라 각 데이터 세트에서 예제를 샘플링하는 것을 말합니다. 온도 스케일링 혼합은 샘플링 속도를 온도 T만큼 재조정합니다. 온도 규모 혼합의 경우 인공 데이터 세트 크기 제한 K = 2^21을 사용합니다.
균등 혼합 이 경우 각 작업의 예제를 동일한 확률로 샘플링합니다. 구체적으로, 각 배치의 각 예는 우리가 훈련하는 데이터 세트 중 하나에서 무작위로 균일하게 샘플링됩니다. 모델은 리소스가 적은 작업에서는 빠르게 과적합되고 리소스가 많은 작업에서는 부족해지기 때문에 이는 최적이 아닌 전략일 가능성이 높습니다. 우리는 비율이 차선으로 설정되면 무엇이 잘못될 수 있는지에 대한 참조 지점으로 주로 포함합니다.
이러한 혼합 전략을 기본 사전 학습 후 미세 조정 결과와 동일한 기반에서 비교하기 위해 동일한 총 단계 수
(2^19 + 2^18 = 786,432)에 대해 다중 작업 모델을 학습합니다. 결과를 표 11에 나타내었다.
일반적으로 다중 작업 훈련은 대부분의 작업에 대한 미세 조정이 뒤따르는 사전 훈련보다 성능이 떨어지는 것으로 나타났습니다. 특히 "동일" 혼합 전략은 성능이 크게 저하되는 결과를 가져옵니다. 이는 리소스가 낮은 작업이 과적합되었거나, 리소스가 많은 작업에서 충분한 데이터를 확인하지 못했거나, 모델이 일반 학습을 위한 레이블이 지정되지 않은 데이터를 충분히 확인하지 못했기 때문일 수 있습니다. 목적 언어 능력. 예제-비례 혼합의 경우, 대부분의 작업에서 모델이 최상의 성능을 얻는 K에 대한 "최적 지점"이 있고 K 값이 크거나 작을수록 성능이 저하되는 경향이 있음을 발견했습니다. (우리가 고려한 K 값의 범위에 대한) 예외는 WMT 영어에서 프랑스어로의 번역이었습니다. 이는 자원이 많이 필요한 작업이므로 혼합 비율이 높을수록 항상 이점이 있습니다. 마지막으로, 온도 규모 혼합은 대부분의 경우 T = 2가 가장 좋은 성능을 발휘하면서 대부분의 작업에서 합리적인 성능을 얻을 수 있는 수단을 제공합니다. 다중 작업 모델이 각 개별 작업에 대해 훈련된 별도의 모델에 의해 성능이 우수하다는 사실은 이전에 관찰되었습니다. Arivazhagan 외. (2019) 및 McCann et al. (2018), 다중 작업 설정은 Liu et al. (2019b); 과 매우 유사한 작업 전반에 걸쳐 이점을 제공할 수 있는 것으로 나타났습니다. Ratneret al. (2018). 다음 섹션에서는 다중 작업 훈련과 사전 훈련 후 미세 조정 접근 방식 사이의 격차를 줄이는 방법을 살펴봅니다.
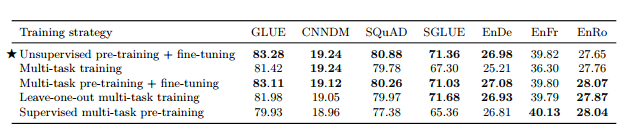
표 12 : 비지도 사전 훈련, 다중 작업 학습 및 다양한 형태의 다중 작업 사전 훈련 비교.
3.5.3. 다중 작업 학습과 미세 조정 결합
우리는 여러 작업이 혼합된 단일 모델을 훈련하지만 모델에 대해 다양한 매개변수 설정 체크포인트를 사용하여 성능을 평가할 수 있는 완화된 버전의 다중 작업 학습을 연구하고 있다는 점을 기억하세요. 모델이 모든 작업에 대해 동시에 사전 훈련된 다음 개별 감독 작업에 대해 미세 조정되는 경우를 고려하여 이 접근 방식을 확장할 수 있습니다. 이는 도입 당시 GLUE 등 벤치마크에서 최고 수준의 성능을 달성한 'MT-DNN'(Liu et al., 2015, 2019b)에서 사용하는 방식이다. 우리는 이 접근법의 세 가지 변형을 고려합니다. 먼저, 각 개별 다운스트림 작업에서 모델을 미세 조정하기 전에 인공 데이터 세트 크기 제한 K = 2^19를 사용하여 예제-비례 혼합에 대해 모델을 사전 훈련합니다. 이는 사전 훈련 중에 감독되지 않은 목표와 함께 감독된 작업을 포함하면 모델이 다운스트림 작업에 대한 유익한 조기 노출을 제공하는지 여부를 측정하는 데 도움이 됩니다. 또한 다양한 감독 소스를 혼합하면 사전 훈련된 모델이 개별 작업에 적용되기 전에 보다 일반적인 "기술" 세트(느슨하게 말하면)를 획득하는 데 도움이 될 수 있기를 바랄 수도 있습니다. 이를 직접 측정하기 위해 이 사전 훈련 혼합물에서 다운스트림 작업 중 하나를 생략한다는 점을 제외하고 동일한 예제-비례 혼합(K = 2^19)에서 모델을 사전 훈련하는 두 번째 변형을 고려합니다. 그런 다음 사전 훈련 중에 제외된 작업에 대해 모델을 미세 조정합니다. 우리가 고려하는 각 다운스트림 작업에 대해 이를 반복합니다.
우리는 이러한 접근 방식을 "leave-one-out" 다중 작업 훈련이라고 부릅니다. 이는 사전 훈련된 모델이 사전 훈련 중에 보지 못한 작업에 대해 미세 조정되는 실제 설정을 시뮬레이션합니다. 다중 작업 사전 훈련은 감독된 작업의 다양한 혼합을 제공합니다. 다른 분야(예: 컴퓨터 비전(Oquab et al., 2014; Jia et al., 2014; Huh et al., 2016; Yosinski et al., 2014))에서는 사전 훈련을 위해 지도 데이터 세트를 사용하므로 우리는 관심이 있었습니다. 다중 작업 사전 훈련 혼합에서 감독되지 않은 작업을 생략해도 여전히 좋은 결과가 나오는지 확인합니다. 따라서 세 번째 변형의 경우 K = 2^19로 고려하는 모든 감독 작업의 예시-비례 혼합에 대해 사전 훈련합니다. 이러한 모든 변형에서 우리는 2^18 단계에 대한 미세 조정 전에 2^19 단계에 대한 사전 학습의 표준 절차를 따릅니다.
표 12에서 이러한 접근 방식의 결과를 비교합니다. 비교를 위해 예제-비례 혼합에 대한 기준(사전 학습 후 미세 조정) 및 표준 다중 작업 학습(미세 조정 없음)에 대한 결과도 포함합니다. K = 2^19 . 다중 작업 사전 훈련 후 미세 조정을 수행하면 기준과 비슷한 성능을 얻을 수 있음을 발견했습니다.
이는 다중 작업 학습 후 미세 조정을 사용하면 섹션 3.5.2에 설명된 다양한 혼합 속도 간의 일부 균형을 완화하는 데 도움이 될 수 있음을 시사합니다. 흥미롭게도 "leave-one-out" 훈련의 성능은 약간 더 나빴습니다. 이는 다양한 작업에 대해 훈련된 모델이 여전히 새로운 작업에 적응할 수 있음을 시사합니다(즉, 다중 작업 사전 훈련은 극적인 결과를 가져오지 못할 수 있음). 작업 간섭). 마지막으로 감독된 다중 작업 사전 훈련은 번역 작업을 제외한 모든 경우에 훨씬 더 나쁜 성능을 보였습니다. 이는 번역 작업이 (영어) 사전 훈련의 이점이 적은 반면 감독되지 않은 사전 훈련은 다른 작업에서 중요한 요소임을 시사할 수 있습니다.
3.6. 스케일링
기계 학습 연구의 "씁쓸한 교훈"은 추가 계산을 활용할 수 있는 일반적인 방법이 궁극적으로 인간의 전문 지식에 의존하는 방법에 비해 승리한다고 주장합니다(Sutton, 2019; Hestness et al., 2017; Shazeer et al., 2017; Jozefowicz et al. ., 2016; Mahajan 등, 2018; Shazeer 등, 2018, 2017; Huang 등, 2018b; Keskar 등, 2019a).
최근 결과는 이것이 NLP의 전이 학습에 적용될 수 있음을 시사합니다(Liu et al., 2019c; Radford et al., 2019; Yang et al., 2019; Lan et al., 2019). 즉, 다음과 같이 반복적으로 나타났습니다. 확장하면 보다 신중하게 설계된 방법에 비해 성능이 향상됩니다. 그러나 더 큰 모델 사용, 더 많은 단계에 대한 모델 학습, 앙상블 등 다양한 확장 방법이 있습니다. 이 섹션에서는 다음 전제를 다루면서 이러한 다양한 접근 방식을 비교합니다. “방금 4배 더 많은 컴퓨팅이 제공되었습니다. 어떻게 사용해야 할까요?”
우리는 220M 매개변수를 갖고 각각 2^19단계와 2^18단계에 대해 사전 훈련 및 미세 조정된 기준 모델로 시작합니다. 인코더와 디코더는 모두 "BERTBASE"와 비슷한 크기입니다. 증가된 모델 크기를 실험하기 위해 "BERTLARGE" Devlin et al. (2018) 의 지침을 따릅니다. dff = 4096, dmodel = 1024, dkv = 64 및 16-헤드 주의 메커니즘을 사용합니다. 그런 다음 인코더와 디코더에서 각각 16개 및 32개 레이어로 구성된 두 가지 변형을 생성하여 원래 모델보다 2배 및 4배 많은 매개변수를 가진 모델을 생성합니다. 이 두 변형은 계산 비용도 대략 2배와 4배입니다.
기준선과 이 두 개의 더 큰 모델을 사용하여 4배 많은 계산을 사용하는 세 가지 방법을 고려합니다. 즉, 4배 더 많은 단계에 대한 학습, 2배 더 큰 모델로 2배 더 많은 단계에 대한 학습, 4배 더 큰 모델 학습입니다. 훈련 단계의 "기준" 수에 대해.
훈련 단계를 늘릴 때 단순화를 위해 사전 훈련 단계와 미세 조정 단계를 모두 확장합니다. 사전 훈련 단계 수를 늘리면 C4가 너무 커서 2^23단계를 훈련할 때에도 데이터에 대한 한 번의 전달을 완료하지 못하므로 더 많은 사전 훈련 데이터를 효과적으로 포함하게 됩니다.
모델이 4배 많은 데이터를 볼 수 있는 또 다른 방법은 배치 크기를 4배로 늘리는 것입니다. 이렇게 하면 더 효율적인 병렬화로 인해 잠재적으로 더 빠른 훈련이 가능해질 수 있습니다.
그러나 4배 더 큰 배치 크기를 사용한 교육은 4배 많은 단계에 대한 교육과 다른 결과를 얻을 수 있습니다(Shallue et al., 2018). 우리는 이 두 가지 사례를 비교하기 위해 4배 더 큰 배치 크기로 기본 모델을 훈련하는 추가 실험을 포함합니다.
우리가 고려하는 많은 벤치마크에서는 모델 앙상블을 사용하여 훈련하고 평가하여 추가 성능을 끌어내는 것이 일반적인 관행입니다. 이는 추가 계산을 사용하는 직교 방법을 제공합니다. 다른 스케일링 방법과 앙상블을 비교하기 위해 별도로 사전 훈련되고 미세 조정된 4개 모델의 앙상블 성능도 측정합니다. 우리는 총체적인 예측을 얻기 위해 출력 소프트맥스 비선형성에 로짓을 공급하기 전에 앙상블 전체의 로짓을 평균화합니다. 4개의 개별 모델을 사전 훈련하는 대신, 사전 훈련된 단일 모델을 사용하여 4개의 별도의 미세 조정 버전을 생성하는 것이 더 저렴한 대안입니다. 이는 전체 4배 계산 예산을 사용하지 않지만 이 방법을 포함하여 다른 확장 방법에 비해 경쟁력 있는 성능을 제공하는지 확인합니다.
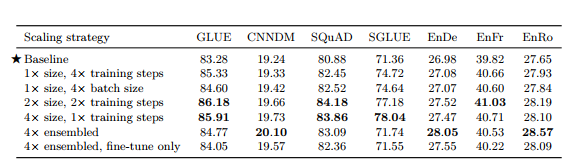
표 13 : 기본 모델을 확장하는 다양한 방법 비교. 미세 조정 모델 앙상블을 제외한 모든 방법은 4배의 계산을 기준으로 사용합니다. "크기"는 모델의 매개변수 수를 나타내고 "훈련 시간"은 사전 훈련과 미세 조정에 사용되는 단계 수를 나타냅니다.
이러한 다양한 스케일링 방법을 적용한 후 달성된 성능은 표 13에 나와 있습니다. 당연히 훈련 시간 및/또는 모델 크기를 늘리면 기준선이 지속적으로 향상됩니다. 4배 많은 단계에 대한 훈련과 4배 더 큰 배치 크기를 사용하는 것 사이에는 확실한 승자가 없었지만 둘 다 유익했습니다. 일반적으로 모델 크기를 늘리면 훈련 시간이나 배치 크기만 늘리는 것에 비해 성능이 추가로 향상됩니다. 우리가 연구한 작업에서 2배 더 큰 모델을 2배 더 오랫동안 훈련하는 것과 4배 더 큰 모델을 훈련하는 것 사이에는 큰 차이가 관찰되지 않았습니다. 이는 훈련 시간을 늘리고 모델 크기를 늘리는 것이 성능 향상을 위한 보완적인 수단이 될 수 있음을 시사합니다. 우리의 결과는 또한 앙상블이 규모를 통해 성능을 향상시키는 직교적이고 효과적인 수단을 제공한다는 것을 시사합니다. 일부 작업(CNN/DM, WMT 영어-독일어, WMT 영어-루마니아어)에서는 완전히 개별적으로 훈련된 4개의 모델을 앙상블하는 것이 다른 모든 확장 접근 방식보다 훨씬 뛰어난 성능을 보였습니다.
함께 사전 훈련되었지만 개별적으로 미세 조정된 앙상블 모델도 기준선에 비해 상당한 성능 향상을 제공했으며 이는 성능을 향상시키는 더 저렴한 방법을 제안합니다. 유일한 예외는 SuperGLUE였는데, 두 가지 앙상블 접근 방식 모두 기준선에 비해 크게 개선되지 않았습니다.
다양한 확장 방법에는 성능과 별개로 서로 다른 절충안이 있다는 점에 유의하세요. 예를 들어 더 큰 모델을 사용하면 다운스트림 미세 조정 및 추론 비용이 더 높아질 수 있습니다. 대조적으로, 소규모 모델을 더 오랫동안 사전 훈련하는 비용은 많은 다운스트림 작업에 적용되면 효과적으로 상각됩니다. 이와 별도로, N개의 개별 모델을 앙상블하는 것은 N × 더 높은 계산 비용을 갖는 모델을 사용하는 것과 비슷한 비용을 갖는다는 점에 주목합니다. 결과적으로, 확장 방법 중에서 선택할 때 모델의 최종 사용에 대한 몇 가지 고려 사항이 중요합니다.
3.7. 함께 모아서
이제 우리는 체계적인 연구에서 얻은 통찰력을 활용하여 인기 있는 NLP 벤치마크에서 성능을 얼마나 향상시킬 수 있는지 결정합니다. 우리는 또한 대량의 데이터에 대해 더 큰 모델을 훈련함으로써 NLP에 대한 전이 학습의 현재 한계를 탐색하는 데 관심이 있습니다. 기본 교육 접근 방식부터 시작하여 다음과 같이 변경합니다.
목표 i.i.d를 교체합니다. SpanBERT(Joshi et al., 2019)에서 느슨하게 영감을 받은 섹션 3.3.4에 설명된 범위 손상 목표에 대한 기준선의 노이즈 제거 목표입니다. 구체적으로 우리는 평균 범위 길이 3을 사용하고 원본 시퀀스의 15%를 손상시켰습니다. 우리는 이 목표가 더 짧은 목표 시퀀스 길이로 인해 약간 더 계산적으로 효율적이면서 약간 더 나은 성능을 생성한다는 것을 발견했습니다(표 7).
더 긴 훈련 우리의 기준 모델은 상대적으로 적은 양의 사전 훈련을 사용합니다(BERT 의 1/4(Devlin et al., 2018), XLNet(Yang et al., 2019)의 1/16, 1/64) RoBERTa(Liu et al., 2019c) 등)만큼. 다행스럽게도 C4는 데이터 반복 없이 상당히 오랫동안 훈련할 수 있을 만큼 충분히 큽니다(섹션 3.4.2에서 볼 수 있듯이 해로울 수 있음). 우리는 섹션 3.6에서 추가 사전 훈련이 실제로 도움이 될 수 있으며 배치 크기를 늘리고 훈련 단계 수를 늘리는 것이 이러한 이점을 제공할 수 있음을 발견했습니다. 따라서 우리는 길이가 512인 211개 시퀀스의 배치 크기에서 100만 단계에 대해 모델을 사전 훈련합니다. 이는 총 약 1조 개의 사전 훈련 토큰(기준의 약 32배)에 해당합니다. 섹션 3.4.1에서 우리는 RealNews와 유사한 WebText와 Wikipedia + TBC 데이터 세트에 대한 사전 훈련이 몇 가지 다운스트림 작업에서 C4에 대한 사전 훈련보다 성능이 우수하다는 것을 보여주었습니다. 그러나 이러한 데이터 세트 변형은 1조 개의 토큰에 대한 사전 훈련 과정에서 수백 번 반복될 만큼 충분히 작습니다. 섹션 3.4.2에서 이러한 반복이 해로울 수 있음을 보여주었기 때문에 대신 C4 데이터 세트를 계속 사용하기로 결정했습니다.
모델 크기 섹션 3.6에서는 기본 모델 크기를 확장하면 성능이 어떻게 향상되는지 보여주었습니다. 그러나 미세 조정이나 추론에 사용할 수 있는 계산 리소스가 제한된 환경에서는 더 작은 모델을 사용하는 것이 도움이 될 수 있습니다. 이러한 요소를 기반으로 우리는 다양한 크기의 모델을 교육합니다.
• 베이스. 이는 섹션 3.1.1에 하이퍼파라미터가 설명된 기본 모델입니다. 대략 2억 2천만 개의 매개변수가 있습니다.
• 작은. 우리는 dmodel = 512, dff = 2,048, 8-headed attention, 인코더와 디코더 각각에 6개의 레이어만 사용하여 기준선을 축소하는 더 작은 모델을 고려합니다. 이 변형에는 약 6천만 개의 매개변수가 있습니다.
• 크기가 큰. 우리의 기준선은 BERTBASE 크기의 인코더와 디코더를 사용하므로 인코더와 디코더의 크기와 구조가 모두 BERTLARGE와 유사한 변형도 고려합니다. 구체적으로 이 변형은 dmodel = 1,024, dff = 4,096, dkv = 64, 16-headed attention, 인코더와 디코더 각각의 24개 레이어를 사용하여 약 7억 7천만 개의 매개변수를 생성합니다.
• 3B 및 11B. 어떤 종류의 성능이 가능한지 더 자세히 알아보기 위해
더 큰 모델을 사용하여 두 가지 추가 변형을 고려합니다. 두 경우 모두 dmodel = 1024, 24 레이어 인코더 및 디코더, dkv = 128을 사용합니다. "3B" 변형의 경우 dff = 16,384를 32개 방향 주의로 사용하여 약 28억 개의 매개변수를 생성합니다. "11B"의 경우 dff = 65,536을 사용하고 128개 방향의 Attention을 사용하여 약 110억 개의 매개변수가 있는 모델을 생성합니다. 우리는 특히 현대 가속기(예: 모델을 훈련하는 TPU)가 Transformer의 피드포워드 네트워크와 같은 대규모 조밀 행렬 곱셈에 가장 효율적이기 때문에 dff를 확장하기로 결정했습니다.
다중 작업 사전 훈련 섹션 3.5.3에서 우리는 미세 조정 전에 감독되지 않은 작업과 감독된 작업이 혼합된 다중 작업에 대한 사전 훈련과 감독되지 않은 작업에 대한 사전 훈련이 효과적이라는 것을 보여주었습니다. 이것이 "MT-DNN"(Liu et al., 2015, 2019b)이 옹호하는 접근 방식입니다. 또한 단지 미세 조정이 아닌 전체 교육 기간 동안 "다운스트림" 성능을 모니터링할 수 있다는 실질적인 이점도 있습니다. 따라서 우리는 최종 실험 세트에서 다중 작업 사전 훈련을 사용했습니다. 우리는 더 오랫동안 훈련된 더 큰 모델이 더 작은 훈련 데이터 세트에 과적합될 가능성이 높기 때문에 레이블이 지정되지 않은 더 많은 비율의 데이터로부터 이익을 얻을 수 있다고 가정합니다. 그러나 섹션 3.5.3의 결과는 다중 작업 사전 훈련 후 미세 조정을 통해 레이블이 지정되지 않은 데이터의 최적이 아닌 비율을 선택함으로써 발생할 수 있는 일부 문제를 완화할 수 있음을 시사합니다. 이러한 아이디어를 기반으로 표준 예제-비례 혼합(섹션 3.5.2에 설명됨)을 사용하기 전에 레이블이 없는 데이터를 다음과 같은 인공 데이터 세트 크기로 대체합니다. 소형의 경우 710,000, 기본의 경우 2,620,000, 대형의 경우 8,660,000, 3B의 경우 33,500,000, 11B의 경우 133,000,000입니다.
모든 모델 변형에 대해 사전 훈련 중에 WMT 영어-프랑스어 및 WMT 영어-독일어 데이터 세트의 유효 데이터 세트 크기를 100만 개 예시로 제한했습니다.
개별 GLUE 및 SuperGLUE 작업 미세 조정 지금까지 GLUE 및 SuperGLUE를 미세 조정할 때 GLUE에 대해 한 번, SuperGLUE에 대해 한 번만 모델을 미세 조정하도록 각 벤치마크의 모든 데이터 세트를 연결했습니다. 이 접근 방식은 우리의 연구를 논리적으로 더 단순하게 만들지만, 개별적으로 작업을 미세 조정하는 것과 비교하여 일부 작업에서는 성능이 약간 희생된다는 것을 발견했습니다. 개별 작업을 미세 조정할 때 발생하는 잠재적인 문제(한 번에 모든 작업에 대한 교육을 통해 완화될 수 있음)는 리소스가 적은 작업에 빠르게 과적합할 수 있다는 것입니다.
예를 들어, 길이 211개, 시퀀스 512개의 대규모 배치 크기로 인해 리소스가 적은 GLUE 및 SuperGLUE 작업 중 다수에 대해 각 배치에서 전체 데이터 세트가 여러 번 표시됩니다. 따라서 우리는 각 GLUE 및 SuperGLUE 작업에 대한 미세 조정 중에 8개 길이-512 시퀀스의 더 작은 배치 크기를 사용합니다. 또한 모델이 과적합되기 전에 모델 매개변수에 액세스할 수 있도록 5,000단계가 아닌 1,000단계마다 체크포인트를 저장합니다.
빔 검색 이전 결과는 모두 그리디 디코딩을 사용하여 보고되었습니다. 출력 시퀀스가 긴 작업의 경우 빔 검색을 사용하면 성능이 향상되는 것으로 나타났습니다(Sutskever et al., 2014). 특히 WMT 변환 및 CNN/DM 요약 작업에 빔 폭 4와 길이 페널티 α = 0.6(Wu et al., 2016)을 사용합니다.
테스트 세트 이것이 최종 실험 세트이므로 검증 세트가 아닌 테스트 세트에 대한 결과를 보고합니다. CNN/Daily Mail의 경우 데이터 세트와 함께 배포된 표준 테스트 세트를 사용합니다. WMT 작업의 경우 이는 영어-독일어의 경우 newstest2014, 영어-프랑스어의 경우 newstest2015, 영어-루마니아어의 경우 newstest2016을 사용하는 것에 해당합니다. GLUE 및 SuperGLUE의 경우 벤치마크 평가 서버를 사용하여공식 테스트 세트 점수 계산. 15, 16 SQuAD의 경우 테스트 세트를 평가하려면 벤치마크 서버에서 추론을 실행해야 합니다. 불행하게도 이 서버의 계산 리소스는 가장 큰 모델에서 예측을 얻기에는 부족합니다. 결과적으로 우리는 대신 SQuAD 검증 세트에 대한 성능을 계속 보고합니다. 다행스럽게도 SQuAD 테스트 세트에서 가장 높은 성능을 보인 모델이 검증 세트에서도 결과를 보고했기 때문에 여전히 표면적으로는 최첨단과 비교할 수 있습니다.
위에서 언급한 변경 사항 외에도 우리는 기준과 동일한 훈련 절차와 하이퍼파라미터(AdaFactor 최적화 프로그램, 사전 훈련을 위한 역제곱근 학습 속도 일정, 미세 조정을 위한 일정한 학습 속도, 드롭아웃 정규화, 어휘 등)를 사용합니다. 참고로 이러한 세부 사항은 섹션 2에 설명되어 있습니다.
이 최종 실험 세트의 결과는 표 14에 나와 있습니다. 전반적으로 우리는 고려한 24개 작업 중 18개 작업에서 최첨단 성능을 달성했습니다. 예상대로 우리의 가장 큰(110억 매개변수) 모델은 모든 작업에 걸쳐 모델 크기 변형 중에서 가장 좋은 성능을 보였습니다.
우리의 T5-3B 모델 변형은 몇 가지 작업에서 이전 기술 수준을 능가했지만, 모델 크기를 110억 개의 매개변수로 확장하는 것이 최고의 성능을 달성하는 데 가장 중요한 요소였습니다. 이제 각 개별 벤치마크에 대한 결과를 분석합니다.
우리는 최첨단 평균 GLUE 점수 90.3을 달성했습니다. 특히, 자연어 추론 작업 MNLI, RTE 및 WNLI에 대한 성능은 이전 최첨단 기술보다 훨씬 향상되었습니다. RTE와 WNLI는 기계 성능이 역사적으로 각각 93.6과 95.9인 인간 성능보다 뒤처진 두 가지 작업입니다(Wang et al., 2018). 매개변수 수 측면에서 볼 때 11B 모델 변형은 GLUE 벤치마크에 제출된 모델 중 가장 큰 모델입니다. 그러나 가장 높은 점수를 받은 제출물은 대부분 예측을 생성하기 위해 많은 양의 앙상블 및 계산을 사용합니다. 예를 들어, ALBERT의 최고 성능 변형(Lan et al., 2019)은 3B 변형과 크기 및 아키텍처가 유사한 모델을 사용합니다(영리한 매개변수 공유로 인해 매개변수가 극적으로 적음). GLUE에서 인상적인 성능을 생성하기 위해 ALBERT 작성자는 작업에 따라 "6~17" 모델을 앙상블했습니다. 이로 인해 T5-11B보다 ALBERT 앙상블을 사용하여 예측을 생성하는 데 계산 비용이 더 많이 들 수 있습니다.
SQuAD의 경우 Exact Match 점수에서 이전 최첨단 기술(ALBERT(Lan et al., 2019))을 1점 이상 능가했습니다. SQuAD는 3년 전에 만들어진 오랜 벤치마크이며, 가장 최근의 개선으로 인해 최첨단 기술이 몇 퍼센트 포인트만 향상되었을 뿐입니다. 테스트 세트에 대한 결과가 보고될 때 일반적으로 모델 앙상블을 기반으로 하거나 외부 데이터 세트를 활용합니다(예: TriviaQA(Joshi et al., 2017) 또는 NewsQA(Trischler et al., 2016)) 작은 SQuAD 훈련 세트를 보강합니다. SQuAD의 인간 성능은 Exact Match 및 F1 측정 항목에 대해 각각 82.30 및 91.22로 추정되므로(Rajpurkar et al., 2016), 이 벤치마크의 추가 개선이 의미가 있는지는 확실하지 않습니다.
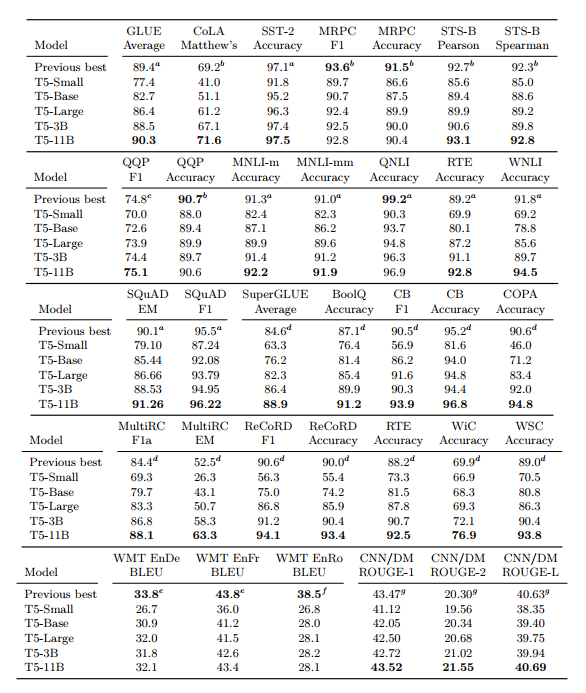
표 14 : 우리가 연구하는 모든 작업에 대한 T5 변형의 성능. 소형, 기본, 대형, 3B 및 11B는 각각 6천만, 2억 2천만, 7억 7천만, 30억 및 110억 개의 매개변수를 갖는 모델 구성을 나타냅니다. 각 표의 첫 번째 행에는 작업에 대한 최신 기술(2019년 10월 24일 기준)이 보고되어 있으며 위 첨자는 이 캡션 끝에 나열된 참고 자료와 소스를 나타냅니다. 검증 세트를 사용하는 SQuAD를 제외한 모든 결과는 테스트 세트에 보고됩니다. a(Lan 등, 2019) b(Wang 등, 2019c) c(Zhu 등, 2019) d(Liu 등, 2019c) e(Edunov 등, 2018) f(Lample 및 Conneau , 2019) g (동 외, 2019)
SuperGLUE의 경우 평균 점수 84.6(Liu et al., 2019c)에서 88.9로 큰 차이로 최첨단 기술을 개선했습니다. SuperGLUE는 "현재 최첨단 시스템의 범위를 벗어나지만 대부분의 대학 교육을 받은 영어 사용자가 해결할 수 있는" 작업을 포함하도록 설계되었습니다(Wang et al., 2019b). 우리는 인간의 성능 89.8과 거의 일치합니다(Wang et al., 2019b). 흥미롭게도 독해 작업(MultiRC 및 ReCoRD)에서 우리는 인간의 성능을 크게 능가하며 이러한 작업에 사용되는 평가 지표가 기계가 만든 예측에 편향될 수 있음을 시사합니다.
반면 인간은 COPA와 WSC 모두에서 100% 정확도를 달성했는데, 이는 우리 모델의 성능보다 훨씬 더 좋습니다. 이는 특히 자원이 부족한 환경에서 우리 모델이 완벽하게 하기 어려운 언어 작업이 남아 있음을 시사합니다.
우리는 WMT 번역 작업에서 최고의 성능을 달성하지 못했습니다.
이는 부분적으로 영어로만 레이블이 지정되지 않은 데이터 세트를 사용했기 때문일 수 있습니다. 또한 이러한 작업에 대한 최상의 결과 대부분은 정교한 데이터 확대 체계인 역번역(Edunov et al., 2018; Lample and Conneau, 2019)을 사용한다는 점에 주목합니다. 자원이 적은 영어-루마니아어 벤치마크의 최신 기술에서는 추가 형태의 교차 언어 비지도 학습도 사용합니다(Lample and Conneau, 2019). 우리의 결과는 규모와 영어 사전 훈련이 이러한 보다 정교한 방법의 성능을 맞추기에는 부족할 수 있음을 시사합니다. 좀 더 구체적으로 말하자면, 영어-독일어 newstest2014 세트에서 가장 좋은 결과는 WMT 2018(Edunov et al., 2018)의 훨씬 더 큰 훈련 세트를 사용하므로 결과와 직접 비교하기가 어렵습니다.
마지막으로 CNN/Daily Mail에서는 ROUGE-2-F 점수에서 상당한 수준에 불과했지만 최첨단 성능을 얻었습니다. ROUGE 점수의 개선이 반드시 더 일관된 요약과 일치하는 것은 아닌 것으로 나타났습니다(Paulus et al., 2017). 또한 CNN/Daily Mail은 추상적인 요약 벤치마크로 제시되지만 순수 추출적인 접근 방식이 잘 작동하는 것으로 나타났습니다(Liu, 2019). 또한 최대 가능성으로 훈련된 생성 모델은 반복적인 요약을 생성하는 경향이 있다는 주장도 있었습니다(See et al., 2017). 이러한 잠재적인 문제에도 불구하고 우리는 우리 모델이 일관되고 대체로 정확한 요약을 생성한다는 것을 발견했습니다. 부록 C에서는 체리가 선택되지 않은 검증 세트의 예를 제공합니다.
강력한 결과를 얻기 위해 T5는 실험 연구에서 얻은 통찰력을 전례 없는 규모와 결합합니다. 섹션 3.6에서 우리는 기본 모델의 사전 훈련 양이나 크기를 확장하면 상당한 이득을 얻을 수 있다는 것을 발견했습니다. 이를 고려하여 우리는 T5에 도입한 "비확장" 변경 사항이 T5의 강력한 성능에 얼마나 기여했는지 측정하는 데 관심이 있었습니다. 따라서 우리는 다음 세 가지 구성을 비교하는 최종 실험을 수행했습니다. 첫째, 2^35 ≒ 34B 토큰에 대해 사전 훈련된 표준 기준 모델입니다. 둘째, 기준선은 약 1조 개의 토큰(즉, T5에 사용된 것과 동일한 양의 사전 훈련)에 대해 훈련되었으며, 이를 "기준-1T"라고 합니다. 셋째, T5-Base입니다. 기준선-1T와 T5-Base 간의 차이점은 T5를 설계할 때 적용한 "비스케일링" 변경 사항으로 구성됩니다. 따라서 이 두 모델의 성능을 비교하면 체계적인 연구에서 얻은 통찰력의 영향을 구체적으로 측정할 수 있습니다.
이 세 가지 모델 구성의 성능은 표 15에 나와 있습니다. 섹션 3.6의 결과와 일치하여 추가 사전 훈련이 기준에 비해 성능을 향상시키는 것으로 나타났습니다. 그럼에도 불구하고 T5-Base는 모든 다운스트림 작업에서 기준선-1T보다 훨씬 뛰어난 성능을 발휘합니다. 이는 규모만이 T5의 성공에 기여하는 유일한 요소가 아님을 시사합니다. 우리는 더 큰 모델이 증가된 크기뿐만 아니라 이러한 비척도적 요인으로부터도 이익을 얻는다고 가정합니다.
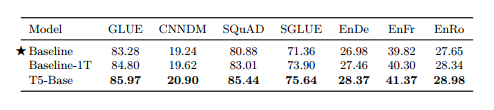
표 15 : T5-Base의 성능을 논문의 나머지 부분에 사용된 기본 실험 설정과 비교합니다. 결과는 검증 세트에 대해 보고됩니다. "Baseline-1T"는 2^35 ≒ 34B 토큰(기준에 사용된 것과 동일) 대신 1조 토큰(T5 모델 변형에 사용된 것과 동일한 수)에서 기준 모델을 사전 훈련하여 달성한 성능을 나타냅니다.
4. 고찰
체계적인 연구를 마친 후 가장 중요한 발견 중 일부를 요약하여 마무리합니다. 우리의 결과는 어느 정도 유망한 연구 방법에 대한 높은 수준의 관점을 제공합니다. 결론적으로, 우리는 이 분야를 더욱 발전시키기 위한 효과적인 접근 방식을 제공할 수 있다고 생각되는 몇 가지 주제에 대해 간략히 설명합니다.
4.1. 핵심사항
텍스트-텍스트 우리의 텍스트-텍스트 프레임워크는 동일한 손실 함수 및 디코딩 절차를 사용하여 다양한 텍스트 작업에 대한 단일 모델을 교육하는 간단한 방법을 제공합니다.
우리는 이 접근 방식이 추상 요약과 같은 생성 작업, 자연어 추론과 같은 분류 작업, STS-B와 같은 회귀 작업에 어떻게 성공적으로 적용될 수 있는지 보여주었습니다. 단순함에도 불구하고 텍스트-텍스트 프레임워크는 작업별 아키텍처와 비슷한 성능을 얻었으며 궁극적으로 규모와 결합 시 최첨단 결과를 생성했습니다.
아키텍처 NLP를 위한 전이 학습에 대한 일부 작업에서는 Transformer의 아키텍처 변형을 고려했지만 원래 인코더-디코더 형식이 텍스트-텍스트 프레임워크에서 가장 잘 작동한다는 것을 발견했습니다. 인코더-디코더 모델은 "인코더 전용"(예: BERT) 또는 "디코더 전용"(언어 모델) 아키텍처보다 두 배 더 많은 매개변수를 사용하지만 계산 비용은 비슷합니다. 또한 인코더와 디코더에서 매개변수를 공유해도 전체 매개변수 수를 절반으로 줄이면서 성능이 크게 떨어지지 않는다는 것을 보여주었습니다.
지원되지 않는 목표 전반적으로 우리는 무작위로 손상된 텍스트를 재구성하도록 모델을 훈련시키는 대부분의 "노이즈 제거" 목표가 텍스트-텍스트 설정에서 유사하게 수행된다는 것을 발견했습니다. 결과적으로, 감독되지 않은 사전 훈련이 계산적으로 더 효율적이도록 짧은 목표 시퀀스를 생성하는 목표를 사용하는 것이 좋습니다.
데이터 세트 우리는 Common Crawl 웹 덤프에서 경험적으로 정리된 텍스트로 구성된 "Colossal Clean Crawled Corpus"(C4)를 도입했습니다. 추가 필터링을 사용하는 데이터 세트와 C4를 비교할 때 도메인 내 레이블이 없는 데이터에 대한 교육이 몇 가지 다운스트림 작업의 성능을 향상시킬 수 있다는 것을 발견했습니다. 그러나 단일 도메인으로 제한하면 일반적으로 데이터 세트가 더 작아집니다. 우리는 레이블이 지정되지 않은 데이터 세트가 사전 훈련 과정에서 여러 번 반복될 만큼 작은 경우 성능이 저하될 수 있음을 별도로 보여주었습니다. 이는 일반적인 언어 이해 작업을 위해 C4와 같은 크고 다양한 데이터 세트를 사용하도록 동기를 부여합니다.
훈련 전략 우리는 미세 조정 중에 사전 훈련된 모델의 모든 매개변수를 업데이트하는 기본 접근 방식이 모든 매개변수를 업데이트하는 데 가장 비용이 많이 들지만 더 적은 수의 매개변수를 업데이트하도록 설계된 방법보다 성능이 우수하다는 것을 발견했습니다. 또한 한 번에 여러 작업에 대해 모델을 훈련하기 위한 다양한 접근 방식을 실험했습니다. 이는 텍스트 대 텍스트 설정에서 단순히 배치를 구성할 때 서로 다른 데이터 세트의 예제를 혼합하는 것에 해당합니다. 다중 작업 학습의 주요 관심사는 훈련할 각 작업의 비율을 설정하는 것입니다. 우리는 궁극적으로 감독되지 않은 사전 훈련과 감독된 미세 조정의 기본 접근 방식의 성능과 일치하는 혼합 비율을 설정하기 위한 전략을 찾지 못했습니다. 그러나 우리는 혼합 작업에 대한 사전 훈련 후 미세 조정이 감독되지 않은 사전 훈련과 비슷한 성능을 제공한다는 것을 발견했습니다.
확장 더 많은 데이터에 대한 모델 훈련, 더 큰 모델 훈련, 모델 앙상블 사용을 포함하여 추가 컴퓨팅을 활용하기 위한 다양한 전략을 비교했습니다. 더 많은 데이터로 더 작은 모델을 훈련하는 것이 더 적은 단계로 더 큰 모델을 훈련하는 것보다 성능이 더 좋은 경우가 많았음에도 불구하고 우리는 각 접근 방식이 성능을 크게 향상시키는 것을 발견했습니다. 또한 모델 앙상블이 추가 계산을 활용하는 직교 수단을 제공하는 단일 모델보다 훨씬 더 나은 결과를 제공할 수 있음을 보여주었습니다. 동일한 기본 사전 학습 모델에서 미세 조정된 앙상블 모델은 사전 학습 및 모든 모델을 완전히 개별적으로 미세 조정하는 것보다 성능이 나빴지만, 미세 조정 전용 앙상블은 여전히 단일 모델보다 성능이 훨씬 뛰어났습니다.
한계 극복 우리는 위의 통찰력을 결합하고 훨씬 더 큰 모델(최대 110억 개의 매개변수)을 훈련하여 우리가 고려한 많은 벤치마크에서 최첨단 결과를 달성했습니다. 비지도 학습의 경우 C4 데이터 세트에서 텍스트를 추출하고 연속 토큰 범위를 손상시키는 노이즈 제거 목표를 적용했습니다.
우리는 개별 작업을 미세 조정하기 전에 다중 작업 혼합에 대해 사전 교육했습니다. 전반적으로 우리 모델은 1조 개가 넘는 토큰에 대해 훈련되었습니다. 결과의 복제, 확장 및 적용을 촉진하기 위해 우리는 각 T5 변형에 대해 코드, C4 데이터 세트 및 사전 훈련된 모델 가중치를 공개합니다.
4.2. 시야
대형 모델의 불편함 우리 연구의 놀랍지도 않지만 중요한 결과는 대형 모델이 더 나은 성능을 발휘하는 경향이 있다는 것입니다. 이러한 모델을 실행하는 데 사용되는 하드웨어가 지속적으로 저렴해지고 강력해지고 있다는 사실은 확장이 더 나은 성능을 달성하기 위한 유망한 방법이 될 수 있음을 시사합니다(Sutton, 2019). 그러나 클라이언트 측 추론 또는 연합 학습을 수행할 때와 같이 더 작거나 저렴한 모델을 사용하는 것이 도움이 되는 애플리케이션 및 시나리오는 항상 존재합니다(Konečn`y et al., 2015, 2016). 이와 관련하여 전이 학습의 한 가지 유익한 용도는 리소스가 적은 작업에서 좋은 성과를 얻을 수 있다는 것입니다. 정의에 따라 더 많은 데이터에 라벨을 붙일 자산이 부족한 환경에서는 리소스가 부족한 작업이 자주 발생합니다. 따라서 리소스가 부족한 애플리케이션은 추가 비용이 발생할 수 있는 계산 리소스에 대한 액세스가 제한되는 경우가 많습니다.
결과적으로 우리는 전이 학습이 가장 큰 영향을 미치는 곳에 적용될 수 있도록 더 저렴한 모델로 더 강력한 성능을 달성하는 방법에 대한 연구를 옹호합니다. 이러한 라인에 따른 일부 현재 작업에는 증류(Hinton et al., 2015; Sanh et al., 2019; Jiao et al., 2019), 매개변수 공유(Lan et al., 2019) 및 조건부 계산(Shazeer et al. , 2017).
보다 효율적인 지식 추출 사전 훈련의 목표 중 하나는 (느슨하게 말하면) 다운스트림 작업의 성능을 향상시키는 범용 "지식"을 모델에 제공하는 것임을 상기하십시오. 현재 일반적인 관행인 이 작업에서 우리가 사용하는 방법은 손상된 텍스트 범위의 노이즈를 제거하도록 모델을 훈련시키는 것입니다.
우리는 이 단순한 기법이 모델 범용 지식을 가르치는 데 매우 효율적인 방법이 아닐 수 있다고 의심합니다. 보다 구체적으로, 먼저 1조 개의 텍스트 토큰에 대해 모델을 교육할 필요 없이 우수한 미세 조정 성능을 얻을 수 있으면 유용할 것입니다. 이러한 라인에 따른 일부 동시 작업은 실제 텍스트와 기계 생성 텍스트를 구별하기 위해 모델을 사전 학습하여 효율성을 향상시킵니다(Clark et al., 2020).
작업 간의 유사성 공식화 우리는 레이블이 지정되지 않은 도메인 내 데이터에 대한 사전 교육이 다운스트림 작업의 성능을 향상시킬 수 있음을 관찰했습니다(섹션 3.4). 이 발견은 주로 SQuAD가 Wikipedia의 데이터를 사용하여 만들어졌다는 사실과 같은 기본적인 관찰에 의존합니다. 사전 학습 작업과 다운스트림 작업 간의 "유사성"에 대한 보다 엄격한 개념을 공식화하여 사용할 레이블이 없는 데이터 소스에 대해 보다 원칙적인 선택을 할 수 있도록 하는 것이 유용할 것입니다.
컴퓨터 비전 분야에서는 이러한 맥락을 따르는 몇 가지 초기 경험적 연구가 있습니다(Huh et al., 2016; Kornblith et al., 2018; He et al., 2018). 작업의 관련성에 대한 더 나은 개념은 감독된 사전 훈련 작업을 선택하는 데 도움이 될 수도 있으며, 이는 GLUE 벤치마크에 도움이 되는 것으로 나타났습니다(Phang et al., 2018).
언어에 구애받지 않는 모델 우리는 영어만 사용한 사전 훈련이 우리가 연구한 번역 작업에서 최고 수준의 결과를 얻지 못했다는 사실에 실망했습니다. 우리는 또한 어휘가 어떤 언어를 인코딩할 수 있는지 미리 지정해야 하는 논리적인 어려움을 피하는 데 관심이 있습니다. 이러한 문제를 해결하기 위해 우리는 언어에 구애받지 않는 모델, 즉 텍스트의 언어에 관계없이 좋은 성능으로 주어진 NLP 작업을 수행할 수 있는 모델을 추가로 조사하는 데 관심이 있습니다. 영어가 세계 인구 대다수의 모국어가 아니라는 점을 고려하면 이는 특히 적절한 문제입니다.
이 논문의 동기는 NLP를 위한 전이 학습에 대한 최근 연구의 분주함이었습니다. 우리가 이 작업을 시작하기 전에 이러한 발전은 이미 학습 기반 방법이 아직 효과적이지 않은 환경에서 획기적인 발전을 가능하게 했습니다. 예를 들어, 현대 전이 학습 파이프라인에서는 어렵도록 특별히 설계된 작업인 SuperGLUE 벤치마크에서 인간 수준의 성능과 거의 일치함으로써 이러한 추세를 계속할 수 있게 되어 기쁘게 생각합니다. 우리의 결과는 간단하고 통합된 텍스트-텍스트 프레임워크, 새로운 C4 데이터 세트 및 체계적인 연구에서 얻은 통찰력의 조합에서 비롯됩니다. 추가적으로, 우리는 해당 분야에 대한 경험적 개요와 그것이 어디에 있는지에 대한 관점을 제공했습니다. 우리는 일반적인 언어 이해라는 목표를 향해 전이 학습을 사용하는 지속적인 작업을 보게 되어 기쁩니다.
'자연어처리논문' 카테고리의 다른 글
| [번역] Language Models are Few-Shot Learners (0) | 2024.01.15 |
|---|---|
| T5 논문 리뷰 (0) | 2023.12.31 |
| RoBERTa 논문 리뷰 (0) | 2023.12.03 |
| [번역] RoBERTa: A Robustly Optimized BERT Pretraining Approach (2) | 2023.12.03 |
| [번역] Improving Language Understandingby Generative Pre-Training (2) | 2023.11.25 |