개요
• 모든 text 기반 language 문제를 text-to-text 형식으로 바꾸는 unified framework을 제시하여 NLP에서의 transfer learning에 대해 탐구
• 논문의 체계적인 연구는 pre-training objectives, 아키텍처, unlabeled 데이터셋, transfer approach 등 요인들을 여러 language understanding tasks에서 비교
• scale에 대한 탐구로 얻은 인사이트와 새롭게 선보인 데이터셋 "Colossal Clean Crawled Corpus"(C4)를 사용하여 summarization, question answering, text classification 등 많은 tasks에서 SOTA를 달성
• NLP에서 transfer learning 연구를 장려하기 위해 dataset, pre-trained model, code를 공개
1. 개요
• 최근 NLP는 scalability를 가진 모델을 large unlabeled data로 pre-train 시키는 방식을 사용
• NLP에서의 pre-training objectives, unlabeled data sets, benchmark, fine-tuning method에 대해 많은 연구가 있었음
• 빠르고 다양하게 연구되는 분야다 보니 여러 알고리즘, 새 contribution의 분석이 어려움
• NLP 분야에 대한 보다 철저한 이해를 위해, 체계적으로 다양한 approaches를 비교하고 한계를 끌어올릴 수 있게 해주는 unified transfer learning approach를 제시
• basic idea는 모든 text 문제를 text-to-text 문제로 여기는 것
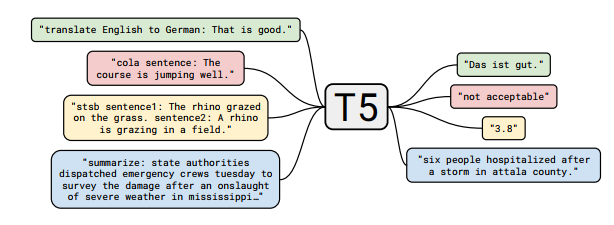
그림 1 : text-to-text 프레임워크에 대한 다이어그램입니다. 번역, 질문 답변 및 분류를 포함하여 우리가 고려하는 모든 작업은 모델 텍스트를 입력으로 제공하고 목표 텍스트를 생성하도록 훈련시키는 것으로 캐스팅됩니다. 이를 통해 다양한 작업 세트에서 동일한 모델, 손실 함수 및 하이퍼파라미터 등을 사용할 수 있습니다. 또한 경험적 조사에 포함된 방법에 대한 표준 테스트 베드를 제공합니다. "T5"는 모델을 참조하여 " Text-to-Text Transfer Transformer"라고 합니다.
• 본 논문의 목적은 새로운 method의 제시가 아닌 분야의 현주소에 대한 종합적인 관점을 제공하는 것
• 연구된 여러 method들은 scaling up에서 한계가 있다는 것을 실험을 통해 확인
• 웹에서 스크랩한 수백기가의 cleaned English text dataset인 Colossal Clean Crawled Corpus(C4)를 소개
2. Setup
2.1 Model
• original Transformer와 거의 비슷한 아키텍처를 사용
1) Layer Norm bias 제거
2) layer normalization을 residual path 밖으로 옮김
3) positional embedding schema 수정 (relative position embeddings)
- Input 사이에 pair-wise relationship 고려
- 각 토큰 위치 별로 고정된 encoding을 주고 attention을 계산하는 것이 아닌, self-attention 내에서 “key”와 “query”사이 relative position embedding 값을 준 것
- Self-attention score + relative position embedding 값을 최종 score로 취함
2.2 The Colossal Clean Crawled Corpus (C4)
- 기존 데이터셋은 filtering에 제한적이고 공개적으로 사용할 수 없어 새로운 데이터셋을 구축
• Pre-training dataset
• Unlabeled text data
• 한 달에 20TB 수집
• Common Crawl 데이터셋이 발전한 dataset
• 약 750GB를 수집, TF Dataset을 통해 쉽게 접근 가능
• Heuristic clean up을 통해 텍스트 정제 진행
1) Terminal punctuation(. ! ? “”)로 끝나는 문장만 사용
2) 5문장보다 적은 페이지는 제거하고, 적어도 3단어 이상 포함된 문장만 사용
3) “List of Dirty, Naughty, Obscene or Otherwise Bad Words” 나쁜 단어 포함된 문장 제거
4) Javascript 단어 들어간 라인 제거
5) “lorem ipsum” 포함된 페이지 제거
6) 자연어가 아닌 { } 와 같은 프로그래밍 언어 포함된 것 제거
7) 대부분 downstream task가 영어로 langdetect을 사용해 영어일 확률이 0.99 이하인 것들은 제거
2.3 Downstream Tasks
• GLUE, SuperGLUE text classification, CNN/Daily Mail, SQuAD, WMT 등 모델의 성능을 실험하기 위해 다양한 테스트 진행
2.4 Input and Output Format
• 단일 모델로 여러 tasks를 처리하기 위해 text-to-text 형식을 취함
• MNLI, text classification에서 모델은 target label의 index가 아닌 target label의 word를 predict (label에 없는 word를 prediction하면 오답으로 간주, 하지만 학습된 모델에서 그런 경우는 발견되지 않음)
• summarization task에는 document 끝에 TL;DR을 붙이는 등 prefix를 활용
• STS-B와 같은 regression task는 label이 의미있는 크고 작음을 가지기 때문에 label은 모두 소수점 아래 둘째 자리에서 반올림, prediction word는 float으로 변환하여 loss를 산출
• multi-task 학습 중 dataset 간 data leakage 위험으로 인해 WNLI는 average GLUE score에서 제외
3. Experiments
3.1 Baseline
“standard Transformer using a simple denoising objective” 사용(기본적인 Transformer 구조)하여 선학습
이후 다운스트림 Task를 통해 파인튜닝을 진행
3.1.1 Model
• 실험 결과 generation, classification task에서 성능이 더 좋았던 standard encoder-decoder Transformer를 사용
• BERTBASE configuration과 동일하게 구성
• 모델 파라미터는 220M으로 BERTBASE(110M)의 2배
3.1.2 Training
• 모든 태스크는 text-to-text 형태를 따름
• Maximum likelihood와 cross-entropy loss로 학습 진행
• Optimization : AdaFactor
• Greedy decoding 사용 (매 timestep마다 가장 확률이 높은 logit 선택)
• Pre-training 하이퍼파라미터
- 2^19 = 524,288 steps
- Maximum sequence length : 512
- Batch size : 128
- 2^16 = 65,536 tokens per batch
- 사전학습시 batch size와 number of steps는 2^35 ≈ 34B tokens, BERT(137B)와 RoBERTa(2.2T)보다 훨씬 적음
- Learning rate schedule : Inverse square root 활용
lr=1/√max(n,k) (n : current training iteration, k : number of warmup steps (=10^4)
• Fine-tuning 하이퍼파라미터
- 2^18 = 262,144 steps
- Maximum sequence length : 512
- Batch size : 128
- 2^16 tokens per batch
- Constant learning rate : 0.001
3.1.3 Vocabulary
• SentencePiece(라이브러리)를 사용하여 text를 WordPiece로 변환
• 영어, 독일어, 프랑스어, 루마니아어를 10:1:1:1 비율로 학습
• 약 32,000개의 wordpiece vocab
3.1.4 Unsupervised objective

: 이전에는 선학습할 때 casual language modeling objective가 많이 사용되었으나, 최근에는 denoising objective 가 좋은 성능을 보여주고 있음
• Masked language modeling을 사용
• 15%의 token을 masking, 연속되는 masked token은 하나의 MASK token으로 변환
• mask token의 경우 unique한 id를 부여 (모두 다르게 취급)
• Target은 Input에서 마스킹되지 않은 부분을 맞춰야 함

• 10개 baseline을 학습시켜 평균과 표준편차 확인
• BERTBASE보다 성능이 올랐으나 T5는 encoder-decoder 모델이고, 1/4 steps만 선학습 진행했기 때문에 직접적으로 비교하긴 어려움
• Pre-training 하는것이 성능향상에 도움이 된다.
3.2 Archietectures
3.2.1 Model structures
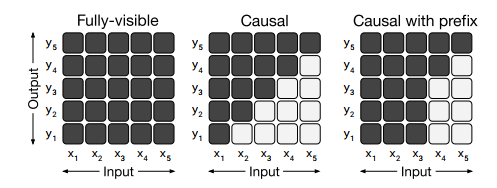
• Fully-visible : encoder에서 사용, Query가 모든 key에 attention 가능
• Causal : decoder 에서 사용, Query가 현재 시점 포함 이전 timestep의 Key에 attention 가능
• Causal with prefix :입력 텍스트인 prefix로 주어진 부분은 fully-visible, 출력 텍스트는 casual 사용

• Standard Encoder-Decoder : encoder는 Full-visible attention, decoder는 causal attention 사용
• Language model : Transformer의 decoder에서 causal attention 사용
• Prefix LM
- Transformer의 decoder에서 causal with prefix attention 사용
- input text(x) full-visible attention을 수행하는 prefix가 되는 구조
: 위 3가지 아키텍처 디자인을 비교
3.2.4 Result

• Encoder-decoder 구조 / Denoising objective가 가장 좋은 결과를 기록
• 인코더와 디코더 파라미터 공유하는 것은 성능 차이 크게 나지 않음
• Layer를 줄이는 것은 성능에 악영향
• Denoising objective를 사용하는 것이 language modeling objective보다 높은 성능
3.3 Unsupervised Objectives

Objective는 text-to-text encoder-decoder에 맞게 변환
• Prefix language modeling : input으로 문장 앞부분 넣으면 target에서 문장의 뒷부분 예측
• BERT-style : 토큰의 15%를 마스킹, 90%를 랜덤 토큰으로 교체
• Deshuffling : 문장을 섞은 다음 원래 문장을 예측
• MASS-style : BERT-style에서 90% 랜덤 토큰으로 교체하는 방법만 제외
• I.i.d. noise, replace spans : masking되지 않은 부분 예측
• I.i.d. noise, drop tokens : masking을 알려주지 않아도 빠진 문장 예측
• Random spans : span이 1개가 아니라 더 긴 span 예측

[High-level Approaches]

• Greedy하게 Coarse to fine으로 여러 objective와 하위 설정에 대한 실험
- Prefix language modeling / BERT-style / Deshuffling 중 BERT-style의 성능이 가장 뛰어났음
[Corruption strategies]

• 연속된 corrupted tokens을 하나의 mask token으로 대체하는 Replace corrupted spans,
long sequence에서 attention을 피하기 위한 Drop corrupted tokens으로 BERT-style의 masking 설정에 대한 실험
- Replace corrupted spans의 성능이 가장 좋았음
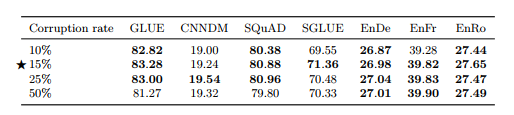
[Corruption rate]
[Corrupted span length]
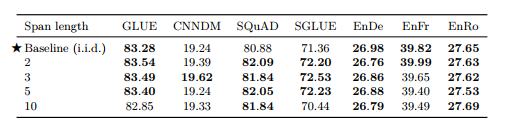
• Corruption rate, Span length에 대한 실험 (표 6,7)
• 15%, Baseline(span length 제약 없이 i.i.d corruption)의 성능이 최고
3.4 Pre-training Data set
: Pre-training시 사용한 데이터셋에 대해 실험 진행
1) Unlabeled Data sets
• C4 : Pre-training에 사용한 데이터셋
• Unfiltered C4 : langdetect을 통해 영어만 추출, Heuristic filtering 적용 안함
• RealNews-like : “RealNews” 데이터셋에 대해 C4와 같이 heuristic filtering 적용
• WebText-like
- WebText 데이터셋은 사용자들이 웹페이지의 컨텐츠에 따라 1~3점 스코어 부여
- 높은 스코어의 URL과 겹치는 페이지만 남김
- C4는 한달치 Common Crawl 데이터라 남은 데이터가 2GB밖에 안됨
- 2018.08 ~ 2019.07(12개월) Common Crawl 데이터에서 heuristic filtering 적용하여 17GB 데이터 구축
• Wikipedia : English Wikipedia 사용
• Wikipedia + Toronto Books Corpus : Wikipedia는 백과사전 도메인만 있기 때문에, Toronto Book Corpus(TBC)를 추가하여 다양한 도메인 정보 포함
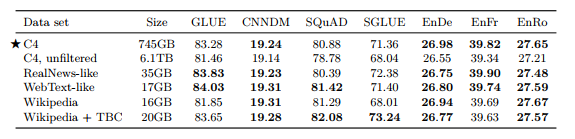
• C4가 전체적으로 성능 좋음
• Heuristic filtering을 적용하지 않은 C4는 성능이 떨어짐
• In-domain 데이터로 학습하면 downstream task에서 성능이 향상
• WebText-like 데이터셋이 C4보다 40배 가까이 데이터가 적음에도 좋은 성능을 보임
2) Pre-training Data Set Size
Full data set = 2^35 ≈ 34B tokens
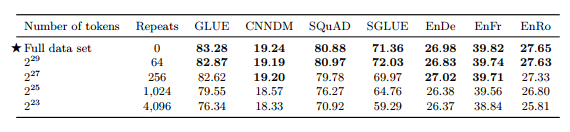
• 적은 데이터셋으로 여러 번 학습하는 것 보다 하나의 큰 데이터셋으로 학습하는 것이 성능 좋음
• 64번 반복까지만 효과 있음
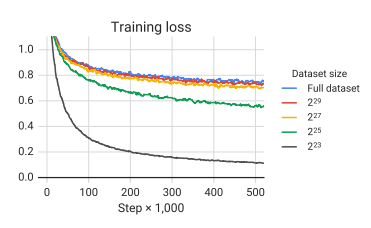
• 데이터셋 크기가 감소하면 모델의 loss는 훨씬 작아지지만, 암기하는 효과 나타남(overfitting)
3.5 Training Strategy
3.5.1 Fine-tuning method
모델의 모든 parameter를 다 fine-tuning하는 것은 좋지 않음 (특히 파인튜닝 데이터가 적을 때)
Text classification 태스크의 경우 pre-trained 모델은 고정하고, 뒷단의 classifier layer만 새로 학습하는 형태 선호
그러나, Encoder-Decoder 모델에 적용하기 어려워 다른 대안으로 두가지 방법 제시
1) Adapter layers
• Pre-training된 부분은 그대로 두고 그 위에 별도의 학습 가능한 layer를 두어 그 부분만 학습시킴
• Transformer 블록 내 feed-forward networks 위에 adapter Layer를 추가해서 학습하는 방식
• Fine-tuning 할 때 adapter layer와 layer normalization 파라미터만 업데이트

2) Gradual Unfreezing
• 모든 layer를 fine-tuning 하는 것이 아닌 마지막 레이어부터 fine-tuning 하는 방식
• Top layer부터 bottom까지 천천히 학습되는 방식
• 가장 아래 layer가 가장 늦게 unfreezing 됨
: 두 방식에 대한 실험을 진행함

𝑑 : feed-forward network 내부 차원
• 모든 파라미터를 freezing 하지 않고 학습시켰을 때 가장 성능 좋음
• 적은 리소스를 요구하는 태스크의 경우 𝑑 값이 클 필요 없음
• GLUE와 SuperGLUE의 경우 하나의 태스크로 간주하고 학습 진행하였기 때문에 큰 𝑑 필요했음
• Gradual unfreezing은 모든 태스크에서 약간의 성능 저하 보이지만, fine-tuning시 속도 향상됨
3.5.2 multi-task learning
• T5의 unified text-to-text framework는 모든 tasks가 test-to-text 형식으로 구성되어 있어 데이터셋을 섞는 것이 곧 multi-task와 같다
• Examples-proportional mixing
- 각 dataset의 크기에 비례하여 샘플링
- 너무 큰 dataset의 크기는 가상의 datasize limit K로 제한
• Equal mixing : 모든 task에서 동일한 수의 데이터를 샘플링
• Temperature-scaled mixing
- multilingual BERT에서 사용한 방식으로 mixing rate rm을 (1/T)^2로 설정하고 renormalize하여 합이 1이되도록 함
- T=1이면 Examples-proprotional mixing과 동일, T가 증가하면 equal mixing과 비슷한 형태(모두 같은 비율)
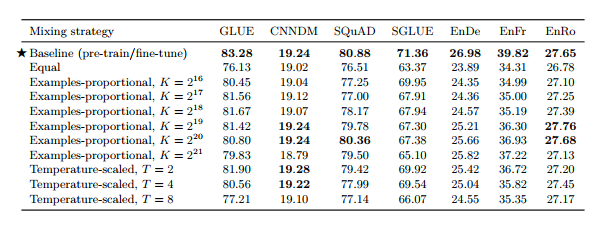
• 새로 설계한 method 대부분 성능 저하 결과
3.5.3 Combining multi-task learning with fine-tuning
- 위 실험의 결과로 자연스럽게 fine-tuning에서의 multi-task learning으로 이동
• leave-one-out : 하나의 task를 빼고 pre-training 한 후, 해당 task를 fine-tune
• supervised multi-task pre-training : K=2^19, examples-proportional mixture를 사용하여 supervised training
• Multi-task training, Multi-task pre-training + fine-tuning
- MT-DNN에서 제시한 방식
- unsupervised objective와 supervise task의 결합
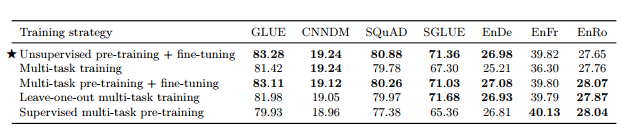
• Unsupervised pre-training + fine-tuning이 가장 좋은 성능을 보임
3.6 Scaling
• 4배 큰 computing power가 생겼을 때 모델의 크기를 어떻게 늘리는 것이 효율적일지에 대해 실험 진행
- 고려대상 : 파라미터 수, 트레이닝 steps, batch size, ensemble
• baseline보단 성능 향상
• 무조건 4 x training steps나 4 x batch size가 제일 좋은 성능은 아님
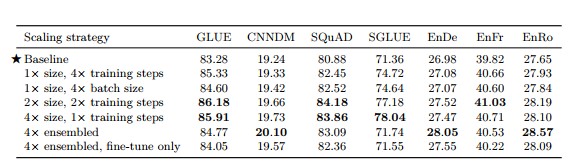
3.7 Putting It All Together
- 지금까지 수행한 체계적인 실험 결과를 모아 NLP benchmark를 얼마나 끌어올릴 수 있는지 테스트
• Objective : i.i.d denoising objective (span length 3, 15% corruption)
• Longer training
• Model size
- Base(220M parameters), Small(60M parameters), large(770M parameters), 3B(3B parameters), 11B(11B parameters)
• Multi-task pre-training
- MT-DNN에서 제시한 방식 사용
- training 도중에도 multi-task에서 성능을 관찰할 수 있는 장점 존재
• Fine-tuning on individual GLUE and SuperGLUE tasks
• Beam Search(beam width=4, length penalty alpha=0.6) for WMT, CNN/DM
• Test set
- 각 데이터셋의 validation set이 아닌 test set의 결과 report
- SQuAD는 test set benchmark server 문제로 valid set 사용
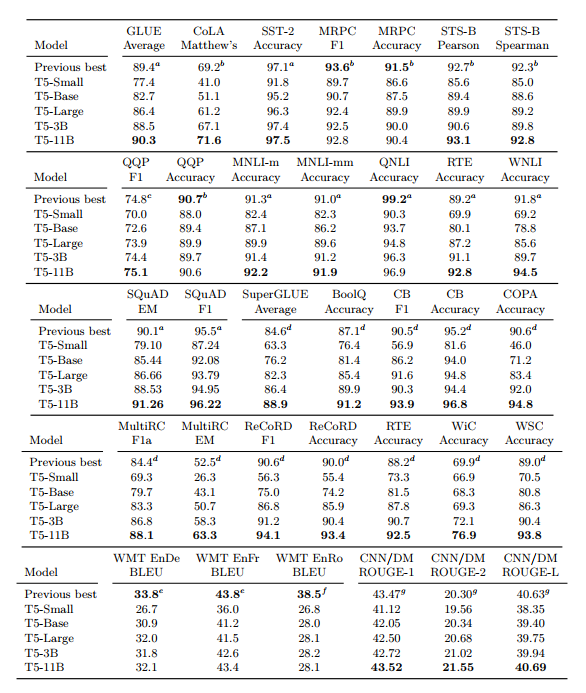
• 24개 task 중 18개 task에서 SOTA를 달성
• 예상과 같이 11B 모델이 가장 좋은 성능을 보임
4. Reflection
4.1 Takeaways
• Text-to-Text
- 간단한 encoder-decoder 구조로 text-specific한 아키텍처와 비슷한 성능을 보여줌, scale up을 통해 SOTA까지 달성한 디자인
• Architectures
- encoder-decoder 아키텍처는 text-to-text framework에서 encoder-only, language model 아키텍처보다 좋은 성능을 보여줌
• Unsupervised learning
- short target sequence를 사용하는 denoising objective를 선정하여 computational cost를 줄이는 것이 좋음
• Data sets
- C4를 제시
• Training strategies
- 여러 tasks로 pre-training 하고 fine-tuning 하는 것은 unsupervised pre-training에 견줄만한 성능을 보임
- 하지만 task mixing 비율에 대해서는 연구가 더 필요
• Scaling
- scale up, ensemble 모두 효과적
• Pushing the limits
- 얻은 인사이트를 결합하고 충분히 큰 모델(11B)에서 학습한 결과, 많은 benchmark에서 SOTA를 달성
4.2 Outlook
• The inconvenience of large models
- 모델 크기가 클수록 좋은 성능이 나오지만 모든 상황에서 큰 모델을 사용할 수 없기 때문에 가볍고 성능 좋은 모델을 만들어야 한다.
• More efficient knowledge extraction
- corruped span을 denoise하는 task(손상된 텍스트 span을 맞추는 학습 방법)가 general-purpose knowledge를 가르치는데 효과적인 방법이 아닐 수 있음
- real & machine generation text를 구분하는 이전 연구와 같은 새로운 접근이 필요
• Formalizing the similarity between tasks
- SQuAD의 경우 Wikipedia로 부터 만들어졌기 때문에 중복이 많아 성능이 높을 수 밖에 없음
• Language-agnostic models
- 언어에 상관없이 모든 NLP 태스크에서 좋은 성능을 내는 모델을 개발하고자 함
'자연어처리논문' 카테고리의 다른 글
| GPT-3 논문리뷰 (0) | 2024.01.17 |
|---|---|
| [번역] Language Models are Few-Shot Learners (0) | 2024.01.15 |
| [번역] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (1) | 2023.12.31 |
| RoBERTa 논문 리뷰 (0) | 2023.12.03 |
| [번역] RoBERTa: A Robustly Optimized BERT Pretraining Approach (2) | 2023.12.03 |