
[번역] Deep contextualized word representations (ELMo)
개요
우리는 (1) 단어 사용의 복잡한 특성(예: 구문 및 의미론)과 (2) 이러한 단어 사용 방법을 모두 모델링하는 새로운 유형의 심층적인 맥락화된 단어 표현을 소개합니다.
언어적 맥락에 따라 다양합니다(즉, 다의어를 모델링하기 위해). 우리의 단어 벡터는 대규모 텍스트 코퍼스에서 사전 훈련된 biLM(심층 양방향 언어 모델)의 내부 상태에 대한 학습 함수입니다. 우리는 이러한 표현을 기존 모델에 쉽게 추가할 수 있으며 질문 답변, 텍스트 수반 및 감정 분석을 포함한 6가지 까다로운 NLP 문제 전반에 걸쳐 최신 기술을 크게 향상시킬 수 있음을 보여줍니다. 또한 다운스트림 모델이 다양한 유형의 준감독 신호를 혼합할 수 있도록 사전 훈련된 네트워크의 심층 내부를 노출하는 것이 중요하다는 것을 보여주는 분석을 제시합니다.
1 서론
사전 훈련된 단어 표현(Mikolov et al., 2013; Pennington et al., 2014)은 많은 신경 언어 이해 모델의 핵심 구성 요소입니다. 그러나 고품질 표현을 학습하는 것은 어려울 수 있습니다. (1) 단어 사용의 복잡한 특성(예: 구문 및 의미론)과 (2) 이러한 사용이 언어적 맥락에 따라 어떻게 다른지(예: 다의어 모델링) 모두 이상적으로 모델링해야 합니다. 이 논문에서는 두 가지 문제를 직접적으로 해결하고, 기존 모델에 쉽게 통합할 수 있으며, 다양한 언어 이해 문제에 대해 고려된 모든 사례에서 state-of-the-art기술을 크게 향상시키는 새로운 유형의 심층적 맥락화된 단어 표현을 소개합니다.
우리의 표현은 각 토큰에 전체 입력 문장의 함수인 표현이 할당된다는 점에서 전통적인 단어 유형 임베딩과 다릅니다. 우리는 큰 텍스트 코퍼스에서 LM(결합 언어 모델) 목적으로 훈련된 양방향 LSTM에서 파생된 벡터를 사용합니다. 이러한 이유로 우리는 이를 ELMo(Embeddings from Language Models) 표현이라고 부릅니다.
상황에 맞는 단어 벡터를 학습하기 위한 이전 접근 방식(Peters et al., 2017; McCannet al., 2017)과 달리 ELMo 표현은 biLM의 모든 내부 계층의 함수라는 점에서 심층적입니다. 보다 구체적으로, 우리는 각 최종 작업에 대한 각 입력 단어 위에 쌓인 벡터의 선형 조합을 학습합니다. 이는 최상위 LSTM 레이어를 사용하는 것보다 성능이 크게 향상됩니다.
이러한 방식으로 내부 상태를 결합하면 매우 풍부한 단어 표현이 가능해집니다. 내재적 평가를 사용하여 우리는 상위 레벨 LSTM 상태가 단어 의미의 문맥 의존적 측면을 포착하는 반면(예: 감독된 단어 의미 명확성 작업을 잘 수행하기 위해 수정 없이 사용할 수 있음) 하위 레벨 상태는 구문의 모델 측면(예: , 품사 태깅을 수행하는 데 사용할 수 있습니다). 이러한 모든 신호를 동시에 노출하는 것은 학습된 모델이 각 최종 작업에 가장 유용한 semi-supervision 유형을 선택할 수 있으므로 매우 유익합니다.
광범위한 실험을 통해 ELMo 표현이 실제로 매우 잘 작동함을 보여줍니다.
우리는 먼저 텍스트 내포, 질문 응답 및 정서 분석을 포함하여 6가지 다양하고 까다로운 언어 이해 문제에 대해 기존 모델에 쉽게 추가할 수 있음을 보여줍니다. ELMo 표현을 추가하는 것만으로도 최대 20%의 상대 오차를 포함하여 모든 경우에 최신 기술이 크게 향상됩니다.
감소. 직접적인 비교가 가능한 작업의 경우 ELMo는 신경 기계 번역 인코더를 사용하여 상황에 맞는 표현을 계산하는 CoVe(McCann et al., 2017)보다 성능이 뛰어납니다. 마지막으로 ELMo와 CoVe를 모두 분석한 결과 심층 표현이 LSTM의 최상위 계층에서 파생된 표현보다 성능이 뛰어난 것으로 나타났습니다.
훈련된 모델과 코드는 공개적으로 사용 가능하며 ELMo가 다른 많은 NLP 문제에 대해 유사한 이점을 제공할 것으로 기대합니다.
2 관련 작업
레이블이 지정되지 않은 대규모 텍스트에서 단어의 구문 및 의미 정보를 캡처할 수 있는 능력으로 인해 사전 학습된 단어 벡터(Turian et al., 2010; Mikolov et al., 2013; Pennington et al., 2014)는 대부분의 상태의 표준 구성 요소입니다. 질문 답변(Liu et al., 2017), 텍스트 수반을 포함한 state-of-the-art NLP 아키텍처 (Chen et al., 2017) 및 의미론적 역할 라벨링 (He et al., 2017). 그러나 단어 벡터를 학습하기 위한 이러한 접근 방식은 각 단어에 대해 상황에 독립적인 단일 표현만 허용합니다.
이전에 제안된 방법은 하위 단어 정보로 강화하거나(예: Wieting et al., 2016; Bojanowski et al., 2017) 각 단어 의미에 대해 별도의 벡터를 학습함으로써(예: Neelakantan et al., 2014) 기존 단어 벡터의 일부 단점을 극복했습니다. 우리의 접근 방식은 문자 컨볼루션을 사용하여 하위 단어 단위의 이점도 얻을 수 있으며 사전 정의된 감각 클래스를 예측하기 위해 명시적으로 훈련하지 않고도 다중 감각 정보를 다운스트림 작업에 원활하게 통합합니다. 다른 최근 연구에서도 상황에 따른 표현을 학습하는 데 중점을 두었습니다.
context2vec(Melamud et al., 2016)은 양방향 장단기 기억(LSTM; Hochreiter and Schmidhuber, 1997)을 사용하여 피벗 단어 주변의 컨텍스트를 인코딩합니다. 상황별 임베딩을 학습하기 위한 다른 접근 방식에는 다음이 포함됩니다.
표현에서 단어 자체를 피벗하고 지도 신경 기계 번역(MT) 시스템(CoVe; McCann et al., 2017) 또는 비지도 언어 모델(Peters et al., 2017)의 인코더로 계산됩니다. MT 접근 방식은 병렬 말뭉치의 크기로 인해 제한되지만 이 두 접근 방식 모두 대규모 데이터 세트에서 이점을 얻습니다. 이 논문에서 우리는 풍부한 단일 언어 데이터에 대한 액세스를 최대한 활용하고 약 3천만 개의 문장이 있는 코퍼스에서 biLM을 훈련합니다(Chelba et al., 2014). 우리는 또한 이러한 접근 방식을 심층적인 맥락 표현에 일반화하여 광범위한 다양한 NLP 작업에 걸쳐 잘 작동함을 보여줍니다.
이전 연구에서는 또한 다양한 계층의 심층 biRNN이 다양한 유형의 정보를 인코딩하는 것으로 나타났습니다. 예를 들어, 깊은 LSTM의 하위 수준에 다중 작업 구문 감독(예: 품사 태그)을 도입하면 종속성 구문 분석(Hashimoto et al., 2017) 또는 CCG super와 같은 상위 수준 작업의 전반적인 성능을 향상시킬 수 있습니다. 태깅(Søgaard 및 Goldberg, 2016).
RNN 기반 인코더-디코더 기계 번역 시스템에서 Belinkov et al. (2017)은 2-레이어 LSTM 인코더의 첫 번째 레이어에서 학습된 표현이 두 번째 레이어보다 POS 태그를 예측하는 데 더 낫다는 것을 보여주었습니다. 마지막으로 단어 컨텍스트를 인코딩하기 위한 LSTM(Melamud et al., 2016)의 최상위 계층은 단어 의미 표현을 학습하는 것으로 나타났습니다. 우리는 유사한 신호도 있음을 보여줍니다.
ELMo 표현의 수정된 언어 모델 목표에 의해 유도되며 이러한 다양한 유형의 semi-supervision을 혼합하는 다운스트림 작업에 대한 모델을 학습하는 것이 매우 유용할 수 있습니다.
Dai와 Le(2015) 및 Ramachandran et al. (2017)은 언어 모델과 시퀀스 자동 인코더를 사용하여 인코더-디코더 쌍을 사전 훈련한 다음 작업별 감독을 통해 미세 조정합니다. 대조적으로, 레이블이 지정되지 않은 데이터로 biLM을 사전 훈련한 후 가중치를 수정하고 추가 작업별 모델 용량을 추가하여 다운스트림 훈련 데이터 크기가 더 작은 감독 모델을 지시하는 경우 크고 풍부하며 보편적인 biLM 표현을 활용할 수 있습니다.
3 ELMo: Embeddings from Language Models
가장 널리 사용되는 단어 임베딩(Pennington et al., 2014)과 달리 ELMo 단어 표현은 이 섹션에 설명된 대로 전체 입력 문장의 함수입니다. 내부 네트워크 상태(Sec. 3.2)의 선형 함수로서 문자 컨볼루션(Sec. 3.1)이 있는 2계층 biLM 위에서 계산됩니다. 이 설정을 통해 우리는 biLM이 대규모로 사전 훈련되고(Sec. 3.4) 광범위한 기존 신경 NLP 아키텍처(Sec. 3.3)에 쉽게 통합되는 semi-supervised 학습을 수행할 수 있습니다.
3.1 양방향 언어 모델
N개의 토큰 시퀀스(t1, t2, ..., tN)가 주어지면 순방향 언어 모델은 내역(t1, ..., tk−1)이 주어진 토큰 tk의 확률을 모델링하여 시퀀스의 확률을 계산합니다.

최근 state-of-the-art 신경 언어 모델(J́ozefowicz et al., 2016; Melis et al., 2017; Merity et al., 2017)은 컨텍스트 독립적인 토큰 표현 x LM k를 계산합니다(토큰 임베딩 또는 문자에 대한 CNN 전송을 통해) 그런 다음 정방향 LSTM의 L 레이어를 통해 전달합니다. 각 위치 k에서 각 LSTM 레이어는 상황에 따른 표현 → h LM j,k, 여기서 j = 1, . . . , L 을 출력합니다. 최상위 레이어 LSTM 출력 → h LM L,k, 는 Softmax 레이어를 사용하여 다음 토큰 tk+1을 예측하는 데 사용됩니다. 역방향 LM은 역순으로 시퀀스를 실행하여 미래 컨텍스트를 고려하여 이전 토큰을 예측한다는 점을 제외하면 순방향 LM과 유사합니다.
이는 순방향 LM과 유사한 방식으로 구현될 수 있으며, L 계층 심층 모델의 각 역방향 LSTM 계층 j는 주어진 tk의 표현 ← h LM j,k, k(tk+1,...,tN)을 생성합니다.
biLM은 순방향 LM과 역방향 LM을 모두 결합합니다. 우리의 공식은 정방향과 역방향의 로그 우도를 공동으로 최대화합니다.
각 방향에서 LSTM에 대한 별도의 매개변수를 유지하면서 토큰 표현(Θx)과 소프트맥스 레이어(Θs)에 대한 매개변수를 순방향 및 역방향으로 연결합니다. 전반적으로 이 공식은 Peters et al. (2017), 의 접근 방식과 유사합니다. 완전히 독립적인 매개변수를 사용하는 대신 방향 간에 일부 가중치를 공유한다는 점을 제외하고. 다음 섹션에서는 biLM 레이어의 선형 조합인 단어 표현을 학습하기 위한 새로운 접근 방식을 도입하여 이전 작업에서 출발합니다.
3.2 ELMo
ELMo는 biLM의 중간 계층 표현의 특정 작업 조합입니다. 각 토큰 tk에 대해 L 계층 biLM은 2L + 1 표현 세트를 계산합니다.
여기서 h LM k,0은 토큰 레이어이고 각 biLSTM 레이어에 대해 h LM k,j = [→ h LM k,j; ← h LM k,j],이다.
다운스트림 모델에 포함하기 위해 ELMo는 R의 모든 레이어를 단일 벡터 ELMok = E(Rk ; Θe )로 축소합니다.
가장 간단한 경우 ELMo는 TagLM(Peters et al., 2017) 및 CoVe(McCann et al., 2017)에서와 같이 최상위 레이어 E(Rk) = h LM k,j를 선택합니다. 보다 일반적으로 모든 biLM 레이어의 작업별 가중치를 계산합니다.
(1)에서 작업은 소프트맥스 정규화 가중치이고 스칼라 매개변수 γ 작업을 통해 작업 모델이 전체 ELMo 벡터를 확장할 수 있습니다. γ는 최적화 프로세스를 지원하는 데 실질적으로 중요합니다(자세한 내용은 보충 자료 참조). 각 biLM 레이어의 활성화가 서로 다른 분포를 갖는다는 점을 고려하면 어떤 경우에는 가중치를 부여하기 전에 각 biLM 레이어에 레이어 정규화(Ba et al., 2016)를 적용하는 것도 도움이 되었습니다.
3.3 supervised NLP 작업에 biLM 사용
사전 훈련된 biLM과 대상 NLP 작업에 대한 지도 아키텍처가 주어지면 biLM을 사용하여 작업 모델을 개선하는 것은 간단한 프로세스입니다. 우리는 단순히 biLM을 실행하고 각 단어에 대한 모든 레이어 표현을 기록합니다. 그런 다음 아래 설명된 대로 최종 작업 모델이 이러한 표현의 선형 조합을 학습하도록 합니다.
먼저 biLM이 없는 지도 모델의 가장 낮은 레이어를 고려하세요. 대부분의 지도 NLP 모델은 가장 낮은 계층에서 공통 아키텍처를 공유하므로 일관되고 통합된 방식으로 ELMo를 추가할 수 있습니다. 일련의 토큰(t1,...,tN)이 주어지면 사전 훈련된 단어 임베딩 및 선택적으로 문자 기반 표현을 사용하여 각 토큰 위치에 대해 컨텍스트 독립적인 토큰 표현 xk를 형성하는 것이 표준입니다. 그런 다음 모델은 일반적으로 양방향 RNN, CNN 또는 피드 포워드 네트워크를 사용하여 상황에 맞는 표현 hk 를 형성합니다.
감독 모델에 ELMo를 추가하기 위해 먼저 biLM의 가중치를 고정한 다음 ELMo 벡터 ELMo task k를 xk와 연결하고 ELMo 강화 표현 [xk ; ELMo task k ]를 태스크 RNN에 넣습니다. 일부 작업(예: SNLI, SQuAD)의 경우 다른 출력 특정 선형 가중치 세트를 도입하고 hk를 [hk; ELMo task k]. 지도 모델의 나머지 부분은 변경되지 않은 상태로 유지되므로 이러한 추가는 더 복잡한 신경 모델의 맥락에서 발생할 수 있습니다. 예를 들어 Sec의 SNLI 실험을 참조하세요. 4에서는 bi-Attention 레이어가 biLSTM을 따르거나 클러스터링 모델이 biLSTM 위에 계층화되는 상호 참조 해결 실험을 수행합니다.
마지막으로 우리는 ELMo에 적당한 양의 드롭아웃을 추가하고(Srivastava et al., 2014) 어떤 경우에는 손실에 λ||w||2 2를 추가하여 ELMo 가중치를 정규화하는 것이 유익하다는 것을 발견했습니다. 이는 ELMo 가중치에 유도 바이어스를 부과하여 모든 biLM 레이어의 평균에 가깝게 유지됩니다.
3.4 사전 훈련된 양방향 언어 모델 아키텍처
본 논문의 사전 훈련된 biLMs은 Jozefowicz et al. (2016) 및 Kim et al. (2015)의 아키텍처와 유사하지만 양방향의 공동 훈련을 지원하고 LSTM 레이어 사이에 잔여 연결을 추가하도록 수정되었습니다. Peters et al.(2017)이 순방향 전용 LMs 및 large scale training보다 biLMs 사용의 중요성을 강조한 것처럼 이 작업에서는 대규모 biLMs에 중점을 둡니다.
순전히 문자 기반 입력 표현을 유지하면서 전체 언어 모델 복잡성과 모델 크기 및 다운스트림 작업에 대한 계산 요구 사항의 균형을 맞추기 위해 Jozefowicz et al. (2016)에서 단일 최고의 모델 CNN-BIG-LSTM의 모든 임베딩 및 숨겨진 차원을 절반으로 줄였습니다. 최종 모델은 4096개의 단위와 512개의 차원 투영을 가진 L = 2 biLSTM 레이어와 첫 번째 레이어에서 두 번째 레이어까지의 잔여 연결을 사용합니다. 상황에 무관한 유형 표현은 2048 문자 n-gram 컨벌루션 필터와 두 개의 고속도로 레이어를 사용합니다. (Srivastava et al., 2015) 및 512 표현까지의 선형 투영 결과적으로 biLM은 순수 문자 입력으로 인해 훈련 세트 외부의 표현을 포함하여 각 입력 토큰에 대해 세 가지 표현 레이어를 제공합니다. 전통적인 단어 임베딩 방법은 고정된 어휘의 토큰에 대해 한 계층의 표현만 제공합니다.
1B Word Benchmark(Chelba et al., 2014)에서 10 epoch 동안 훈련한 후 평균 순방향 및 역방향 혼란은 39.7인데 비해 순방향 CNN-BIG-LSTM의 경우 30.0입니다. 일반적으로 우리는 순방향 및 역방향 복잡도가 거의 동일하고 역방향 값이 약간 낮다는 것을 발견했습니다.
일단 사전 훈련되면 biLM은 모든 작업에 대한 표현을 계산할 수 있습니다. 어떤 경우에는 도메인 특정 데이터에서 biLM을 미세 조정하면 복잡성이 크게 감소하고 다운스트림 작업 성능이 향상됩니다. 이는 biLM의 도메인 이전 유형으로 볼 수 있습니다. 결과적으로 대부분의 경우 다운스트림 작업에서 미세 조정된 biLM을 사용했습니다. 자세한 내용은 보충 자료를 참조하세요.
4 평가
표 1은 다양한 6가지 벤치마크 NLP 작업 세트에서 ELMo의 성능을 보여줍니다. 고려되는 모든 작업에서 단순히 ELMo를 추가하면 강력한 기본 모델에 비해 상대 오류가 6~20% 감소하는 새로운 state-of-the-art 결과가 생성됩니다. 이는 다양한 세트 모델 아키텍처 및 언어 이해 작업 전반에 걸쳐 매우 일반적인 결과입니다. 이 섹션의 나머지 부분에서는 개별 작업 결과에 대한 높은 수준의 스케치를 제공합니다. 전체 실험 세부정보는 보충 자료를 참조하세요.
질문 답변 SQuAD(Stanford 질문 답변 데이터 세트)(Rajpurkar et al., 2016)에는 답변이 주어진 Wikipedia 단락의 범위인 100,000개 이상의 크라우드 소싱 질문 답변 쌍이 포함되어 있습니다. 우리의 기본 모델(Clark and Gardner, 2017)은 Seo et al. (BiDAF; 2017). 의 양방향 주의 흐름 모델의 개선된 버전입니다. 이는 양방향 Attention 요소 뒤에 Self-Attention 레이어를 추가하고 일부 풀링 작업을 단순화하며 Gated Recurrent Unit을 LSTM으로 대체합니다 (GRU; Cho et al., 2014). 기본 모델에 ELMo를 추가한 후 테스트 세트 F1은 81.1%에서 85.8%로 4.7% 향상되었으며, 기준에 비해 상대 오류가 24.9% 감소했으며 전체 단일 모델 state-of-the-art이 1.4% 향상되었습니다. 11명의 멤버 앙상블은 F1을 87.4로 끌어올렸는데, 이는 리더보드 제출 시점의 전체 state-of-the-art 수치입니다. ELMo를 사용한 4.7% 증가는 CoVe를 기본 모델에 추가한 1.8% 증가보다 훨씬 더 컸습니다. (McCann 외, 2017).
표 1: 6개 벤치마크 NLP 작업에 걸쳐 state-of-the-art 단일 모델 기준을 사용하여 ELMo 강화 신경 모델의 테스트 세트 비교. 성능 지표는 작업에 따라 다릅니다. 즉, SNLI 및 SST-5의 정확도; SQuAD, SRL 및 NER의 경우 F1; Coref의 평균 F1. NER 및 SST-5의 테스트 크기가 작기 때문에 서로 다른 무작위 시드를 사용하여 5번의 실행에 대한 평균 및 표준 편차를 보고합니다. "increase" 열에는 기준에 비해 절대적 개선과 상대적 개선이 모두 나열됩니다.
텍스트 수반 텍스트 수반은 "전제"가 주어졌을 때 "가설"이 참인지 여부를 결정하는 작업입니다. SNLI(Stanford Natural Language Inference) 코퍼스(Bowman et al., 2015)는 대략 550K의 가설/전제 쌍을 제공합니다. 우리의 기준선인 Chen et al. (2017), 의 ESIM 시퀀스 모델은 biLSTM을 사용하여 전제와 가설을 인코딩한 다음 행렬 주의 계층, 로컬 추론 계층, 또 다른 biLSTM 추론 구성 계층, 마지막으로 출력 계층 이전에 풀링 작업을 수행합니다. 전반적으로 ESIM 모델에 ELMo를 추가하면 5개의 무작위 시드에 대해 정확도가 평균 0.7% 향상됩니다. 5명으로 구성된 앙상블은 전체 정확도를 89.3%로 끌어올려 이전 앙상블 최고 기록인 88.9%를 초과했습니다(Gong et al., 2018).
의미론적 역할 레이블링 의미론적 역할 레이블링(SRL) 시스템은 문장의 술어 논증 구조를 모델로 하며 "누가 누구에게 무엇을 했는지"에 대한 대답으로 설명되는 경우가 많습니다. He et al.(2017) 은 SRL을 BIO 태깅 문제로 모델링하고 Zhou and Xu(2015)에 이어 순방향 및 역방향이 인터리브된 8층 심층 biLSTM을 사용했습니다. 표 1에서 볼 수 있듯이 He et al.(2017)의 재구현에 ELMo를 추가하면 단일 모델 테스트 세트 F1이 81.4%에서 84.6%로 3.2% 증가했습니다. OntoNotes 벤치마크(Pradhan et al., 2013)로 이전 최고 앙상블 결과보다 1.2% 향상되었습니다.
상호 참조 해결 상호 참조 해결은 동일한 기본 실제 엔터티를 참조하는 텍스트의 언급을 클러스터링하는 작업입니다. 우리의 기본 모델은 Lee et al. (2017)의 end-to-end Span 기반 신경 모델입니다. biLSTM 및 어텐션 메커니즘을 사용하여 먼저 범위 표현을 계산한 다음 소프트맥스 멘션 순위 모델을 적용하여 상호 참조 체인을 찾습니다. CoNLL 2012 공유 작업(Pradhan et al., 2012)의 OntoNotes 상호 참조 주석을 사용한 실험에서 ELMo를 추가하면 평균 F1이 67.2에서 70.4로 3.2% 향상되어 새로운 state-of-the-art 기술이 확립되었으며 이전보다 다시 향상되었습니다. 1.6% F1만큼 최고의 앙상블 결과.
명명된 엔터티 추출 CoNLL 2003 NER 작업(Sang and Meulder, 2003)은 네 가지 엔터티 유형(PER, LOC, ORG, 기타). 최신 시스템(Lample et al., 2016; Peters et al., 2017)에 따라 기본 모델은 사전 훈련된 단어 임베딩, 문자 기반 CNN 표현, 두 개의 biLSTM 레이어 및 조건부 무작위를 사용합니다. 필드(CRF) 손실(Lafferty et al., 2001)은 Collobert et al.(2011)과 유사합니다. 표 1에서 볼 수 있듯이 ELMo 강화 biLSTM-CRF는 5회 실행에 걸쳐 평균 92.22% F1을 달성합니다. 우리 시스템과 이전 Peters et al.(2017)의 주요 차이점은 작업 모델이 모든 biLM 레이어의 가중 평균을 학습하도록 허용한 반면 Peters et al. (2017)은 최상위 biLM 레이어만 사용합니다. 초에 표시된대로. 5.1에서는 마지막 레이어 대신 모든 레이어를 사용하면 여러 작업 전반에 걸쳐 성능이 향상됩니다.
감정 분석 Stanford Sentiment Treebank(SST-5; Socher et al., 2013)의 세분화된 감정 분류 작업에는 영화 리뷰의 문장을 설명하기 위해 5개 레이블(매우 부정적인 것부터 매우 긍정적인 것까지) 중 하나를 선택하는 작업이 포함됩니다. 문장에는 관용어와 같은 다양한 언어 현상과 모델이 학습하기 어려운 부정과 같은 복잡한 구문 구조가 포함되어 있습니다. 우리의 기본 모델은 McCann et al.(2017)의 BCN(Biattentive Classification Network)이며, 이는 CoVe 임베딩으로 강화될 때 이전의 state-of-the-art 결과도 유지했습니다. BCN 모델에서 CoVe를 ELMo로 교체하면 최신 기술에 비해 절대 정확도가 1.0% 향상됩니다.
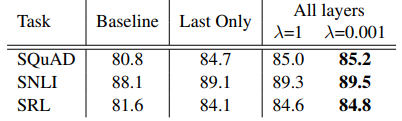
표 2: SQuAD, SNLI 및 SRL에 대한 개발 세트 성능은 biLM의 모든 레이어(다양한 정규화 강도 λ 선택 포함)를 사용하여 최상위 레이어만 사용하는 것과 비교합니다.
5 분석
이 섹션에서는 주요 주장을 검증하고 ELMo 표현의 몇 가지 흥미로운 측면을 설명하기 위한 절제 분석을 제공합니다. Sec. 5.1은 다운스트림 작업에서 깊은 상황별 표현을 사용하면 biLM 또는 MT 인코더에서 생성되었는지 여부에 관계없이 최상위 레이어만 사용하는 이전 작업에 비해 성능이 향상되고 ELMo 표현이 최고의 전체 성능을 제공한다는 것을 보여줍니다. Sec. 5.3은 biLM에서 캡처된 다양한 유형의 상황별 정보를 탐색하고 두 가지 고유 평가를 사용하여 MT 인코더와 일치하게 구문 정보가 하위 계층에서 더 잘 표현되는 반면 의미 정보는 상위 계층에서 캡처된다는 것을 보여줍니다. 또한 우리의 biLM이 CoVe보다 지속적으로 더 풍부한 표현을 제공한다는 것을 보여줍니다.
또한 작업 모델(Sec. 5.2), 훈련 세트 크기(Sec. 5.4)에 ELMo가 포함된 위치에 대한 민감도를 분석하고 작업 전반에 걸쳐 ELMo 학습 가중치를 시각화합니다(Sec. 5.5).
5.1 대체 레이어 가중치 체계
biLM 레이어를 결합하기 위해 Equation 1에 대한 많은 대안이 있습니다. 상황별 표현에 대한 이전 작업에서는 biLM(Peters et al., 2017)이든 MT 인코더(CoVe, McCann et al., 2017)이든 마지막 레이어만 사용했습니다. λ = 1과 같은 큰 값은 레이어에 대한 가중치 함수를 효과적으로 감소시키는 반면, 작은 값(예: λ = 0.001)을 사용하면 레이어 가중치가 달라질 수 있으므로 정규화 매개변수 λ의 선택도 중요합니다.
표 2는 SQuAD, SNLI 및 SRL에 대한 이러한 대안을 비교합니다. 모든 레이어의 표현을 포함하면 마지막 레이어를 사용하는 것보다 전반적인 성능이 향상되고, 마지막 레이어의 상황별 표현을 포함하면 기준에 비해 성능이 향상됩니다. 예를 들어 SQuAD의 경우 마지막 biLM 레이어만 사용하면 개발 F1이 기준선보다 3.9% 향상됩니다. 마지막 레이어만 사용하는 대신 모든 biLM 레이어를 평균화하면 F1이 0.3% 더 향상되고("Last Only"를 λ=1 열과 비교) 작업 모델이 개별 레이어 가중치를 학습하도록 허용하면 F1이 0.2% 더 향상됩니다(λ=1 대 λ=0.001). 대부분의 경우 ELMo에서는 작은 λ가 선호되지만 훈련 세트가 더 작은 작업인 NER의 경우 결과는 λ에 민감하지 않습니다(표시되지 않음).
전반적인 추세는 CoVe와 유사하지만 기준선에 비해 증가 폭이 더 작습니다. SNLI의 경우 λ=1로 모든 레이어를 평균화하면 마지막 레이어만 사용할 때보다 개발 정확도가 88.2%에서 88.7%로 향상됩니다. SRL F1은 마지막 레이어만 사용하는 것과 비교하여 λ=1 경우에 대해 82.2로 한계 0.1% 증가했습니다.
5.2 ELMo를 어디에 포함시킬 것인가?
이 문서의 모든 작업 아키텍처에는 최하위 계층 biRNN에 대한 입력으로만 단어 임베딩이 포함됩니다. 그러나 작업별 아키텍처의 biRNN 출력에 ELMo를 포함하면 일부 작업의 전반적인 결과가 향상된다는 것을 발견했습니다. 표 3에서 볼 수 있듯이 SNLI 및 SQuAD의 입력 및 출력 레이어 모두에 ELMo를 포함하면 입력 레이어보다 향상되지만 SRL(및 상호 참조 해상도, 표시되지 않음)의 경우 입력 레이어에만 포함되었을 때 성능이 가장 높습니다.
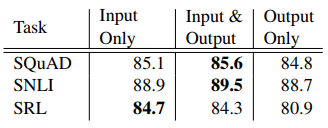
표 3: 감독 모델의 다양한 위치에 ELMo를 포함할 때 SQuAD, SNLI 및 SRL에 대한 개발 세트 성능.
이 결과에 대한 한 가지 가능한 설명은 SNLI와 SQuAD 아키텍처가 모두 biRNN 이후 Attention 레이어를 사용하므로 이 레이어에 ELMo를 도입하면 모델이 biLM의 내부 표현에 직접 참여할 수 있다는 것입니다. SRL의 경우 작업별 컨텍스트 표현이 biLM의 표현보다 더 중요할 수 있습니다.
5.3 biLM의 표현에는 어떤 정보가 포함됩니까?
ELMo를 추가하면 단어 벡터보다 작업 성능이 향상되므로 biLM의 상황별 표현은 캡처되지 않은 NLP 작업에 일반적으로 유용한 정보를 인코딩해야 합니다.
단어 벡터에서 직관적으로 biLM은 문맥을 사용하여 단어의 의미를 명확하게 해야 합니다. 매우 다의어적인 단어인 "play"를 생각해 보십시오. 표 4의 상단에는 GloVe 벡터를 사용하여 "play"할 가장 가까운 이웃이 나열되어 있습니다.
이는 품사의 여러 부분(예: "played", "playing"을 동사로, "player", "game"을 명사로 사용)에 분산되어 있지만 "play"라는 스포츠 관련 의미에 집중되어 있습니다. 대조적으로, 맨 아래 두 행은 원본 문장에서 biLM의 "play" 컨텍스트 표현을 사용하여 SemCor 데이터세트(아래 참조)의 가장 가까운 이웃 문장을 보여줍니다. 이러한 경우 biLM은 원본 문장에서 품사와 단어 의미를 모두 명확하게 구분할 수 있습니다.
이러한 관찰은 Belinkov et al.(2017)과 유사한 맥락적 표현의 본질적인 평가를 사용하여 정량화될 수 있습니다. biLM에 의해 인코딩된 정보를 분리하기 위해 표현은 세밀한 단어 의미 명확성(WSD) 작업 및 POS 태깅 작업에 대한 예측을 직접 만드는 데 사용됩니다. 이 접근 방식을 사용하면 CoVe와 각 개별 계층을 비교하는 것도 가능합니다.

표 4: GloVe 및 biLM의 컨텍스트 임베딩을 사용하여 "play"할 가장 가까운 이웃.
단어 의미 명확성 문장이 주어지면 biLM 표현을 사용하여 Melamud et al.(2016)과 유사한 간단한 1-최근접 이웃 접근 방식을 사용하여 대상 단어의 의미를 예측할 수 있습니다. 이를 위해 먼저 biLM을 사용하여 훈련 자료인 Sem-Cor 3.0(Miller et al., 1994)의 모든 단어에 대한 표현을 계산한 다음 각 의미에 대한 평균 표현을 취합니다. 테스트 시간에 우리는 다시 biLM을 사용하여 주어진 대상 단어에 대한 표현을 계산하고 훈련 세트에서 가장 가까운 이웃 의미를 가져오고 훈련 중에 관찰되지 않은 기본정리에 대해 WordNet의 첫 번째 의미로 돌아갑니다.
표 5는 Raganato et al.(2017a)의 동일한 4개 테스트 세트 세트에 걸쳐 Raganato et al.(2017b)의 평가 프레임워크를 사용하여 WSD 결과를 비교합니다. 전반적으로 biLM 최상위 레이어 표현은 F1이 69.0이고 첫 번째 레이어보다 WSD에서 더 좋습니다. 수작업 기능을 사용하는 state-of-the-art WSD-specific supervised 모델(Iacobacci et al., 2016) 및 특정 작업의 대략적인 의미 체계 레이블 및 POS 태그 (Raganato et al., 2017a)로 훈련된 작업별 biLSTM과 경쟁적입니다. CoVe biLSTM 레이어는 biLM의 레이어와 유사한 패턴을 따릅니다(첫 번째 레이어에 비해 두 번째 레이어의 전체 성능이 더 높음). 그러나 우리의 biLM은 WordNet First Sense 기준선을 뒤쫓는 CoVe biLSTM보다 성능이 뛰어납니다.
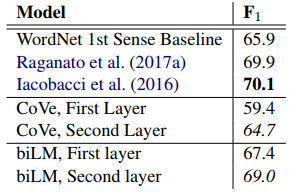
표 5: 모든 단어로 세분화된 WSD F1. CoVe 및 biLM의 경우 첫 번째 및 두 번째 계층 biLSTM 모두에 대한 점수를 보고합니다.
POS 태깅 biLM이 기본 구문을 캡처하는지 여부를 조사하기 위해 Penn Treebank(PTB)의 Wall Street Journal 부분을 사용하여 POS 태그를 예측하는 선형 분류기에 대한 입력으로 컨텍스트 표현을 사용했습니다(Marcus et al., 1993).
선형 분류기는 소량의 모델 용량만 추가하므로 이는 biLM 표현을 직접 테스트하는 것입니다. WSD와 유사하게 biLM 표현은 신중하게 조정된 작업별 biLSTM과 경쟁적입니다(Ling et al., 2015; Ma and Hovy, 2016). 그러나 WSD와 달리 첫 번째 biLM 레이어를 사용한 정확도는 최상위 레이어보다 높으며 이는 다중 작업 훈련(Søgaard 및 Gold-berg, 2016; Hashimoto et al., 2017) 및 MT(Be- linkov 외, 2017). CoVe POS 태깅 정확도는 biLM과 동일한 패턴을 따르며 WSD와 마찬가지로 biLM은 CoVe 인코더보다 더 높은 정확도를 달성합니다.
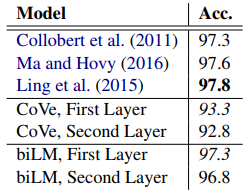
표 6: PTB에 대한 테스트 세트 POS 태깅 정확도. CoVe 및 biLM의 경우 첫 번째 및 두 번째 계층 biLSTM 모두에 대한 점수를 보고합니다.
지도 작업에 대한 의미 종합적으로 볼 때, 이러한 실험은 biLM의 다양한 레이어가 다양한 유형의 정보를 나타냄을 확인하고 모든 biLM 레이어를 포함하는 이유를 설명합니다.
다운스트림 작업에서 최고의 성능을 발휘하는데 중요합니다. 또한 biLM의 표현은 CoVe의 표현보다 WSD 및 POS 태깅으로 더 쉽게 전환 가능하므로 ELMo가 다운스트림 작업에서 CoVe보다 뛰어난 성능을 보이는 이유를 설명하는 데 도움이 됩니다.
5.4 표본 효율성
모델에 ELMo를 추가하면 state-of-the-art 성능에 도달하기 위한 매개변수 업데이트 수와 전체 훈련 세트 크기 측면에서 샘플 효율성이 상당히 높아집니다. 예를 들어, SRL 모델은 ELMo 없이 486번의 훈련 후에 최대 개발 F1에 도달합니다. ELMo를 추가한 후 모델은 에포크 10에서 기준 최대값을 초과합니다. 이는 동일한 성능 수준에 도달하는 데 필요한 업데이트 수가 상대적으로 98% 감소한 것입니다.
또한 ELMo 강화 모델은 ELMo가 없는 모델보다 더 작은 훈련 세트를 더 효율적으로 사용합니다. 그림 1은 기준 모델이 있는 경우와 없는 경우의 성능을 비교합니다.
전체 훈련 세트의 백분율인 ELMo는 0.1%에서 100%까지 다양합니다. ELMo의 개선 사항은 더 작은 훈련 세트에서 가장 크며 주어진 성능 수준에 도달하는 데 필요한 훈련 데이터의 양을 크게 줄입니다. SRL의 경우 훈련 세트가 1%인 ELMo 모델은 훈련 세트가 10%인 기본 모델과 F1이 거의 동일합니다.
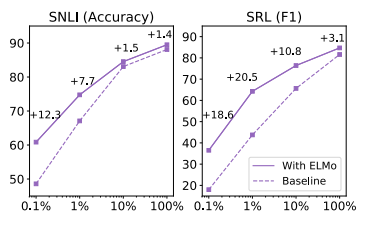
그림 1: 훈련 세트 크기가 0.1%에서 100%까지 다양할 때 SNLI 및 SRL에 대한 기준선과 ELMo 성능의 비교.
5.5 학습된 가중치의 시각화
그림 2는 소프트맥스 정규화 학습된 계층 가중치를 시각화합니다. 입력 레이어에서 작업 모델은 첫 번째 biLSTM 레이어를 선호합니다. 상호 참조 및 SQuAD의 경우 이것이 매우 선호되지만 다른 작업의 경우 분포가 덜 정점에 있습니다. 출력 레이어 가중치는 상대적으로 균형이 잡혀 있으며 하위 레이어가 약간 선호됩니다.
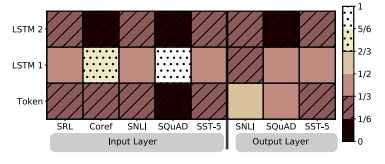
그림 2: 작업 및 ELMo 위치 전반에 걸쳐 소프트맥스 정규화된 biLM 계층 가중치 시각화. 1/3보다 작은 정규화된 가중치는 수평선으로 표시되고 2/3보다 큰 가중치는 얼룩으로 표시됩니다.
6 결론
우리는 biLM에서 고품질의 심층 컨텍스트 종속 표현을 학습하기 위한 일반적인 접근 방식을 도입했으며 ELMo를 광범위한 NLP 작업에 적용할 때 큰 개선을 보였습니다. 절제 및 기타 통제된 실험을 통해 우리는 biLM 레이어가 문맥 내 단어에 대한 다양한 유형의 구문 및 의미 정보를 효율적으로 인코딩하고 모든 레이어를 사용하면 모든 작업 성능이 향상된다는 사실도 확인했습니다.
References
1. Jimmy Ba, Ryan Kiros, and Geoffrey E. Hinton. 2016. Layer normalization. CoRR abs/1607.06450.
2. Yonatan Belinkov, Nadir Durrani, Fahim Dalvi, Hassan Sajjad, and James R. Glass. 2017. What do neural machine translation models learn about morphology? In ACL.
3. Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2017. Enriching word vectors with subword information. TACL 5:135–146.
4. Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. 2015. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics.
5. Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. 2014. One billion word benchmark for measuring progress in statistical language modeling. In INTERSPEECH .
6. Qian Chen, Xiao-Dan Zhu, Zhen-Hua Ling, Si Wei, Hui Jiang, and Diana Inkpen. 2017. Enhanced lstm for natural language inference. In ACL.
7. Jason Chiu and Eric Nichols. 2016. Named entity recognition with bidirectional LSTM-CNNs. In TACL.
8. Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bahdanau, and Yoshua Bengio. 2014. On the properties of neural machine translation: Encoder-decoder approaches. In SSST@EMNLP.
9. Christopher Clark and Matthew Gardner. 2017. Simple and effective multi-paragraph reading comprehension. CoRR abs/1710.10723.
11. Kevin Clark and Christopher D. Manning. 2016. Deep reinforcement learning for mention-ranking coreference models. In EMNLP.
12. Ronan Collobert, Jason Weston, Leon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel P. Kuksa. 2011. Natural language processing (almost) from scratch. In JMLR.
13. Andrew M. Dai and Quoc V. Le. 2015. Semisupervised sequence learning. In NIPS.
14. Greg Durrett and Dan Klein. 2013. Easy victories and uphill battles in coreference resolution. In EMNLP.
15. Yarin Gal and Zoubin Ghahramani. 2016. A theoretically grounded application of dropout in recurrent neural networks. In NIPS.
16. Yichen Gong, Heng Luo, and Jian Zhang. 2018. Natural language inference over interaction space. In ICLR.
17. Kazuma Hashimoto, Caiming Xiong, Yoshimasa Tsuruoka, and Richard Socher. 2017. A joint many-task model: Growing a neural network for multiple nlp tasks. In EMNLP 2017 .
18. Luheng He, Kenton Lee, Mike Lewis, and Luke S. Zettlemoyer. 2017. Deep semantic role labeling: What works and what’s next. In ACL.
19. Sepp Hochreiter and Jurgen Schmidhuber.1997. Long short-term memory. Neural Computation 9.
Ignacio Iacobacci, Mohammad Taher Pilehvar, and Roberto Navigli. 2016. Embeddings for word sense disambiguation: An evaluation study. In ACL.
20. Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu. 2016. Exploring the limits of language modeling. CoRR abs/1602.02410.
21. Rafal Jozefowicz, Wojciech Zaremba, and Ilya Sutskever. 2015. An empirical exploration of recurrent network architectures. In ICML.
22. Yoon Kim, Yacine Jernite, David Sontag, and Alexander M Rush. 2015. Character-aware neural language models. In AAAI 2016.
23. Diederik P. Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In ICLR.
24. Ankit Kumar, Ozan Irsoy, Peter Ondruska, Mohit Iyyer, Ishaan Gulrajani James Bradbury, Victor Zhong, Romain Paulus, and Richard Socher. 2016. Ask me anything: Dynamic memory networks for natural language processing. In ICML.
25. John D. Lafferty, Andrew McCallum, and Fernando Pereira. 2001. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In ICML.
26. Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. 2016. Neural architectures for named entity recognition. In NAACL-HLT .
27. Kenton Lee, Luheng He, Mike Lewis, and Luke S. Zettlemoyer. 2017. End-to-end neural coreference resolution. In EMNLP.
28. Wang Ling, Chris Dyer, Alan W. Black, Isabel Trancoso, Ramon Fermandez, Silvio Amir, Luıs Marujo, and Tiago Luıs. 2015. Finding function in form: Compositional character models for open vocabulary word representation. In EMNLP.
29. Xiaodong Liu, Yelong Shen, Kevin Duh, and Jianfeng Gao. 2017. Stochastic answer networks for machine reading comprehension. arXiv preprint arXiv:1712.03556 .
30. Xuezhe Ma and Eduard H. Hovy. 2016. End-to-end sequence labeling via bi-directional LSTM-CNNs-CRF. In ACL.
31. Mitchell P. Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. 1993. Building a large annotated corpus of english: The penn treebank. Computational Linguistics 19:313–330.
32. Bryan McCann, James Bradbury, Caiming Xiong, and Richard Socher. 2017. Learned in translation: Contextualized word vectors. In NIPS 2017.
33. Oren Melamud, Jacob Goldberger, and Ido Dagan. 2016. context2vec: Learning generic context embedding with bidirectional lstm. In CoNLL.
34. Gabor Melis, Chris Dyer, and Phil Blunsom. 2017. On the state of the art of evaluation in neural language models. CoRR abs/1707.05589.
35. Stephen Merity, Nitish Shirish Keskar, and Richard Socher. 2017. Regularizing and optimizing lstm language models. CoRR abs/1708.02182.
36. Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality. In NIPS.
37. George A. Miller, Martin Chodorow, Shari Landes, Claudia Leacock, and Robert G. Thomas. 1994. Using a semantic concordance for sense identification. In HLT.
38. Tsendsuren Munkhdalai and Hong Yu. 2017. Neural tree indexers for text understanding. In EACL.
39. Arvind Neelakantan, Jeevan Shankar, Alexandre Passos, and Andrew McCallum. 2014. Efficient nonarametric estimation of multiple embeddings per word in vector space. In EMNLP.
40. Martha Palmer, Paul Kingsbury, and Daniel Gildea. 2005. The proposition bank: An annotated corpus of semantic roles. Computational Linguistics 31:71–106
41. Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. Glove: Global vectors for word representation. In EMNLP.
42. Matthew E. Peters, Waleed Ammar, Chandra Bhagavatula, and Russell Power. 2017. Semi-supervised sequence tagging with bidirectional language models. In ACL.
43. Sameer Pradhan, Alessandro Moschitti, Nianwen Xue, Hwee Tou Ng, Anders Bjorkelund, Olga Uryupina, Yuchen Zhang, and Zhi Zhong. 2013. Towards robust linguistic analysis using ontonotes. In CoNLL.
44. Sameer Pradhan, Alessandro Moschitti, Nianwen Xue, Olga Uryupina, and Yuchen Zhang. 2012. Conll2012 shared task: Modeling multilingual unrestricted coreference in ontonotes. In EMNLP-CoNLL Shared Task.
45. Alessandro Raganato, Claudio Delli Bovi, and Roberto Navigli. 2017a. Neural sequence learning models for word sense disambiguation. In EMNLP.
46. Alessandro Raganato, Jose Camacho-Collados, and Roberto Navigli. 2017b. Word sense disambiguation: A unified evaluation framework and empirical comparison. In EACL.
47. Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100, 000+ questions for machine comprehension of text. In EMNLP.
48. Prajit Ramachandran, Peter Liu, and Quoc Le. 2017. Improving sequence to sequence learning with unlabeled data. In EMNLP.
49. Erik F. Tjong Kim Sang and Fien De Meulder. 2003. Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. In CoNLL.
50. Min Joon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hannaneh Hajishirzi. 2017. Bidirectional attention flow for machine comprehension. In ICLR.
51. Richard Socher, Alex Perelygin, Jean Y Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment treebank. In EMNLP.
52. Anders Søgaard and Yoav Goldberg. 2016. Deep multi-task learning with low level tasks supervised at lower layers. In ACL 2016.
53. Nitish Srivastava, Geoffrey E. Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research 15:1929–1958.
54. Rupesh Kumar Srivastava, Klaus Greff, and Jurgen Schmidhuber. 2015. Training very deep networks. In NIPS.
55. Joseph P. Turian, Lev-Arie Ratinov, and Yoshua Bengio. 2010. Word representations: A simple and general method for semi-supervised learning. In ACL.
56. Wenhui Wang, Nan Yang, Furu Wei, Baobao Chang, and Ming Zhou. 2017. Gated self-matching networks for reading comprehension and question answering. In ACL.
57. John Wieting, Mohit Bansal, Kevin Gimpel, and Karen Livescu. 2016. Charagram: Embedding words and sentences via character n-grams. In EMNLP.
58. Sam Wiseman, Alexander M. Rush, and Stuart M. Shieber. 2016. Learning global features for coreference resolution. In HLT-NAACL.
59. Matthew D. Zeiler. 2012. Adadelta: An adaptive learning rate method. CoRR abs/1212.5701.
60. Jie Zhou and Wei Xu. 2015. End-to-nd learning of semantic role labeling using recurrent neural networks. In ACL.
61. Peng Zhou, Zhenyu Qi, Suncong Zheng, Jiaming Xu, Hongyun Bao, and Bo Xu. 2016. Text classification improved by integrating bidirectional lstm with two dimensional max pooling. In COLING.
심층적인 문맥화된 단어 표현을 수반하는 보충 자료
이 보충 자료에는 섹션 4의 state-of-the-art 모델에 대한 모델 아키텍처, 훈련 루틴 및 하이퍼 매개변수 선택에 대한 세부 정보가 포함되어 있습니다.
모든 개별 모델은 여러 계층의 스택 RNN(GRU를 사용하는 SQuAD 모델을 제외한 모든 경우에 LSTM) 아래에 컨텍스트 독립적인 토큰 표현을 사용하여 가장 낮은 계층의 공통 아키텍처를 공유합니다.
A.1 biLM 미세 조정
섹션에서 언급한 바와 같이. 3.4에서 작업별 데이터에 대한 biLM을 미세 조정하면 일반적으로 복잡성이 크게 감소합니다. 주어진 작업을 미세 조정하기 위해 감독된 레이블은 일시적으로 무시되었으며, biLM은 훈련 분할에서 한 에포크 동안 미세 조정되고 개발 분할에서 평가되었습니다. 미세 조정이 완료되면 작업 훈련 중에 biLM 가중치가 고정되었습니다.
표 7은 고려된 작업에 대한 개발 세트의 복잡성을 나열합니다. CoNLL 2012를 제외한 모든 경우에 미세 조정을 통해 복잡성이 크게 향상됩니다(예: SNLI의 경우 72.1에서 16.8로).
감독 성능에 대한 미세 조정의 영향은 작업에 따라 다릅니다. SNLI의 경우 biLM을 미세 조정하면 단일 최고 모델의 개발 정확도가 88.9%에서 89.5%로 0.6% 증가했습니다. 그러나 감정 분류 개발 세트의 정확도는 미세 조정된 biLM 사용 여부에 관계없이 거의 동일합니다.
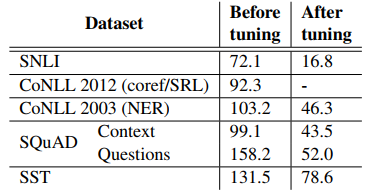
표 7: 다양한 데이터 세트에 대한 훈련 세트에 대한 one epoch의 미세 조정 전후의 개발 세트 복잡성(낮을수록 좋음). 보고된 값은 순방향 및 역방향 복잡도의 평균입니다.
A.2 식에서 γ의 중요성. (1)
식의 γ 매개변수. (1)은 biLM 내부 표현과 작업별 표현 간의 분포가 다르기 때문에 최적화를 돕는 데 실질적으로 중요했습니다.
Sec의 마지막 경우에만 특히 중요합니다. 5.1. 이 매개변수가 없으면 마지막 전용 사례는 SNLI에 대해 제대로 수행되지 않았고(기준보다 훨씬 낮음) SRL에 대한 훈련은 완전히 실패했습니다.
A.3 텍스트 내용
우리의 기본 SNLI 모델은 Chen et al. (2017)의 ESIM 시퀀스 모델입니다. 원래 구현에 따라 우리는 모든 LSTM 및 피드포워드 레이어에 300차원을 사용하고 훈련 중에 수정된 사전 훈련된 300차원 GloVe 임베딩을 사용했습니다. 정규화를 위해 각 LSTM 레이어의 입력에 50% 변형 드롭아웃(Gal and Ghahramani, 2016)을 추가하고 마지막 두 완전 연결 레이어의 입력에 50% 드롭아웃(Srivastava et al., 2014)을 추가했습니다. 모든 피드포워드 계층은 ReLU 활성화를 사용합니다. 매개변수는 Adam(Kingma and Ba, 2015)을 사용하여 최적화되었으며 그라디언트 표준은 5.0으로 잘리고 초기 학습 속도는 0.0004로 개발 세트의 정확도가 후속 시대에서 증가하지 않을 때마다 절반씩 감소했습니다. 배치 크기는 32였습니다.
최상의 ELMo 구성은 레이어 정규화 및 λ = 0.001을 사용하는 (1)을 사용하여 최하위 레이어 LSTM의 입력과 출력 모두에 ELMo 벡터를 추가했습니다. ELMo 모델의 매개변수 수가 증가함에 따라 모든 순환 및 피드포워드 가중치 행렬에 정규화 계수 0.0001을 갖는 2개의 정규화를 추가하고 어텐션 계층 이후에는 50% 드롭아웃을 추가했습니다.
표 8은 우리 시스템의 테스트 세트 정확도를 이전에 발표된 시스템과 비교합니다. 전체적으로 ESIM 모델에 ELMo를 추가하면 정확도가 0.7% 향상되어 새로운 단일 모델의 state-of-the-art 88.7%를 구축했으며, 5인 앙상블을 사용하면 전체 정확도가 89.3%로 향상됩니다.

표 8: SNLI 테스트 세트 정확도. 단일 모델 결과가 그 부분을 차지하고 앙상블 결과는 맨 아래에 있습니다.
A.4 질문 답변
우리의 QA 모델은 Clark 및 Gardner(2017) 모델의 단순화된 버전입니다. 각 토큰의 대소문자를 구분하는 300차원 GloVe 단어 벡터(Pennington et al., 2014)를 컨볼루션 신경망을 사용하여 생성된 문자 파생 임베딩과 학습된 문자 임베딩에 대한 최대 풀링을 연결하여 토큰을 임베딩합니다. 토큰 임베딩은 공유된 양방향 GRU를 통과한 다음 BiDAF의 양방향 주의 메커니즘을 통과합니다(Seo et al., 2017). 그런 다음 증강된 컨텍스트 벡터는 ReLU 활성화가 있는 선형 계층, GRU를 사용하는 잔여 self-attention 계층과 컨텍스트 간 컨텍스트에 동일한 주의 메커니즘이 적용되는 ReLU 활성화가 있는 또 다른 선형 계층을 통과합니다. 마지막으로 결과는 선형 레이어를 통해 제공되어 답변의 시작 및 끝 토큰을 예측합니다.
Variational Dropout은 GRU 및 선형 레이어에 대한 입력 이전에 0.2 비율로 사용됩니다. GRU에는 90차원이 사용되고 선형 레이어에는 180차원이 사용됩니다. 우리는 배치 크기가 45인 Adadelta를 사용하여 모델을 최적화했습니다. 테스트 시에는 가중치의 지수 이동 평균을 사용하고 출력 범위를 최대 크기 17로 제한합니다. 훈련 중에 단어 벡터를 업데이트하지 않습니다.
상황별 GRU 레이어의 입력과 출력 모두에 레이어 정규화 없이 ELMo를 추가하고 ELMo 가중치를 비정규화(λ = 0)로 남겨둘 때 성능이 가장 높았습니다.
표 9는 시스템을 제출한 2017년 11월 17일 현재 SQuAD 리더보드의 테스트 세트 결과를 비교합니다. 전반적으로 우리가 제출한 단일 모델 및 앙상블 결과가 가장 높았으며, 이전 단일 모델 결과(SAN)는 1.4% F1, 기준선은 4.2% 향상되었습니다. 11 member로 구성된 앙상블은 F1을 87.4%로 끌어올려 이전 앙상블 최고치보다 1.0% 증가했습니다.
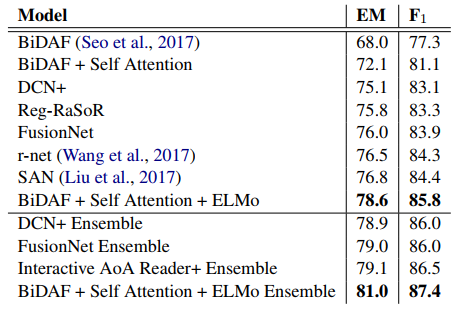
표 9: 정확히 일치(EM)와 F1을 모두 보여주는 SQuAD에 대한 테스트 세트 결과. 테이블의 위쪽 절반에는 아래쪽에 앙상블이 있는 단일 모델 결과가 포함됩니다. 가능한 경우 참조 자료가 제공됩니다.
A.5 의미론적 역할 라벨링
우리의 기본 SRL 모델은 (He et al., 2017)을 정확하게 재구현한 것입니다. 단어는 GloVe(Pennington et al., 2014)를 사용하여 초기화된 100차원 벡터 표현의 연결과 100차원 임베딩을 사용하여 표현된 이진 단어별 조건자 기능을 사용하여 표현됩니다. 이 200차원 토큰 표현은 300차원 숨겨진 크기를 갖는 8개 계층 "인터리브" biLSTM을 통과하며, 여기서 LSTM 계층의 방향은 계층별로 번갈아 나타납니다. 이 심층 LSTM은 레이어 간 고속도로 연결(Srivastava et al., 2015)과 변형 반복 드롭아웃(Gal and Ghahramani, 2016)을 사용합니다. 그런 다음 이 심층 표현은 최종 밀집 레이어를 사용하여 투영됩니다.
소프트맥스 활성화를 통해 가능한 모든 태그에 대한 분포를 형성합니다. 라벨은 인수 범위를 나타내기 위해 BIO 라벨링 방식으로 보강된 PropBank(Palmer et al., 2005)의 의미론적 역할로 구성됩니다. 훈련 중에 학습률 1.0 및 ρ = 0.95인 Adadelta를 사용하여 태그 시퀀스의 음의 로그 가능성을 최소화합니다(Zeiler, 2012).
테스트 시에는 BIO 제약 조건을 사용하여 유효한 범위를 적용하기 위해 Viterbi 디코딩을 수행합니다. 모든 LSTM 히든 레이어에 10%의 변형 드롭아웃이 추가됩니다. 값이 1.0을 초과하면 그라데이션이 잘립니다.
모델은 500 epoch 동안 또는 검증 F1이 200 epoch 동안 개선되지 않을 때까지 중 더 빠른 기간 동안 학습됩니다. 사전 훈련된 GloVe 벡터는 훈련 중에 미세 조정됩니다. Final Dense Layer와 모든 LSTM의 모든 셀은 직교하도록 초기화됩니다. 망각 게이트 바이어스는 모든 LSTM에 대해 1로 초기화되고, 다른 모든 게이트는 0으로 초기화됩니다(Jozefowicz et al.', 2015).
표 10은 ELMo 증강 구현(He et al., 2017)의 테스트 세트 F1 점수를 이전 결과와 비교합니다. 84.6 F1의 단일 모델 점수는 CONLL 2012 Semantic Role Labeling 작업에 대한 새로운 state-of-the-art 결과를 나타내며 이전 단일 모델 결과를 2.9 F1, 5-모델 앙상블을 1.2 F1 능가합니다.
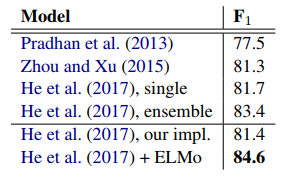
표 10: SRL CoNLL 2012 테스트 세트 F1.
A.6 상호 참조 해결
우리의 기본 상호 참조 모델은 Lee et al.(2017)의 엔드투엔드 신경 모델이며 모든 하이퍼파라미터는 원래 구현을 정확히 따릅니다.
최상의 구성은 최하위 계층 biLSTM의 입력에 ELMo를 추가하고 정규화(λ = 0) 또는 계층 정규화 없이 (1)을 사용하여 biLM 계층에 가중치를 부여했습니다. ELMo 표현에 50% 드롭아웃이 추가되었습니다.
표 11은 우리의 결과를 이전에 발표된 결과와 비교합니다. 전반적으로 우리는 단일 모델을 3.2% 평균 F1만큼 개선했으며, 단일 모델 결과는 이전 앙상블을 1.6% F1만큼 향상시켰습니다. biLSTM 입력 외에 biLSTM의 출력에 ELMo를 추가하면 F1이 약 0.7% 감소했습니다(표시되지 않음).
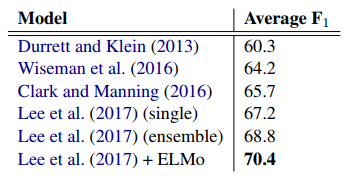
표 11: CoNLL 2012 공유 작업의 테스트 세트에 대한 상호 참조 해결 평균 F1.
A.7 명명된 엔터티 인식
우리의 기본 NER 모델은 사전 훈련된 50차원 Senna 벡터(Collobert et al., 2011)를 CNN 문자 기반 표현과 연결합니다.
문자 표현은 16차원 문자 임베딩과 너비가 3자인 128개의 컨벌루션 필터, ReLU 활성화 및 최대 풀링을 사용합니다. 토큰 표현은 두 개의 biLSTM 레이어를 통해 전달됩니다. 첫 번째 레이어에는 200개의 숨겨진 유닛이 있고 두 번째 레이어에는 100개의 숨겨진 유닛이 있으며 최종 밀도 레이어와 소프트맥스 레이어가 있습니다. 훈련 중에는 CRF 손실을 사용하고 테스트 시 출력 태그 시퀀스가 유효한지 확인하면서 Viterbi 알고리즘을 사용하여 디코딩을 수행합니다.
두 biLSTM 레이어의 입력에 Variational Dropout이 추가됩니다. 훈련 중에 2 노름이 5.0을 초과하면 기울기의 크기가 다시 조정되고 매개변수는 0.001의 일정한 학습 속도로 Adam을 사용하여 업데이트됩니다. 사전 훈련된 Senna 임베딩은 훈련 중에 미세 조정됩니다. 우리는 개발 세트에 대한 조기 중지를 사용하고 서로 다른 무작위 시드를 사용하여 5번의 실행에서 평균 테스트 세트 점수를 보고합니다.
ELMo는 최하위 계층 작업 biLSTM의 입력에 추가되었습니다. CoNLL 2003 NER 데이터 세트가 상대적으로 작기 때문에 (1)을 사용하여 λ = 0.1을 설정하여 훈련 가능한 계층 가중치를 효과적으로 일정하게 제한함으로써 최상의 성능을 찾았습니다.
표 12는 ELMo 강화 biLSTM-CRF tagger의 테스트 세트 F1 점수를 이전 결과와 비교합니다. 전반적으로 우리 시스템의 92.22% F1은 새로운 state-of-the-art 기술을 확립합니다. Peters et al. (2017), 과 비교했을 때 biLM의 모든 계층의 표현을 사용하면 약간의 개선이 제공됩니다.
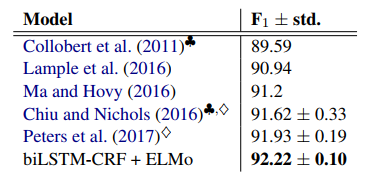
표 12: CoNLL 2003 NER 작업을 위한 테스트 세트 F1. ♣가 포함된 모델에는 gazetteers이 포함되어 있었고, ◆가 포함된 모델은 훈련을 위해 train 분할과 development 분할을 모두 사용했습니다.
A.8 감정 분류
우리는 McCann et al.(2017)에 설명된 거의 동일한 바이어텐션 분류 네트워크 아키텍처를 사용합니다. 단, 최종 최대 출력 네트워크를 드롭아웃이 있는 두 개의 ReLu 레이어로 구성된 더 간단한 피드포워드 네트워크로 대체하는 점만 다릅니다.
배치 정규화된 최대 출력 네트워크를 사용하는 BCN 모델은 실험에서 검증 정확도가 상당히 낮았지만, 우리의 구현과 McCann et al.(2017)의 구현 간에는 불일치가 있을 수 있습니다. CoVe 훈련 설정과 일치시키기 위해 우리는 4개 이상의 토큰이 포함된 문구에 대해서만 훈련합니다. 우리는 숨겨진 300-d를 사용합니다
biLSTM에 대해 상태를 지정하고 학습률 0.0001을 사용하여 Adam(Kingma 및 Ba, 2015)으로 모델 매개변수를 최적화합니다. 학습 가능한 biLM 레이어 가중치는 λ = 0.001로 정규화되며 biLSTM의 입력과 출력 모두에 ELMo를 추가합니다. 출력 ELMo 벡터는 두 번째 biLSTM으로 계산되어 입력에 연결됩니다.

표 13: SST-5의 테스트 세트 정확도.