강화학습이란?
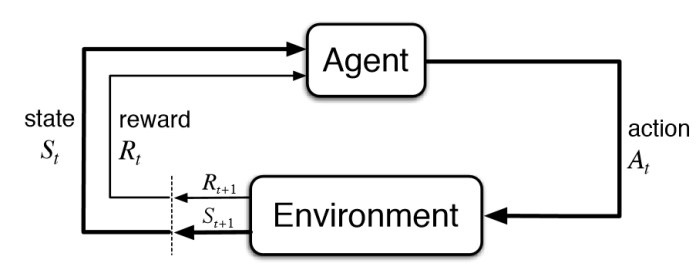
강화 학습(RL)은 에이전트가 환경과 상호 작용하여 의사 결정을 내리는 것을 배우는 기계 학습의 하위 분야입니다. 에이전트는 환경에서 행동을 취하고, 보상이나 처벌의 형태로 피드백을 받고, 이 정보를 사용하여 시간이 지남에 따라 의사 결정을 향상시킵니다.
강화 학습의 주요 구성 요소는 다음과 같습니다:
1. Agent : 환경에서 의사결정을 하고 행동을 취하는 엔티티 또는 시스템.
2. Environment : 에이전트와 상호 작용하는 외부 시스템 또는 환경.
3. Actions : 에이전트가 특정 상태에서 할 수 있는 가능한 이동 또는 결정의 집합입니다.
4. State : 에이전트의 결정에 영향을 미치는 환경의 현재 상황 또는 구성.
5. Reward : 에이전트가 특정 상태에서 행동을 취한 후 피드백으로 받는 수치. 에이전트의 목표는 시간에 따른 누적 보상을 극대화하는 것입니다.
6. Policy : 에이전트가 현재 상태에 따라 작업을 결정하는 데 사용하는 전략 또는 매핑입니다.
강화 학습 알고리즘은 에이전트가 가능한 최대 누적 보상으로 이어지는 결정을 내리도록 안내하는 최적의 정책을 찾는 것을 목표로 합니다. 학습 과정은 종종 탐색(효과를 발견하기 위해 새로운 행동을 시도하는 것)과 활용(높은 보상을 산출하는 것으로 알려진 행동을 선택하는 것) 사이의 균형을 포함합니다.
일반적인 RL 알고리즘에는 에이전트가 각 상태의 각 동작에 대한 Q 값을 학습하는 Q-러닝과 보상을 최대화하기 위해 정책을 직접 최적화하는 정책 구배 방법이 있습니다. 심층 강화 학습(DRL)은 RL과 심층 신경망을 결합하여 고차원적이고 복잡한 입력 공간의 처리를 가능하게 합니다.
RL은 로봇 공학, 게임, 금융, 건강 관리, 그리고 자율 시스템과 같은 다양한 분야에서 응용 프로그램을 찾습니다. 그것은 초인적인 수준에서 게임을 할 수 있는 에이전트를 훈련시키고, 로봇을 제어하고, 금융 거래 전략을 최적화하고, 건강 관리 치료를 개인화하는 데 사용되었습니다.
RL의 성공에도 불구하고 샘플 비효율성, 탐색-이용 절충, 하이퍼 파라미터 튜닝에 대한 민감성 등의 문제가 있습니다. 현재 진행 중인 연구는 이러한 문제를 해결하고 실제 시나리오에서 강화 학습의 적용 가능성을 확장하는 것을 목표로 하고 있습니다.