GPT-3 논문리뷰
초록
• 현재 NLP 모델이 발전하면서 파인-튜닝을 통해 다양한 task를 수행하는 모델을 만들 수 있게 되었다.
• 하지만, 인간은 단 몇 장의 사진(훈련 데이터)으로도 생애 처음 본 사물(테스트 데이터)를 구분할 수 있다. (few-shot learning의 개념)
• GPT-3는 ‘파인-튜닝’ 과정을 제거 하여 few-shot(FS) learning을 통해 몇 개의 샘플만으로도 좋은 성능을 낼 수 있다.
• 매우 큰 데이터셋을 학습시켰기 때문에 파인-튜닝을 하지 않아도 few-shot learning으로 다양한 sub-task들을 수행한다.
- 데이터셋은 3000억개의 데이터셋으로 1750억개의 파라미터를 활용하여 학습했다 (GPT-2는 15억개. GPT-3의 파라미터가 100배 이상 거대함)
- 데이터셋은 단어 뭉치를 의미한다. 3000억개의 데이터셋은 3000억개의 단어를 학습했음을 의미한다.
1. 소개
• NLP의 발전으로 독해, Q&A, textual entailment 등의 테스크에서 높은 성능을 보이고 있다.
• 그러나, 이러한 방법의 한계는 task-agnostic(테스크에 구애받지 않는)한 구조에도 불구하고 여전히 task-specific(테스크 명시적인)한 데이터셋과 파인-튜닝을 필요로 한다.
• 논문에서는 3가지 이유를 들어 이러한 한계점을 없애는 것이 바람직하다고 서술한다
1) 첫 째, 지금과 같은 방식에서는 새 태스크를 풀 때마다 많은 라벨링된 데이터가 필요하다.
2) 두 번째, 모델은 사전학습 중 대량의 지식을 흡수하지만, 아주 작은 태스크 분포에 대해 fine-tune 된다
3) 세 번째, 사람은 대부분의 언어 태스크를 하기 위해 "예제 데이터"를 많이 필요로 하지 않는다.
- 이를 극복하기 위해 meta-learning 분야가 활발하게 연구되었다.
Meta-Learning
• 이러한 문제를 다루는 한 가지 가능성은 Meta-learning이다

• Meta-Learning: 모델 학습 과정에서, 다양한 스킬과 패턴을 인지하도록 개발하는 것을 의미
• 학습 시에 2개의 루프가 존재한다
- Outer Loop : 비지도 사전학습에서의 SGD를 통한 학습
- Inner Loop : In-context learning (문맥 학습)
동일한 테스크 조합들이 하나의 sequence로 들어온다.
각각의 sequence가 어떤 테스크의 묶음인지 알려주지 않아도,
다양한 테스크들을 하나의 모델이 학습할 수 있도록 유도한다.
• 그러나, Meta-learning은 여전히 파인-튜닝 보다 낮은 성능을 낸다.
논문의 실험 조건
• 선행 연구들은 파라미터 수를 늘리면 NLP 테스크에 발전이 있음을 보여왔다.
• 그래서, 이 논문에서는 1,750억개의 파라미터를 사용하여 Auto-regressive Language Model을 훈련시키고, in-context learning 능력을 확인한다.

• 모델의 성능은 NLP 테스크에 대한 설명이 증가할수록(x축 오른쪽 방향으로 갈 수록), 모델의 문맥 예제 수 K가 커질수록 향상된다.
• few-shot learning일 때 모델 크기에 따른 성능 차이가 더 크게 난다.
• GPT-3은 NLP 테스크에서 zero-shot, one-shot learning도 유망한 결과를 달성했다.
• few-shot setting 중에서는 SOTA와 비슷하거나 능가하기도 한다.
• 그러나, 여전히 few-shot setting 성능이 안좋은 일부 태스크도 있다.
- ANLI : 자연어 추론
- RACE : 독해
- QuAC
GPT-3의 다양한 테스트에 대한 정확도 종합 그래프

2. 접근방식
기존의 fine-tuning 방식
원하는 task에 맞는 data set을 통해 taks-specific fine-tuning을 실시
• 첫번째 예시로부터 나온 결과를 보고 gradient update를 한다.
• 두번째 예시로부터 나온 결과를 보고 gradient update를 한다.
• 이 과정이 반복된다.
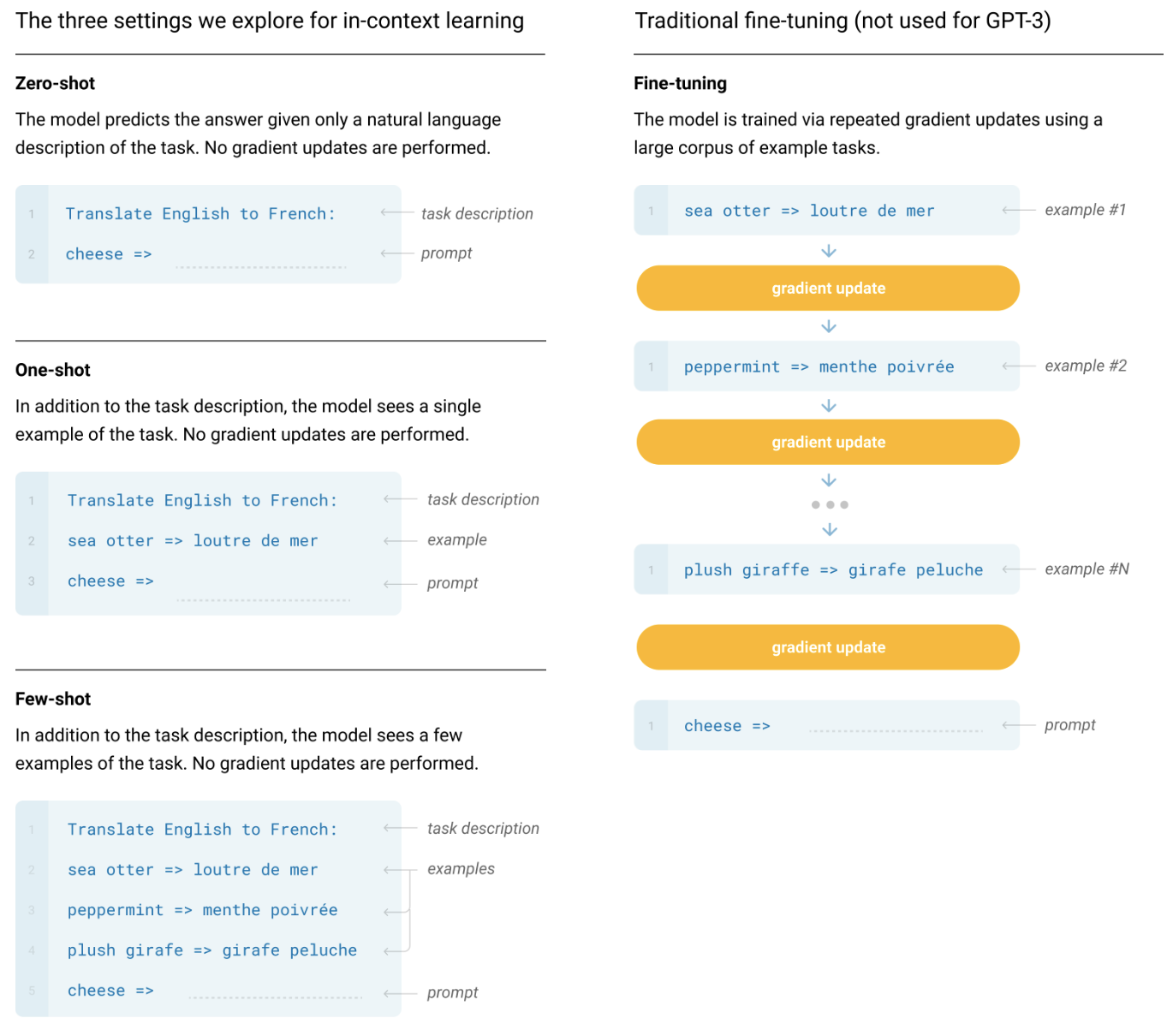
in-context learning에 대해 3가지를 평가
1) Zero-shot(0s) : 예제는 사용하지 않고 태스크에 대한 설명, 혹은 지시사항만을 모델에게 준다.
2) One-shot(1S) : task에 대한 예시가 하나만 주어지는 것으로 인간과 비슷한 조건이다.
3) Few-shot(FS) : 모델의 문맥 윈도우(10~100)에 넣을 수 있는 만큼 많은 예제를 넣고 , 가중치 업데이트를 하지 않는다.
• Translate English to French: cheese ⇒ (총 6개의 토큰/ 이 6개가 한 번에 GPT-3에 입력으로 들어감.)
• one-shot에서는 task description, example, prompt이 하나의 입력으로 들어옴.
• few-shot도 파란 박스 안에 있는 내용이 한 번에 입력됨.
• 이렇게 example들을 늘려갈 수록 성능이 얼마나 발전하는지 그림 1.3에서 볼 수 있음
2.1 Model and Architectures

• GPT-3은 GPT-2의 후속버전이라 아키텍처 자체가 크게 달라진 건 없다.
- GPT-2와 다른 점 : Sparse Attention
• Decoder 기반의 GPT 구조를 그대로 차용하되, 크기만 키운 것
• 1,750억개의 파라미터, 96개의 디코더, d_model의 차원은 12,288
- d_model: 트랜스포머의 인코더와 디코더에서의 정해진 입력과 출력의 크기
- n_heads: self-attention에서 사용하는 head의 개수
• GPT-3에서의 토큰의 개수는 모두 동일하게 2^11 = 2048개
2.2 Training Dataset
• Common Crawl 데이터셋 (거의 1조 개의 단어)
• 데이터셋의 퀄리티 향상을 위해 3단계의 전처리를 거쳐 사용함

• 위 표에서 Common Crawl의 epoch가 1이 되지 않는다. 모델이 워낙 커서 전체 데이터를 모두 사용하지 않았다.


• GPT-3가 뉴스기사를 쓰게 하고, 그 기사를 사람들에게 주고 기계가 썼는지 사람이 썼는지 구분하는 실험을 진행했다.
• 그 결과, 파라미터가 1,750억개인 경우 실험대상자의 48%가 사람이 쓴 기사라고 판단했다.(거의 랜덤 수준)
• 성능이 좋지만, 한계점도 존재함
• test set에 사전학습 시 사용했던 set을 다시 포함하는 경우가 있고, 이는 downstream task를 오염시킨다.
• 중복 항목을 제거 해야하지만, 모델이 너무 커서 학습 시키는 데 비용이 많이 들어서 문제를 무시하고 학습을 계속 진행했다.
3. 결과
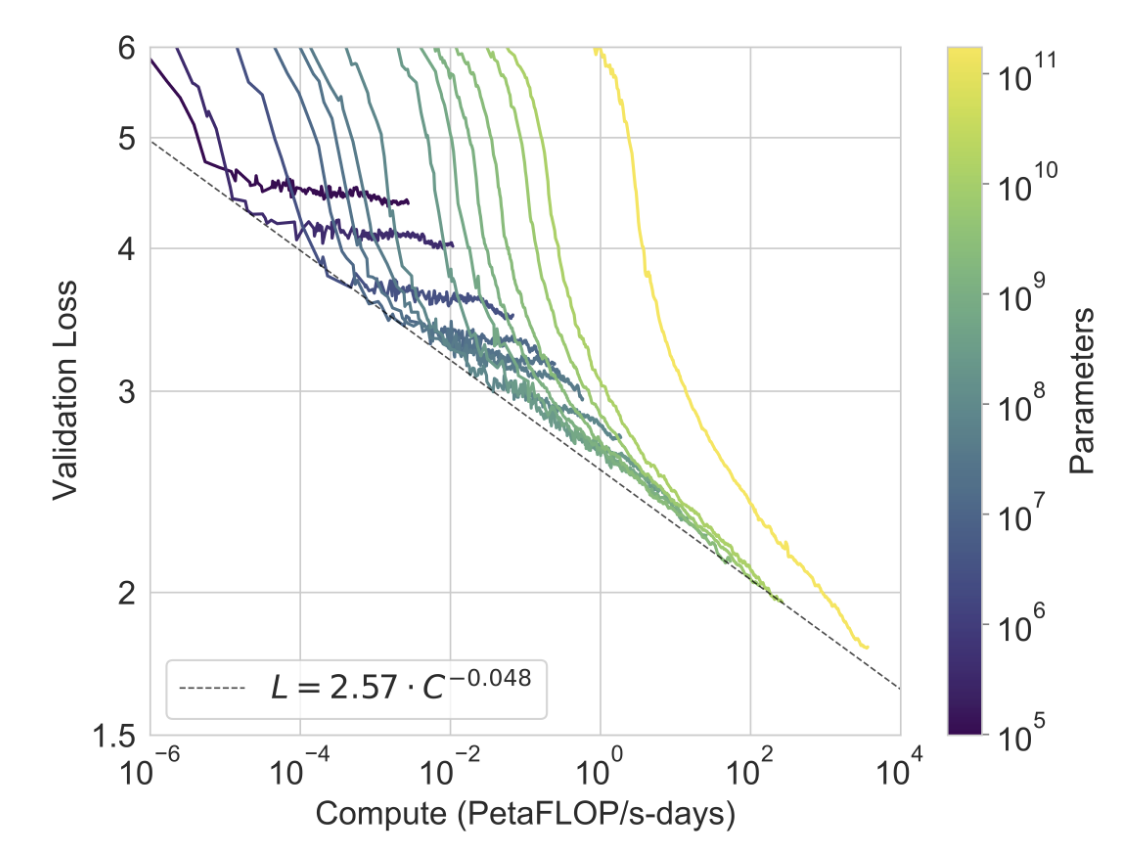
• 언어 모델의 성능은 power-law를 따른다
• 시간이 지날수록 Parameter 개수에 상관 없이 Validation Loss가 줄어든다.
- Validation Loss
1) 학습 데이터를 훈련 데이터와 검증 데이터로 나눈다.
2) 모델은 훈련 데이터를 사용하여 학습하고, 검증 데이터를 사용하여 학습 중간에 모델의 성능을 평가한다.
3) 모델이 검증 데이터에 대해 예측한 값과 실제 값 사이의 차이를 측정하는 손실 함수를 계산한다.
4) 이렇게 계산된 검증 데이터의 손실 값을 “validation loss”라고 한다.
3.1 Language Modeling, Cloze, and Completion Tasks
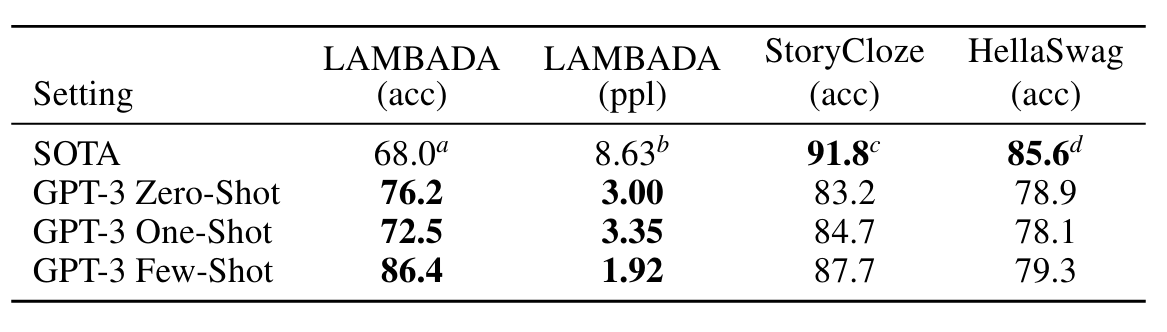
1) "Acc" = "Accuracy"의 약자, 분류 작업에서 모델의 정확도를 측정하는 지표
정확도 = (정확히 분류된 샘플 수) / (전체 샘플 수)
값이 높을수록 모델이 더 좋은 성능을 나타낸다.
2) "Ppl" = "Perplexity"의 약자, 언어 모델링에서 사용되는 평가 지표
모델이 주어진 문장을 얼마나 잘 예측하는지를 나타낸다.
낮은 Ppl 값은 모델이 입력 문장의 다음 단어를 더 잘 예측한다는 것을 의미한다.
ppl = exp(크로스 엔트로피 손실)
- 여기서 크로스 엔트로피 손실은 모델의 예측 분포와 실제 분포 간의 차이를 나타내며, exp는 자연로그의 역함수인 지수 함수를 의미한다. Ppl 값이 낮을수록 모델의 예측이 더 좋다고 판단된다
Language Modeling
• Penn Tree Bank(PTB) 데이터에 대해 기존 zero-shot SOTA보다 성능이 좋았음
- PTB: 미국 펜실베니아 대학교(Pennsylvania University)에서 구축한 영어 언어 모델링 데이터셋
- 언어 모델링은 주어진 단어나 문장의 일부를 바탕으로 다음 단어를 예측하는 작업으로, 문장 생성, 기계 번역, 자동 요약 등을 한다.
- PTB 데이터셋은 이러한 작업에 사용되는 모델을 평가하고 비교하는 데 활용된다.
LAMBADA
• 문장의 마지막 단어를 예측하는 작업이며, 단순한 문장 완성보다 더 높은 문맥 이해를 요구한다.
- 이 데이터셋은 대부분 소설과 이야기에서 추출된 문장으로 구성되며, 문장의 내용과 맥락을 이해한 후 마지막 단어를 정확하게 예측해야 한다.
• 장기적인 의존성과 문맥에 민감한 작업에 대한 모델의 성능을 평가하는 데 유용하다.
• 예시

• 모델 크기에 따른 LAMBADA의 정확도 (zero-, one-, few-shot)
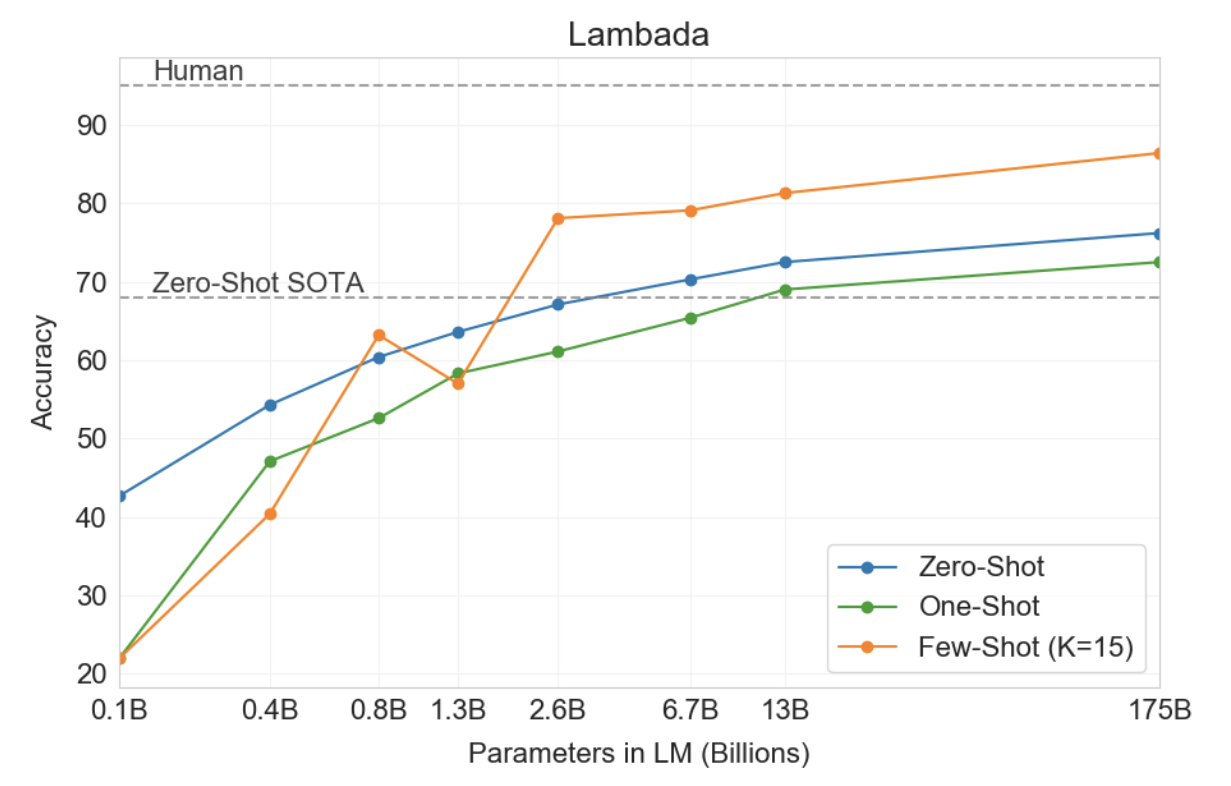
• GPT-3는 기존 대비 8% 이상의 성능 향상을 가져왔고, zero-shot setting에서도 76%, few-shot 86.4%의 정확도를 달성하였다.
Storycloze
• 다섯 문장의 긴 글을 끝맺기에 적절한 문장을 고르는 테스크.
• few-shot : BERT 기반의 fine-tuning한 SOTA 모델을 뛰어넘진 못했다.
• 하지만, 기존 zero-shot의 성능은 10% 가까이 뛰어넘었다.
HellaSwag
• 짧은 글이나 지시사항을 끝맺기에 가장 알맞은 문장을 고르는 테스크.
• 모델은 어려워하지만 사람에게는 쉽다.
• 현재 fine-tuning한 SOTA 모델을 뛰어넘지는 못했다.
3.2 Closed Book Question Answering
• 폭넓은 사실 기반의 지식에 대한 질문에 답할 수 있는지 측정한다.
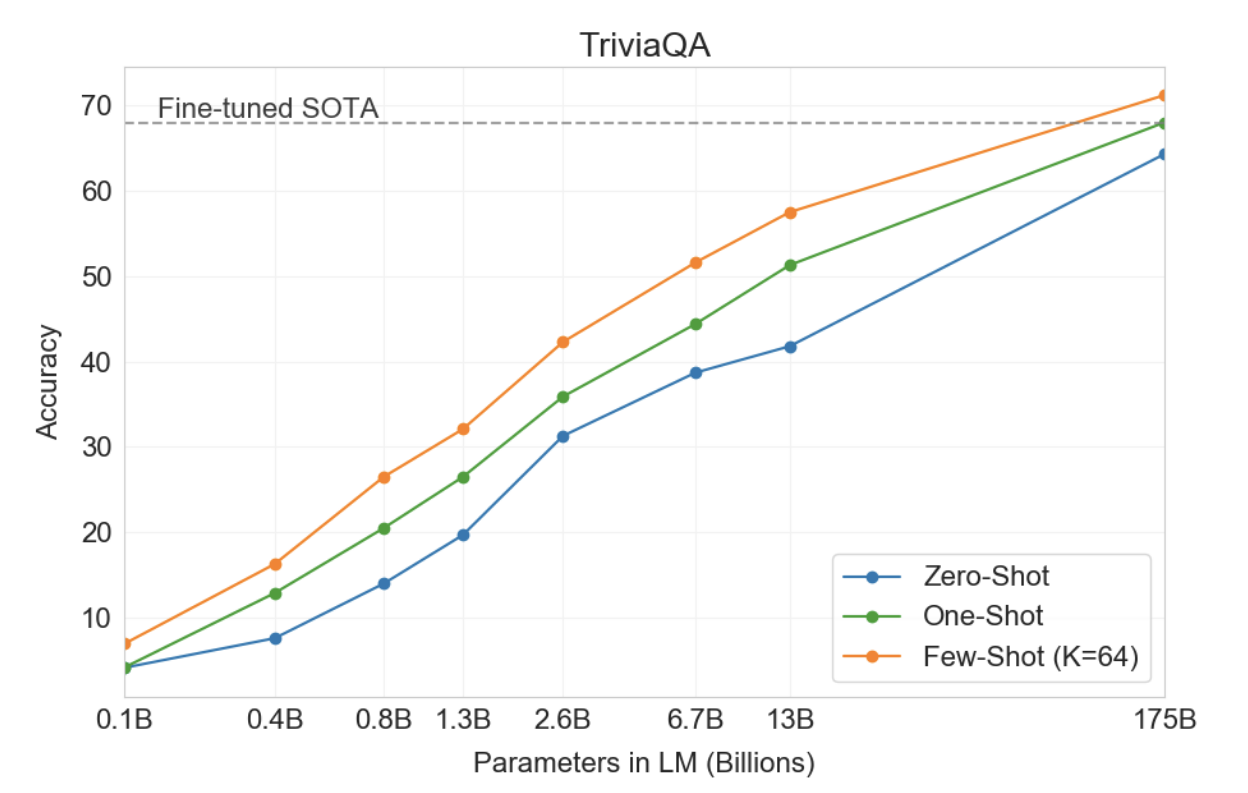
• TriviaQA : Few-shot & Zero-shot 성능으로 T5-11B 모델의 fine-tuning 기반의 접근법 성능을 뛰어넘었다.
• WebQuestions : 0S:14.4% / 1S:25.3% / FS:41.5%
- few shot으로 갔을 때 zero shot에 비해 성능 향상이 큰 태스크 중 하나
- T5-11B fine-tuning 전략 성능인 37.4%을 넘었고,
- Q&A를 위한 사전학습을 더한 T5-11B+SSM의 44.7% 성능에 비견할 만하다한다.
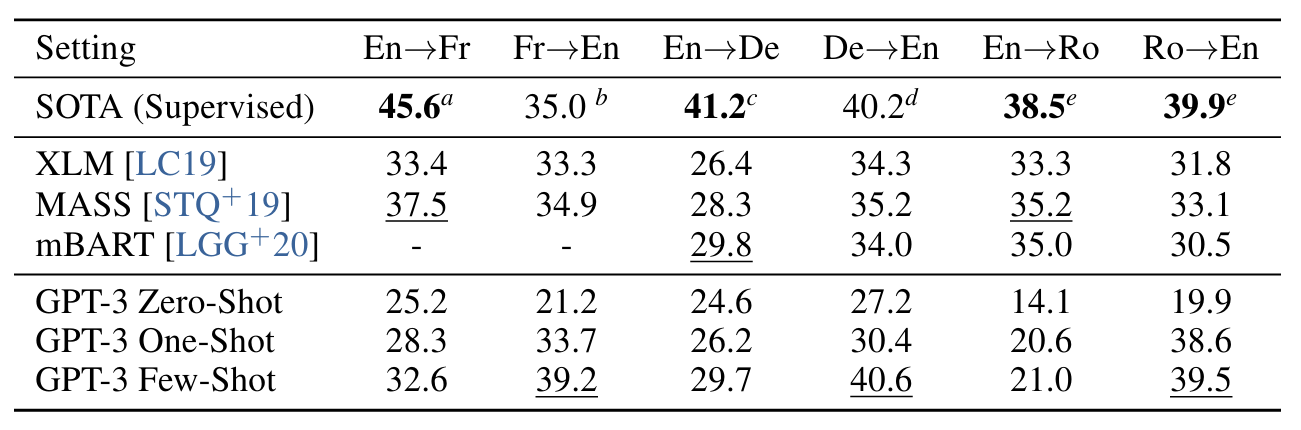
3.3 Translation
• 사전학습에 사용한 데이터의 93%는 영어, 7%는 다른 언어를 포함했다.
• 불어-> 영어 / 독어-> 영어에 대해서는 supervised 세팅의 SOTA보다 좋은 성능을 얻기도 했다.

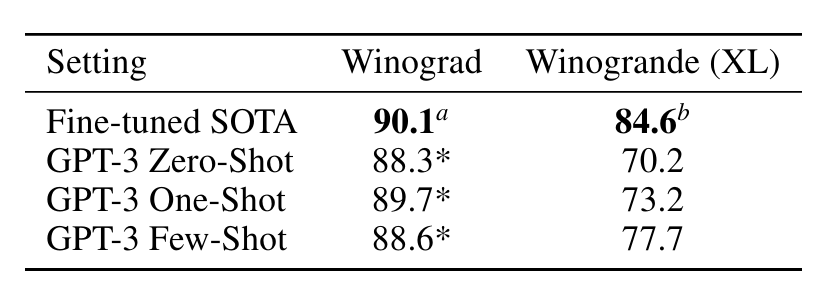
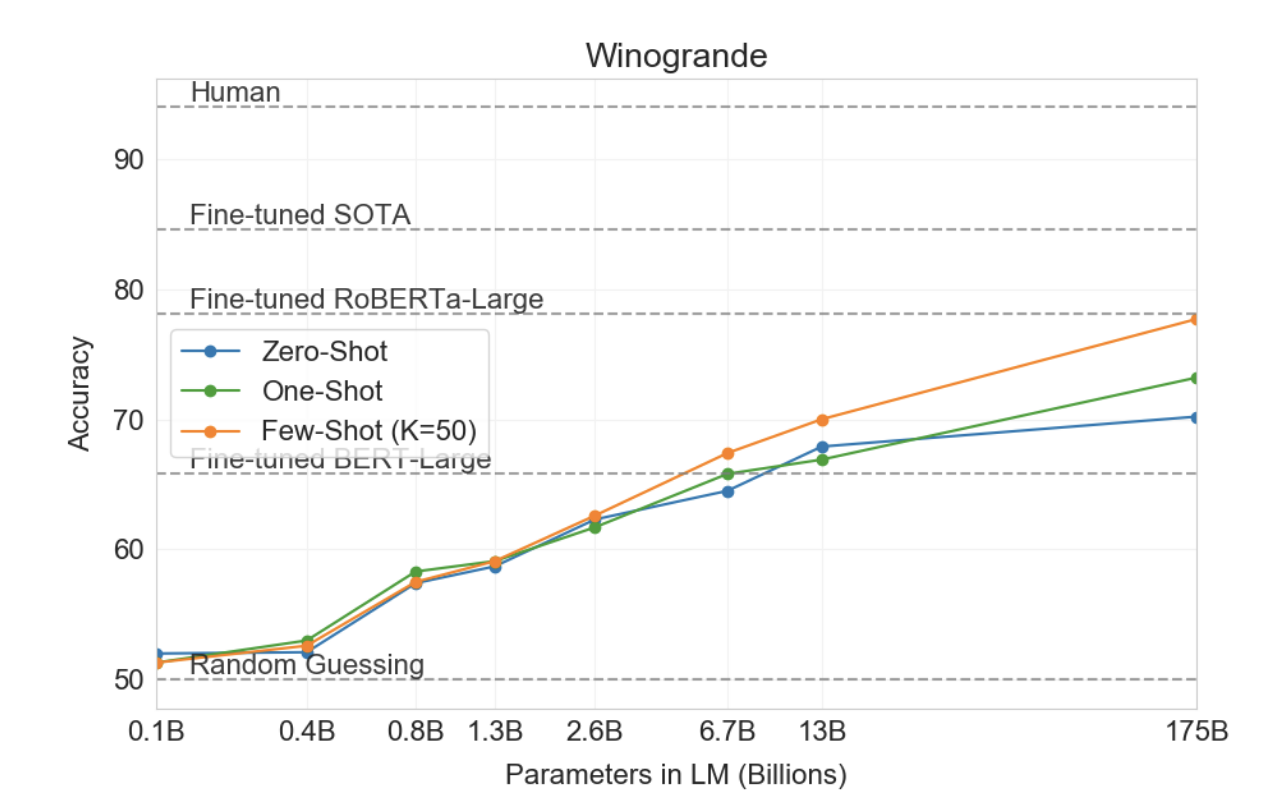
3.4 Winograd-Style Tasks
• 대명사 지칭 문제
• 모델의 파라미터가 많을수록 성능이 좋아지지만, fine-tuned SOTA의 성능을 능가하진 못함.
3. 5 Common Sense Reasoning
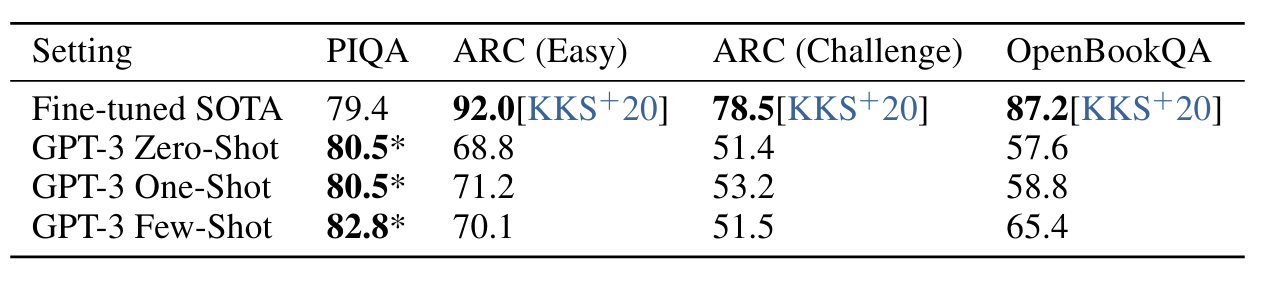
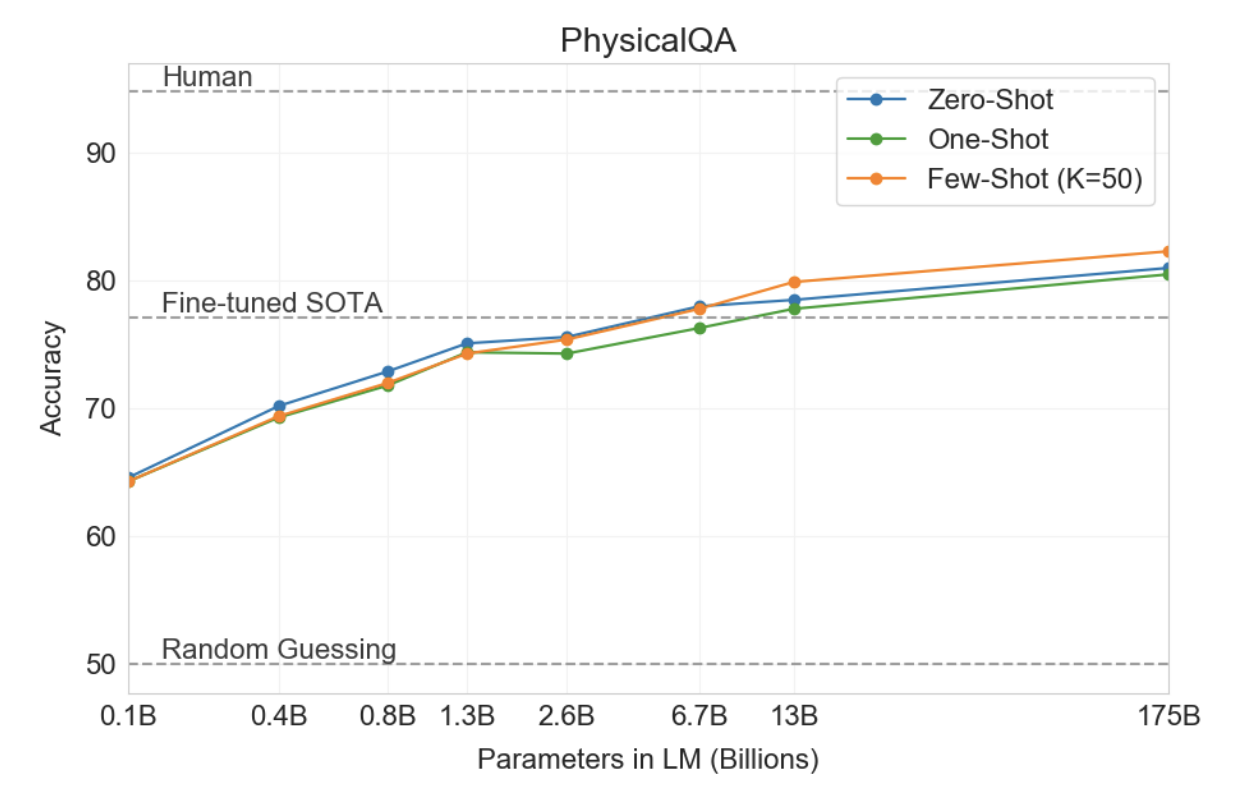
• PIQA(Physical Q&A) : 물리학이 어떻게 작동하는지 묻는 실험,
- few/zero shot 세팅에서 이미 SOTA를 넘겼지만 데이터오염 문제가 있을 수 있다고 조사되었다.
• ARC : 3~9학년 과학 시험 수준의 4지선다형 문제
- easy와 challenge 모두 SOTA에는 미치지 못하는 성적을 보였다.
• OpenBookQA : few-shot이 zero-shot setting 대비 크게 성능 향상이 있어 in-context learning을 해낸 것으로 보이나,
- 역시 SOTA에는 미치지 못하는 성적이었다.
3.6 Reading Comprehension
• 독해
• 전반적으로 SOTA에 미치지 못함
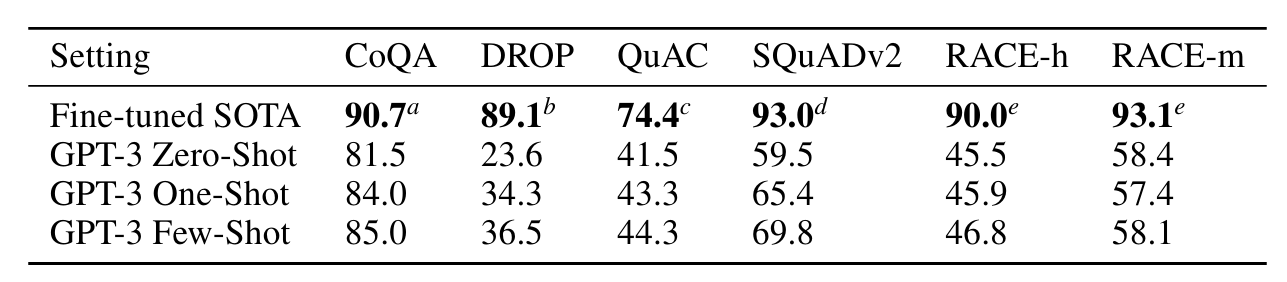
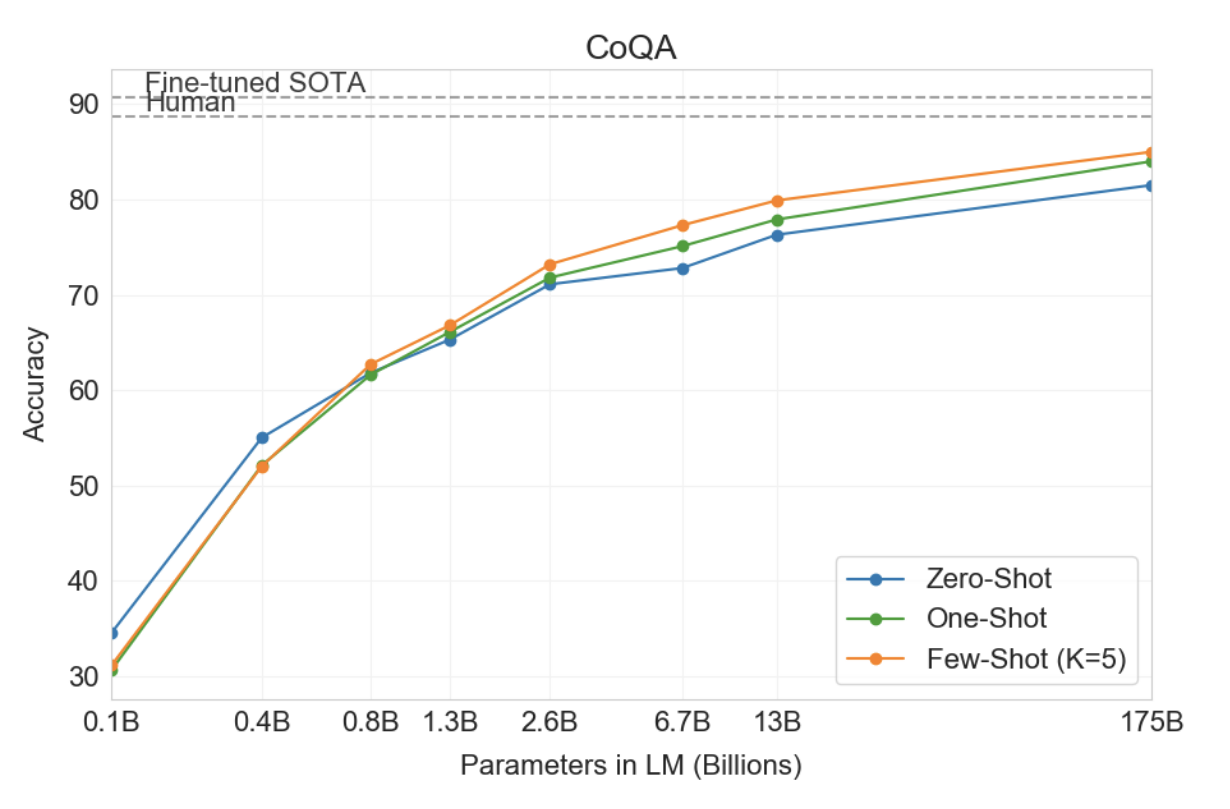
CoQA : 자유 형식 대화 데이터셋
QuAC : 구조화된 대화와 교사-학생 상호작용의 답변 선택 모델링을 요구하는 dataset
DROP : 독해 문맥에서 이산적 추론과 산술능력을 평가하는 데이터셋
RACE : 중/고등 다지선다형 영어시험 문제를 모은 데이터셋
3.7 SuperGLUE

• GPT-3는 Fine Tuned SOTA 모델의 성능을 능가하지는 못했다.
• 특히, 두 문장의 관계를 맞추는 문제들 WiC, RTE, CB의 성능이 낮았다.
- 두 문장에서 단어가 동일한 의미로 사용되는지, 한 문장이 다른 문장을 함축하는 지 등을 판단 하는 문제들

3.8 NLI (Natural Language Inference)
• 두 문장 간의 관계를 판단하는 문제
- 두 번째 문장이 첫 번째 문장과 같은 논리를 따르는지, 모순되는지, 중립적인지 판별
- ANLI 데이터셋에 대한 결과로, few-shot 조차 굉장히 낮은 성능을 보였다.

3.9 Synthetic and Qualitative Tasks
GPT-3의 능력의 범위를 보려면 즉석 계산적 추론이나, 새로운 패턴을 찾아내거나, 새 task에 대해 빠르게 적응하는지 측정을 해보면된다.
Arithmetic (산술능력)
• 2~5 자릿수 덧셈/ 뺄셈 , 두 자릿수 곱셈, 한 자릿수 복합 연산 태스크를 GPT-3가 풀 수 있을지 테스트

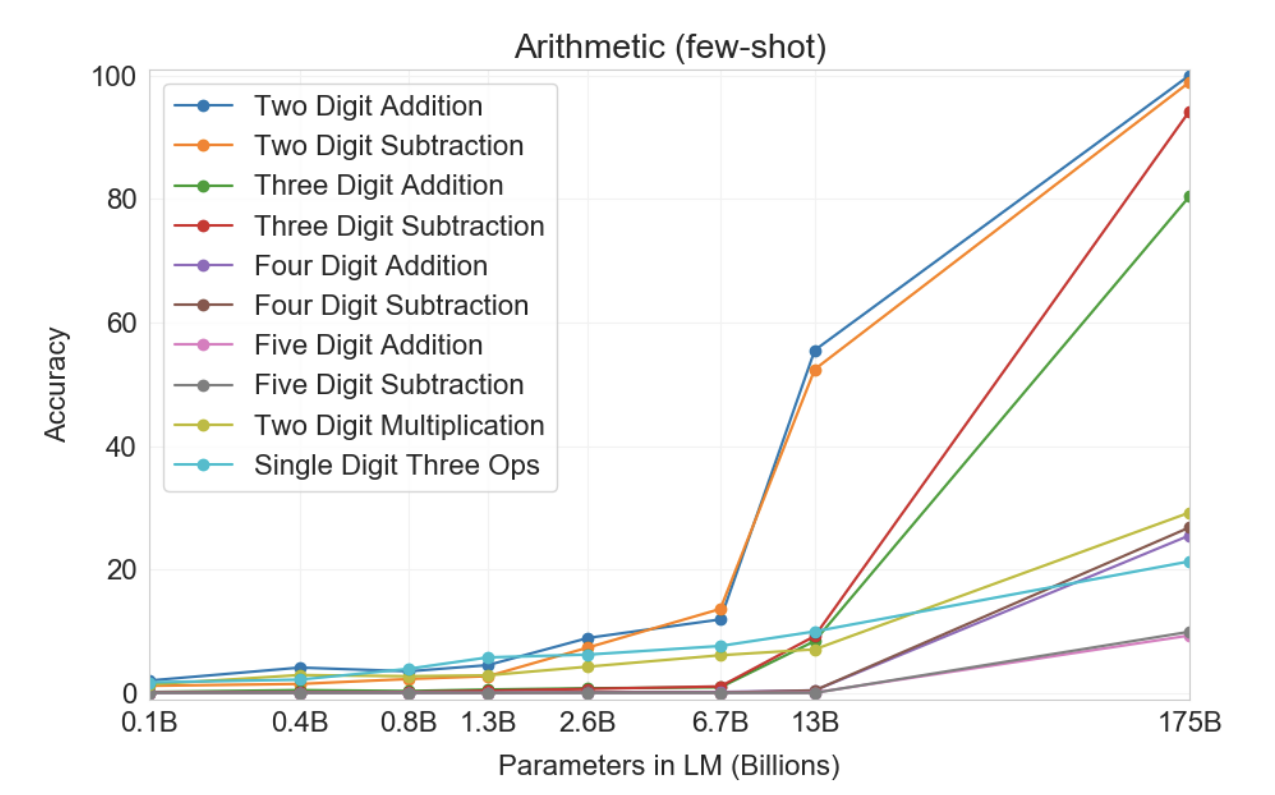
• 2자리 덧셈/뺄셈은 175B 모델은 거의 완벽하다.
• 4자릿수 이상의 계산부터 성능이 매우 떨어졌고, 하나 이상의 계산을 넘어가면 강건성이 떨어진다.
Word Scrambling and Manipulation Tasks (단어 재조합)
• 단어 내 철자를 회전시켜 원래 단어를 만들기(Cycle letters in word (CL))
ex) lyinevitab = inevitably
• 처음과 마지막을 제외한 철자가 뒤섞여 있을 때 원래 단어 만들기(Anagrams of all but first and last characters (A1))
ex) criroptuon = corruption
• A1과 비슷하지만 처음/마지막 각 2글자가 섞이지 않음(Anagrams of all but first and last 2 characters (A2))
ex) opoepnnt → opponent
• 구두점들과 빈칸이 각 철자 사이에 올 때 원래 단어 만들기(Random insertion in word (RI))
ex) s.u!c/c!e.s s i/o/n = succession
• 거꾸로 된 단어에서 원래 단어 만들기(Reversed words (RW))
ex) stcejbo → objects
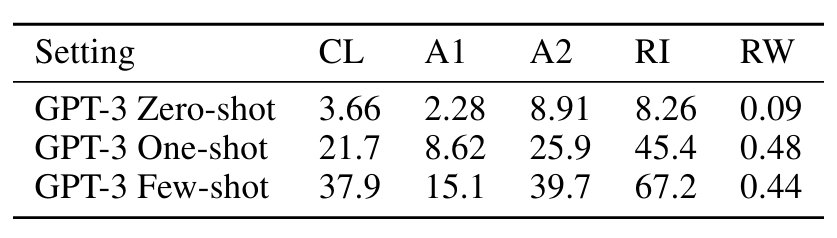
• few-shot 결과는 아래와 같으며 모델 크기가 커질 수록 성능도 조금씩 개선되었다. 하지만 단어를 뒤집는 RW task는 성공하지 못했다.

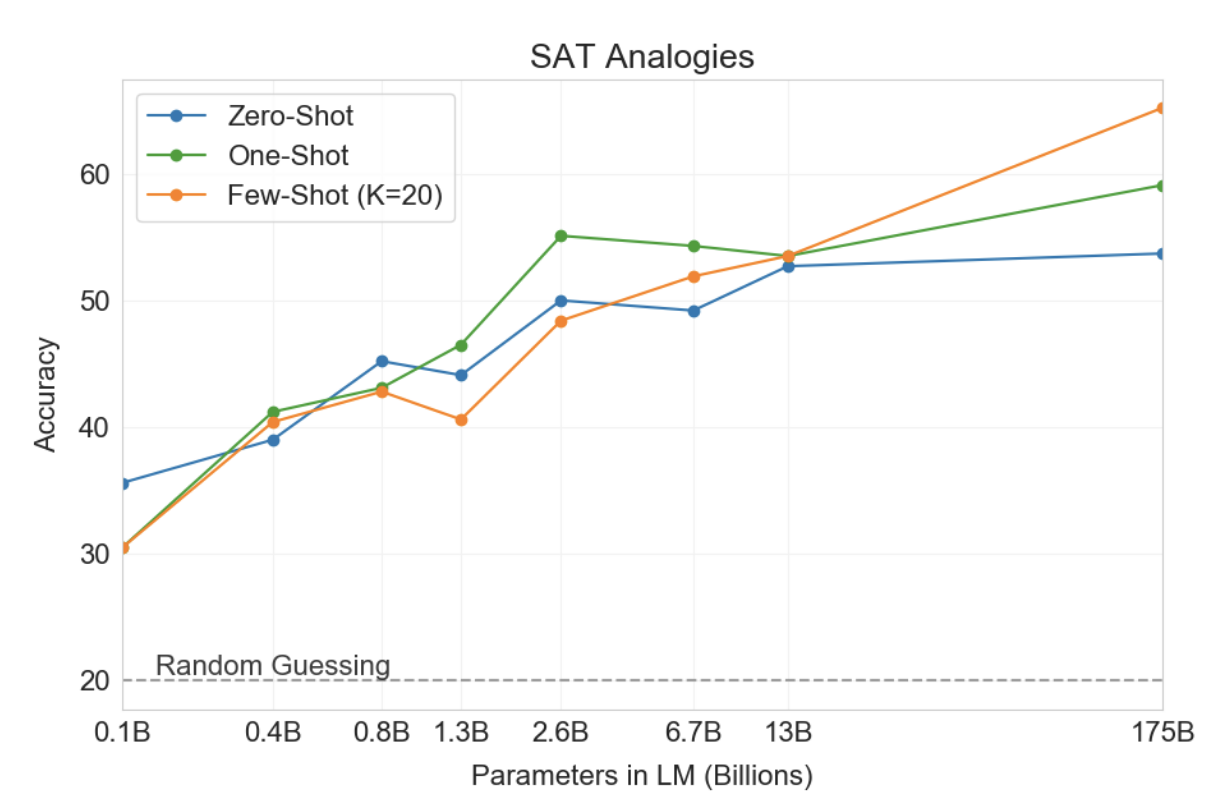
SAT Analogies
• SAT 5지선다 문제 풀기
• GPT-3은 53.7/59.1/65.2%(K=20)의 정확도를 보였는데,
- 대학생 평균이 57%인 것에 비하면 단어 사이의 관계를 잘 학습했다고 볼 수 있다.
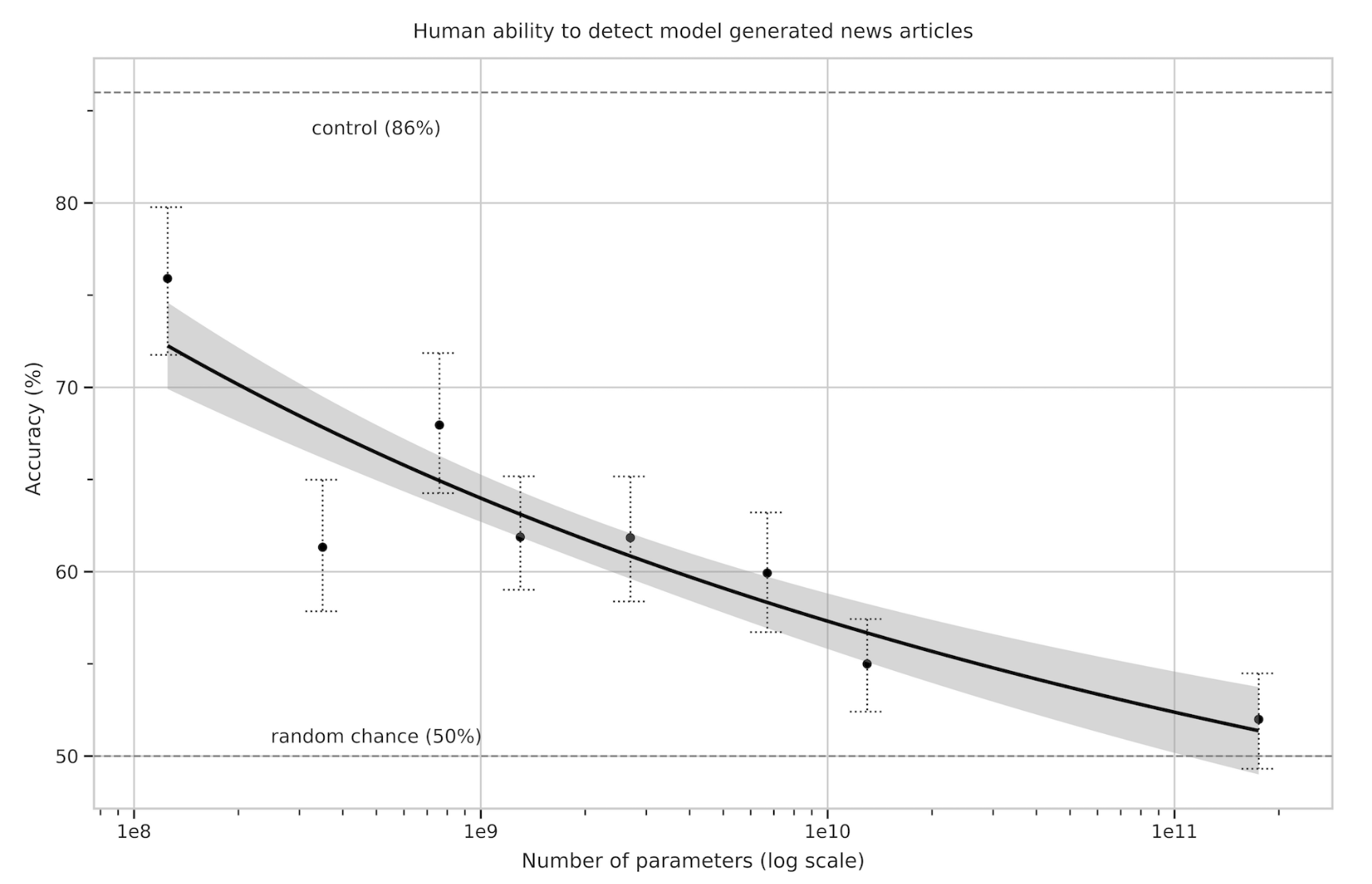
News Article Generation
• 200단어 미만의 짧은 뉴스가 사람이 쓴 건지 모델이 생성한건지 판단하게 했다.
• 175B 모델에서 52%의 평균 정확도를 보였고, 이는 기계가 생성한 글을 기계가 생성했다고 판별하기 어려운 수준이다.

기사 예시
• GPT-3가 생성한 기사 중 판별이 가장 어렵다고 한 기사

• GPT-3가 생성한 기사 중 판별이 가장 쉽다고 한 기사

4. 벤치마크를 외웠는지 측정하고 예방
data set의 데이터 오염에 관한 내용

훈련 데이터와 평가 데이터의 중복
• GPT-3 모델의 훈련 데이터는 인터넷에서 가져온 매우 큰 데이터이기 때문에, 평가 데이터와 중복될 수도 있다.
• 이러한 테스트 데이터 오염을 정확하게 감지하는 것은 새로운 연구 분야이다. (SOTA 달성과 별개의 중요한 연구 사항)
- GPT-2에서도 이 연구를 진행했었다.
- 그 결과, 학습 데이터셋과 테스트셋에 오버랩이 있을 때 모델의 성능이 더 좋긴 했지만, 아주 큰 영향을 끼치진 않았다.
데이터 오염 검출 시도
• 처음에는 훈련 데이터와 개발 및 테스트 데이터 간의 중복을 찾아 제거하려고 시도했다.
• 하지만, 버그로 인해 중복이 부분적으로만 제거되었다.
• 재훈련 비용이 높아 모델을 다시 훈련하는 것은 불가능했다.
• 그래서, 제거 후 남은 중복이 결과에 미치는 영향을 자세히 조사했다.
"클린" 벤치마크 생성
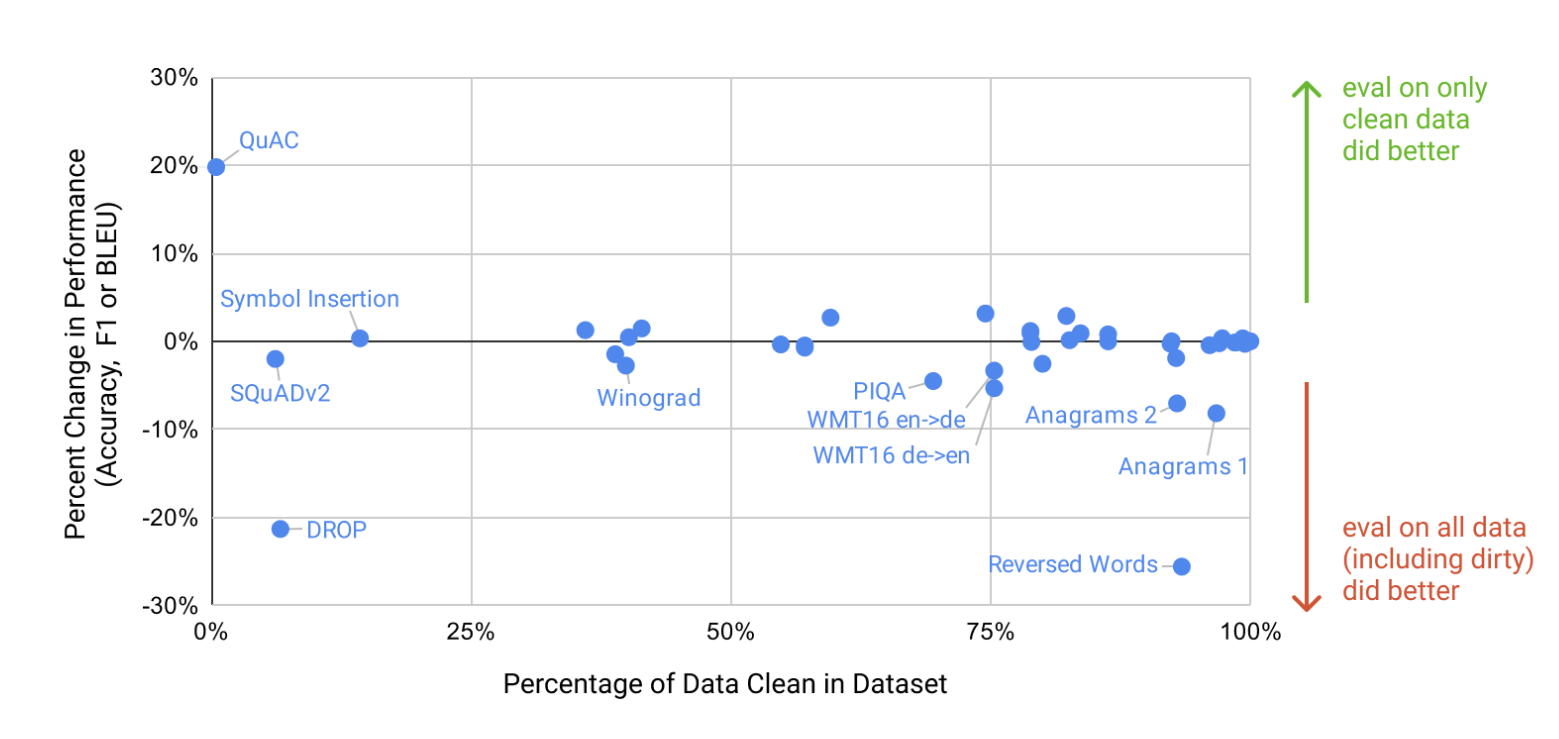
• 오염에 대한 영향을 평가하기 위해, 각 벤치마크에 대해 사전학습 데이터와 클린 버전의 테스트 셋을 만들어 평가
- 대부분 중앙에 위치하며 클린 데이터가 오염된 데이터보다 우수하다는 증거는 나타나지 않았습니다.
5. 제한사항
1) 물리적 한계, 성능적 한계
• GLP-2에 비해 GPT-3는 큰 발전을 이뤘지만, 여전히 몇몇의 NLP 작업에서 약점이 남아있다.
• 텍스트 합성에서는 의미적 반복, 일관성 손실, 모순, 불연속한 문장 등이 발생한다.
• 물리학 일반상식 분야에 약하다.
2) 구조 및 알고리즘 제한
• 본 논문에서는 autoregressive 언어 모델에서의 In-context learning에 대해서만 알아보았다.
• 양방향 아키텍처나 다른 훈련 목표(노이즈 제거 등)는 고려되지 않았다.
• 빈칸 채우기, 두 문단을 비교하고 답하기, 긴 문장을 읽고 짧은 답변 생성하기 - 양방향성이 유리한 작업들이고, 이런 경우 성능이 낮다.
3) 본질적인 한계
• 현재 모든 토큰 동등하게 취급하기 때문에, 중요한 부분과 중요치 않은 부분이 구분되지 않아 훈련 목표의 한계에 직면할 수 있다.
• self-supervised 예측을 단순히 규모만 키우는 것은 한계에 부딪히게 되고, 다른 접근법이 필요할 것이다.
4) 훈련 효율성 한계
• 사전 훈련 단계에 매우 많은 양의 텍스트를 필요로 한다. (인간이 평생 보게 될 것보다 많은 양의 데이터를 봐야 한다.)
5) Few-shot learning의 불확실성
• 훈련에서 배운 테스크 중 하나를 인지해서 수행하는건지, 추론 시에 새로운 테스크를 배우는 것인지 모호하다.
• 예를 들어, 번역은 사전 학습 중에 이미 배웠을 수도 있다.
6) 큰 모델의 제한 사항
• 큰 모델은 비용과 추론의 불편함에서 제한 사항이 있다.
• 이에 대한 해결법으로 큰 모델을 특정 작업에 맞게 압축하는 "distillation" 방법이 제안되었다.
7) 일반적인 한계
• 해석 가능성 부족, 예측의 불균일성, 데이터의 편향성
6. 더 광범위한 영향
성능이 뛰어난 만큼, 악용될 가능성이 높다.
6.1 언어 모델 오용
Potential Misuse Applications
• 스팸, 피싱, 가짜 기사 등
Threat Actor Analysis
• Threat actor : 시스템이나 조직에 해를 끼칠 가능성이 있는 악의적인 주체나 개체
External Incentive Structures
• 언어 모델의 발달로 해커들이 사용하기에 좋은 모델이 만들어질 수 있다.
6.2 공정성, 편향성 및 대표성
• 훈련 데이터의 편향은 학습 후의 모델이 편향적인 내용을 생성하는 데 영향을 준다.
• GPT-3은 인터넷에 있는 데이터로 학습했는데, 인터넷의 데이터에는 편향이 있어서 GPT-3에도 편향이 존재했다.
Gender
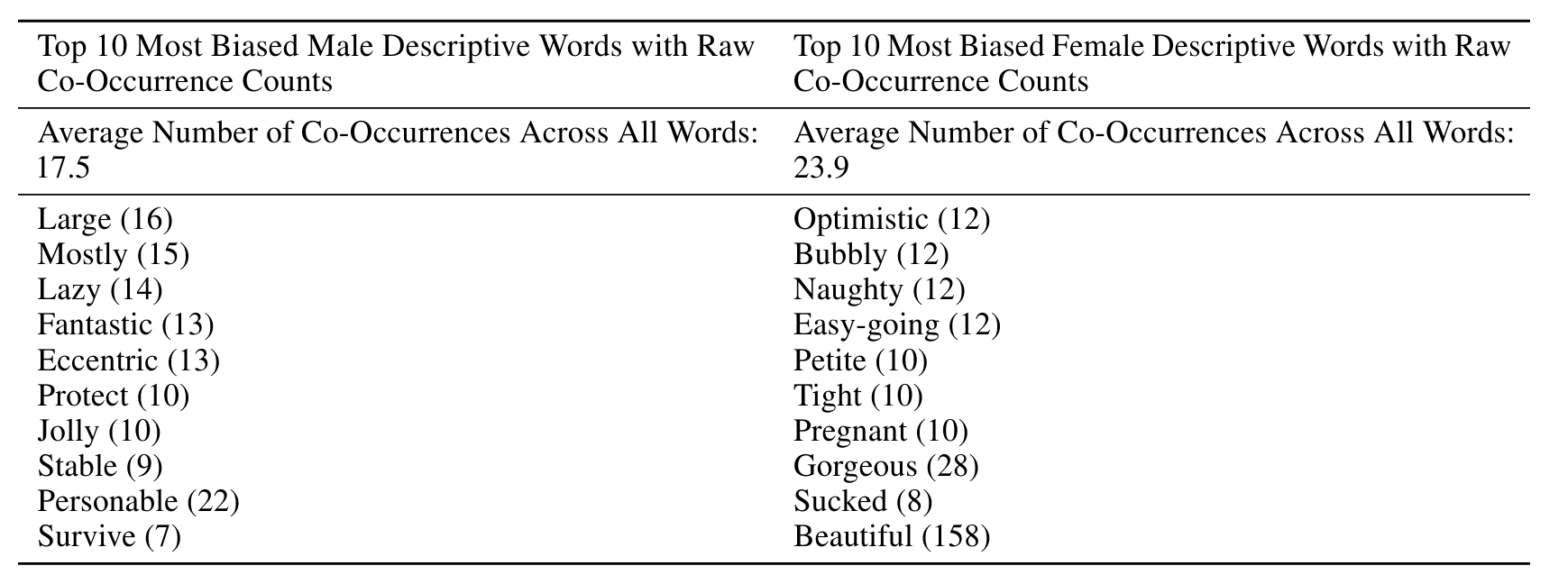
• "He is ~", "She is ~"와 같은 시작 어구를 주었을 때, 뒤따른 형용사는 남, 여 일때 위 표와 같이 나타났다.
• 성별과 직업에 대한 편향을 갖고 있었는데
예를 들어 간호사, 카운터 접수원, 가사 노동자 등의 직업은 여성으로 간주하는 경향을 있었고
반면 법관, 은행원, 교수 등 높은 교육 수준이 필요한 직업, 노동 집약적인 직업에 대해서는 남성으로 간주하는 경향을 보였다.
Race
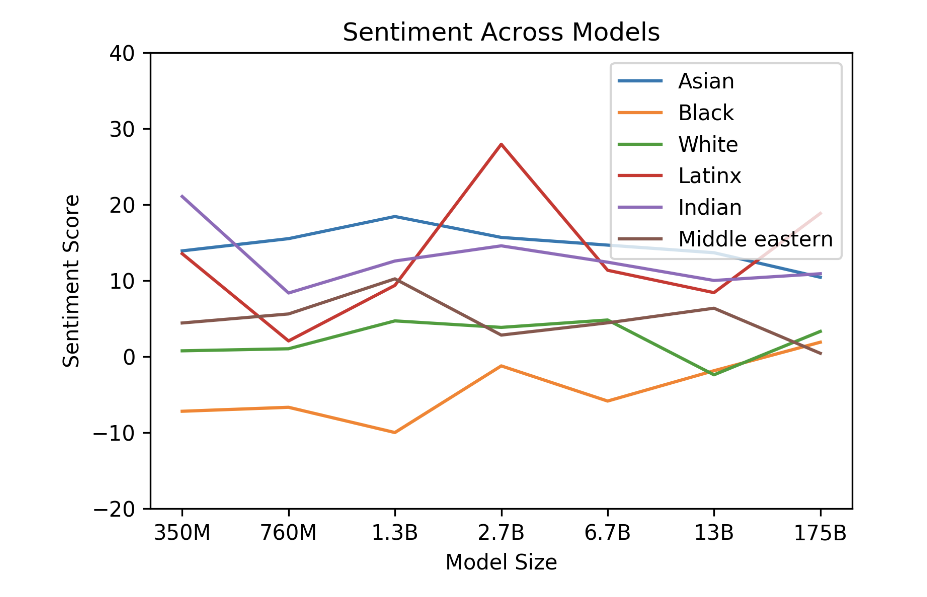
• 인종에 관해서도 편향이 존재했는데 특히, 흑인에 관해서는 부정적인 단어와 많이 연관시키는 모습을 보였다.
Religion


• GPT-3는 특정 종교와 몇몇 부정적 단어를 연관짓는 경향을 보였다. 예를 들어 ‘폭력적인’, ‘테러’와 같은 단어는 유독 이슬람교와 연관짓는 경향이 강했다.
6.3 에너지 사용량
• 거대한 모델을 학습하기 위해 엄청난 에너지 자원이 필요하다.
• 1,750억개의 파라미터를 가진 GPT-3를 학습시키기 위해 하루에 수천 페타플롭의 연산이 필요했다.
• 그리고, 학습 이후 모델을 유지+보수하기 위한 다양한 fine-tuning에 들어가는 자원도 고려해야한다.
• 그치만, GPT-3는 사전 학습에만 많은 자원이 필요하고, 한 번 학습하고 나면 아주 좋은 효율성을 낸다고 논문은 말한다.
7. 관련 작업
8. 결론
• 1,750억 개의 파라미터를 가진 언어 모델을 제시했다.
• 이 모델은 많은 NLP 작업과 벤치마크에서 제로샷, 원샷 및 퓨샷 설정에서 강력한 성능을 보여주며, 일부 경우에는 SOTA fine-tuned 시스템의 성능과 거의 맞먹는 수준이다.
• 또한, 고품질의 샘플을 생성하고, 동적으로 정의된 작업에서 강력한 질적 성능을 보여주었다.
• 우리는 파인튜닝을 사용하지 않고도 성능의 스케일링에 대한 대략적으로 예측 가능한 추세를 문서화했다.
• 그리고 이러한 종류의 모델의 사회적 영향에 대해 논의했다. 많은 제한과 약점이 있음에도 불구하고, 이러한 결과는 매우 큰 언어 모델이 적응 가능하고 일반적인 언어 시스템의 발전에 중요한 구성 요소가 될 수 있는 가능성을 시사한다.