RoBERTa 논문 리뷰
1.1 소개 : 배경과 기여점
• 배경
- Self-training method의 어떤 측면이 좋은 성능을 내는지 특정하기 어려움
- 비공개 데이터에서 학습될 경우, 모델링을 통해 개선된 성능이 얼마인지 측정하기 어려움
- 학습 비용이 높기 때문에 실제로 해볼 수 있는 튜닝 횟수는 제한적
• 기여점
- Bert 모델이 downstream task에서 더 나은 성능을 이끌어내는 pre-training 전략 제시
- 새로운 대용량 데이터셋 구축, 더 많은 데이터가 성능을 향상 시킴을 보임
- 적절한 파라미터 튜닝과 학습 전략 만으로도 최신 모델과 비등한 성능을 낼 수 있음을 보임
1.2 서론 : 요약
• A Robustly Optimized BERT Pretraining Approach
- BERT모델은 under-trained 되었으므로, 구조는 그대로 두고 downstream task에서 더 나은 성능을 이끌어 낼 파라미터 설정 & pretrainig 전략 제시
• BERT 모델에 대한 심플한 수정사항
- 더 많은 데이터로, 더 긴 시간, 더 큰 batch size로 학습
- Next Sentence Prediction(NSP) 제거
- 일정하게 긴 input sequence로 학습
- 동적 마스킹으로 변경
2.1 Input : 최대길이 → 고정된 길이
• 2개의 segment X, Y를 연결, [SEP] 토큰으로 구분한 input을 받음
- N, M : segment X, Y의 길이(토큰 개수)
- T : 학습 데이터에서 input sequence 최대 길이
[CLS], x1, x2, ....., xN, [SEP], y1, y2,....., yM, [EOS]
N + M < T, T = 512
• BERT는 학습 속도 개선을 위해 초반 90% steps길이 128로 제한
• RoBERTa는 일정하게 T로 맞춤
2.2 Achitecture : BERTLARGE 그대로
• Transformer layer size L
• Self-attention head A
• Hidden dimension H
| Model | L | H | A |
| BEARBASE | 12 | 768 | 12 |
| BEARLARGE | 24 | 1024 | 16 |
2.3 Training objectives
• Masked Language Model(MLM) : Static → Dynamic
- 목표 : 마스킹 된 토큰이 무엇인지 예측
- Static masking
- BERT는 input sequence 토큰의 15%를 pre-processing 단계에서 선택
- 선택된 토큰 중 80% special token[MASK]로 교체, 10% 그대로, 10% random token으로 교체
- 한 번 선택된 마스킹 구성으로 pre-trainig 내내 학습되지 않도록, 데이터를 복제해서 다르게 마스킹
- 더 자주 마스킹을 다르게 해주면 유리하지 않을까?
• Next Sentenxe Prediction(NSP) : 삭제
- 목표 : input으로 받은 2개 segment X, Y가 연속된 문장인지 여부 판단
- IsNext : 한 코퍼스에서 연속된 두 문장 추출해 쌍을 만듦
- NotNext : 두 번째 문장은 다른 문서에서 추출해 쌍을 만듦
- 두 문장 관계를 이해한 모델이 Question Answering(QA), Natural Language Inference(NLI) task에서 더 나은 성능을 보였음
- 충분히 잘 학습된 BERT 모델은 여전히 NSP를 필요로 할까?
2.4 Optimization
| 비교항목 | BERT | RoBERTa |
| Mini batch size | 256 | 8K |
| Update | 1,000,000 | 500K |
| Adam | β1 = 0.9 β2 = 0.999 ∈ = 1e-6 |
학습이 Adam epsilon에 민간 β2 = 0.98 batch size 클때도 안정적으로 학습 |
| Learning rate | Warm up 10,000 steps Peak value : 1e-4, 선형 감소 |
Warm up 30K steps Peak value : 4e-4, 선형 감소 |
| Dropout | 0.1 for all layers | |
| Activation function | GELU | |
2.5 Pre-train data : 기존 포함 10배 확장
• Pre-training data가 많으면 end-task 성능 개선에 도움을 줄 수 있음(Baevski ei al. 2019)
• RoBERTa는 더 많고, 더 다양한 도메인으로 학습 데이터 구축
| BERT(16GB) | RoBERTa(160GB) |
| • BOOKCORPUS + English WIKIPEDIA, 16GB |
• BOOKCORPUS + English WIKIPEDIA, 16GB • CC-NEWS(from CommonCrawl), 76GB 2016.9 ~ 2019.2 630만개 영문 뉴스 기사 • OPEN WEB TEXT, 38GB Reddit에서 좋아요 3개 이상 받은 웹 콘텐츠 • STORIES(from CommanCrawl), 31GB Winograd schemas 형식의 데이터 |
3. Evaluation
• GLUE : General Language Understanding Evaluation benchmark
- 자연어 이해 성능 평가를 위한 9가지 데이터셋 조합
• SQuAD V1.1, V2.0 : Stanford Question Answering Dataset
- 지문과 질문쌍이 주어지고, 질문에 답하는 문제
- V1.1 : 지문이 항상 답을 포함하고 있음
- V2.0 : 주어진 지문 내에 답이 없을 수 있음
- 질문에 대한 답이 가능한지 여부(이진분류)를 동시에 학습
- 답이 가능할 때만 지문 내에 위치한 정답을 학습
• RACE : ReAding Comprehension from Examinations
- 중국 중고등 학생의 4지선다형 영어 시험
- 28,000개 지문과 100,000개의 문제로 구성
- 다른 데이터셋들보다 지문이 길고, 추론을 요하는 질문의 비중이 높음
4.1 Training procedure Analysis
• Static vs Dynamic Masking
- Static
- 기존의 BERT는 마스킹 할때 한 번만 랜덤하게 마스크를 적용하고 모든 epoch에서 pre-training 단계에서 동일한 마스크가 반복적으로 사용
- Dynamic
- 이를 피하고자 train set을 10배로 늘려 10개의 다른 마스크가 적용되도록 했고 똑같은 방식으로 40 epochs, 즉 하나의 방법으로 4 epoch씩 진행
• Metrix : 기존 BERT와 큰 차이가 없거나 몇몇 task에서 조금 높은 성능을 보임

4.2.1 Input format & NSP(Next Sentence Prediction)
• 최근 연구에서 NSP loss에 대한 의문이 제기됨
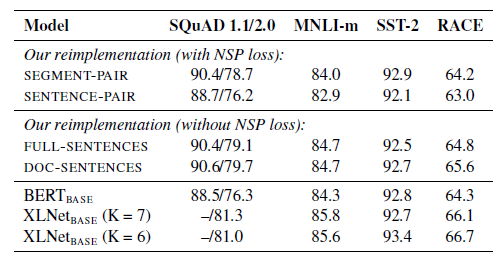
• RoBERTa를 구현할 때 4가지의 다른 방식으로 테스트를 진행
• With NSP loss
1) SEGMENT-PAIR+NSP : 기존 BERT와 동일, 각각의 segment는 다수의 문장들을 포함하고 512 token 이하로 이루어짐
2) SENTENCE-PAIR+NSP : 하나의 문서에서 쪼개진 인접한 문장으로 구성, 512 token 보다 작은 사이즈로 구성되나, batch size 키워 segment와 비슷한 크기 유지
• Without NSP loss
1) FULL-SENTENCES : 경계를 넘을 경우 문단이 끝이 나면 다음 문단도 계속하여 탐색, 512 token 이하의 연속된 전체 문장으로 구성, 다른 문서 사이에 구분 토큰 추가
2) DOC-SENTENCES : FULL-SENTENCES와 유사하나 다른 문서의 경계를 넘지 않음, 512 token 보다 작은 사이즈로 구성되나, batch size 키워 FULL-SENTENCES 와 비슷한 크기 유지
4.2.2 Input format & NSP 실험 결과
• Sentence-pair를 사용하는 경우 downstream task에서 성능이 안 좋아짐 : 모델이 long range 의존성을 학습할 수 없기 때문에
• 기존 BERT에서 NSP는 매우 중요했지만, NSP loss를 제거하고 문장 길이를 채워서 input으로 넣는 것만으로도 NSP보다 더 높은 성능을 보임
• NSP를 제거한 경우 doc sentences가 full sentences보다 성능을 더 좋지만 batch-size를 다양하게 조절해야 하기 때문에 다른 모델과의 비교를 위해 full sentence를 사용
4.3 Training with Large Batches
• Mini-batch 사이즈를 크게 함으로 Perplexity와 END-task Accuracy 향상
• 배치 크기를 2K로 하였을 때 가능 좋은 성능을 보임
- 8K 배치 사이즈 사용
- Distribution → parallel 학습의 용이성으로 인해 8K 사용

4.4 Text Encoding
• BERT는 3만 단어(30K)로 vocabulary 구성
• RoBERTa는 50K 정도로 구성
- 실제 모델 파라미터 수도 이정도로 삽입
- BPE를 사용함으로써 더 많은 subword vocab을 이용할 수 있도록 함
5. RoBERTa
• Dynamic Masking
• Full sentences w.o NSP loss : Only MLM Task
• Large mini-batches : BERT의 약 32배의 batch size
• A larger byte-level BPE
++ 이전 연구에서 강조되지 않은 두가지 중요 요소 조사
• Pretraining 에 사용한 데이터 : BERT(16GB) → RoBERTa(160GB)
• Data로 훈련하는 횟수

더 많은 데이터로 더 많이 학습할수록 좋은 결과를 보여줌
5.1 GLUE Results
• Setting 1 : Single-task, dev
- 해당 작업에 대한 훈련 데이터만 사용하여 각 GLUE 작업에 대해 별도로 RoBERTa를 미세 조정
• Setting 2 : Ensembles, test
- Single-task fine tuning → Ensemble
- RTE, STS, MRPC에서는 MNLI 모델은 base로 fine tuning
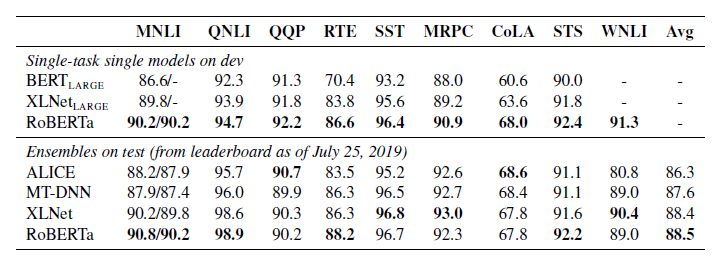
Single-task, dev : 모두 SOTA
Ensembles, test : 9개 중 4개 Task SOTA
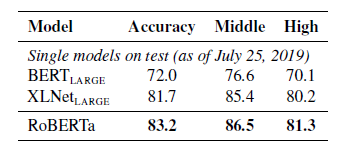
5.2-3 SQuAD / RACE Results
• SQuAD Results

• RACE Results
7. Conclusion
• BERT를 사전 학습할때 고려할 수 있는 여러 Design decision에 대하여 평가한 논문
• 모델의 성능을 향상시키는 방법으로
- 모델을 더 오래, 더 많은 데이터에 대해서, 더 큰 배치로 학습
- NSP objectives 제거
- 더 긴 sentence 학습
- Dynamic Masking 적용