Sequence to Sequence 논문 리뷰
개요
본 논문에서는 인코더, 디코더 사용
LSTM을 사용 멀티 4 Layers 쌓아서 구현
영어를 불어로 번역
사용된 데이터셋 : WMT’14
BLEU : 기계번역 성능지표
LSTM을 사용하면 긴 문장도 높은성능으로 잘 번역 : 34.8%(BLEU)
통계적기계번역 시스템 : 33.3%
통계적기계번역 시스템 + 딥러닝 자연어처리기법(LSTM) : 36.5%
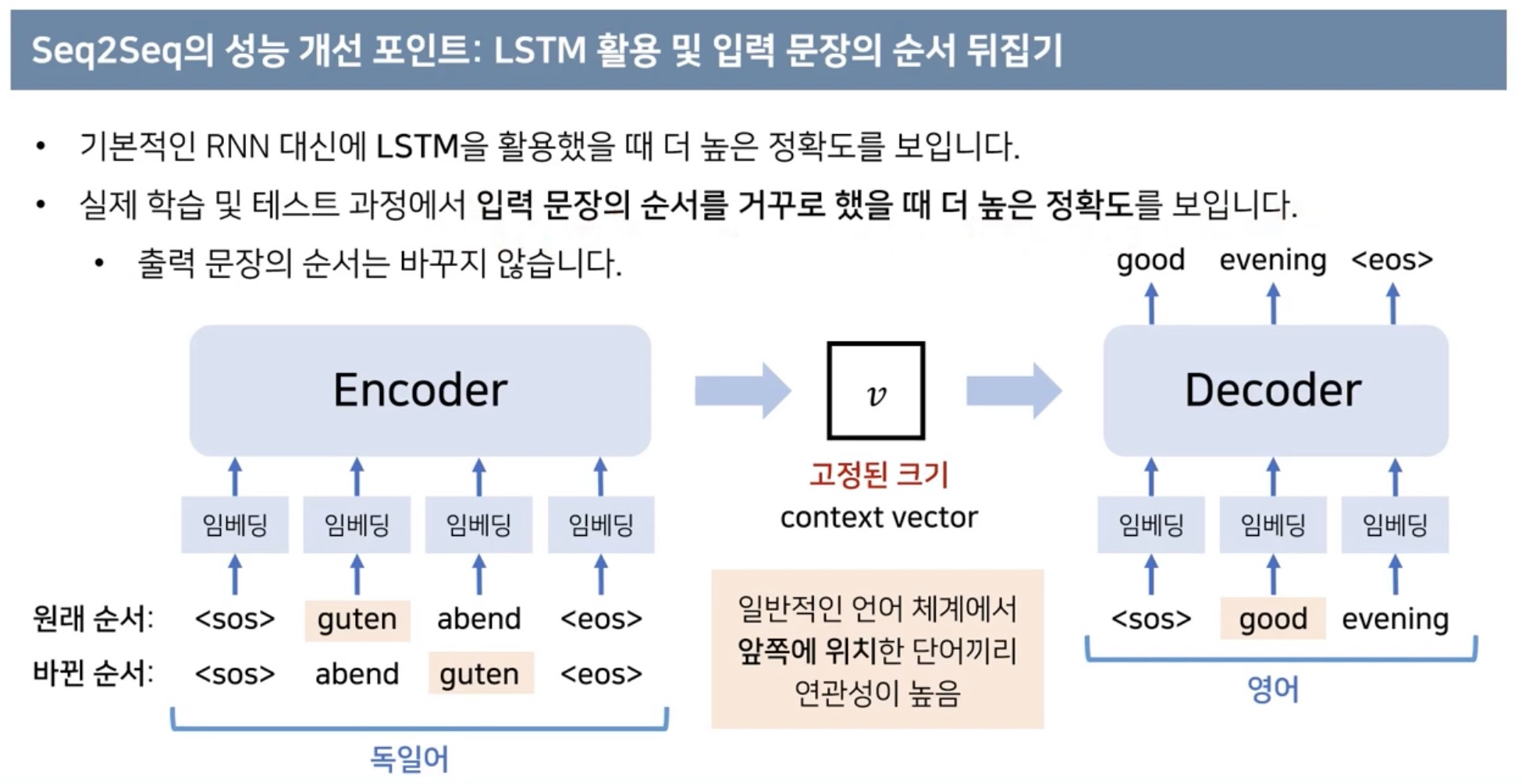
LSTM 입력문장의 순서를 바꾸는 것이 학습 난이도를 낮춰 성능이 높아졌다.
1. 서론
DNN 복잡한 함수 학습하는 것에서 성능이 좋다.
경사하강법을 사용 하면 복잡한 함수도 잘 찾아 학습을 진행한다.
입력과 출력의 차원이 고정되어있다.
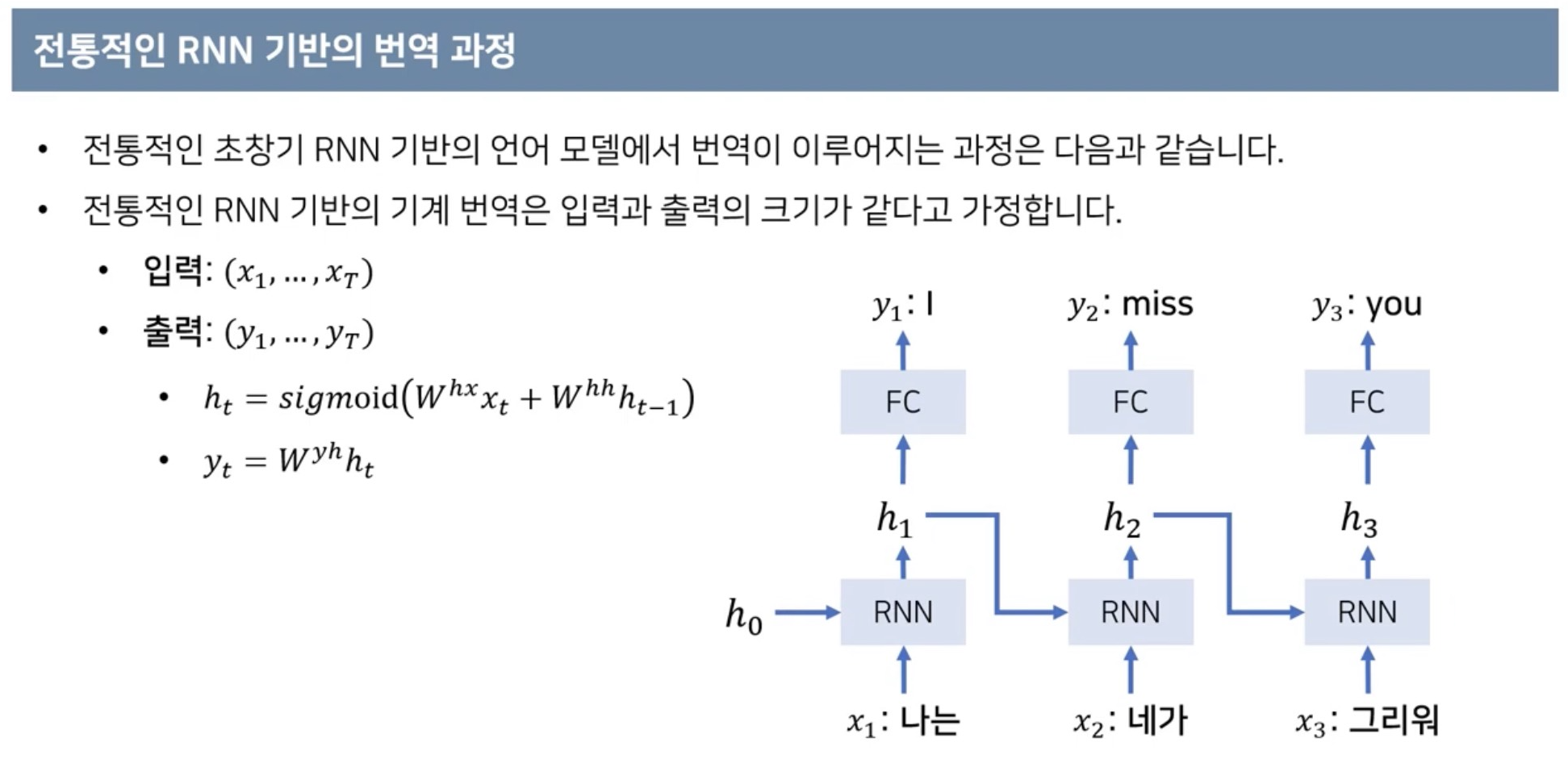
이전까지의 모델들은 입력과 출력의 차원이 고정되어 있어
연속적인 시퀀스 데이터를 처리하는것은 쉽지 않다.
번역과 같이 Sequencial한 데이터를 처리할때 입력과 출력의 길이가 가변적으로 바뀔 필요가 있다.
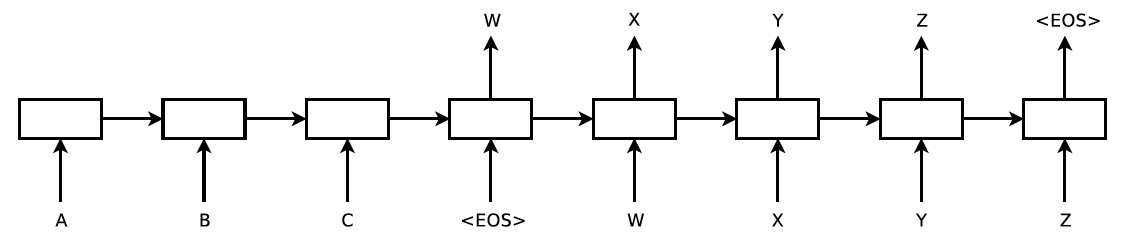
LSTM만으로 Sequence to Sequence 문제를 해결할수 있다.
인코딩을 통해 입력된 데이터에 대해 큰 크기에 고정된 컨텍스트 벡터를 뽑은 뒤 디코더가 이를 입력으로 받아 출력 시퀀스를 뽑는 동작을 하면 충분히 좋은 성능을 낼수 있다.
LSTM 장기의존성 없이 잘 처리할수 있다.
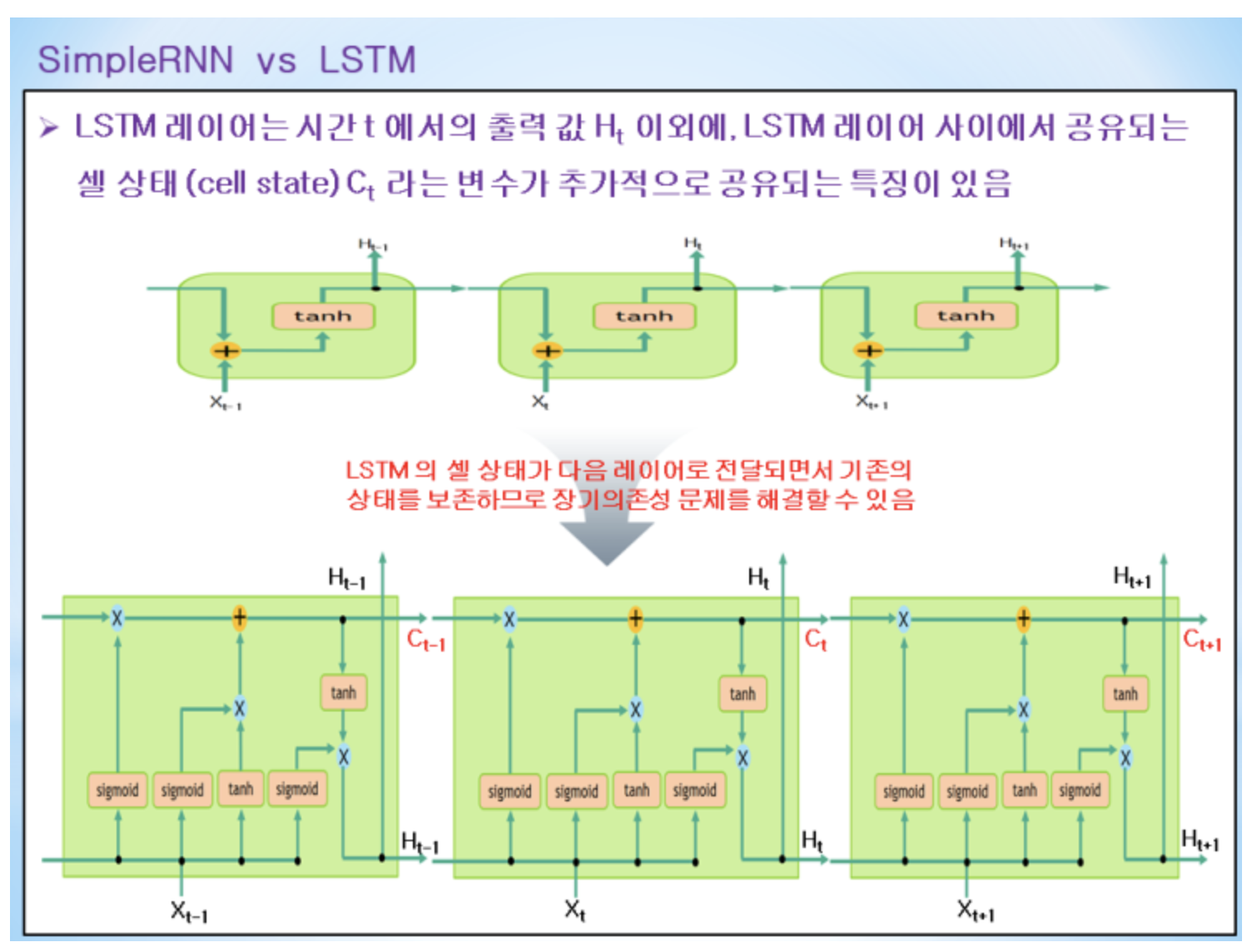
새로운 입력과 이전 상태 참조하여 현재의 상태를 결정하는 것
Forget gate : 얼마나 잊어 버릴 것인지 결정
Input gate : 얼마의 비율로 사용할 것인지 결정
Cell state : 이 둘을 적절히 섞는다.
일련의 정보들을 모두 종합해서 Output gate로 넘겨준다.
LSTM와 SMT기법을 같이 사용하니 가장 성능이 좋았다.
LSTM을 사용하면 문장일 길어도 잘 처리했다.

2. 모델
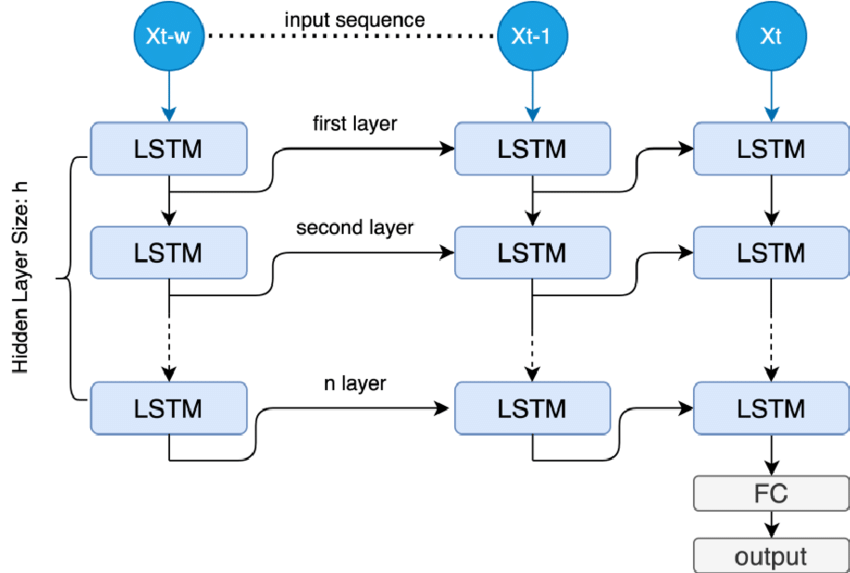
인코딩 LSTM 과 디코딩 LSTM는 서로 다른 파라미터를 가진다.
4개의 layer로 중첩하여 사용하였고 마지막으로 입력 문장의 순서를 바꾸는 것이 성능향상이 되었다.
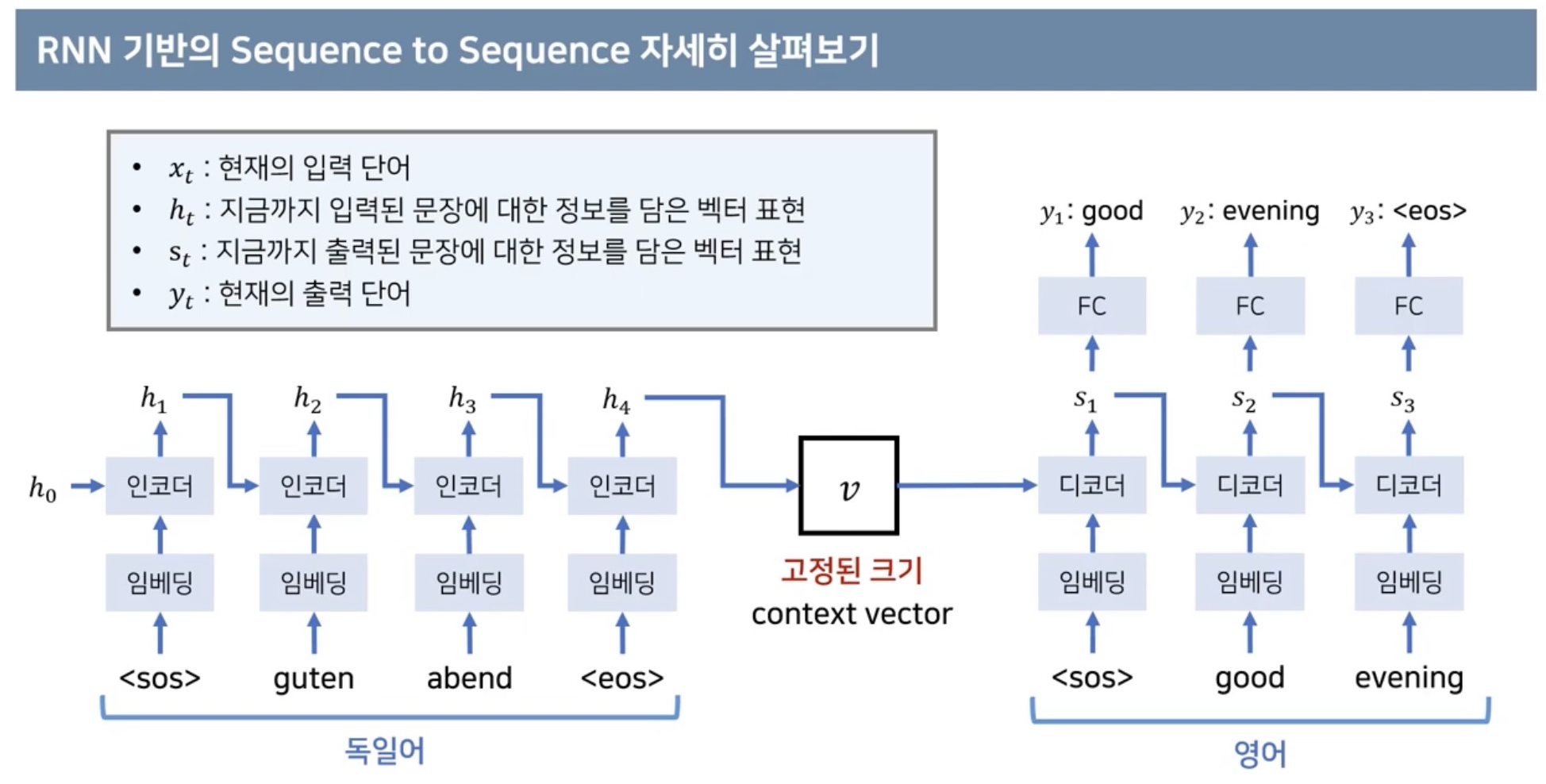
임베딩 : 독일어를 영어로 바꾼다고 하면 독일어에서 등장빈도 높은 단어가 2만개 정도 있다고 가정하면 매 단어를 2만 차원의 원핫 인코딩으로 하면 차원의 크기가 너무 커질수 있어 1천차원 2천차원으로 상대적으로 적은 데이터로 표현할수 있도록 차원을 줄임
3. 실험
학습
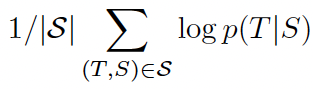
테스트
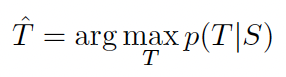
트레이닝 정보
LSTM 4Layers
임베딩 1,000차원
LSTM 파라미터 -0.08 ~ 0.08 값으로 유니폼 분포를 따른다.
그라디언트 배치 사이즈 128만큼 설정(문장의 개수 128개)
매번 문장이 들어올때마다 가장 확률이 높은 타켓 문장을 출력
beam search 활용 : 단순히 매번 가장 확률이 높은 것만 뽑는것이 아니라 특정 깊이 만큼 더 들어갈수 있게 만들어 출력 문장이 확률이 더 높아질수 있도록 적용
beam search를 활용 EOS가 나올때까지 타켓 문장중에 가장 확률값이 높은 경우를 고름
beam search : 평가값이 우수한 일정 개수의 확장 가능한 노드만을 메모리에 관리하면서 최상 우선 탐색을 적용하는 기법이다.

통계적 기계번역 시스템과 같이 사용하면 성능이 좋았다.
처음들어온 문장은 더 잘 맞추고 나중에 들어오는 문장일수록 덜 맞추지만 그럼에도 불구하고 성능이 좋았다.
실험결과
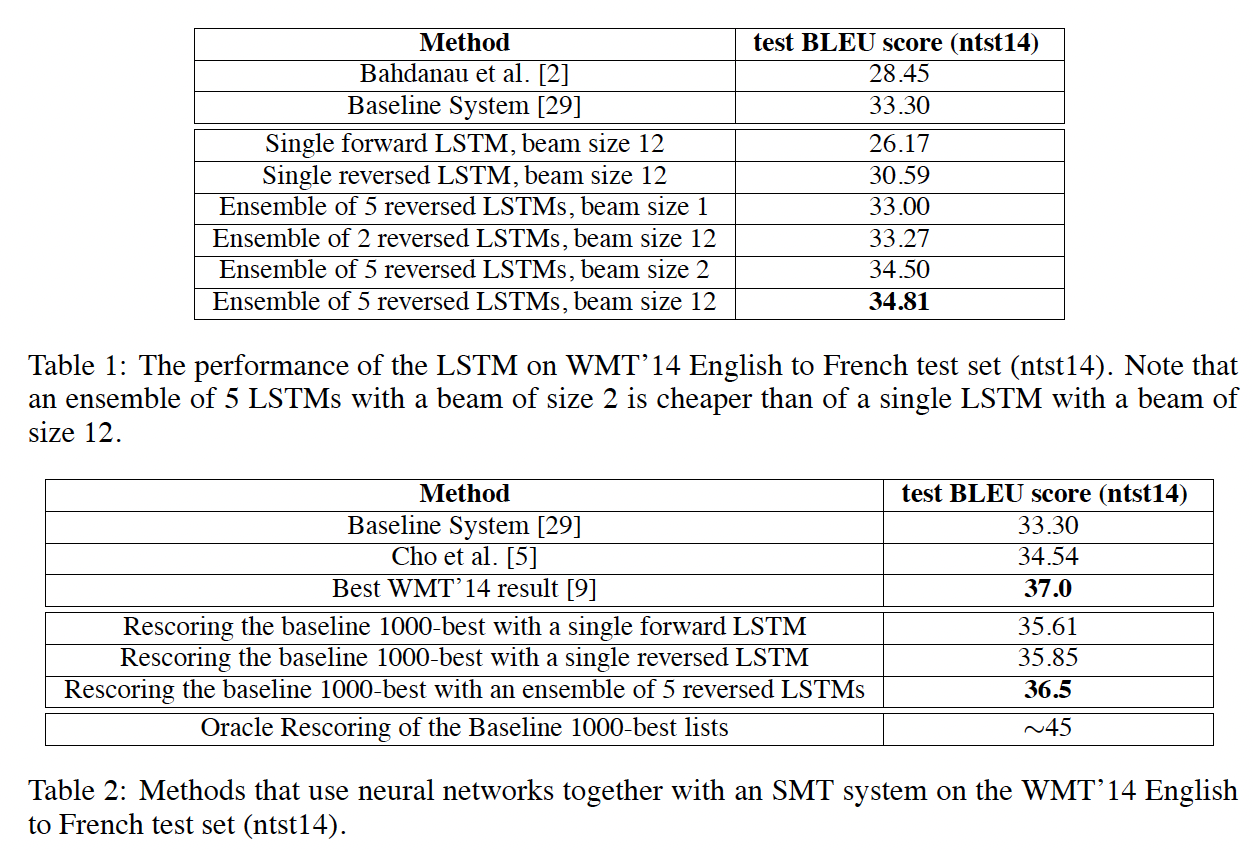
이전 SOTA 보다는 좋지는 않지만 높은 성능이 나왔다.